 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Micro Knowledge Graphs from Technical Support Documents
Apr 14, 2025Short technical support pages such as IBM Technotes are quite common in technical support domain. These pages can be very useful as the knowledge sources for technical support applications such as chatbots, search engines and question-answering (QA) systems. Information extracted from documents to drive technical support applications is often stored in the form of Knowledge Graph (KG). Building KGs from a large corpus of documents poses a challenge of granularity because a large number of entities and actions are present in each page. The KG becomes virtually unusable if all entities and actions from these pages are stored in the KG. Therefore, only key entities and actions from each page are extracted and stored in the KG. This approach however leads to loss of knowledge represented by entities and actions left out of the KG as they are no longer available to graph search and reasoning functions. We propose a set of techniques to create micro knowledge graph (micrograph) for each of such web pages. The micrograph stores all the entities and actions in a page and also takes advantage of the structure of the page to represent exactly in which part of that page these entities and actions appeared, and also how they relate to each other. These micrographs can be used as additional knowledge sources by technical support applications. We define schemas for representing semi-structured and plain text knowledge present in the technical support web pages. Solutions in technical support domain include procedures made of steps. We also propose a technique to extract procedures from these webpages and the schemas to represent them in the micrographs. We also discuss how technical support applications can take advantage of the micrographs.
A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases
Jan 15, 2022



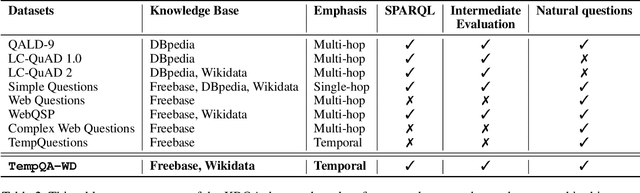
Knowledge Base Question Answering (KBQA) tasks that involve complex reasoning are emerging as an important research direction. However, most existing KBQA datasets focus primarily on generic multi-hop reasoning over explicit facts, largely ignoring other reasoning types such as temporal, spatial, and taxonomic reasoning. In this paper, we present a benchmark dataset for temporal reasoning, TempQA-WD, to encourage research in extending the present approaches to target a more challenging set of complex reasoning tasks. Specifically, our benchmark is a temporal question answering dataset with the following advantages: (a) it is based on Wikidata, which is the most frequently curated, openly available knowledge base, (b) it includes intermediate sparql queries to facilitate the evaluation of semantic parsing based approaches for KBQA, and (c) it generalizes to multiple knowledge bases: Freebase and Wikidata. The TempQA-WD dataset is available at https://github.com/IBM/tempqa-wd.
SYGMA: System for Generalizable Modular Question Answering OverKnowledge Bases
Sep 28, 2021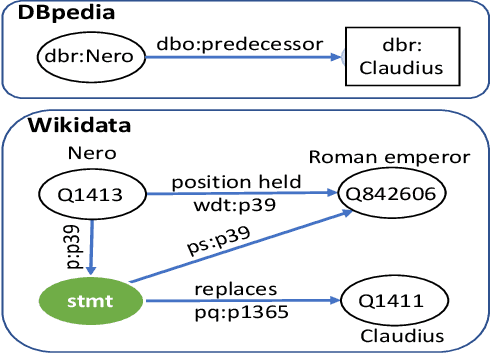


