 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniAdapter: Unified Parameter-Efficient Transfer Learning for Cross-modal Modeling
Feb 13, 2023Large-scale vision-language pre-trained models have shown promising transferability to various downstream tasks. As the size of these foundation models and the number of downstream tasks grow, the standard full fine-tuning paradigm becomes unsustainable due to heavy computational and storage costs. This paper proposes UniAdapter, which unifies unimodal and multimodal adapters for parameter-efficient cross-modal adaptation on pre-trained vision-language models. Specifically, adapters are distributed to different modalities and their interactions, with the total number of tunable parameters reduced by partial weight sharing. The unified and knowledge-sharing design enables powerful cross-modal representations that can benefit various downstream tasks, requiring only 1.0%-2.0% tunable parameters of the pre-trained model. Extensive experiments on 6 cross-modal downstream benchmarks (including video-text retrieval, image-text retrieval, VideoQA, and VQA) show that in most cases, UniAdapter not only outperforms the state-of-the-arts, but even beats the full fine-tuning strategy. Particularly, on the MSRVTT retrieval task, UniAdapter achieves 49.7% recall@1 with 2.2% model parameters, outperforming the latest competitors by 2.0%. The code and models are available at https://github.com/RERV/UniAdapter.
AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
Feb 03, 2023Diffusion models have demonstrated their powerful generative capability in many tasks, with great potential to serve as a paradigm for offline reinforcement learning. However, the quality of the diffusion model is limited by the insufficient diversity of training data, which hinders the performance of planning and the generalizability to new tasks. This paper introduces AdaptDiffuser, an evolutionary planning method with diffusion that can self-evolve to improve the diffusion model hence a better planner, not only for seen tasks but can also adapt to unseen tasks. AdaptDiffuser enables the generation of rich synthetic expert data for goal-conditioned tasks using guidance from reward gradients. It then selects high-quality data via a discriminator to finetune the diffusion model, which improves the generalization ability to unseen tasks. Empirical experiments on two benchmark environments and two carefully designed unseen tasks in KUKA industrial robot arm and Maze2D environments demonstrate the effectiveness of AdaptDiffuser. For example, AdaptDiffuser not only outperforms the previous art Diffuser by 20.8% on Maze2D and 7.5% on MuJoCo locomotion, but also adapts better to new tasks, e.g., KUKA pick-and-place, by 27.9% without requiring additional expert data.
Online Learning Based Mobile Robot Controller Adaptation for Slip Reduction
Jan 30, 2023Slip is a very common phenomena present in wheeled mobile robotic systems. It has undesirable consequences such as wasting energy and impeding system stability. To tackle the challenge of mobile robot trajectory tracking under slippery conditions, we propose a hierarchical framework that learns and adapts gains of the tracking controllers simultaneously online. Concretely, a reinforcement learning (RL) module is used to auto-tune parameters in a lateral predictive controller and a longitudinal speed PID controller. Experiments show the necessity of simultaneous gain tuning, and have demonstrated that our online framework outperforms the best baseline controller using fixed gains. By utilizing online gain adaptation, our framework achieves robust tracking performance by rejecting slip and reducing tracking errors when the mobile robot travels through various terrains.
Towards Modeling and Influencing the Dynamics of Human Learning
Jan 02, 2023



Humans have internal models of robots (like their physical capabilities), the world (like what will happen next), and their tasks (like a preferred goal). However, human internal models are not always perfect: for example, it is easy to underestimate a robot's inertia. Nevertheless, these models change and improve over time as humans gather more experience. Interestingly, robot actions influence what this experience is, and therefore influence how people's internal models change. In this work we take a step towards enabling robots to understand the influence they have, leverage it to better assist people, and help human models more quickly align with reality. Our key idea is to model the human's learning as a nonlinear dynamical system which evolves the human's internal model given new observations. We formulate a novel optimization problem to infer the human's learning dynamics from demonstrations that naturally exhibit human learning. We then formalize how robots can influence human learning by embedding the human's learning dynamics model into the robot planning problem. Although our formulations provide concrete problem statements, they are intractable to solve in full generality. We contribute an approximation that sacrifices the complexity of the human internal models we can represent, but enables robots to learn the nonlinear dynamics of these internal models. We evaluate our inference and planning methods in a suite of simulated environments and an in-person user study, where a 7DOF robotic arm teaches participants to be better teleoperators. While influencing human learning remains an open problem, our results demonstrate that this influence is possible and can be helpful in real human-robot interaction.
