 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingqiang Wei
SPCNet: Stepwise Point Cloud Completion Network
Sep 05, 2022

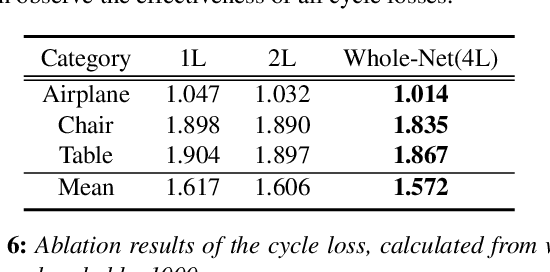
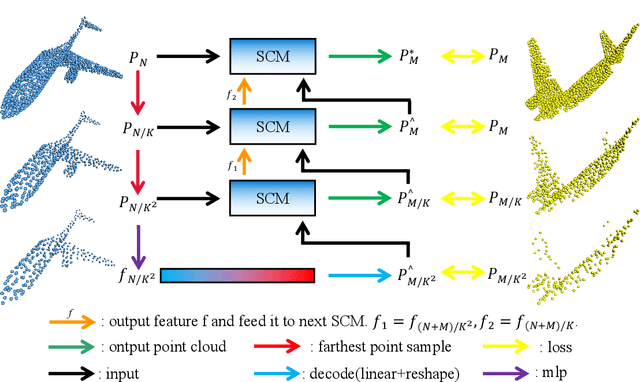
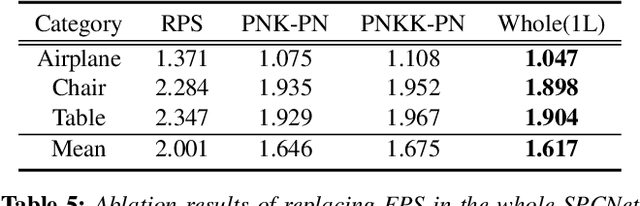
How will you repair a physical object with large missings? You may first recover its global yet coarse shape and stepwise increase its local details. We are motivated to imitate the above physical repair procedure to address the point cloud completion task. We propose a novel stepwise point cloud completion network (SPCNet) for various 3D models with large missings. SPCNet has a hierarchical bottom-to-up network architecture. It fulfills shape completion in an iterative manner, which 1) first infers the global feature of the coarse result; 2) then infers the local feature with the aid of global feature; and 3) finally infers the detailed result with the help of local feature and coarse result. Beyond the wisdom of simulating the physical repair, we newly design a cycle loss %based training strategy to enhance the generalization and robustness of SPCNet. Extensive experiments clearly show the superiority of our SPCNet over the state-of-the-art methods on 3D point clouds with large missings.
TogetherNet: Bridging Image Restoration and Object Detection Together via Dynamic Enhancement Learning
Sep 03, 2022
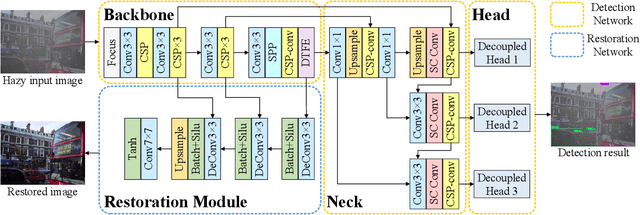
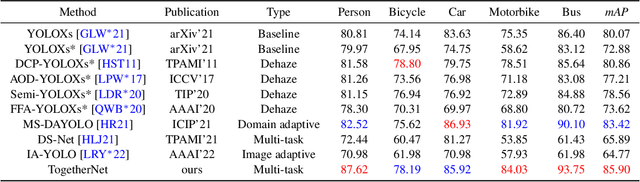
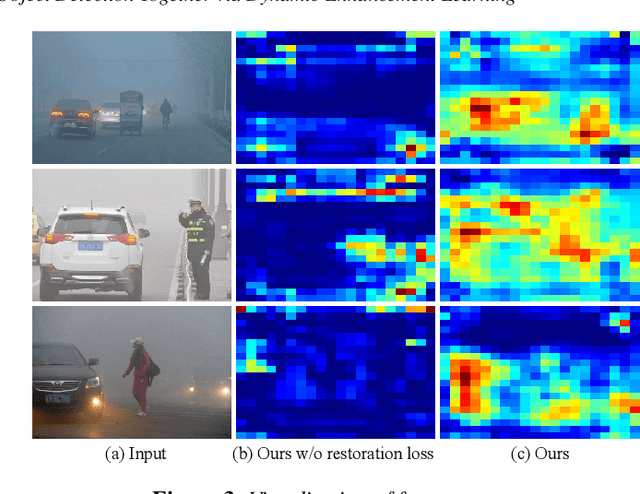
Adverse weather conditions such as haze, rain, and snow often impair the quality of captured images, causing detection networks trained on normal images to generalize poorly in these scenarios. In this paper, we raise an intriguing question - if the combination of image restoration and object detection, can boost the performance of cutting-edge detectors in adverse weather conditions. To answer it, we propose an effective yet unified detection paradigm that bridges these two subtasks together via dynamic enhancement learning to discern objects in adverse weather conditions, called TogetherNet. Different from existing efforts that intuitively apply image dehazing/deraining as a pre-processing step, TogetherNet considers a multi-task joint learning problem. Following the joint learning scheme, clean features produced