 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoHAS: Differentiable Hyper-parameter and Architecture Search
Jun 05, 2020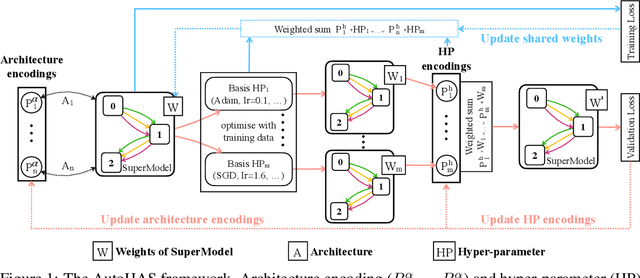
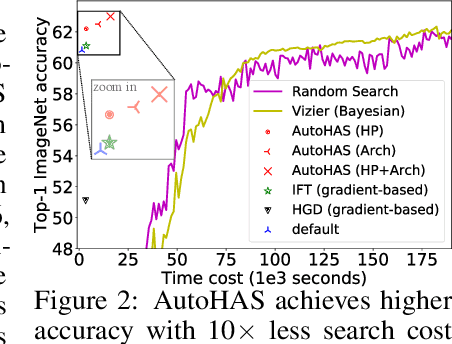
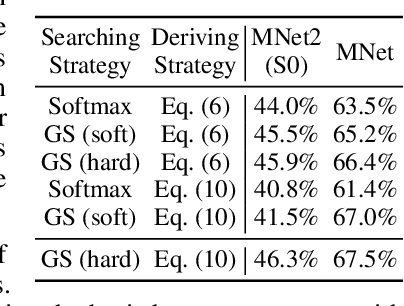
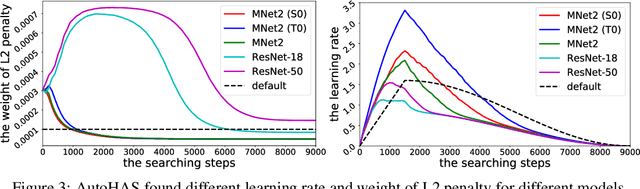
Neural Architecture Search (NAS) has achieved significant progress in pushing state-of-the-art performance. While previous NAS methods search for different network architectures with the same hyper-parameters, we argue that such search would lead to sub-optimal results. We empirically observe that different architectures tend to favor their own hyper-parameters. In this work, we extend NAS to a broader and more practical space by combining hyper-parameter and architecture search. As architecture choices are often categorical whereas hyper-parameter choices are often continuous, a critical challenge here is how to handle these two types of values in a joint search space. To tackle this challenge, we propose AutoHAS, a differentiable hyper-parameter and architecture search approach, with the idea of discretizing the continuous space into a linear combination of multiple categorical basis. A key element of AutoHAS is the use of weight sharing across all architectures and hyper-parameters which enables efficient search over the large joint search space. Experimental results on MobileNet/ResNet/EfficientNet/BERT show that AutoHAS significantly improves accuracy up to 2% on ImageNet and F1 score up to 0.4 on SQuAD 1.1, with search cost comparable to training a single model. Compared to other AutoML methods, such as random search or Bayesian methods, AutoHAS can achieve better accuracy with 10x less compute cost.
When Ensembling Smaller Models is More Efficient than Single Large Models
May 01, 2020


Ensembling is a simple and popular technique for boosting evaluation performance by training multiple models (e.g., with different initializations) and aggregating their predictions. This approach is commonly reserved for the largest models, as it is commonly held that increasing the model size provides a more substantial reduction in error than ensembling smaller models. However, we show results from experiments on CIFAR-10 and ImageNet that ensembles can outperform single models with both higher accuracy and requiring fewer total FLOPs to compute, even when those individual models' weights and hyperparameters are highly optimized. Furthermore, this gap in improvement widens as models become large. This presents an interesting observation that output diversity in ensembling can often be more efficient than training larger models, especially when the models approach the size of what their dataset can foster. Instead of using the common practice of tuning a single large model, one can use ensembles as a more flexible trade-off between a model's inference speed and accuracy. This also potentially eases hardware design, e.g., an easier way to parallelize the model across multiple workers for real-time or distributed inference.
