 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinitesimal Causality
Jun 23, 2026This paper introduces a categorical account of infinitesimal causality in Frobenius Markov categories equipped with tangent-bundle semantics. IDC captures the infinitesimal layer in which interventions act as tangent deformations of copy/discard structure. Two distinct Frobenius structures interact: (1) the categorical Frobenius algebra on classical variables encoding copying, comparing, and discarding; and (2) the geometric Frobenius integrability condition, namely involutive closure of the intervention distribution, distinct from the algebraic Frobenius structure. Categorical causal sufficiency is defined as the compatibility of these two notions. A key observation is that, for structural causal models, infinitesimal causality is most naturally formulated in the slice of deterministic mechanisms over exogenous variables, with visible stochastic kernels obtained only after pushforward. Interventions are tangent vectors that deform the Frobenius copy/discard operations; their Lie brackets measure whether this deformation preserves classical information-flow structure. Pearl's do-calculus is used as a guiding example of intervention identities: ignoring irrelevant interventions corresponds to counit invariance, action/observation exchange to coproduct compatibility with pushforward, and independence to involutive bracket closure of the visible intervention distribution.
Latent Confounded Causal Discovery via Lie Bracket Geometry
Jun 17, 2026Recent work on Kan-Do-Calculus (KDC) has established that the boundary between passive observation and active intervention in causal inference is a category-theoretic bi-adjunction, with interventions modeled by left Kan extensions and conditioning by right Kan extensions. This paper introduces two causal discovery algorithms under latent confounding, building on the information-geometric and categorical consequences of KDC. In smooth statistical settings, Radon-Nikodym derivatives between observational and interventional measures induce local causal vector fields; failures of these fields to close under Lie brackets become computable Frobenius residuals, which we interpret as witnesses of failed visible integrability and possible latent or unmodeled structure. Our first algorithm, BRIDGE (Bracket Residuals for Interventional Discovery and Geometric Estimation), combines an interventional density or Radon-Nikodym-ratio engine with a geometric screen that proposes a high-recall family of admissible arrows, identifies non-closing visible pairs as latent-obstruction candidates, and passes the reduced family to downstream score-based or differentiable discovery routines. The second algorithmic contribution, Spectral Kan-Do Flow Matching (SKFM), learns amortized intervention fields and factors latent curvature spectrally, exposing the direct Lie-space endpoint toward which BRIDGE points. A detailed set of experiments show that both algorithms are capable of discovering causal models with latent confounders while collapsing the super-exponential space of possible DAGs by many orders of magnitude. This paper introduces a new paradigm in causal discovery, where latent structure is inferred directly from the geometry of intervention-induced flows.
Causal Density Functions
May 30, 2026We introduce causal density functions: Radon-Nikodym derivatives that compare interventional laws to observational laws and therefore act as local density ratios for causal effects. Whereas many causal-strength measures compare whole distributions after graph surgery, causal density functions provide a pointwise change-of-measure object that can be estimated, calibrated, and used to score directed influence. The basic identity \[ \mathbb{E}_{\mathrm{do}}[f(Y)] = \mathbb{E}_{\mathrm{obs}}\!\left[f(Y)ρ(X,Y)\right] \] makes causal density directly testable: if the estimated density ratio is correct, observational expectations reweighted by $ρ$ reproduce interventional expectations. We derive practical estimators for do-curves and directed edge scores, relate the construction to Radon-Nikodym/Kan semantics for conditioning and intervention, and evaluate the resulting estimators on synthetic and real perturbation benchmarks.
Universal Decision Learners
May 29, 2026Many theories of decision making -- planning, reinforcement learning, causal intervention, online learning, and game-theoretic equilibrium -- turn local information into globally coherent behavior. This paper proposes a common categorical formulation: a Universal Decision Learner (UDL) extends a partially specified decision functor from observed contexts to new contexts by a pair of universal constructions. Left Kan extensions express rollout, aggregation, and candidate generation; right Kan extensions express consistency, constraint satisfaction, and fixed-point semantics. The central claim is not that every decision problem has the same algorithm, but that many decision formalisms instantiate the same universal problem: extend local behavioral data canonically, then characterize the globally coherent extensions. We give the abstract UDL construction, prove its universal comparison property, define Kan-invariant behavioral equivalence and minimal abstractions, and show how Bellman equations, planning recursions, causal interventions, online regret, and equilibria arise as special cases. The supplementary material develops the reinforcement-learning specialization in more detail.
Kan Extension Transformers: A Categorical Unification of Attention, Diffusion, and Predict-Detach Self-Conditioning
May 26, 2026We propose Kan Extension Transformers (KETs) as a unifying categorical framework for a diverse group of Transformer implementations. The core claim is that a Transformer layer can be viewed as a weighted structured extension operator: standard attention is the singleton-neighborhood case, Geometric Transformer style incidence mixing is a sparse edge-restricted case, and KET is the higher-order simplicial case. This lens also clarifies a bridge to diffusion-style completion. When the extension operator acts on detached predictive carriers instead of teacher-forced hidden states, it becomes a valid self-conditioning mechanism that exposes noncausal structure without leaking gold future tokens. We include a comprehensive experimental validation of 12 different Transformer implementations varying across strict-causal and predict-detach regimes on Penn Treebank, WikiText-2, and WikiText-103. In the strict-causal setting, quadratic KET is the strongest model among the compared causal architectures on WikiText-2 and WikiText-103. Across all datasets, however, the largest gains come from the predict-detach regime rather than from changing the neighborhood family alone.