by the restoration network can be shared to learn better object detection in the detection network, thus helping TogetherNet enhance the detection capacity in adverse weather conditions. Besides the joint learning architecture, we design a new Dynamic Transformer Feature Enhancement module to improve the feature extraction and representation capabilities of TogetherNet. Extensive experiments on both synthetic and real-world datasets demonstrate that our TogetherNet outperforms the state-of-the-art detection approaches by a large margin both quantitatively and qualitatively. Source code is available at https://github.com/yz-wang/TogetherNet.
Contrastive Semantic-Guided Image Smoothing Network
Sep 02, 2022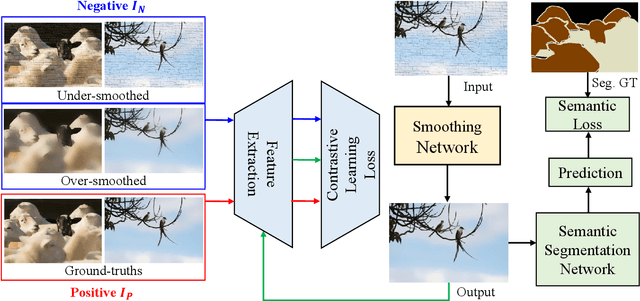
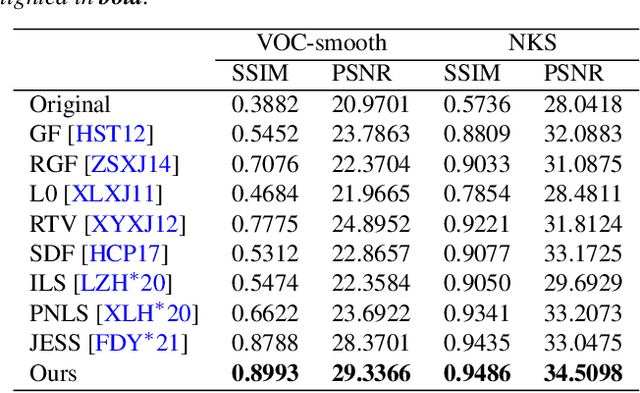
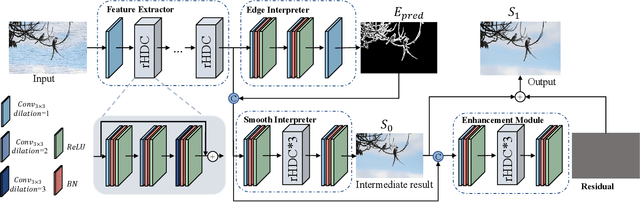

Image smoothing is a fundamental low-level vision task that aims to preserve salient structures of an image while removing insignificant details. Deep learning has been explored in image smoothing to deal with the complex entanglement of semantic structures and trivial details. However, current methods neglect two important facts in smoothing: 1) naive pixel-level regression supervised by the limited number of high-quality smoothing ground-truth could lead to domain shift and cause generalization problems towards real-world images; 2) texture appearance is closely related to object semantics, so that image smoothing requires awareness of semantic difference to apply adaptive smoothing strengths. To address these issues, we propose a novel Contrastive Semantic-Guided Image Smoothing Network (CSGIS-Net) that combines both contrastive prior and semantic prior to facilitate robust image smoothing. The supervision signal is augmented by leveraging undesired smoothing effects as negative teachers, and by incorporating segmentation tasks to encourage semantic distinctiveness. To realize the proposed network, we also enrich the original VOC dataset with texture enhancement and smoothing labels, namely VOC-smooth, which first bridges image smoothing and semantic segmentation. Extensive experiments demonstrate that the proposed CSGIS-Net outperforms state-of-the-art algorithms by a large margin. Code and dataset are available at https://github.com/wangjie6866/CSGIS-Net.