MobileDets: Searching for Object Detection Architectures for Mobile Accelerators
Apr 30, 2020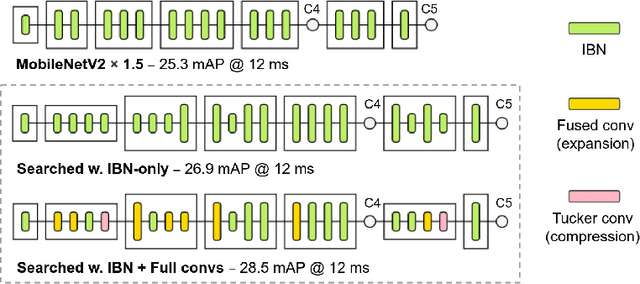
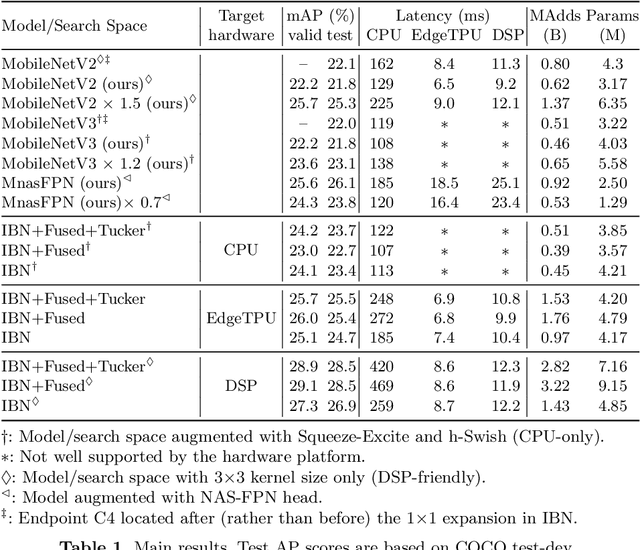
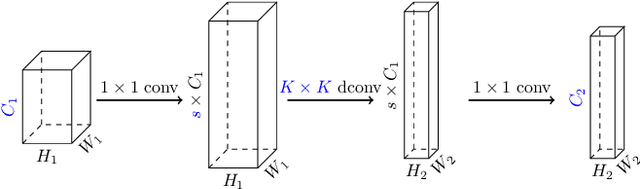
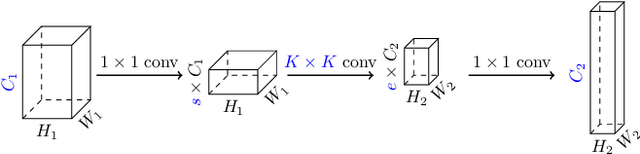
Inverted bottleneck layers, which are built upon depthwise convolutions, have been the predominant building blocks in state-of-the-art object detection models on mobile devices. In this work, we question the optimality of this design pattern over a broad range of mobile accelerators by revisiting the usefulness of regular convolutions. We achieve substantial improvements in the latency-accuracy trade-off by incorporating regular convolutions in the search space, and effectively placing them in the network via neural architecture search. We obtain a family of object detection models, MobileDets, that achieve state-of-the-art results across mobile accelerators. On the COCO object detection task, MobileDets outperform MobileNetV3+SSDLite by 1.7 mAP at comparable mobile CPU inference latencies. MobileDets also outperform MobileNetV2+SSDLite by 1.9 mAP on mobile CPUs, 3.7 mAP on EdgeTPUs and 3.4 mAP on DSPs while running equally fast. Moreover, MobileDets are comparable with the state-of-the-art MnasFPN on mobile CPUs even without using the feature pyramid, and achieve better mAP scores on both EdgeTPUs and DSPs with up to 2X speedup.
