 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative Question Answering with Cutting-Edge Open-Domain QA Techniques: A Comprehensive Study
Jun 07, 2021
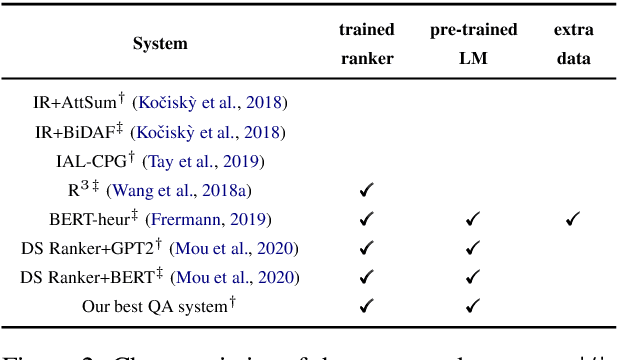
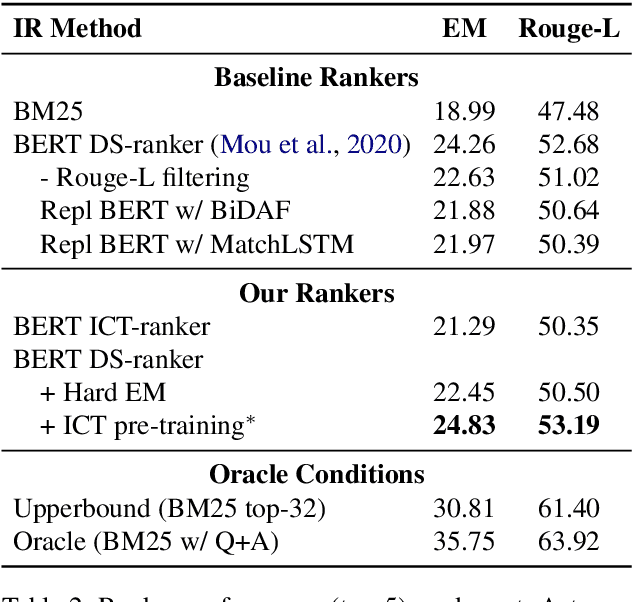

Recent advancements in open-domain question answering (ODQA), i.e., finding answers from large open-domain corpus like Wikipedia, have led to human-level performance on many datasets. However, progress in QA over book stories (Book QA) lags behind despite its similar task formulation to ODQA. This work provides a comprehensive and quantitative analysis about the difficulty of Book QA: (1) We benchmark the research on the NarrativeQA dataset with extensive experiments with cutting-edge ODQA techniques. This quantifies the challenges Book QA poses, as well as advances the published state-of-the-art with a $\sim$7\% absolute improvement on Rouge-L. (2) We further analyze the detailed challenges in Book QA through human studies.\footnote{\url{https://github.com/gorov/BookQA}.} Our findings indicate that the event-centric questions dominate this task, which exemplifies the inability of existing QA models to handle event-oriented scenarios.
Complementary Evidence Identification in Open-Domain Question Answering
Apr 05, 2021
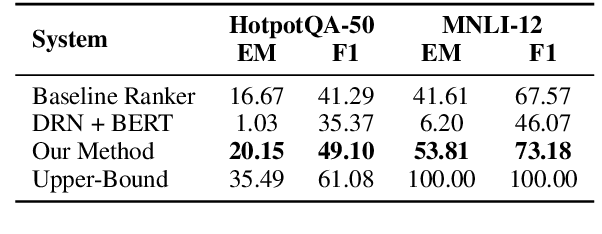

This paper proposes a new problem of complementary evidence identification for open-domain question answering (QA). The problem aims to efficiently find a small set of passages that covers full evidence from multiple aspects as to answer a complex question. To this end, we proposes a method that learns vector representations of passages and models the sufficiency and diversity within the selected set, in addition to the relevance between the question and passages. Our experiments demonstrate that our method considers the dependence within the supporting evidence and significantly improves the accuracy of complementary evidence selection in QA domain.
