 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenMinds: Pretrained User Tokens and Embeddings for User Understanding in Large Recommender Systems
Jun 23, 2026User modeling in industrial recommender systems typically produces dense embeddings, which suffer from representational constraints inherent to fixed-dimensional vectors. An emerging alternative for discrete user representation -- using LLMs to generate text-based user tokens -- captures topical co-occurrences rather than deep sequential behavior dynamics and produces outputs that are difficult to ground to item attributes. Meanwhile, Semantic ID (SID) based item tokenization has proven effective for improving generalization in generative recommendation, yet discrete SID-based representations for users remain largely unexplored. We propose TokenMinds, an industrial-scale system that extends the PLUM framework from item retrieval to user modeling, generating both discrete SID-based user tokens and dense user embeddings via an encoder-decoder architecture adapted from pre-trained LLMs. This dual-output design provides the complementary benefits of discrete, semantically grounded user representations while maintaining compatibility with existing downstream models that rely on dense embeddings. Additionally, the shared SID vocabulary naturally extends to cross-scenario modeling: by unifying long-form and short-form video behaviors into a single model, we substantially reduce training and serving costs. We validate TokenMinds through extensive offline experiments and live launches on multiple YouTube surfaces, served on full user traffic (billions of users) via an asynchronous infrastructure that decouples representation generation from downstream scoring. Focusing on ranking as the primary downstream use case, our results confirm the practical viability of SID-based user tokens at industrial scale and demonstrate that tokens and dense embeddings provide complementary value across different production ranking systems.
Token Factory: Efficiently Integrating Diverse Signals into Large Recommendation Models
Jun 17, 2026Large Recommendation Models (LRMs) have demonstrated promising capabilities in industry-scale recommendation tasks. However, holistically integrating traditional signals into these transformer-based architectures effectively and efficiently remains a major challenge. Conventional approaches that "textualize" these signals directly or create discrete item representations often lead to excessively long prompts, substantial memory footprints, and high computational overhead. To overcome these limitations, we propose "Token Factory", a framework designed to transform traditional signals into "soft tokens" that can be directly processed by LRMs. This approach enables efficient integration and compression of heterogeneous input features, preventing prompt length explosion while enhancing model performance. We detail the architecture of Token Factory and present experimental results validating its effectiveness in a production-scale recommendation environment.
LLM-Based User Personas for Recommendations at Scale
Jun 10, 2026Large Language Models (LLMs) offer unprecedented potential for enhancing recommendation systems through their world knowledge and reasoning capabilities. However, existing approaches often rely on structured IDs or offline processing, limiting semantic richness, real-time adaptability, and user-facing interpretability. In this paper, we introduce a novel framework that enables real-time generation of LLM-based user interest personas for a large-scale commercial video recommendation platform. Our method generates natural-language user interest personas that address the exploitation-exploration trade-off by combining the summarization of existing interests with novel topics, directly during serving. To overcome the computational challenges of online LLM inference at a billion-user scale, we design a cost-efficient architecture leveraging knowledge distillation, asynchronous inference, and input optimization via semantically clustered video representations. Extensive offline evaluations, user studies, and live A/B tests demonstrate significant improvements in viewer value. This work bridges the gap between high-level semantic understanding and industrial-scale recommendation, paving the way for more dynamic, explainable, and satisfying personalized experiences.
ORBIT: Preserving Foundational Language Capabilities in GenRetrieval via Origin-Regulated Merging
May 12, 2026Despite the rapid advancements in large language model (LLM) development, fine-tuning them for specific tasks often results in the catastrophic forgetting of their general, language-based reasoning abilities. This work investigates and addresses this challenge in the context of the Generative Retrieval (GenRetrieval) task. During GenRetrieval fine-tuning, we find this forgetting occurs rapidly and correlates with the distance between the fine-tuned and original model parameters. Given these observations, we propose ORBIT, a novel approach that actively tracks the distance between fine-tuned and initial model weights, and uses a weight averaging strategy to constrain model drift during GenRetrieval fine-tuning when this inter-model distance exceeds a maximum threshold. Our results show that ORBIT retains substantial text and retrieval performance by outperforming both common continual learning baselines and related regularization methods that also employ weight averaging.