BigNAS: Scaling Up Neural Architecture Search with Big Single-Stage Models
Mar 24, 2020
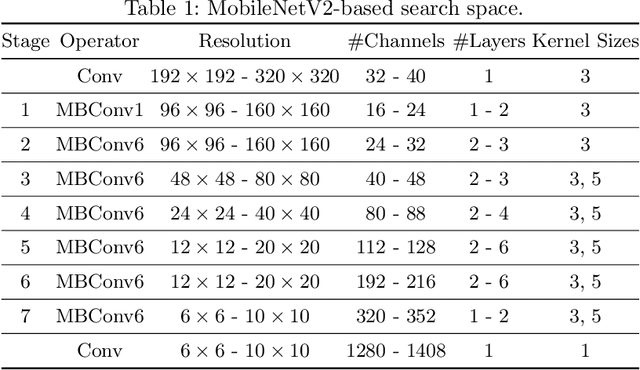
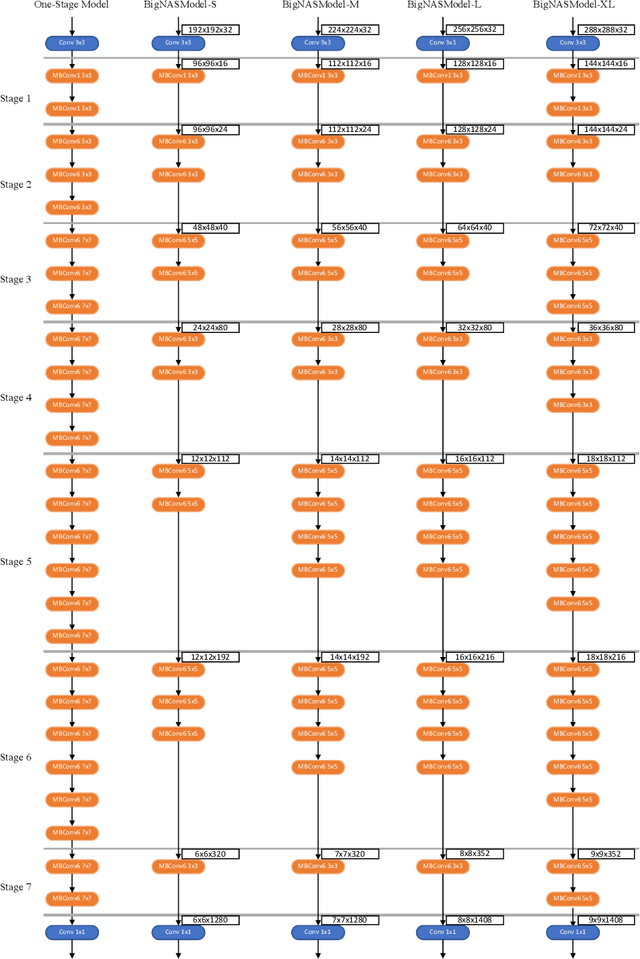
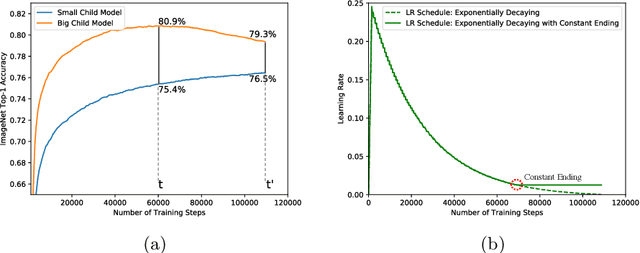
Neural architecture search (NAS) has shown promising results discovering models that are both accurate and fast. For NAS, training a one-shot model has become a popular strategy to rank the relative quality of different architectures (child models) using a single set of shared weights. However, while one-shot model weights can effectively rank different network architectures, the absolute accuracies from these shared weights are typically far below those obtained from stand-alone training. To compensate, existing methods assume that the weights must be retrained, finetuned, or otherwise post-processed after the search is completed. These steps significantly increase the compute requirements and complexity of the architecture search and model deployment. In this work, we propose BigNAS, an approach that challenges the conventional wisdom that post-processing of the weights is necessary to get good prediction accuracies. Without extra retraining or post-processing steps, we are able to train a single set of shared weights on ImageNet and use these weights to obtain child models whose sizes range from 200 to 1000 MFLOPs. Our discovered model family, BigNASModels, achieve top-1 accuracies ranging from 76.5% to 80.9%, surpassing state-of-the-art models in this range including EfficientNets and Once-for-All networks without extra retraining or post-processing. We present ablative study and analysis to further understand the proposed BigNASModels.