Geometric and Learning-based Mesh Denoising: A Comprehensive Survey
Sep 02, 2022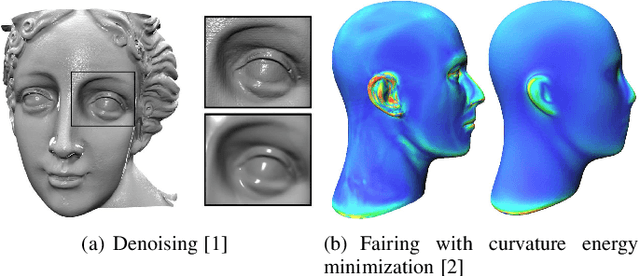

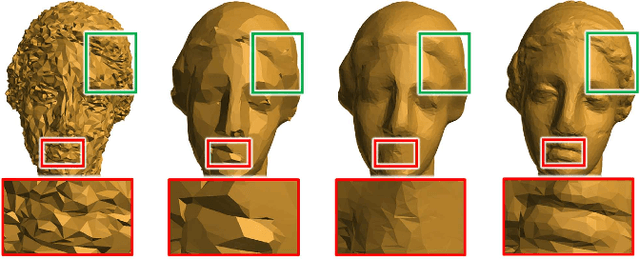
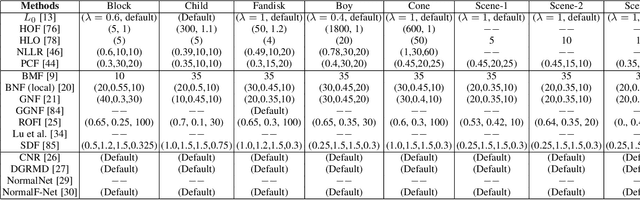
Mesh denoising is a fundamental problem in digital geometry processing. It seeks to remove surface noise, while preserving surface intrinsic signals as accurately as possible. While the traditional wisdom has been built upon specialized priors to smooth surfaces, learning-based approaches are making their debut with great success in generalization and automation. In this work, we provide a comprehensive review of the advances in mesh denoising, containing both traditional geometric approaches and recent learning-based methods. First, to familiarize readers with the denoising tasks, we summarize four common issues in mesh denoising. We then provide two categorizations of the existing denoising methods. Furthermore, three important categories, including optimization-, filter-, and data-driven-based techniques, are introduced and analyzed in detail, respectively. Both qualitative and quantitative comparisons are illustrated, to demonstrate the effectiveness of the state-of-the-art denoising methods. Finally, potential directions of future work are pointed out to solve the common problems of these approaches. A mesh denoising benchmark is also built in this work, and future researchers will easily and conveniently evaluate their methods with the state-of-the-art approaches.
