 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefMamba: Deformable Visual State Space Model
Apr 08, 2025



Recently, state space models (SSM), particularly Mamba, have attracted significant attention from scholars due to their ability to effectively balance computational efficiency and performance. However, most existing visual Mamba methods flatten images into 1D sequences using predefined scan orders, which results the model being less capable of utilizing the spatial structural information of the image during the feature extraction process. To address this issue, we proposed a novel visual foundation model called DefMamba. This model includes a multi-scale backbone structure and deformable mamba (DM) blocks, which dynamically adjust the scanning path to prioritize important information, thus enhancing the capture and processing of relevant input features. By combining a deformable scanning(DS) strategy, this model significantly improves its ability to learn image structures and detects changes in object details. Numerous experiments have shown that DefMamba achieves state-of-the-art performance in various visual tasks, including image classification, object detection, instance segmentation, and semantic segmentation. The code is open source on DefMamba.
SCORE: Story Coherence and Retrieval Enhancement for AI Narratives
Mar 30, 2025



Large Language Models (LLMs) excel at generating creative narratives but struggle with long-term coherence and emotional consistency in complex stories. To address this, we propose SCORE (Story Coherence and Retrieval Enhancement), a framework integrating three components: 1) Dynamic State Tracking (monitoring objects/characters via symbolic logic), 2) Context-Aware Summarization (hierarchical episode summaries for temporal progression), and 3) Hybrid Retrieval (combining TF-IDF keyword relevance with cosine similarity-based semantic embeddings). The system employs a temporally-aligned Retrieval-Augmented Generation (RAG) pipeline to validate contextual consistency. Evaluations show SCORE achieves 23.6% higher coherence (NCI-2.0 benchmark), 89.7% emotional consistency (EASM metric), and 41.8% fewer hallucinations versus baseline GPT models. Its modular design supports incremental knowledge graph construction for persistent story memory and multi-LLM backend compatibility, offering an explainable solution for industrial-scale narrative systems requiring long-term consistency.
MARS: Memory-Enhanced Agents with Reflective Self-improvement
Mar 25, 2025Large language models (LLMs) have made significant advances in the field of natural language processing, but they still face challenges such as continuous decision-making, lack of long-term memory, and limited context windows in dynamic environments. To address these issues, this paper proposes an innovative framework Memory-Enhanced Agents with Reflective Self-improvement. The MARS framework comprises three agents: the User, the Assistant, and the Checker. By integrating iterative feedback, reflective mechanisms, and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it significantly enhances the agents capabilities in handling multi-tasking and long-span information.
Curriculum Coarse-to-Fine Selection for High-IPC Dataset Distillation
Mar 24, 2025Dataset distillation (DD) excels in synthesizing a small number of images per class (IPC) but struggles to maintain its effectiveness in high-IPC settings. Recent works on dataset distillation demonstrate that combining distilled and real data can mitigate the effectiveness decay. However, our analysis of the combination paradigm reveals that the current one-shot and independent selection mechanism induces an incompatibility issue between distilled and real images. To address this issue, we introduce a novel curriculum coarse-to-fine selection (CCFS) method for efficient high-IPC dataset distillation. CCFS employs a curriculum selection framework for real data selection, where we leverage a coarse-to-fine strategy to select appropriate real data based on the current synthetic dataset in each curriculum. Extensive experiments validate CCFS, surpassing the state-of-the-art by +6.6\% on CIFAR-10, +5.8\% on CIFAR-100, and +3.4\% on Tiny-ImageNet under high-IPC settings. Notably, CCFS achieves 60.2\% test accuracy on ResNet-18 with a 20\% compression ratio of Tiny-ImageNet, closely matching full-dataset training with only 0.3\% degradation. Code: https://github.com/CYDaaa30/CCFS.
AgentDropout: Dynamic Agent Elimination for Token-Efficient and High-Performance LLM-Based Multi-Agent Collaboration
Mar 24, 2025Multi-agent systems (MAS) based on large language models (LLMs) have demonstrated significant potential in collaborative problem-solving. However, they still face substantial challenges of low communication efficiency and suboptimal task performance, making the careful design of the agents' communication topologies particularly important. Inspired by the management theory that roles in an efficient team are often dynamically adjusted, we propose AgentDropout, which identifies redundant agents and communication across different communication rounds by optimizing the adjacency matrices of the communication graphs and eliminates them to enhance both token efficiency and task performance. Compared to state-of-the-art methods, AgentDropout achieves an average reduction of 21.6% in prompt token consumption and 18.4% in completion token consumption, along with a performance improvement of 1.14 on the tasks. Furthermore, the extended experiments demonstrate that AgentDropout achieves notable domain transferability and structure robustness, revealing its reliability and effectiveness. We release our code at https://github.com/wangzx1219/AgentDropout.