CASS: Towards Building a Social-Support Chatbot for Online Health Community
Feb 04, 2021
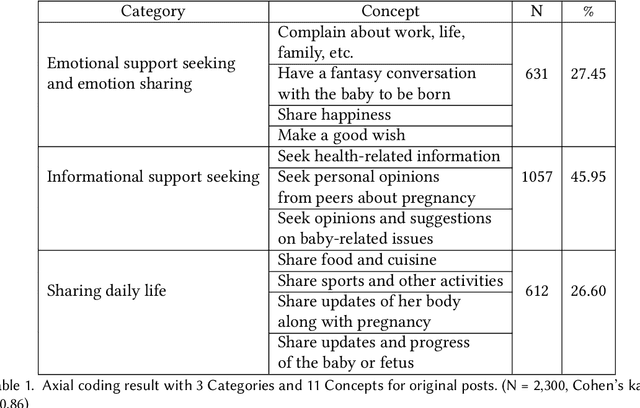
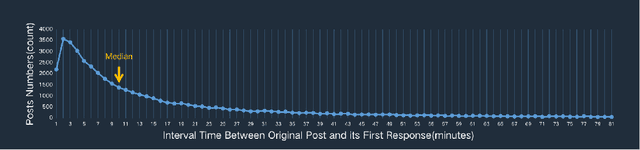
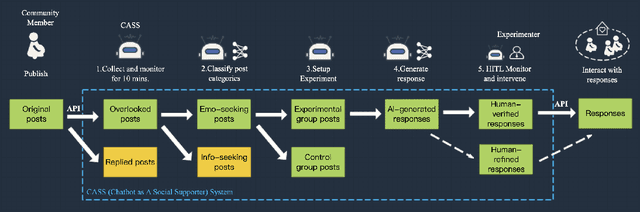
Chatbots systems, despite their popularity in today's HCI and CSCW research, fall short for one of the two reasons: 1) many of the systems use a rule-based dialog flow, thus they can only respond to a limited number of pre-defined inputs with pre-scripted responses; or 2) they are designed with a focus on single-user scenarios, thus it is unclear how these systems may affect other users or the community. In this paper, we develop a generalizable chatbot architecture (CASS) to provide social support for community members in an online health community. The CASS architecture is based on advanced neural network algorithms, thus it can handle new inputs from users and generate a variety of responses to them. CASS is also generalizable as it can be easily migrate to other online communities. With a follow-up field experiment, CASS is proven useful in supporting individual members who seek emotional support. Our work also contributes to fill the research gap on how a chatbot may influence the whole community's engagement.
Question Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020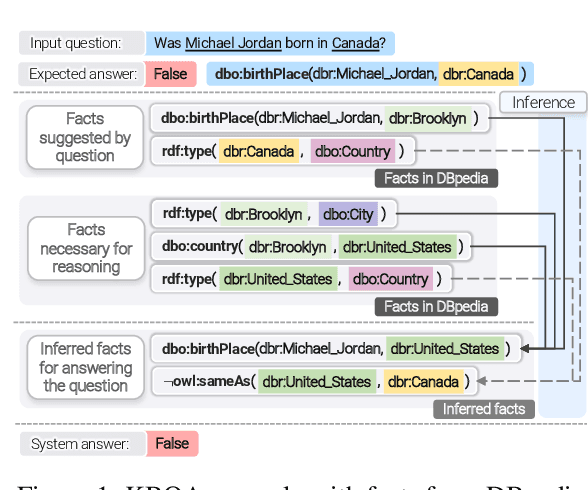
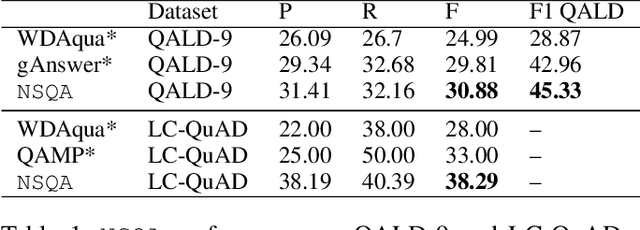