Continuous Trajectory Optimization via B-splines for Multi-jointed Robotic Systems
Dec 20, 2022Continuous formulations of trajectory planning problems have two main benefits. First, constraints are guaranteed to be satisfied at all times. Secondly, dynamic obstacles can be naturally considered with time. This paper introduces a novel B-spline based trajectory optimization method for multi-jointed robots that provides a continuous trajectory with guaranteed continuous constraints satisfaction. At the core of this method, B-spline basic operations, like addition, multiplication, and derivative, are rigorously defined and applied for problem formulation. B-spline unique characteristics, such as the convex hull and smooth curves properties, are utilized to reformulate the original continuous optimization problem into a finite-dimensional problem. Collision avoidance with static obstacles is achieved using the signed distance field, while that with dynamic obstacles is accomplished via constructing time-varying separating hyperplanes. Simulation results on various robots validate the effectiveness of the algorithm. In addition, this paper provides experimental validations with a 6-link FANUC robot avoiding static and moving obstacles.
Prim-LAfD: A Framework to Learn and Adapt Primitive-Based Skills from Demonstrations for Insertion Tasks
Dec 02, 2022



Learning generalizable insertion skills in a data-efficient manner has long been a challenge in the robot learning community. While the current state-of-the-art methods with reinforcement learning (RL) show promising performance in acquiring manipulation skills, the algorithms are data-hungry and hard to generalize. To overcome the issues, in this paper we present Prim-LAfD, a simple yet effective framework to learn and adapt primitive-based insertion skills from demonstrations. Prim-LAfD utilizes black-box function optimization to learn and adapt the primitive parameters leveraging prior experiences. Human demonstrations are modeled as dense rewards guiding parameter learning. We validate the effectiveness of the proposed method on eight peg-hole and connector-socket insertion tasks. The experimental results show that our proposed framework takes less than one hour to acquire the insertion skills and as few as fifteen minutes to adapt to an unseen insertion task on a physical robot.
Outracing Human Racers with Model-based Autonomous Racing
Nov 17, 2022



Autonomous racing has become a popular sub-topic of autonomous driving in recent years. The goal of autonomous racing research is to develop software to control the vehicle at its limit of handling and achieve human-level racing performance. In this work, we investigate how to approach human expert-level racing performance with model-based planning and control methods using the high-fidelity racing simulator Gran Turismo Sport (GTS). GTS enables a unique opportunity for autonomous racing research, as many recordings of racing from highly skilled human players can served as expert emonstrations. By comparing the performance of the autonomous racing software with human experts, we better understand the performance gap of existing software and explore new methodologies in a principled manner. In particular, we focus on the commonly adopted model-based racing framework, consisting of an offline trajectory planner and an online Model Predictive Control-based (MPC) tracking controller. We thoroughly investigate the design challenges from three perspective, namely vehicle model, planning algorithm, and controller design, and propose novel solutions to improve the baseline approach toward human expert-level performance. We showed that the proposed control framework can achieve top 0.95% lap time among human-expert players in GTS. Furthermore, we conducted comprehensive ablation studies to validate the necessity of proposed modules, and pointed out potential future directions to reach human-best performance.
Allowing Safe Contact in Robotic Goal-Reaching: Planning and Tracking in Operational and Null Spaces
Oct 31, 2022



In recent years, impressive results have been achieved in robotic manipulation. While many efforts focus on generating collision-free reference signals, few allow safe contact between the robot bodies and the environment. However, in human's daily manipulation, contact between arms and obstacles is prevalent and even necessary. This paper investigates the benefit of allowing safe contact during robotic manipulation and advocates generating and tracking compliance reference signals in both operational and null spaces. In addition, to optimize the collision-allowed trajectories, we present a hybrid solver that integrates sampling- and gradient-based approaches. We evaluate the proposed method on a goal-reaching task in five simulated and real-world environments with different collisional conditions. We show that allowing safe contact improves goal-reaching efficiency and provides feasible solutions in highly collisional scenarios where collision-free constraints cannot be enforced. Moreover, we demonstrate that planning in null space, in addition to operational space, improves trajectory safety.
