 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
NaviTrace: Evaluating Embodied Navigation of Vision-Language Models
Oct 30, 2025



Vision-language models demonstrate unprecedented performance and generalization across a wide range of tasks and scenarios. Integrating these foundation models into robotic navigation systems opens pathways toward building general-purpose robots. Yet, evaluating these models' navigation capabilities remains constrained by costly real-world trials, overly simplified simulations, and limited benchmarks. We introduce NaviTrace, a high-quality Visual Question Answering benchmark where a model receives an instruction and embodiment type (human, legged robot, wheeled robot, bicycle) and must output a 2D navigation trace in image space. Across 1000 scenarios and more than 3000 expert traces, we systematically evaluate eight state-of-the-art VLMs using a newly introduced semantic-aware trace score. This metric combines Dynamic Time Warping distance, goal endpoint error, and embodiment-conditioned penalties derived from per-pixel semantics and correlates with human preferences. Our evaluation reveals consistent gap to human performance caused by poor spatial grounding and goal localization. NaviTrace establishes a scalable and reproducible benchmark for real-world robotic navigation. The benchmark and leaderboard can be found at https://leggedrobotics.github.io/navitrace_webpage/.
Pretraining in Actor-Critic Reinforcement Learning for Robot Motion Control
Oct 14, 2025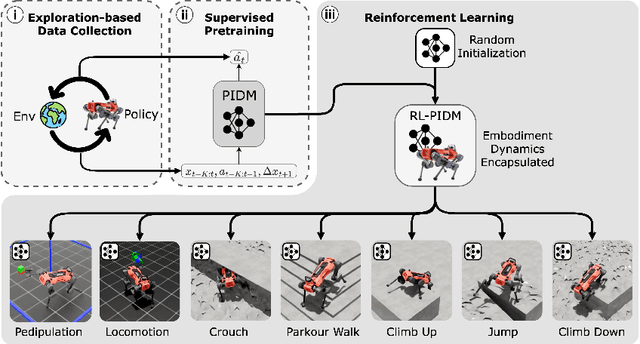


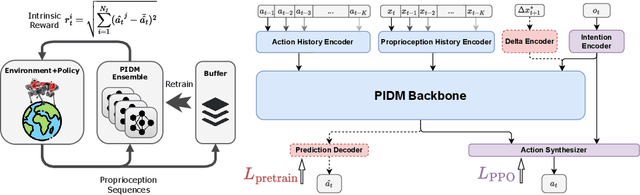
The pretraining-finetuning paradigm has facilitated numerous transformative advancements in artificial intelligence research in recent years. However, in the domain of reinforcement learning (RL) for robot motion control, individual skills are often learned from scratch despite the high likelihood that some generalizable knowledge is shared across all task-specific policies belonging to a single robot embodiment. This work aims to define a paradigm for pretraining neural network models that encapsulate such knowledge and can subsequently serve as a basis for warm-starting the RL process in classic actor-critic algorithms, such as Proximal Policy Optimization (PPO). We begin with a task-agnostic exploration-based data collection algorithm to gather diverse, dynamic transition data, which is then used to train a Proprioceptive Inverse Dynamics Model (PIDM) through supervised learning. The pretrained weights are loaded into both the actor and critic networks to warm-start the policy optimization of actual tasks. We systematically validated our proposed method on seven distinct robot motion control tasks, showing significant benefits to this initialization strategy. Our proposed approach on average improves sample efficiency by 40.1% and task performance by 7.5%, compared to random initialization. We further present key ablation studies and empirical analyses that shed light on the mechanisms behind the effectiveness of our method.