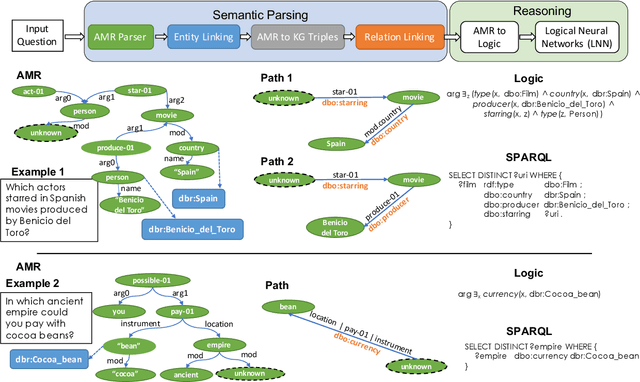

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
Interpretable Visual Reasoning via Induced Symbolic Space
Nov 23, 2020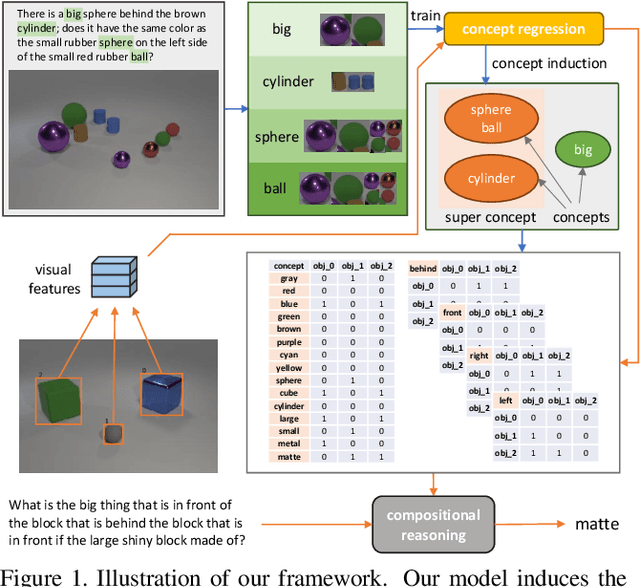
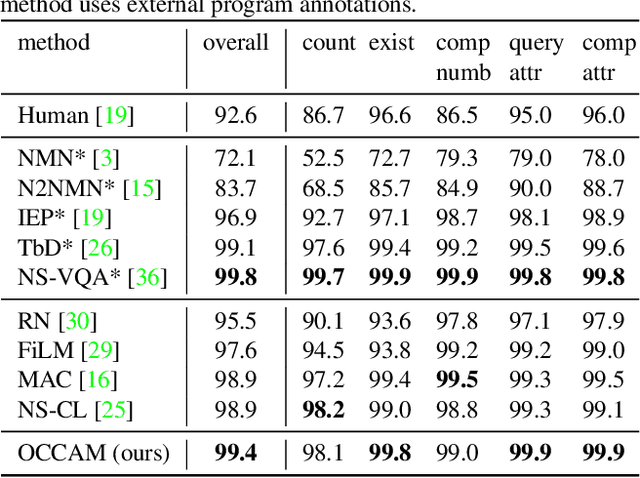
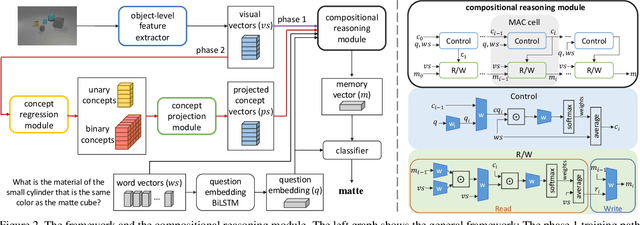

We study the problem of concept induction in visual reasoning, i.e., identifying concepts and their hierarchical relationships from question-answer pairs associated with images; and achieve an interpretable model via working on the induced symbolic concept space. To this end, we first design a new framework named object-centric compositional attention model (OCCAM) to perform the visual reasoning task with object-level visual features. Then, we come up with a method to induce concepts of objects and relations using clues from the attention patterns between objects' visual features and question words. Finally, we achieve a higher level of interpretability by imposing OCCAM on the objects represented in the induced symbolic concept space. Experiments on the CLEVR dataset demonstrate: 1) our OCCAM achieves a new state of the art without human-annotated functional programs; 2) our induced concepts are both accurate and sufficient as OCCAM achieves an on-par performance on objects represented either in visual features or in the induced symbolic concept space.