Vectorizing the Trie: Efficient Constrained Decoding for LLM-based Generative Retrieval on Accelerators
Feb 26, 2026Generative retrieval has emerged as a powerful paradigm for LLM-based recommendation. However, industrial recommender systems often benefit from restricting the output space to a constrained subset of items based on business logic (e.g. enforcing content freshness or product category), which standard autoregressive decoding cannot natively support. Moreover, existing constrained decoding methods that make use of prefix trees (Tries) incur severe latency penalties on hardware accelerators (TPUs/GPUs). In this work, we introduce STATIC (Sparse Transition Matrix-Accelerated Trie Index for Constrained Decoding), an efficient and scalable constrained decoding technique designed specifically for high-throughput LLM-based generative retrieval on TPUs/GPUs. By flattening the prefix tree into a static Compressed Sparse Row (CSR) matrix, we transform irregular tree traversals into fully vectorized sparse matrix operations, unlocking massive efficiency gains on hardware accelerators. We deploy STATIC on a large-scale industrial video recommendation platform serving billions of users. STATIC produces significant product metric impact with minimal latency overhead (0.033 ms per step and 0.25% of inference time), achieving a 948x speedup over a CPU trie implementation and a 47-1033x speedup over a hardware-accelerated binary-search baseline. Furthermore, the runtime overhead of STATIC remains extremely low across a wide range of practical configurations. To the best of our knowledge, STATIC enables the first production-scale deployment of strictly constrained generative retrieval. In addition, evaluation on academic benchmarks demonstrates that STATIC can considerably improve cold-start performance for generative retrieval. Our code is available at https://github.com/youtube/static-constraint-decoding.
PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
Serendipitous Recommendation with Multimodal LLM
Jun 09, 2025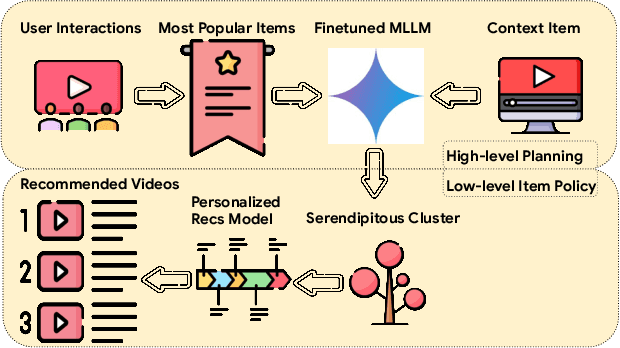
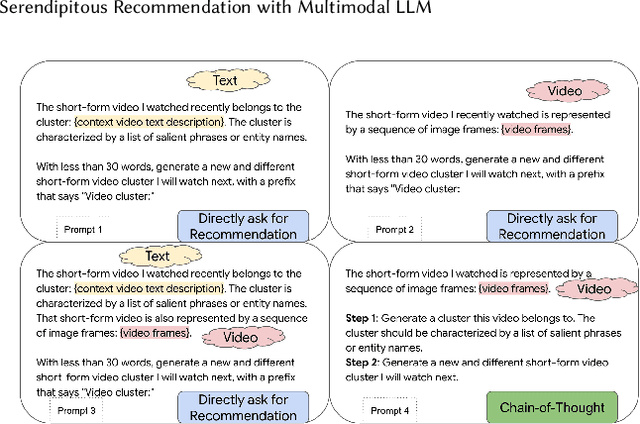
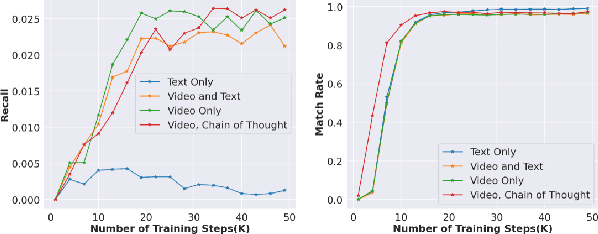
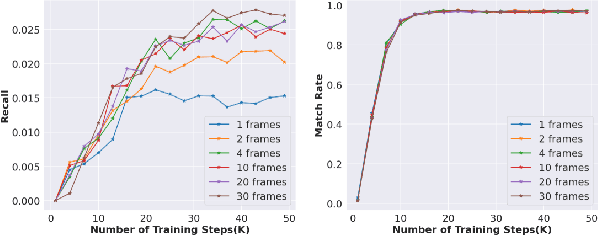
Conventional recommendation systems succeed in identifying relevant content but often fail to provide users with surprising or novel items. Multimodal Large Language Models (MLLMs) possess the world knowledge and multimodal understanding needed for serendipity, but their integration into billion-item-scale platforms presents significant challenges. In this paper, we propose a novel hierarchical framework where fine-tuned MLLMs provide high-level guidance to conventional recommendation models, steering them towards more serendipitous suggestions. This approach leverages MLLM strengths in understanding multimodal content and user interests while retaining the efficiency of traditional models for item-level recommendation. This mitigates the complexity of applying MLLMs directly to vast action spaces. We also demonstrate a chain-of-thought strategy enabling MLLMs to discover novel user interests by first understanding video content and then identifying relevant yet unexplored interest clusters. Through live experiments within a commercial short-form video platform serving billions of users, we show that our MLLM-powered approach significantly improves both recommendation serendipity and user satisfaction.