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
Dec 10, 2019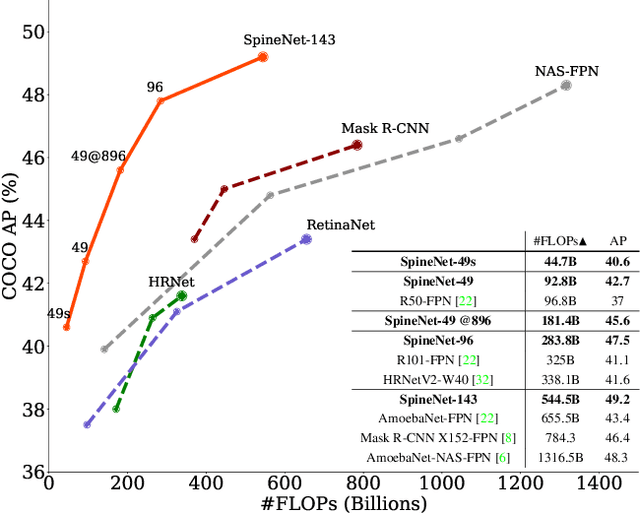
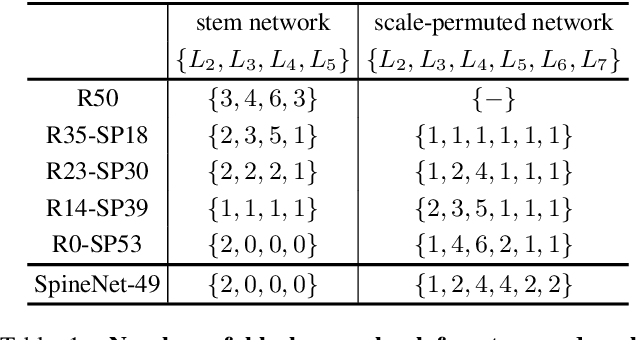
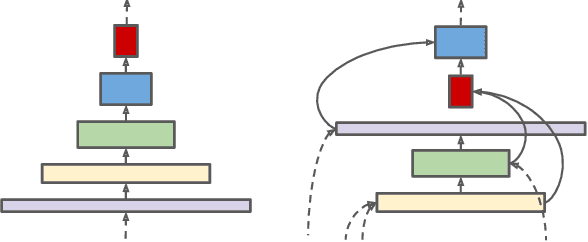
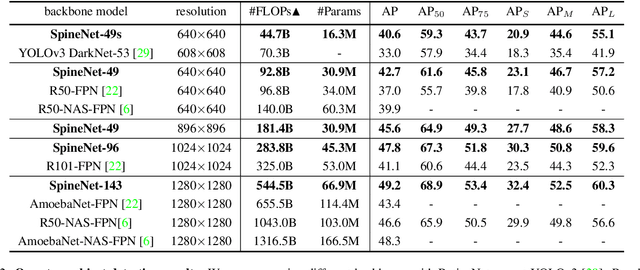
Convolutional neural networks typically encode an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that is learned on an object detection task by Neural Architecture Search. SpineNet achieves state-of-the-art performance of one-stage object detector on COCO with 60% less computation, and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
Adversarial Examples Improve Image Recognition
Nov 21, 2019
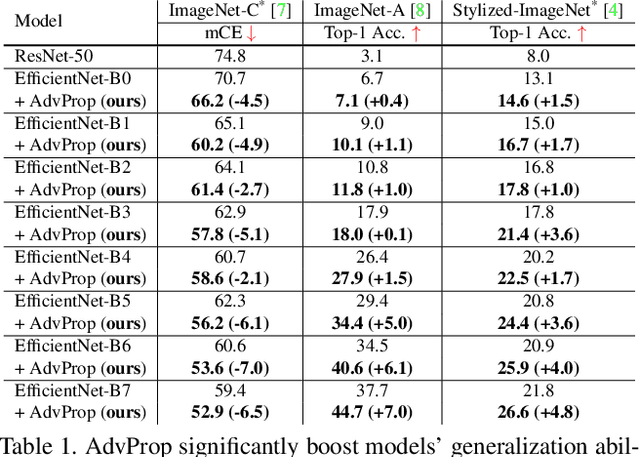
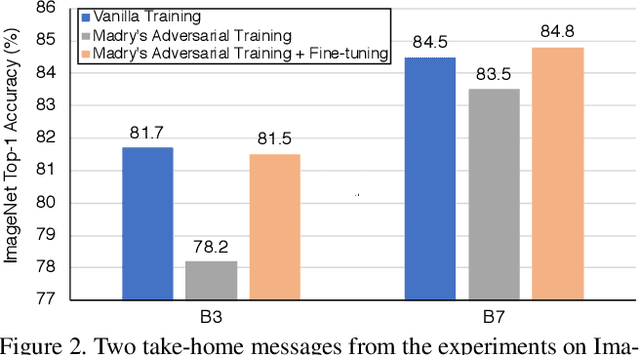
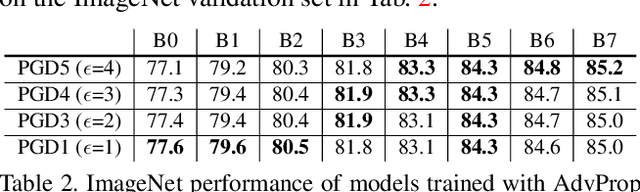
Adversarial examples are commonly viewed as a threat to ConvNets. Here we present an opposite perspective: adversarial examples can be used to improve image recognition models if harnessed in the right manner. We propose AdvProp, an enhanced adversarial training scheme which treats adversarial examples as additional examples, to prevent overfitting. Key to our method is the usage of a separate auxiliary batch norm for adversarial examples, as they have different underlying distributions to normal examples. We show that AdvProp improves a wide range of models on various image recognition