 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxicity Detection towards Adaptability to Changing Perturbations
Dec 17, 2024Toxicity detection is crucial for maintaining the peace of the society. While existing methods perform well on normal toxic contents or those generated by specific perturbation methods, they are vulnerable to evolving perturbation patterns. However, in real-world scenarios, malicious users tend to create new perturbation patterns for fooling the detectors. For example, some users may circumvent the detector of large language models (LLMs) by adding `I am a scientist' at the beginning of the prompt. In this paper, we introduce a novel problem, i.e., continual learning jailbreak perturbation patterns, into the toxicity detection field. To tackle this problem, we first construct a new dataset generated by 9 types of perturbation patterns, 7 of them are summarized from prior work and 2 of them are developed by us. We then systematically validate the vulnerability of current methods on this new perturbation pattern-aware dataset via both the zero-shot and fine tuned cross-pattern detection. Upon this, we present the domain incremental learning paradigm and the corresponding benchmark to ensure the detector's robustness to dynamically emerging types of perturbed toxic text. Our code and dataset are provided in the appendix and will be publicly available at GitHub, by which we wish to offer new research opportunities for the security-relevant communities.
Origin-Destination Demand Prediction: An Urban Radiation and Attraction Perspective
Nov 29, 2024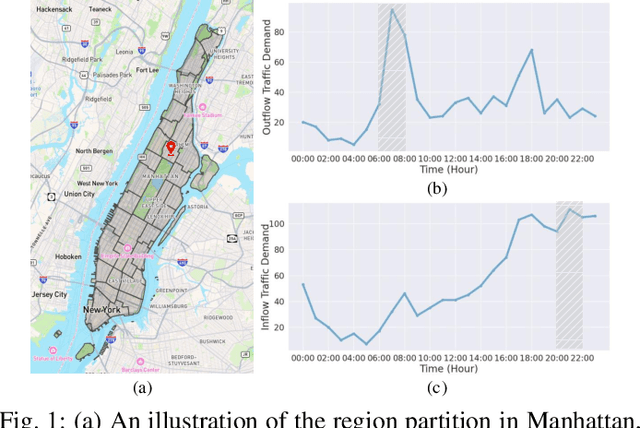
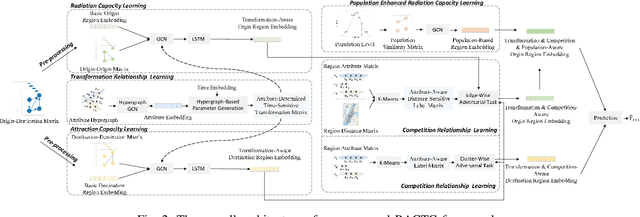
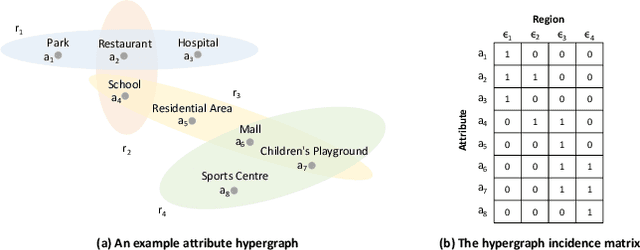
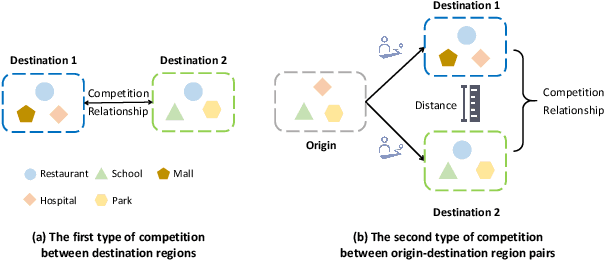
In recent years, origin-destination (OD) demand prediction has gained significant attention for its profound implications in urban development. Existing data-driven deep learning methods primarily focus on the spatial or temporal dependency between regions yet neglecting regions' fundamental functional difference. Though knowledge-driven physical methods have characterised regions' functions by their radiation and attraction capacities, these functions are defined on numerical factors like population without considering regions' intrinsic nominal attributes, e.g., a region is a residential or industrial district. Moreover, the complicated relationships between two types of capacities, e.g., the radiation capacity of a residential district in the morning will be transformed into the attraction capacity in the evening, are totally missing from physical methods. In this paper, we not only generalize the physical radiation and attraction capacities into the deep learning framework with the extended capability to fulfil regions' functions, but also present a new model that captures the relationships between two types of capacities. Specifically, we first model regions' radiation and attraction capacities using a bilateral branch network, each equipped with regions' attribute representations. We then describe the transformation relationship of different capacities of the same region using a hypergraph-based parameter generation method. We finally unveil the competition relationship of different regions with the same attraction capacity through cluster-based adversarial learning. Extensive experiments on two datasets demonstrate the consistent improvements of our method over the state-of-the-art baselines, as well as the good explainability of regions' functions using their nominal attributes.
Deep Learning Based Dense Retrieval: A Comparative Study
Oct 27, 2024