PROMETHEUS: Automating Deep Causal Research Integrating Text, Data and Models
May 13, 2026Large language models can extract local causal claims from text, but those claims become more useful when organized as persistent, navigable world models rather than as flat summaries. We introduce PROMETHEUS, a framework that turns retrieved literature, filings, reviews, reports, agent traces, source data, code, simulations, and scientific models into causal atlases: sheaf-like families of local causal predictive-state models over an explicit cover of a research substrate. Each local region contains causal episodes, structured claim tables, predictive tests, support statistics, and provenance; restriction maps compare overlapping regions; gluing diagnostics expose agreement, drift, contradiction, and underdetermination. The resulting Topos World Model is not a single universal graph. It is a research instrument for navigating what a corpus says, where it says it, how strongly it is supported, and where local claims fail to assemble into a coherent global view. Three literature-atlas case studies -- ocean-temperature impacts on marine populations, GLP-1 weight-loss evidence, and resveratrol/red-wine health-benefit claims -- illustrate deep causal research from text with explicit locality, evidence, persistent state, and gluing tension. Four grounded-counterfactual case studies -- a Nature Climate Change microplastics forcing paper, an Indus Valley hydrology paper with VIC-derived figure data and model code, the canonical Sachs protein-signaling study with single-cell perturbation data, and a Nature singing-mouse study with MAPseq projection matrices -- show a stronger mode: when a paper ships source data, simulation outputs, or code, PROMETHEUS can evaluate a counterfactual against that scientific substrate and then rebuild the sheaf world model around the
CSQL: Mapping Documents into Causal Databases
Jan 13, 2026We describe a novel system, CSQL, which automatically converts a collection of unstructured text documents into an SQL-queryable causal database (CDB). A CDB differs from a traditional DB: it is designed to answer "why'' questions via causal interventions and structured causal queries. CSQL builds on our earlier system, DEMOCRITUS, which converts documents into thousands of local causal models derived from causal discourse. Unlike RAG-based systems or knowledge-graph based approaches, CSQL supports causal analysis over document collections rather than purely associative retrieval. For example, given an article on the origins of human bipedal walking, CSQL enables queries such as: "What are the strongest causal influences on bipedalism?'' or "Which variables act as causal hubs with the largest downstream influence?'' Beyond single-document case studies, we show that CSQL can also ingest RAG/IE-compiled causal corpora at scale by compiling the Testing Causal Claims (TCC) dataset of economics papers into a causal database containing 265,656 claim instances spanning 45,319 papers, 44 years, and 1,575 reported method strings, thereby enabling corpus-level causal queries and longitudinal analyses in CSQL. Viewed abstractly, CSQL functions as a compiler from unstructured documents into a causal database equipped with a principled algebra of queries, and can be applied broadly across many domains ranging from business, humanities, and science.
Categorical Belief Propagation: Sheaf-Theoretic Inference via Descent and Holonomy
Jan 08, 2026We develop a categorical foundation for belief propagation on factor graphs. We construct the free hypergraph category \(\Syn_Σ\) on a typed signature and prove its universal property, yielding compositional semantics via a unique functor to the matrix category \(\cat{Mat}_R\). Message-passing is formulated using a Grothendieck fibration \(\int\Msg \to \cat{FG}_Σ\) over polarized factor graphs, with schedule-indexed endomorphisms defining BP updates. We characterize exact inference as effective descent: local beliefs form a descent datum when compatibility conditions hold on overlaps. This framework unifies tree exactness, junction tree algorithms, and loopy BP failures under sheaf-theoretic obstructions. We introduce HATCC (Holonomy-Aware Tree Compilation), an algorithm that detects descent obstructions via holonomy computation on the factor nerve, compiles non-trivial holonomy into mode variables, and reduces to tree BP on an augmented graph. Complexity is \(O(n^2 d_{\max} + c \cdot k_{\max} \cdot δ_{\max}^3 + n \cdot δ_{\max}^2)\) for \(n\) factors and \(c\) fundamental cycles. Experimental results demonstrate exact inference with significant speedup over junction trees on grid MRFs and random graphs, along with UNSAT detection on satisfiability instances.