Multilingual BERT Post-Pretraining Alignment
Oct 23, 2020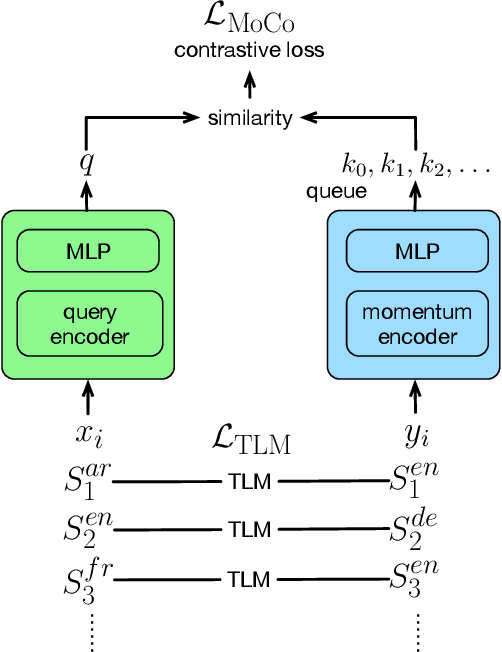
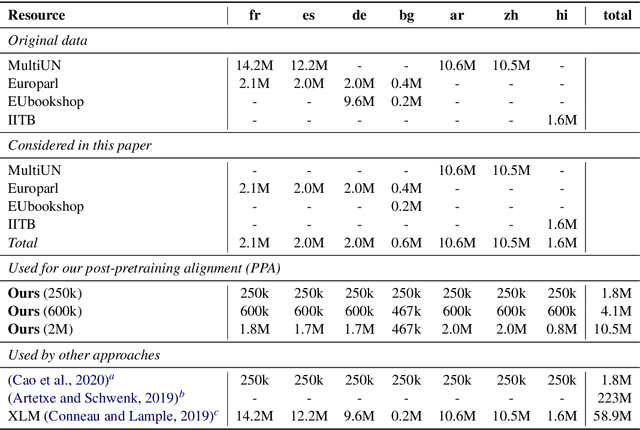
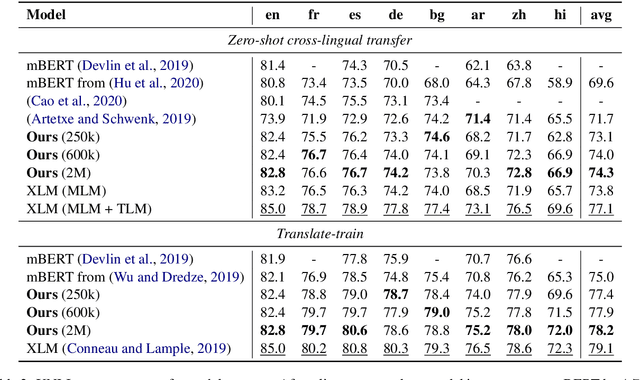
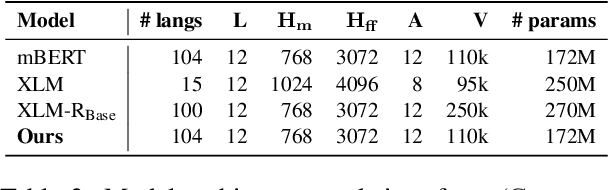
We propose a simple method to align multilingual contextual embeddings as a post-pretraining step for improved zero-shot cross-lingual transferability of the pretrained models. Using parallel data, our method aligns embeddings on the word level through the recently proposed Translation Language Modeling objective as well as on the sentence level via contrastive learning and random input shuffling. We also perform code-switching with English when finetuning on downstream tasks. On XNLI, our best model (initialized from mBERT) improves over mBERT by 4.7% in the zero-shot setting and achieves comparable result to XLM for translate-train while using less than 18% of the same parallel data and 31% less model parameters. On MLQA, our model outperforms XLM-R_Base that has 57% more parameters than ours.
Deriving Commonsense Inference Tasks from Interactive Fictions
Oct 19, 2020

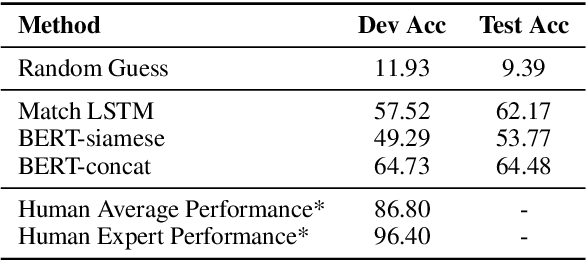
Commonsense reasoning simulates the human ability to make presumptions about our physical world, and it is an indispensable cornerstone in building general AI systems. We propose a new commonsense reasoning dataset based on human's interactive fiction game playings as human players demonstrate plentiful and diverse commonsense reasoning. The new dataset mitigates several limitations of the prior art. Experiments show that our task is solvable to human experts with sufficient commonsense knowledge but poses challenges to existing machine reading models, with a big performance gap of more than 30%.