MODNet: Multi-offset Point Cloud Denoising Network Customized for Multi-scale Patches
Sep 01, 2022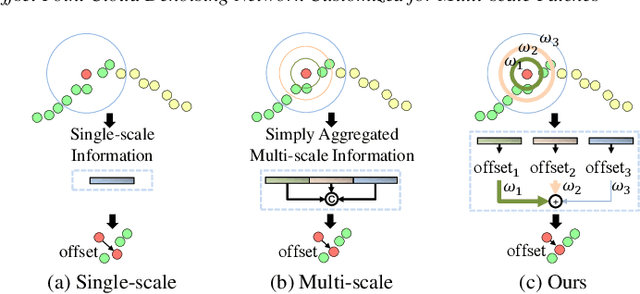
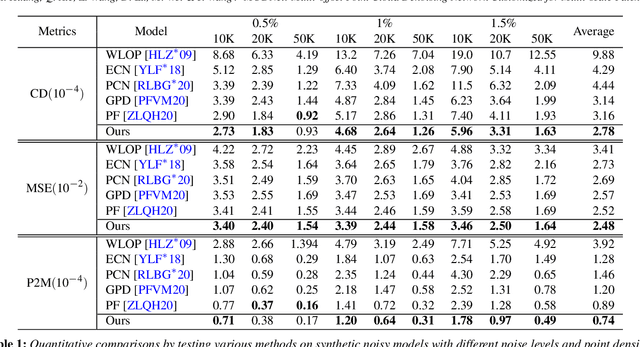
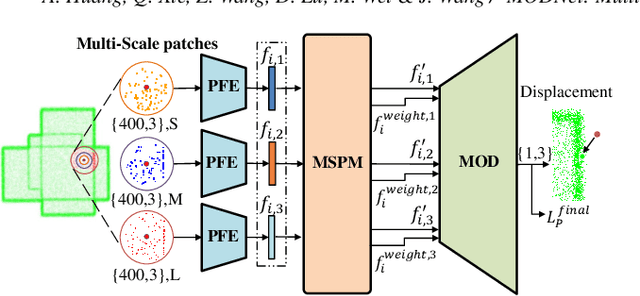
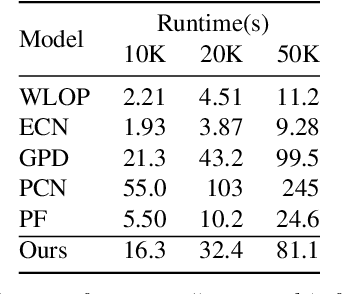
The intricacy of 3D surfaces often results cutting-edge point cloud denoising (PCD) models in surface degradation including remnant noise, wrongly-removed geometric details. Although using multi-scale patches to encode the geometry of a point has become the common wisdom in PCD, we find that simple aggregation of extracted multi-scale features can not adaptively utilize the appropriate scale information according to the geometric information around noisy points. It leads to surface degradation, especially for points close to edges and points on complex curved surfaces. We raise an intriguing question -- if employing multi-scale geometric perception information to guide the network to utilize multi-scale information, can eliminate the severe surface degradation problem? To answer it, we propose a Multi-offset Denoising Network (MODNet) customized for multi-scale patches. First, we extract the low-level feature of three scales patches by patch feature encoders. Second, a multi-scale perception module is designed to embed multi-scale geometric information for each scale feature and regress multi-scale weights to guide a multi-offset denoising displacement. Third, a multi-offset decoder regresses three scale offsets, which are guided by the multi-scale weights to predict the final displacement by weighting them adaptively. Experiments demonstrate that our method achieves new state-of-the-art performance on both synthetic and real-scanned datasets.
3DLG-Detector: 3D Object Detection via Simultaneous Local-Global Feature Learning
Aug 31, 2022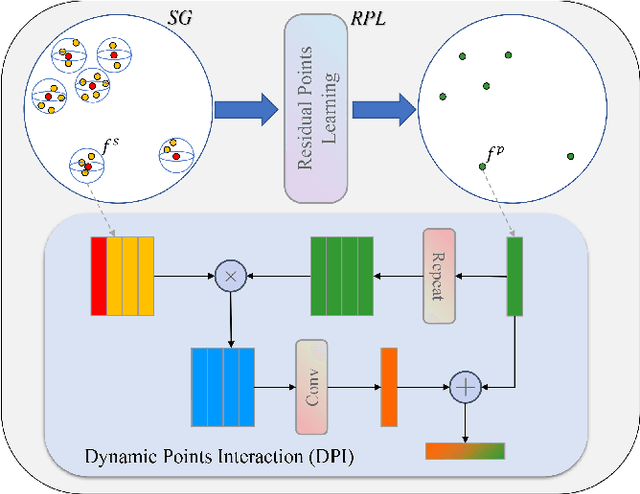
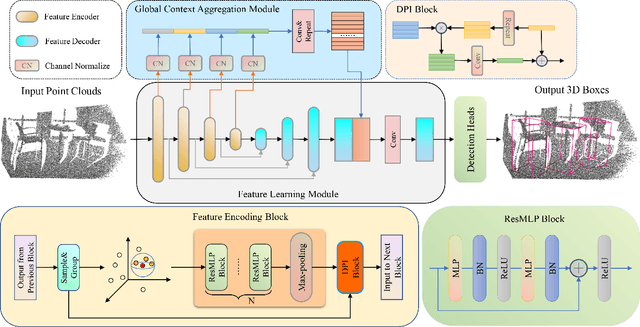
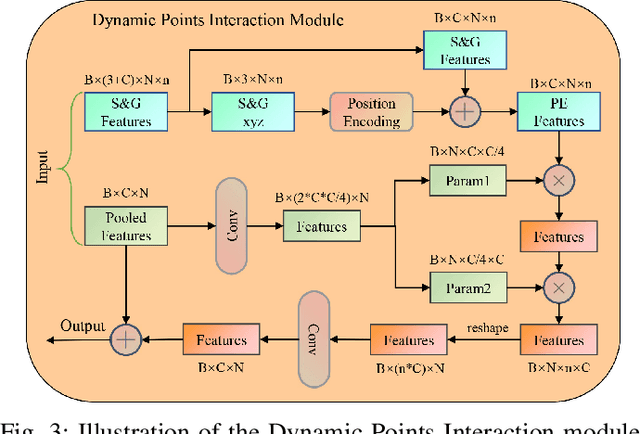