Large Causal Models from Large Language Models
Dec 08, 2025We introduce a new paradigm for building large causal models (LCMs) that exploits the enormous potential latent in today's large language models (LLMs). We describe our ongoing experiments with an implemented system called DEMOCRITUS (Decentralized Extraction of Manifold Ontologies of Causal Relations Integrating Topos Universal Slices) aimed at building, organizing, and visualizing LCMs that span disparate domains extracted from carefully targeted textual queries to LLMs. DEMOCRITUS is methodologically distinct from traditional narrow domain and hypothesis centered causal inference that builds causal models from experiments that produce numerical data. A high-quality LLM is used to propose topics, generate causal questions, and extract plausible causal statements from a diverse range of domains. The technical challenge is then to take these isolated, fragmented, potentially ambiguous and possibly conflicting causal claims, and weave them into a coherent whole, converting them into relational causal triples and embedding them into a LCM. Addressing this technical challenge required inventing new categorical machine learning methods, which we can only briefly summarize in this paper, as it is focused more on the systems side of building DEMOCRITUS. We describe the implementation pipeline for DEMOCRITUS comprising of six modules, examine its computational cost profile to determine where the current bottlenecks in scaling the system to larger models. We describe the results of using DEMOCRITUS over a wide range of domains, spanning archaeology, biology, climate change, economics, medicine and technology. We discuss the limitations of the current DEMOCRITUS system, and outline directions for extending its capabilities.
Consciousness as a Functor
Aug 25, 2025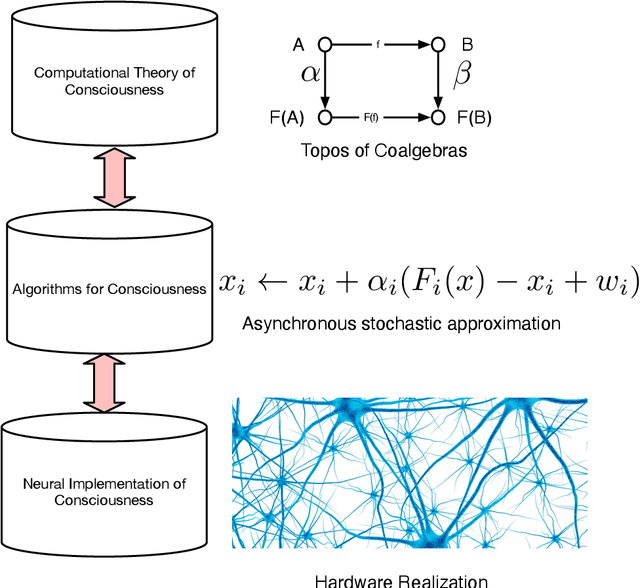
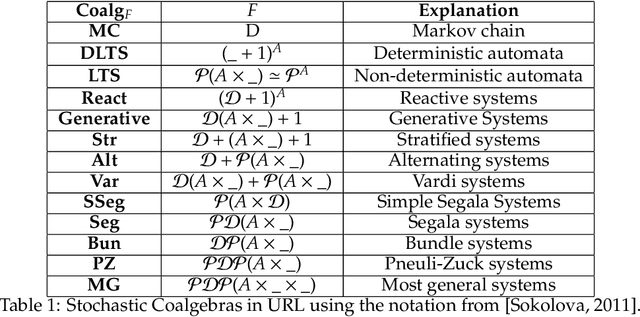
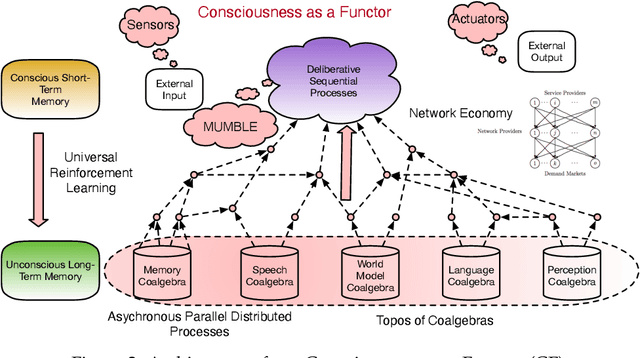
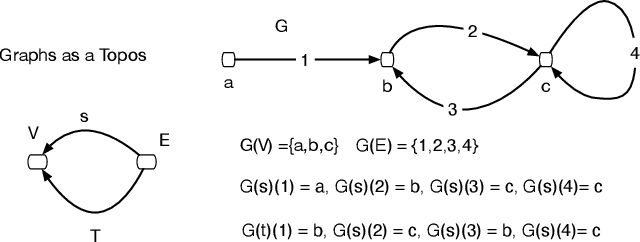
We propose a novel theory of consciousness as a functor (CF) that receives and transmits contents from unconscious memory into conscious memory. Our CF framework can be seen as a categorial formulation of the Global Workspace Theory proposed by Baars. CF models the ensemble of unconscious processes as a topos category of coalgebras. The internal language of thought in CF is defined as a Multi-modal Universal Mitchell-Benabou Language Embedding (MUMBLE). We model the transmission of information from conscious short-term working memory to long-term unconscious memory using our recently proposed Universal Reinforcement Learning (URL) framework. To model the transmission of information from unconscious long-term memory into resource-constrained short-term memory, we propose a network economic model.