PromptLNet: Region-Adaptive Aesthetic Enhancement via Prompt Guidance in Low-Light Enhancement Net
Mar 11, 2025Learning and improving large language models through human preference feedback has become a mainstream approach, but it has rarely been applied to the field of low-light image enhancement. Existing low-light enhancement evaluations typically rely on objective metrics (such as FID, PSNR, etc.), which often result in models that perform well objectively but lack aesthetic quality. Moreover, most low-light enhancement models are primarily designed for global brightening, lacking detailed refinement. Therefore, the generated images often require additional local adjustments, leading to research gaps in practical applications. To bridge this gap, we propose the following innovations: 1) We collect human aesthetic evaluation text pairs and aesthetic scores from multiple low-light image datasets (e.g., LOL, LOL2, LOM, DCIM, MEF, etc.) to train a low-light image aesthetic evaluation model, supplemented by an optimization algorithm designed to fine-tune the diffusion model. 2) We propose a prompt-driven brightness adjustment module capable of performing fine-grained brightness and aesthetic adjustments for specific instances or regions. 3) We evaluate our method alongside existing state-of-the-art algorithms on mainstream benchmarks. Experimental results show that our method not only outperforms traditional methods in terms of visual quality but also provides greater flexibility and controllability, paving the way for improved aesthetic quality.
A Cascading Cooperative Multi-agent Framework for On-ramp Merging Control Integrating Large Language Models
Mar 11, 2025Traditional Reinforcement Learning (RL) suffers from replicating human-like behaviors, generalizing effectively in multi-agent scenarios, and overcoming inherent interpretability issues.These tasks are compounded when deep environment understanding, agent coordination and dynamic optimization are required. While Large Language Model (LLM) enhanced methods have shown promise in generalization and interoperability, they often neglect necessary multi-agent coordination. Therefore, we introduce the Cascading Cooperative Multi-agent (CCMA) framework, integrating RL for individual interactions, a fine-tuned LLM for regional cooperation, a reward function for global optimization, and the Retrieval-augmented Generation mechanism to dynamically optimize decision-making across complex driving scenarios. Our experiments demonstrate that the CCMA outperforms existing RL methods, demonstrating significant improvements in both micro and macro-level performance in complex driving environments.
TSCnet: A Text-driven Semantic-level Controllable Framework for Customized Low-Light Image Enhancement
Mar 11, 2025



Deep learning-based image enhancement methods show significant advantages in reducing noise and improving visibility in low-light conditions. These methods are typically based on one-to-one mapping, where the model learns a direct transformation from low light to specific enhanced images. Therefore, these methods are inflexible as they do not allow highly personalized mapping, even though an individual's lighting preferences are inherently personalized. To overcome these limitations, we propose a new light enhancement task and a new framework that provides customized lighting control through prompt-driven, semantic-level, and quantitative brightness adjustments. The framework begins by leveraging a Large Language Model (LLM) to understand natural language prompts, enabling it to identify target objects for brightness adjustments. To localize these target objects, the Retinex-based Reasoning Segment (RRS) module generates precise target localization masks using reflection images. Subsequently, the Text-based Brightness Controllable (TBC) module adjusts brightness levels based on the generated illumination map. Finally, an Adaptive Contextual Compensation (ACC) module integrates multi-modal inputs and controls a conditional diffusion model to adjust the lighting, ensuring seamless and precise enhancements accurately. Experimental results on benchmark datasets demonstrate our framework's superior performance at increasing visibility, maintaining natural color balance, and amplifying fine details without creating artifacts. Furthermore, its robust generalization capabilities enable complex semantic-level lighting adjustments in diverse open-world environments through natural language interactions.
Class-Aware PillarMix: Can Mixed Sample Data Augmentation Enhance 3D Object Detection with Radar Point Clouds?