User Feedback Alignment for LLM-powered Exploration in Large-scale Recommendation Systems
Apr 07, 2025Exploration, the act of broadening user experiences beyond their established preferences, is challenging in large-scale recommendation systems due to feedback loops and limited signals on user exploration patterns. Large Language Models (LLMs) offer potential by leveraging their world knowledge to recommend novel content outside these loops. A key challenge is aligning LLMs with user preferences while preserving their knowledge and reasoning. While using LLMs to plan for the next novel user interest, this paper introduces a novel approach combining hierarchical planning with LLM inference-time scaling to improve recommendation relevancy without compromising novelty. We decouple novelty and user-alignment, training separate LLMs for each objective. We then scale up the novelty-focused LLM's inference and select the best-of-n predictions using the user-aligned LLM. Live experiments demonstrate efficacy, showing significant gains in both user satisfaction (measured by watch activity and active user counts) and exploration diversity.
STAR: A Simple Training-free Approach for Recommendations using Large Language Models
Oct 21, 2024Recent progress in large language models (LLMs) offers promising new approaches for recommendation system (RecSys) tasks. While the current state-of-the-art methods rely on fine-tuning LLMs to achieve optimal results, this process is costly and introduces significant engineering complexities. Conversely, methods that bypass fine-tuning and use LLMs directly are less resource-intensive but often fail to fully capture both semantic and collaborative information, resulting in sub-optimal performance compared to their fine-tuned counterparts. In this paper, we propose a Simple Training-free Approach for Recommendation (STAR), a framework that utilizes LLMs and can be applied to various recommendation tasks without the need for fine-tuning. Our approach involves a retrieval stage that uses semantic embeddings from LLMs combined with collaborative user information to retrieve candidate items. We then apply an LLM for pairwise ranking to enhance next-item prediction. Experimental results on the Amazon Review dataset show competitive performance for next item prediction, even with our retrieval stage alone. Our full method achieves Hits@10 performance of +23.8% on Beauty, +37.5% on Toys and Games, and -1.8% on Sports and Outdoors relative to the best supervised models. This framework offers an effective alternative to traditional supervised models, highlighting the potential of LLMs in recommendation systems without extensive training or custom architectures.
Bridging the Gap: Unpacking the Hidden Challenges in Knowledge Distillation for Online Ranking Systems
Aug 26, 2024Knowledge Distillation (KD) is a powerful approach for compressing a large model into a smaller, more efficient model, particularly beneficial for latency-sensitive applications like recommender systems. However, current KD research predominantly focuses on Computer Vision (CV) and NLP tasks, overlooking unique data characteristics and challenges inherent to recommender systems. This paper addresses these overlooked challenges, specifically: (1) mitigating data distribution shifts between teacher and student models, (2) efficiently identifying optimal teacher configurations within time and budgetary constraints, and (3) enabling computationally efficient and rapid sharing of teacher labels to support multiple students. We present a robust KD system developed and rigorously evaluated on multiple large-scale personalized video recommendation systems within Google. Our live experiment results demonstrate significant improvements in student model performance while ensuring consistent and reliable generation of high quality teacher labels from a continuous data stream of data.