Interactive Fiction Game Playing as Multi-Paragraph Reading Comprehension with Reinforcement Learning
Oct 05, 2020
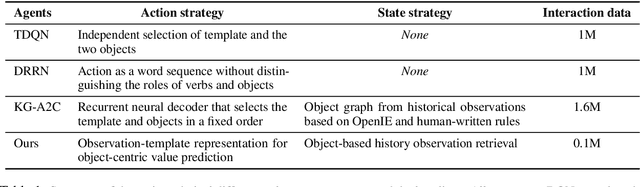
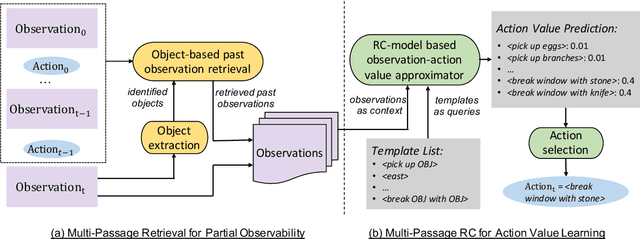
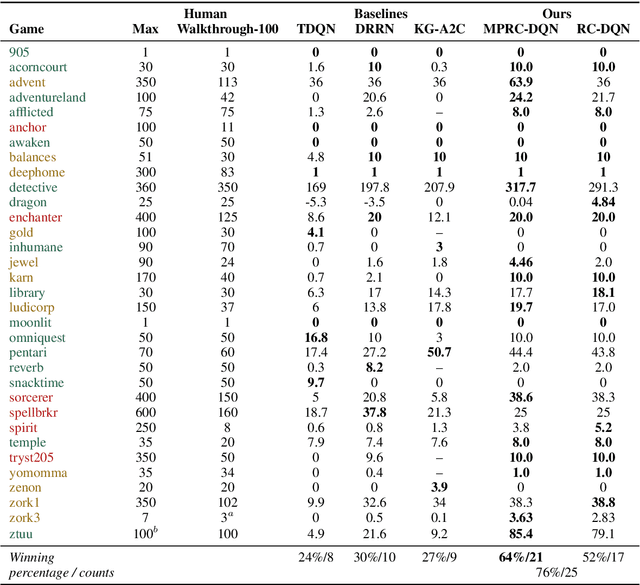
Interactive Fiction (IF) games with real human-written natural language texts provide a new natural evaluation for language understanding techniques. In contrast to previous text games with mostly synthetic texts, IF games pose language understanding challenges on the human-written textual descriptions of diverse and sophisticated game worlds and language generation challenges on the action command generation from less restricted combinatorial space. We take a novel perspective of IF game solving and re-formulate it as Multi-Passage Reading Comprehension (MPRC) tasks. Our approaches utilize the context-query attention mechanisms and the structured prediction in MPRC to efficiently generate and evaluate action outputs and apply an object-centric historical observation retrieval strategy to mitigate the partial observability of the textual observations. Extensive experiments on the recent IF benchmark (Jericho) demonstrate clear advantages of our approaches achieving high winning rates and low data requirements compared to all previous approaches. Our source code is available at: https://github.com/XiaoxiaoGuo/rcdqn.