Dense retrievers have achieved state-of-the-art performance in various information retrieval tasks, but their robustness against tokenizer poisoning remains underexplored. In this work, we assess the vulnerability of dense retrieval systems to poisoned tokenizers by evaluating models such as BERT, Dense Passage Retrieval (DPR), Contriever, SimCSE, and ANCE. We find that supervised models like BERT and DPR experience significant performance degradation when tokenizers are compromised, while unsupervised models like ANCE show greater resilience. Our experiments reveal that even small perturbations can severely impact retrieval accuracy, highlighting the need for robust defenses in critical applications.
Why Does the Effective Context Length of LLMs Fall Short?
Oct 24, 2024



Advancements in distributed training and efficient attention mechanisms have significantly expanded the context window sizes of large language models (LLMs). However, recent work reveals that the effective context lengths of open-source LLMs often fall short, typically not exceeding half of their training lengths. In this work, we attribute this limitation to the left-skewed frequency distribution of relative positions formed in LLMs pretraining and post-training stages, which impedes their ability to effectively gather distant information. To address this challenge, we introduce ShifTed Rotray position embeddING (STRING). STRING shifts well-trained positions to overwrite the original ineffective positions during inference, enhancing performance within their existing training lengths. Experimental results show that without additional training, STRING dramatically improves the performance of the latest large-scale models, such as Llama3.1 70B and Qwen2 72B, by over 10 points on popular long-context benchmarks RULER and InfiniteBench, establishing new state-of-the-art results for open-source LLMs. Compared to commercial models, Llama 3.1 70B with \method even achieves better performance than GPT-4-128K and clearly surpasses Claude 2 and Kimi-chat.
Temperature-Centric Investigation of Speculative Decoding with Knowledge Distillation
Oct 14, 2024Speculative decoding stands as a pivotal technique to expedite inference in autoregressive (large) language models. This method employs a smaller draft model to speculate a block of tokens, which the target model then evaluates for acceptance. Despite a wealth of studies aimed at increasing the efficiency of speculative decoding, the influence of generation configurations on the decoding process remains poorly understood, especially concerning decoding temperatures. This paper delves into the effects of decoding temperatures on speculative decoding's efficacy. Beginning with knowledge distillation (KD), we first highlight the challenge of decoding at higher temperatures, and demonstrate KD in a consistent temperature setting could be a remedy. We also investigate the effects of out-of-domain testing sets with out-of-range temperatures. Building upon these findings, we take an initial step to further the speedup for speculative decoding, particularly in a high-temperature generation setting. Our work offers new insights into how generation configurations drastically affect the performance of speculative decoding, and underscores the need for developing methods that focus on diverse decoding configurations. Code is publically available at https://github.com/ozyyshr/TempSpec.
Law of the Weakest Link: Cross Capabilities of Large Language Models
Sep 30, 2024