Capturing both local and global features of irregular point clouds is essential to 3D object detection (3OD). However, mainstream 3D detectors, e.g., VoteNet and its variants, either abandon considerable local features during pooling operations or ignore many global features in the whole scene context. This paper explores new modules to simultaneously learn local-global features of scene point clouds that serve 3OD positively. To this end, we propose an effective 3OD network via simultaneous local-global feature learning (dubbed 3DLG-Detector). 3DLG-Detector has two key contributions. First, it develops a Dynamic Points Interaction (DPI) module that preserves effective local features during pooling. Besides, DPI is detachable and can be incorporated into existing 3OD networks to boost their performance. Second, it develops a Global Context Aggregation module to aggregate multi-scale features from different layers of the encoder to achieve scene context-awareness. Our method shows improvements over thirteen competitors in terms of detection accuracy and robustness on both the SUN RGB-D and ScanNet datasets. Source code will be available upon publication.
PV-RCNN++: Semantical Point-Voxel Feature Interaction for 3D Object Detection
Aug 29, 2022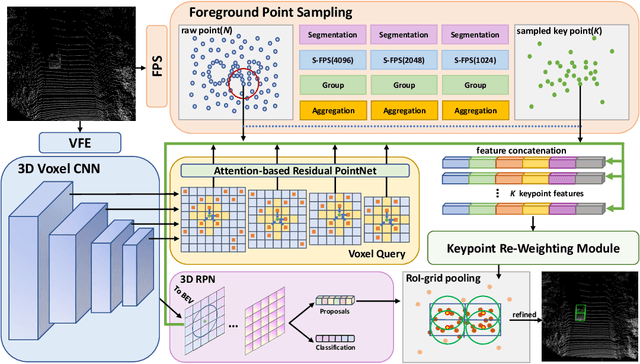
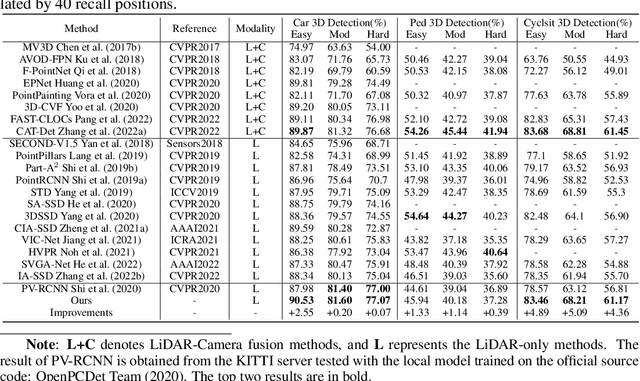
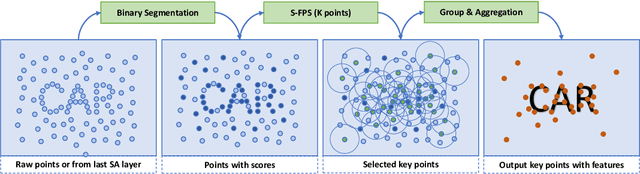
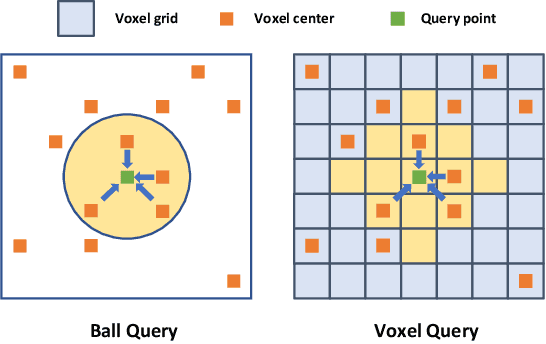
Large imbalance often exists between the foreground points (i.e., objects) and the background points in outdoor LiDAR point clouds. It hinders cutting-edge detectors from focusing on informative areas to produce accurate 3D object detection results. This paper proposes a novel object detection network by semantical point-voxel feature interaction, dubbed PV-RCNN++. Unlike most of existing methods, PV-RCNN++ explores the semantic information to enhance the quality of object detection. First, a semantic segmentation module is proposed to retain more discriminative foreground keypoints. Such a module will guide our PV-RCNN++ to integrate more object-related point-wise and voxel-wise features in the pivotal areas. Then, to make points and voxels interact efficiently, we utilize voxel query based on Manhattan distance to quickly sample voxel-wise features around keypoints. Such the voxel query will