MCMH: Learning Multi-Chain Multi-Hop Rules for Knowledge Graph Reasoning
Oct 05, 2020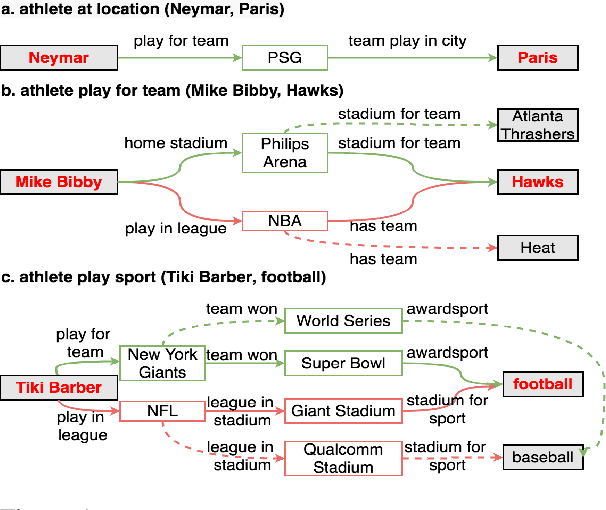

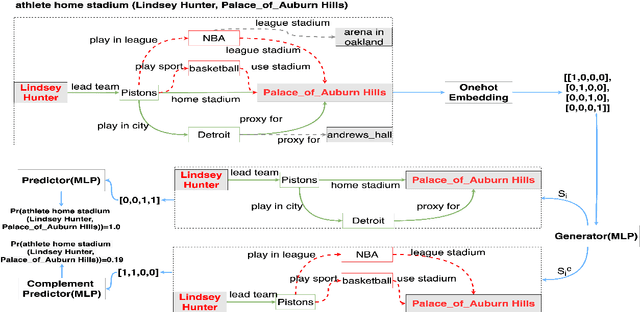
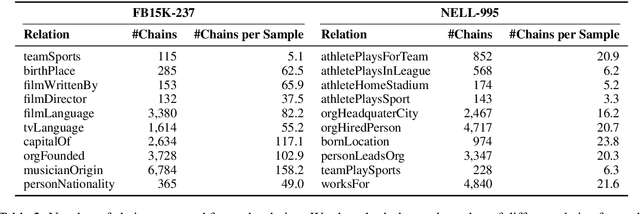
Multi-hop reasoning approaches over knowledge graphs infer a missing relationship between entities with a multi-hop rule, which corresponds to a chain of relationships. We extend existing works to consider a generalized form of multi-hop rules, where each rule is a set of relation chains. To learn such generalized rules efficiently, we propose a two-step approach that first selects a small set of relation chains as a rule and then evaluates the confidence of the target relationship by jointly scoring the selected chains. A game-theoretical framework is proposed to this end to simultaneously optimize the rule selection and prediction steps. Empirical results show that our multi-chain multi-hop (MCMH) rules result in superior results compared to the standard single-chain approaches, justifying both our formulation of generalized rules and the effectiveness of the proposed learning framework.
Leveraging Semantic Parsing for Relation Linking over Knowledge Bases
Sep 16, 2020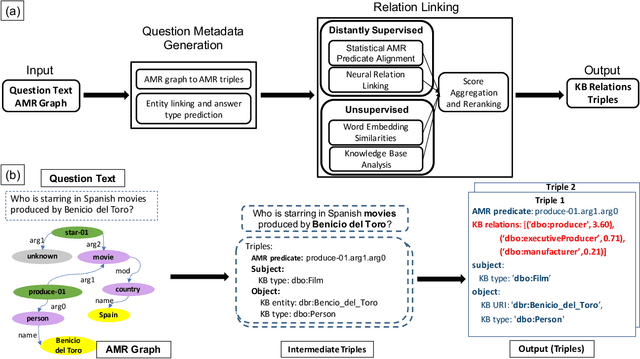

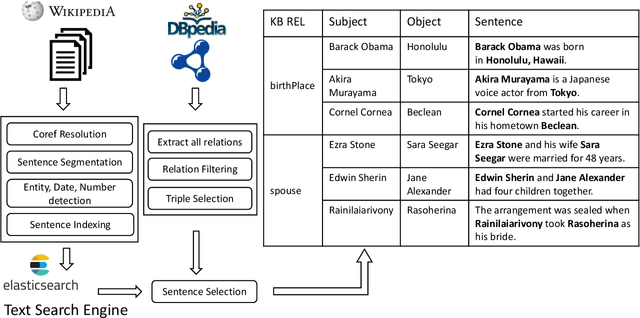
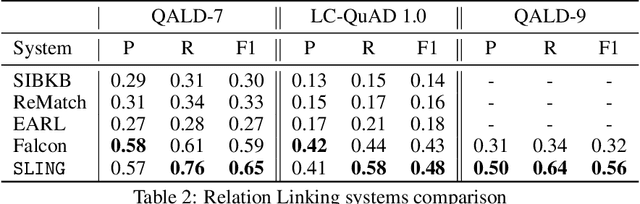
Knowledgebase question answering systems are heavily dependent on relation extraction and linking modules. However, the task of extracting and linking relations from text to knowledgebases faces two primary challenges; the ambiguity of natural language and lack of training data. To overcome these challenges, we present SLING, a relation linking framework which leverages semantic parsing using Abstract Meaning Representation (AMR) and distant supervision. SLING integrates multiple relation linking approaches that capture complementary signals such as linguistic cues, rich semantic representation, and information from the knowledgebase. The experiments on relation linking using three KBQA datasets; QALD-7, QALD-9, and LC-QuAD 1.0 demonstrate that the proposed approach achieves state-of-the-art performance on all benchmarks.