Knowledge Base Question Answering (KBQA) tasks that in-volve complex reasoning are emerging as an important re-search direction. However, most KBQA systems struggle withgeneralizability, particularly on two dimensions: (a) acrossmultiple reasoning types where both datasets and systems haveprimarily focused on multi-hop reasoning, and (b) across mul-tiple knowledge bases, where KBQA approaches are specif-ically tuned to a single knowledge base. In this paper, wepresent SYGMA, a modular approach facilitating general-izability across multiple knowledge bases and multiple rea-soning types. Specifically, SYGMA contains three high levelmodules: 1) KB-agnostic question understanding module thatis common across KBs 2) Rules to support additional reason-ing types and 3) KB-specific question mapping and answeringmodule to address the KB-specific aspects of the answer ex-traction. We demonstrate effectiveness of our system by evalu-ating on datasets belonging to two distinct knowledge bases,DBpedia and Wikidata. In addition, to demonstrate extensi-bility to additional reasoning types we evaluate on multi-hopreasoning datasets and a new Temporal KBQA benchmarkdataset on Wikidata, namedTempQA-WD1, introduced in thispaper. We show that our generalizable approach has bettercompetetive performance on multiple datasets on DBpediaand Wikidata that requires both multi-hop and temporal rea-soning
Knowledge Graph Question Answering via SPARQL Silhouette Generation
Sep 06, 2021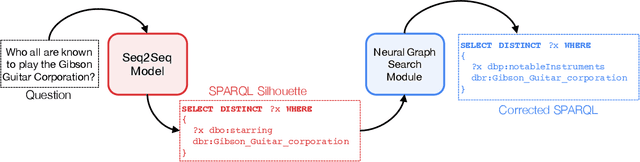
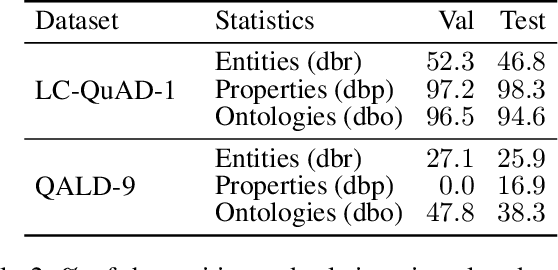
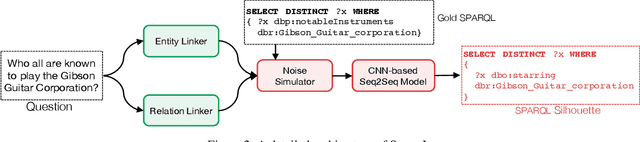
Knowledge Graph Question Answering (KGQA) has become a prominent area in natural language processing due to the emergence of large-scale Knowledge Graphs (KGs). Recently Neural Machine Translation based approaches are gaining momentum that translates natural language queries to structured query languages thereby solving the KGQA task. However, most of these methods struggle with out-of-vocabulary words where test entities and relations are not seen during training time. In this work, we propose a modular two-stage neural architecture to solve the KGQA task. The first stage generates a sketch of the target SPARQL called SPARQL silhouette for the input question. This comprises of (1) Noise simulator to facilitate out-of-vocabulary words and to reduce vocabulary size (2) seq2seq model for text to SPARQL silhouette generation. The second stage is a Neural Graph Search Module. SPARQL silhouette generated in the first stage is distilled in the second stage by substituting precise relation in the predicted structure. We simulate ideal and realistic scenarios by designing a noise simulator. Experimental results show that the quality of generated SPARQL silhouette in the first stage is outstanding for the ideal scenarios but for realistic scenarios (i.e. noisy linker), the quality of the resulting SPARQL silhouette drops drastically. However, our neural graph search module recovers it considerably. We show that our method can achieve reasonable performance improving the state-of-art by a margin of 3.72% F1 for the LC-QuAD-1 dataset. We believe, our proposed approach is novel and will lead to dynamic KGQA solutions that are suited for practical applications.