tasks and performs better when the models are bigger. For instance, by applying AdvProp to the latest EfficientNet-B7 [28] on ImageNet, we achieve significant improvements on ImageNet (+0.7%), ImageNet-C (+6.5%), ImageNet-A (+7.0%), Stylized-ImageNet (+4.8%). With an enhanced EfficientNet-B8, our method achieves the state-of-the-art 85.5% ImageNet top-1 accuracy without extra data. This result even surpasses the best model in [20] which is trained with 3.5B Instagram images (~3000X more than ImageNet) and ~9.4X more parameters. Models are available at https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet.
Search to Distill: Pearls are Everywhere but not the Eyes
Nov 20, 2019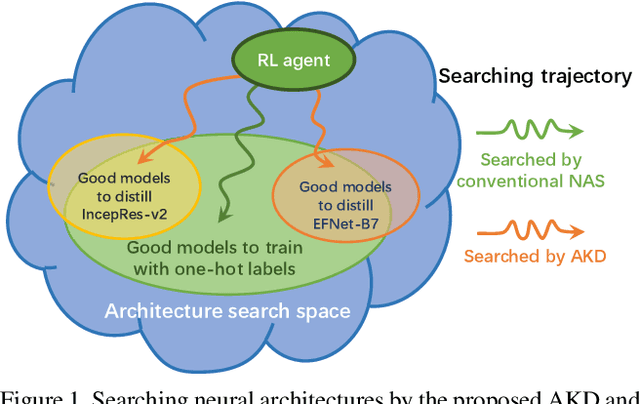
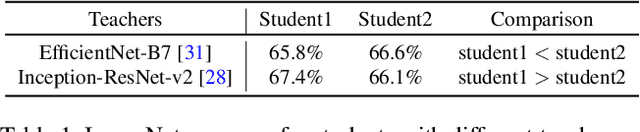
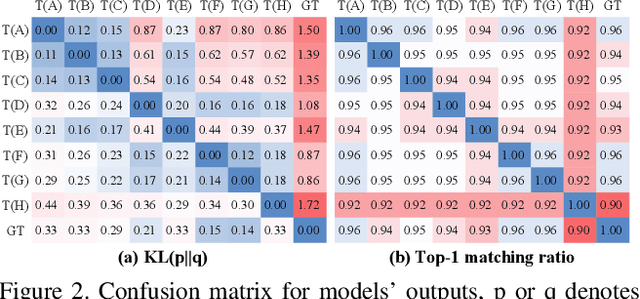
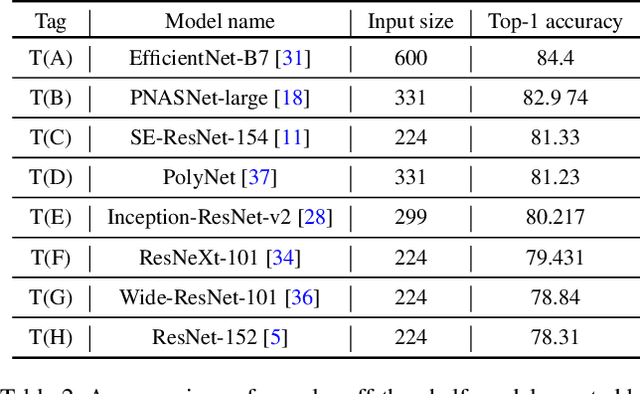
Standard Knowledge Distillation (KD) approaches distill the knowledge of a cumbersome teacher model into the parameters of a student model with a pre-defined architecture. However, the knowledge of a neural network, which is represented by the network's output distribution conditioned on its input, depends not only on its parameters but also on its architecture. Hence, a more generalized approach for KD is to distill the teacher's knowledge into both the parameters and architecture of the