The development and evaluation of Large Language Models (LLMs) have largely focused on individual capabilities. However, this overlooks the intersection of multiple abilities across different types of expertise that are often required for real-world tasks, which we term cross capabilities. To systematically explore this concept, we first define seven core individual capabilities and then pair them to form seven common cross capabilities, each supported by a manually constructed taxonomy. Building on these definitions, we introduce CrossEval, a benchmark comprising 1,400 human-annotated prompts, with 100 prompts for each individual and cross capability. To ensure reliable evaluation, we involve expert annotators to assess 4,200 model responses, gathering 8,400 human ratings with detailed explanations to serve as reference examples. Our findings reveal that, in both static evaluations and attempts to enhance specific abilities, current LLMs consistently exhibit the "Law of the Weakest Link," where cross-capability performance is significantly constrained by the weakest component. Specifically, across 58 cross-capability scores from 17 models, 38 scores are lower than all individual capabilities, while 20 fall between strong and weak, but closer to the weaker ability. These results highlight the under-performance of LLMs in cross-capability tasks, making the identification and improvement of the weakest capabilities a critical priority for future research to optimize performance in complex, multi-dimensional scenarios.
Two-stage initial-value iterative physics-informed neural networks for simulating solitary waves of nonlinear wave equations
Sep 02, 2024We propose a new two-stage initial-value iterative neural network (IINN) algorithm for solitary wave computations of nonlinear wave equations based on traditional numerical iterative methods and physics-informed neural networks (PINNs). Specifically, the IINN framework consists of two subnetworks, one of which is used to fit a given initial value, and the other incorporates physical information and continues training on the basis of the first subnetwork. Importantly, the IINN method does not require any additional data information including boundary conditions, apart from the given initial value. Corresponding theoretical guarantees are provided to demonstrate the effectiveness of our IINN method. The proposed IINN method is efficiently applied to learn some types of solutions in different nonlinear wave equations, including the one-dimensional (1D) nonlinear Schr\"odinger equations (NLS) equation (with and without potentials), the 1D saturable NLS equation with PT -symmetric optical lattices, the 1D focusing-defocusing coupled NLS equations, the KdV equation, the two-dimensional (2D) NLS equation with potentials, the 2D amended GP equation with a potential, the (2+1)-dimensional KP equation, and the 3D NLS equation with a potential. These applications serve as evidence for the efficacy of our method. Finally, by comparing with the traditional methods, we demonstrate the advantages of the proposed IINN method.
* 25 pages, 17 figures
See What LLMs Cannot Answer: A Self-Challenge Framework for Uncovering LLM Weaknesses
Aug 16, 2024



The impressive performance of Large Language Models (LLMs) has consistently surpassed numerous human-designed benchmarks, presenting new challenges in assessing the shortcomings of LLMs. Designing tasks and finding LLMs' limitations are becoming increasingly important. In this paper, we investigate the question of whether an LLM can discover its own limitations from the errors it makes. To this end, we propose a Self-Challenge evaluation framework with human-in-the-loop. Starting from seed instances that GPT-4 fails to answer, we prompt GPT-4 to summarize error patterns that can be used to generate new instances and incorporate human feedback on them to refine these patterns for generating more challenging data, iteratively. We end up with 8 diverse patterns, such as text manipulation and questions with assumptions. We then build a benchmark, SC-G4, consisting of 1,835 instances generated by GPT-4 using these patterns, with human-annotated gold responses. The SC-G4 serves as a challenging benchmark that allows for a detailed assessment of LLMs' abilities. Our results show that only 44.96\% of instances in SC-G4 can be answered correctly by GPT-4. Interestingly, our pilot study indicates that these error patterns also challenge other LLMs, such as Claude-3 and Llama-3, and cannot be fully resolved through fine-tuning. Our work takes the first step to demonstrate that LLMs can autonomously identify their inherent flaws and provide insights for future dynamic and automatic evaluation.
Investigating Instruction Tuning Large Language Models on Graphs
Aug 10, 2024



Inspired by the recent advancements of Large Language Models (LLMs) in NLP tasks, there's growing interest in applying LLMs to graph-related tasks. This study delves into the capabilities of instruction-following LLMs for engaging with real-world graphs, aiming to offer empirical insights into how LLMs can effectively interact with graphs and generalize across graph tasks. We begin by constructing a dataset designed for instruction tuning, which comprises a diverse collection of 79 graph-related tasks from academic and e-commerce domains, featuring 44,240 training instances and 18,960 test samples. Utilizing this benchmark, our initial investigation focuses on identifying the optimal graph representation that serves as a conduit for LLMs to understand complex graph structures. Our findings indicate that JSON format for graph representation consistently outperforms natural language and code formats across various LLMs and graph types. Furthermore, we examine the key factors that influence the generalization abilities of instruction-tuned LLMs by evaluating their performance on both in-domain and out-of-domain graph tasks.
Label Propagation Training Schemes for Physics-Informed Neural Networks and Gaussian Processes
Apr 08, 2024



This paper proposes a semi-supervised methodology for training physics-informed machine learning methods. This includes self-training of physics-informed neural networks and physics-informed Gaussian processes in isolation, and the integration of the two via co-training. We demonstrate via extensive numerical experiments how these methods can ameliorate the issue of propagating information forward in time, which is a common failure mode of physics-informed machine learning.