reduce the time complexity from O(N) to O(K), compared to the ball query. Further, to avoid being stuck in learning only local features, an attention-based residual PointNet module is designed to expand the receptive field to adaptively aggregate the neighboring voxel-wise features into keypoints. Extensive experiments on the KITTI dataset show that PV-RCNN++ achieves 81.60$\%$, 40.18$\%$, 68.21$\%$ 3D mAP on Car, Pedestrian, and Cyclist, achieving comparable or even better performance to the state-of-the-arts.
SO(3)-Pose: SO(3)-Equivariance Learning for 6D Object Pose Estimation
Aug 17, 2022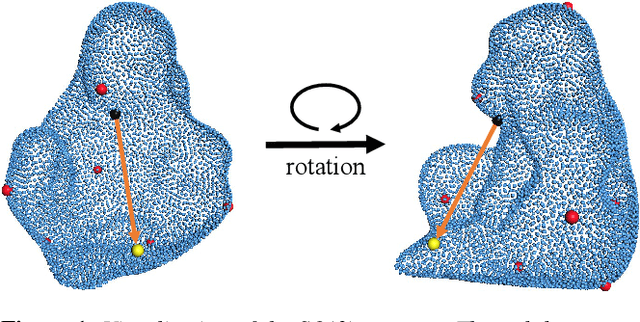
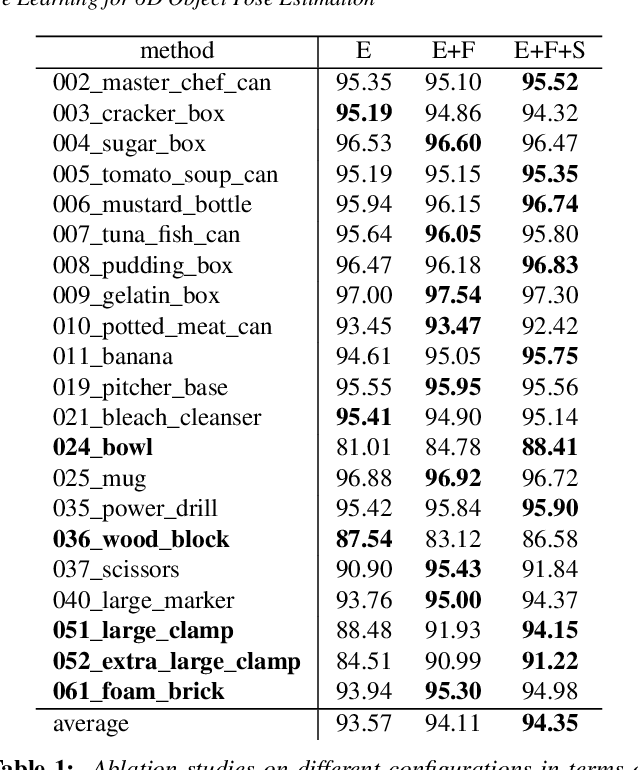

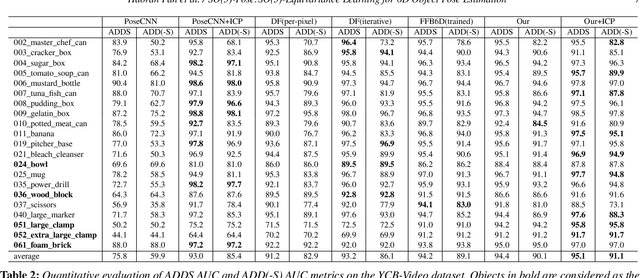
6D pose estimation of rigid objects from RGB-D images is crucial for object grasping and manipulation in robotics. Although RGB channels and the depth (D) channel are often complementary, providing respectively the appearance and geometry information, it is still non-trivial how to fully benefit from the two cross-modal data. From the simple yet new observation, when an object rotates, its semantic label is invariant to the pose while its keypoint offset direction is variant to the pose. To this end, we present SO(3)-Pose, a new representation learning network to explore SO(3)-equivariant and SO(3)-invariant features from the depth channel for pose estimation. The SO(3)-invariant features facilitate to learn more distinctive representations for segmenting objects with similar appearance from RGB channels. The SO(3)-equivariant features communicate with RGB features to deduce the (missed) geometry for detecting keypoints of an object with the reflective surface from the depth channel. Unlike most of existing pose estimation methods, our SO(3)-Pose not only implements the information communication between the RGB and depth channels, but also naturally absorbs the SO(3)-equivariance geometry knowledge from depth images, leading to better appearance and geometry representation learning. Comprehensive experiments show that our method achieves the state-of-the-art performance on three benchmarks.