Mar 04, 2025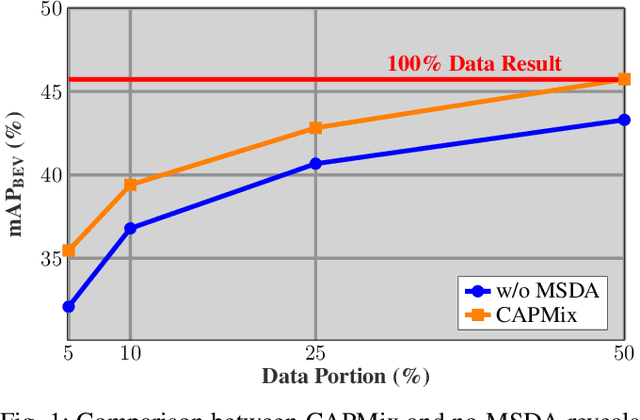
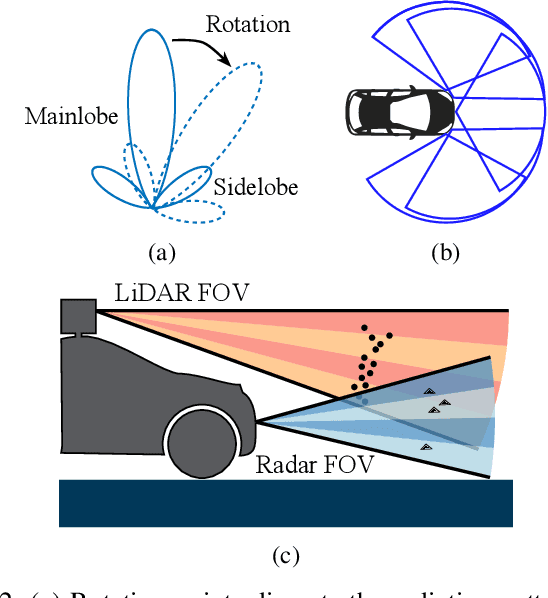
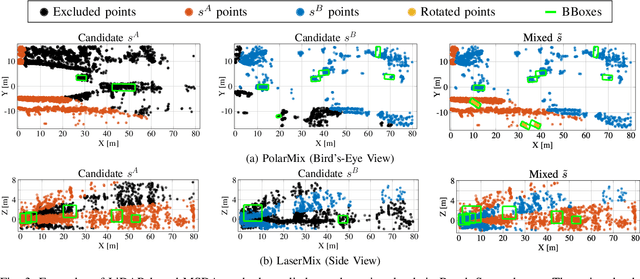
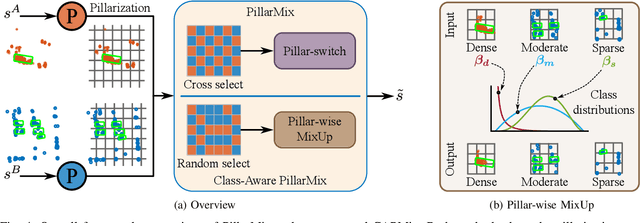
Due to the significant effort required for data collection and annotation in 3D perception tasks, mixed sample data augmentation (MSDA) has been widely studied to generate diverse training samples by mixing existing data. Recently, many MSDA techniques have been developed for point clouds, but they mainly target LiDAR data, leaving their application to radar point clouds largely unexplored. In this paper, we examine the feasibility of applying existing MSDA methods to radar point clouds and identify several challenges in adapting these techniques. These obstacles stem from the radar's irregular angular distribution, deviations from a single-sensor polar layout in multi-radar setups, and point sparsity. To address these issues, we propose Class-Aware PillarMix (CAPMix), a novel MSDA approach that applies MixUp at the pillar level in 3D point clouds, guided by class labels. Unlike methods that rely a single mix ratio to the entire sample, CAPMix assigns an independent ratio to each pillar, boosting sample diversity. To account for the density of different classes, we use class-specific distributions: for dense objects (e.g., large vehicles), we skew ratios to favor points from another sample, while for sparse objects (e.g., pedestrians), we sample more points from the original. This class-aware mixing retains critical details and enriches each sample with new information, ultimately generating more diverse training data. Experimental results demonstrate that our method not only significantly boosts performance but also outperforms existing MSDA approaches across two datasets (Bosch Street and K-Radar). We believe that this straightforward yet effective approach will spark further investigation into MSDA techniques for radar data.
Benchmarking Post-Training Quantization in LLMs: Comprehensive Taxonomy, Unified Evaluation, and Comparative Analysis
Feb 18, 2025



Post-training Quantization (PTQ) technique has been extensively adopted for large language models (LLMs) compression owing to its efficiency and low resource requirement. However, current research lacks a in-depth analysis of the superior and applicable scenarios of each PTQ strategy. In addition, existing algorithms focus primarily on performance, overlooking the trade-off among model size, performance, and quantization bitwidth. To mitigate these confusions, we provide a novel benchmark for LLMs PTQ in this paper. Firstly, in order to support our benchmark, we propose a comprehensive taxonomy for existing mainstream methods by scrutinizing their computational strategies (e.g., optimization-based, compensation-based, etc.). Then, we conduct extensive experiments with the baseline within each class, covering models with various sizes (7B-70B), bitwidths, training levels (LLaMA1/2/3/3.1), architectures (Mixtral, DeepSeekMoE and Mamba) and modality (LLaVA1.5 and VILA1.5) on a wide range of evaluation metrics.Through comparative analysis on the results, we summarize the superior of each PTQ strategy and modelsize-bitwidth trade-off considering the performance. For example, our benchmark reveals that compensation-based technique demonstrates outstanding cross-architecture robustness and extremely low-bit PTQ for ultra large models should be reexamined. Finally, we further accordingly claim that a practical combination of compensation and other PTQ strategy can achieve SOTA various robustness. We believe that our benchmark will provide valuable recommendations for the deployment of LLMs and future research on PTQ approaches.