student. To achieve this, we present a new Architecture-aware Knowledge Distillation (AKD) approach that finds student models (pearls for the teacher) that are best for distilling the given teacher model. In particular, we leverage Neural Architecture Search (NAS), equipped with our KD-guided reward, to search for the best student architectures for a given teacher. Experimental results show our proposed AKD consistently outperforms the conventional NAS plus KD approach, and achieves state-of-the-art results on the ImageNet classification task under various latency settings. Furthermore, the best AKD student architecture for the ImageNet classification task also transfers well to other tasks such as million level face recognition and ensemble learning.
EfficientDet: Scalable and Efficient Object Detection
Nov 20, 2019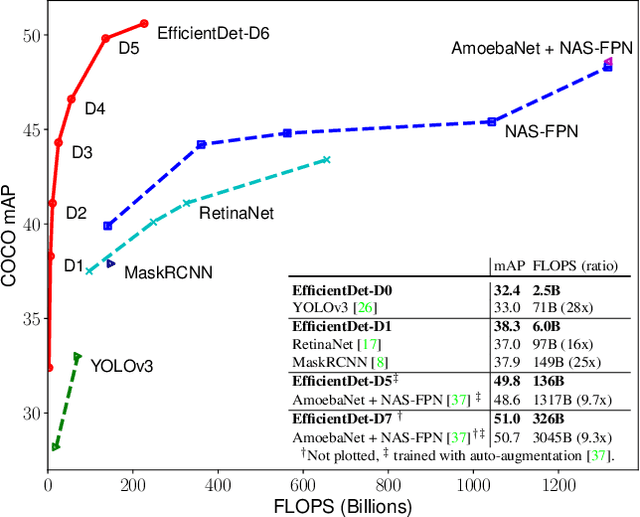
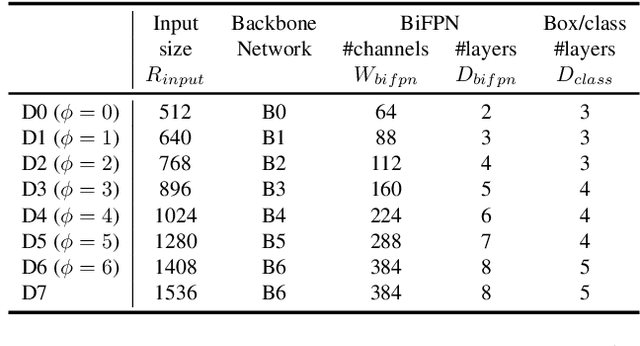
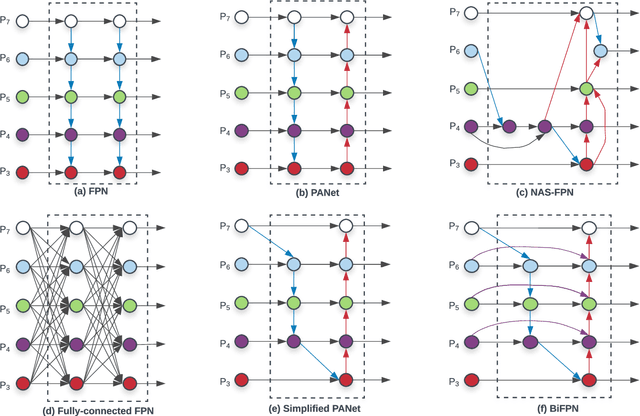
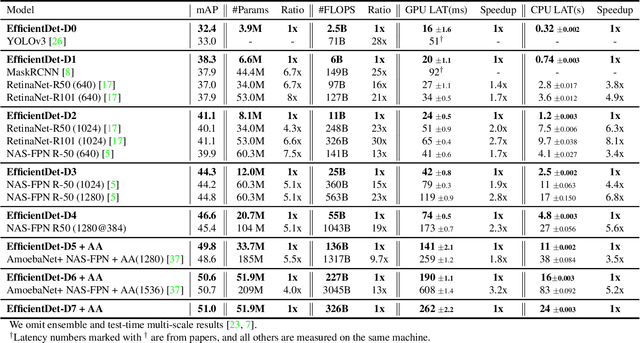
Model efficiency has become increasingly important in computer vision. In this paper, we systematically study various neural network architecture design choices for object detection and propose several key optimizations to improve efficiency. First, we propose a weighted bi-directional feature pyramid network (BiFPN), which allows easy and fast multi-scale