UTOPIC: Uncertainty-aware Overlap Prediction Network for Partial Point Cloud Registration
Aug 12, 2022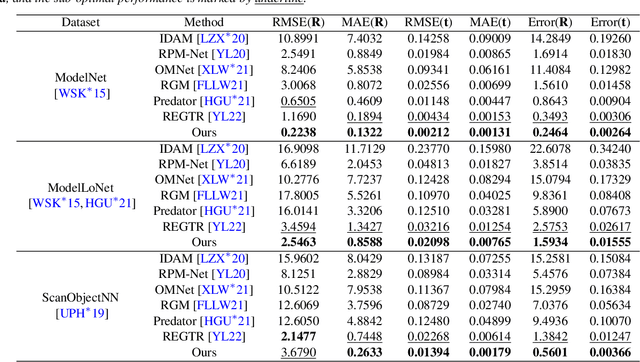
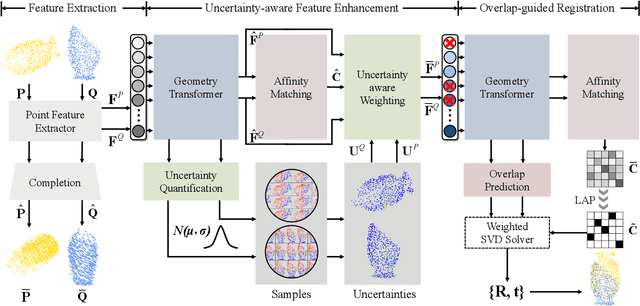
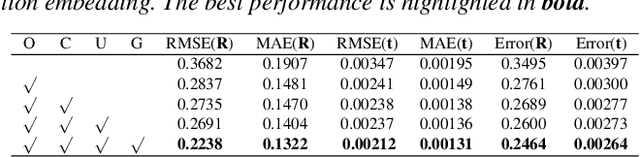
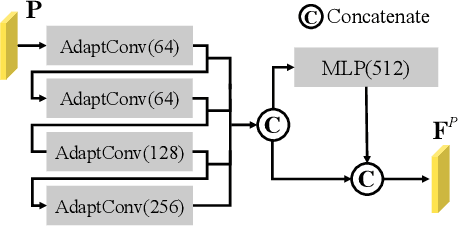
High-confidence overlap prediction and accurate correspondences are critical for cutting-edge models to align paired point clouds in a partial-to-partial manner. However, there inherently exists uncertainty between the overlapping and non-overlapping regions, which has always been neglected and significantly affects the registration performance. Beyond the current wisdom, we propose a novel uncertainty-aware overlap prediction network, dubbed UTOPIC, to tackle the ambiguous overlap prediction problem; to our knowledge, this is the first to explicitly introduce overlap uncertainty to point cloud registration. Moreover, we induce the feature extractor to implicitly perceive the shape knowledge through a completion decoder, and present a geometric relation embedding for Transformer to obtain transformation-invariant geometry-aware feature representations. With the merits of more reliable overlap scores and more precise dense correspondences, UTOPIC can achieve stable and accurate registration results, even for the inputs with limited overlapping areas. Extensive quantitative and qualitative experiments on synthetic and real benchmarks demonstrate the superiority of our approach over state-of-the-art methods.