Time Will Tell: New Outlooks and A Baseline for Temporal Multi-View 3D Object Detection
Oct 05, 2022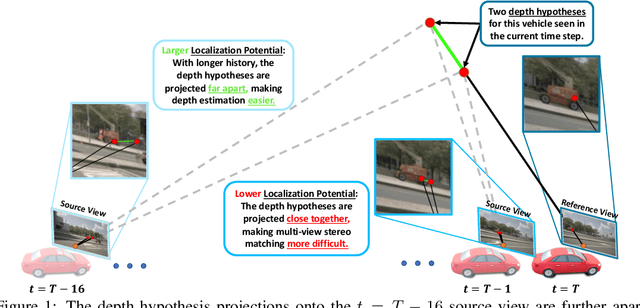
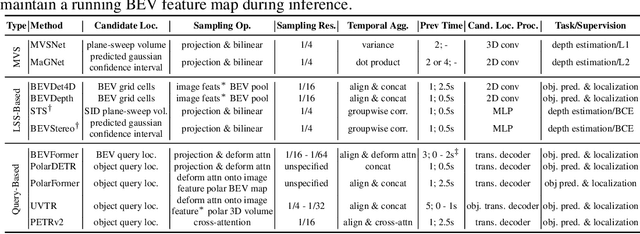
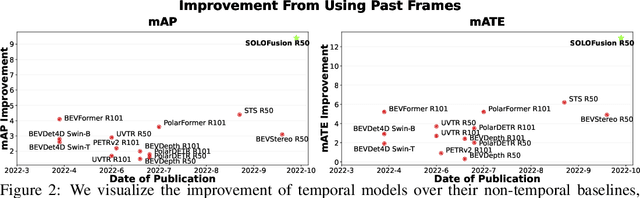
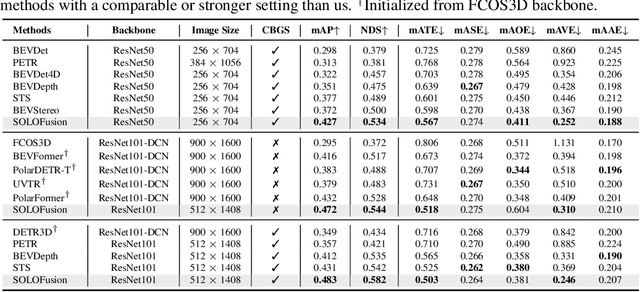
While recent camera-only 3D detection methods leverage multiple timesteps, the limited history they use significantly hampers the extent to which temporal fusion can improve object perception. Observing that existing works' fusion of multi-frame images are instances of temporal stereo matching, we find that performance is hindered by the interplay between 1) the low granularity of matching resolution and 2) the sub-optimal multi-view setup produced by limited history usage. Our theoretical and empirical analysis demonstrates that the optimal temporal difference between views varies significantly for different pixels and depths, making it necessary to fuse many timesteps over long-term history. Building on our investigation, we propose to generate a cost volume from a long history of image observations, compensating for the coarse but efficient matching resolution with a more optimal multi-view matching setup. Further, we augment the per-frame monocular depth predictions used for long-term, coarse matching with short-term, fine-grained matching and find that long and short term temporal fusion are highly complementary. While maintaining high efficiency, our framework sets new state-of-the-art on nuScenes, achieving first place on the test set and outperforming previous best art by 5.2% mAP and 3.7% NDS on the validation set. Code will be released $\href{https://github.com/Divadi/SOLOFusion}{here.}$
Zero-Shot Policy Transfer with Disentangled Task Representation of Meta-Reinforcement Learning
Oct 01, 2022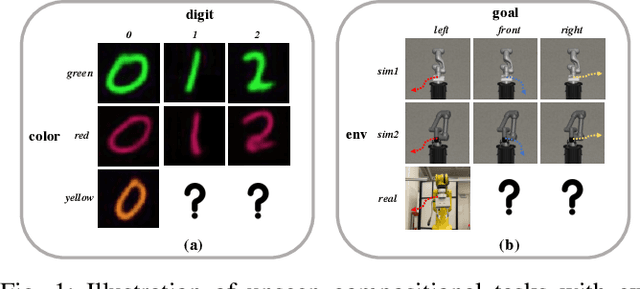
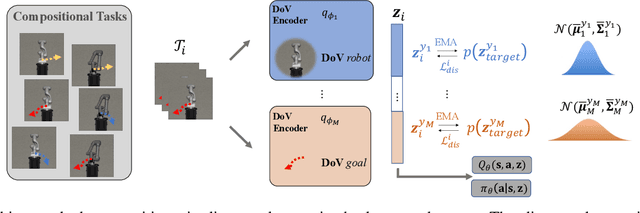
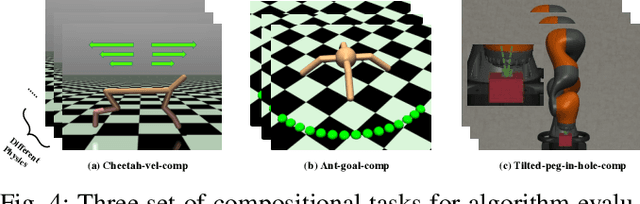
Humans are capable of abstracting various tasks as different combinations of multiple attributes. This perspective of compositionality is vital for human rapid learning and adaption since previous experiences from related tasks can be combined to generalize across novel compositional settings. In this work, we aim to achieve zero-shot policy generalization of Reinforcement Learning (RL) agents by leveraging the task compositionality. Our proposed method is a meta- RL algorithm with disentangled task representation, explicitly encoding different aspects of the tasks. Policy generalization is then performed by inferring unseen compositional task representations via the obtained disentanglement without extra exploration. The evaluation is conducted on three simulated tasks and a challenging real-world robotic insertion task. Experimental results demonstrate that our proposed method achieves policy generalization to unseen compositional tasks in a zero-shot manner.