feature fusion; Second, we propose a compound scaling method that uniformly scales the resolution, depth, and width for all backbone, feature network, and box/class prediction networks at the same time. Based on these optimizations, we have developed a new family of object detectors, called EfficientDet, which consistently achieve an order-of-magnitude better efficiency than prior art across a wide spectrum of resource constraints. In particular, without bells and whistles, our EfficientDet-D7 achieves stateof-the-art 51.0 mAP on COCO dataset with 52M parameters and 326B FLOPS1 , being 4x smaller and using 9.3x fewer FLOPS yet still more accurate (+0.3% mAP) than the best previous detector.
MixConv: Mixed Depthwise Convolutional Kernels
Aug 01, 2019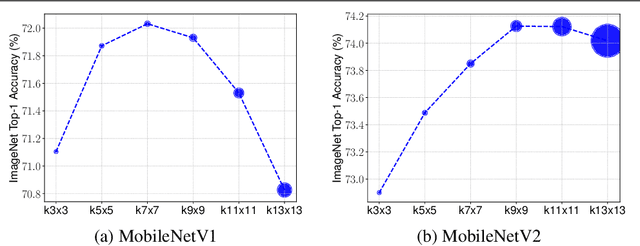
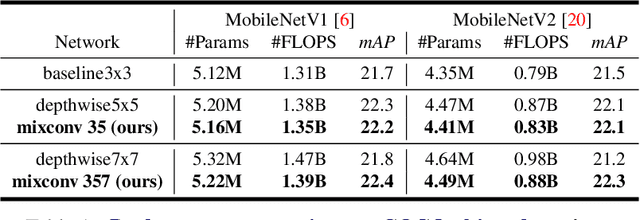
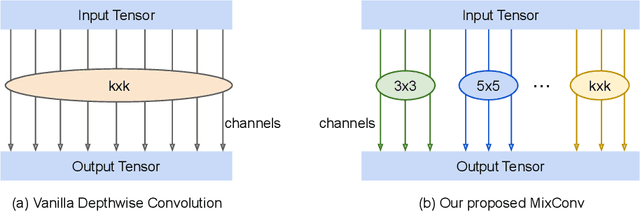
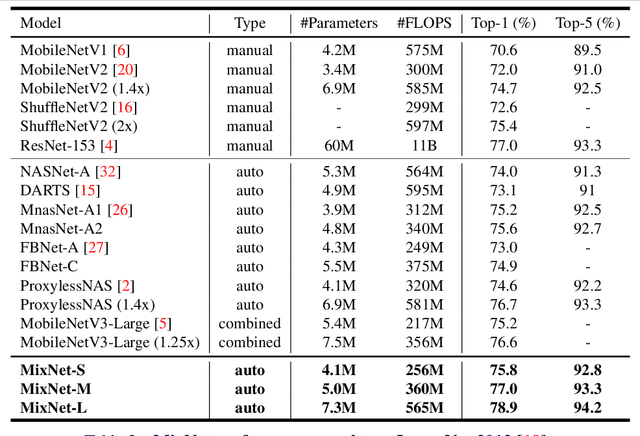
Depthwise convolution is becoming increasingly popular in modern efficient ConvNets, but its kernel size is often overlooked. In this paper, we systematically study the impact of different kernel sizes, and observe that combining the benefits of multiple kernel sizes can lead to better accuracy and efficiency. Based on this observation, we propose a new mixed depthwise convolution (MixConv), which naturally mixes up multiple