Question Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020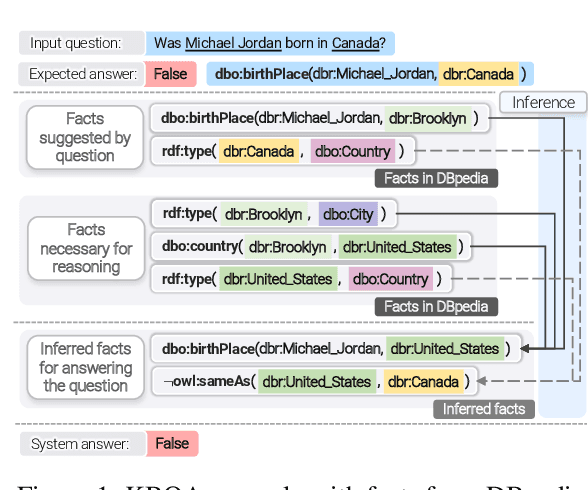
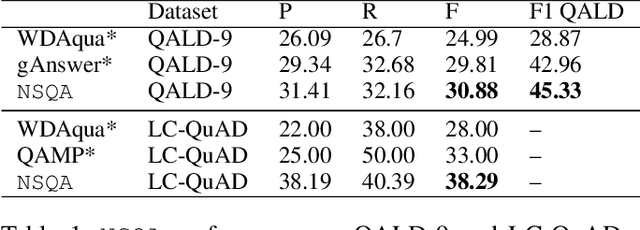
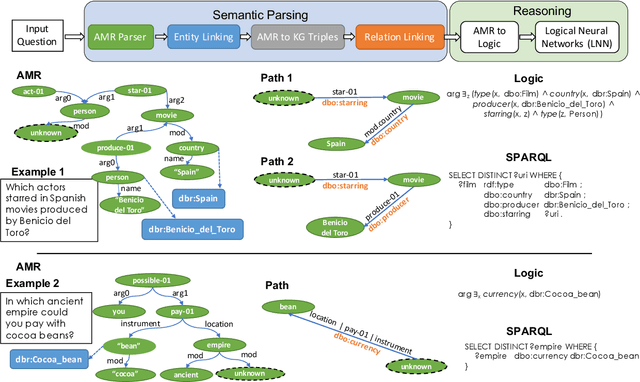

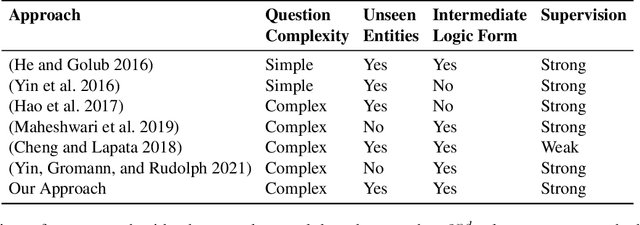
Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
The TechQA Dataset
Nov 08, 2019

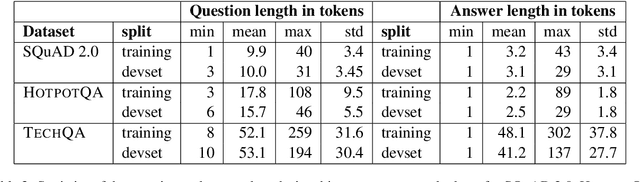
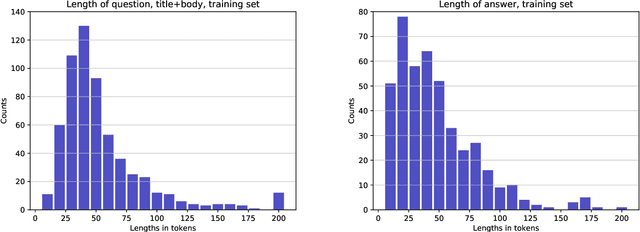
We introduce TechQA, a domain-adaptation question answering dataset for the technical support domain. The TechQA corpus highlights two real-world issues from the automated customer support domain. First, it contains actual questions posed by users on a technical forum, rather than questions generated specifically for a competition or a task. Second, it has a real-world size -- 600 training, 310 dev, and 490 evaluation question/answer pairs -- thus reflecting the cost of creating large labeled datasets with actual data. Consequently, TechQA is meant to stimulate research in domain adaptation rather than being a resource to build QA systems from scratch. The dataset was obtained by crawling the IBM Developer and IBM DeveloperWorks forums for questions with accepted answers that appear in a published IBM Technote---a technical document that addresses a specific technical issue. We also release a collection of the 801,998 publicly available Technotes as of April 4, 2019 as a companion resource that might be used for pretraining, to learn representations of the IT domain language.