kernel sizes in a single convolution. As a simple drop-in replacement of vanilla depthwise convolution, our MixConv improves the accuracy and efficiency for existing MobileNets on both ImageNet classification and COCO object detection. To demonstrate the effectiveness of MixConv, we integrate it into AutoML search space and develop a new family of models, named as MixNets, which outperform previous mobile models including MobileNetV2 [20] (ImageNet top-1 accuracy +4.2%), ShuffleNetV2 [16] (+3.5%), MnasNet [26] (+1.3%), ProxylessNAS [2] (+2.2%), and FBNet [27] (+2.0%). In particular, our MixNet-L achieves a new state-of-the-art 78.9% ImageNet top-1 accuracy under typical mobile settings (<600M FLOPS). Code is at https://github.com/ tensorflow/tpu/tree/master/models/official/mnasnet/mixnet
* Published in BMVC 2019
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Jun 10, 2019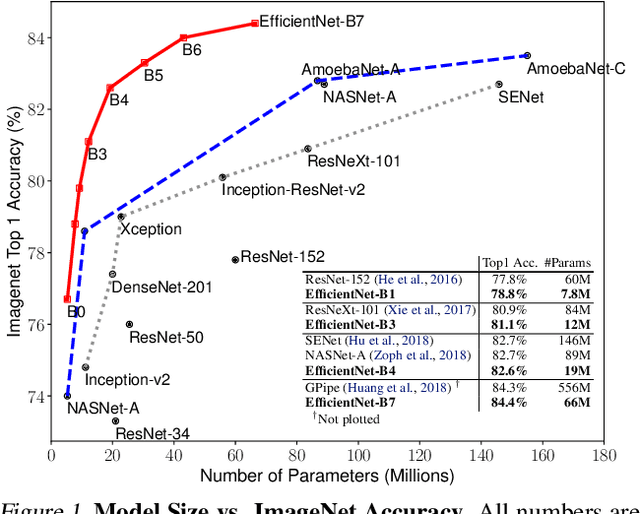
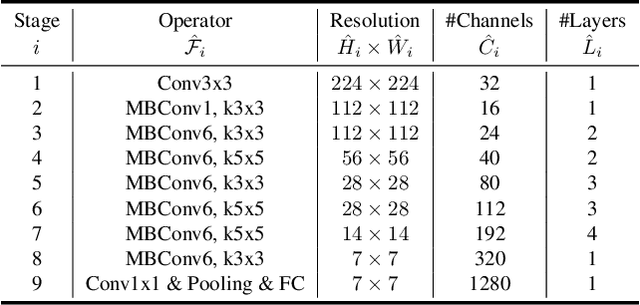
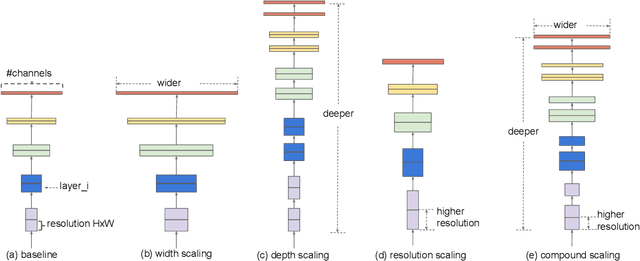
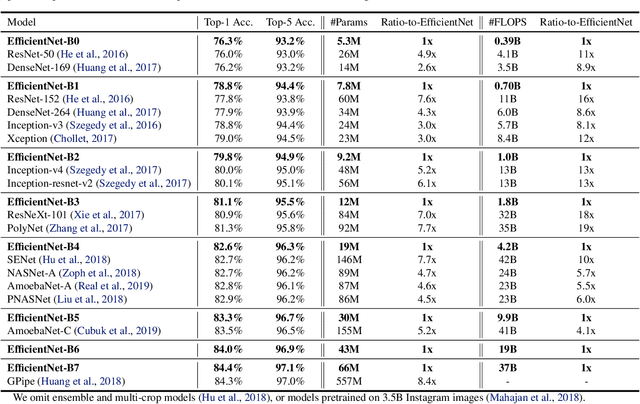
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet. To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.4% top-1 / 97.1% top-5 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters. Source code is at https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet.
* Published in ICML 2019