What Matters in RL-Based Methods for Object-Goal Navigation? An Empirical Study and A Unified Framework
Oct 02, 2025



Object-Goal Navigation (ObjectNav) is a critical component toward deploying mobile robots in everyday, uncontrolled environments such as homes, schools, and workplaces. In this context, a robot must locate target objects in previously unseen environments using only its onboard perception. Success requires the integration of semantic understanding, spatial reasoning, and long-horizon planning, which is a combination that remains extremely challenging. While reinforcement learning (RL) has become the dominant paradigm, progress has spanned a wide range of design choices, yet the field still lacks a unifying analysis to determine which components truly drive performance. In this work, we conduct a large-scale empirical study of modular RL-based ObjectNav systems, decomposing them into three key components: perception, policy, and test-time enhancement. Through extensive controlled experiments, we isolate the contribution of each and uncover clear trends: perception quality and test-time strategies are decisive drivers of performance, whereas policy improvements with current methods yield only marginal gains. Building on these insights, we propose practical design guidelines and demonstrate an enhanced modular system that surpasses State-of-the-Art (SotA) methods by 6.6% on SPL and by a 2.7% success rate. We also introduce a human baseline under identical conditions, where experts achieve an average 98% success, underscoring the gap between RL agents and human-level navigation. Our study not only sets the SotA performance but also provides principled guidance for future ObjectNav development and evaluation.
ExT: Towards Scalable Autonomous Excavation via Large-Scale Multi-Task Pretraining and Fine-Tuning
Sep 18, 2025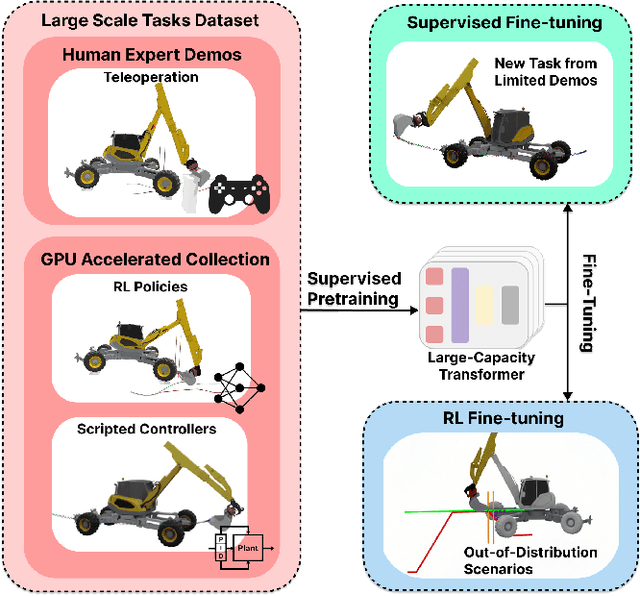
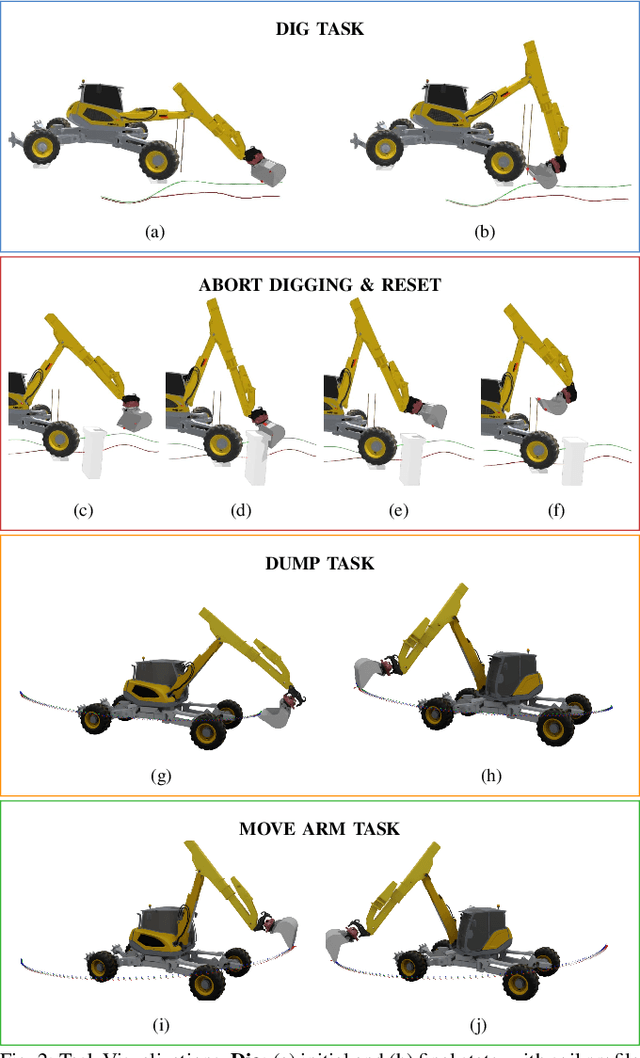


Scaling up the deployment of autonomous excavators is of great economic and societal importance. Yet it remains a challenging problem, as effective systems must robustly handle unseen worksite conditions and new hardware configurations. Current state-of-the-art approaches rely on highly engineered, task-specific controllers, which require extensive manual tuning for each new scenario. In contrast, recent advances in large-scale pretrained models have shown remarkable adaptability across tasks and embodiments in domains such as manipulation and navigation, but their applicability to heavy construction machinery remains largely unexplored. In this work, we introduce ExT, a unified open-source framework for large-scale demonstration collection, pretraining, and fine-tuning of multitask excavation policies. ExT policies are first trained on large-scale demonstrations collected from a mix of experts, then fine-tuned either with supervised fine-tuning (SFT) or reinforcement learning fine-tuning (RLFT) to specialize to new tasks or operating conditions. Through both simulation and real-world experiments, we show that pretrained ExT policies can execute complete excavation cycles with centimeter-level accuracy, successfully transferring from simulation to real machine with performance comparable to specialized single-task controllers. Furthermore, in simulation, we demonstrate that ExT's fine-tuning pipelines allow rapid adaptation to new tasks, out-of-distribution conditions, and machine configurations, while maintaining strong performance on previously learned tasks. These results highlight the potential of ExT to serve as a foundation for scalable and generalizable autonomous excavation.
Collaborative Loco-Manipulation for Pick-and-Place Tasks with Dynamic Reward Curriculum
Sep 16, 2025We present a hierarchical RL pipeline for training one-armed legged robots to perform pick-and-place (P&P) tasks end-to-end -- from approaching the payload to releasing it at a target area -- in both single-robot and cooperative dual-robot settings. We introduce a novel dynamic reward curriculum that enables a single policy to efficiently learn long-horizon P&P operations by progressively guiding the agents through payload-centered sub-objectives. Compared to state-of-the-art approaches for long-horizon RL tasks, our method improves training efficiency by 55% and reduces execution time by 18.6% in simulation experiments. In the dual-robot case, we show that our policy enables each robot to attend to different components of its observation space at distinct task stages, promoting effective coordination via autonomous attention shifts. We validate our method through real-world experiments using ANYmal D platforms in both single- and dual-robot scenarios. To our knowledge, this is the first RL pipeline that tackles the full scope of collaborative P&P with two legged manipulators.
Divide, Discover, Deploy: Factorized Skill Learning with Symmetry and Style Priors
Aug 27, 2025Unsupervised Skill Discovery (USD) allows agents to autonomously learn diverse behaviors without task-specific rewards. While recent USD methods have shown promise, their application to real-world robotics remains underexplored. In this paper, we propose a modular USD framework to address the challenges in the safety, interpretability, and deployability of the learned skills. Our approach employs user-defined factorization of the state space to learn disentangled skill representations. It assigns different skill discovery algorithms to each factor based on the desired intrinsic reward function. To encourage structured morphology-aware skills, we introduce symmetry-based inductive biases tailored to individual factors. We also incorporate a style factor and regularization penalties to promote safe and robust behaviors. We evaluate our framework in simulation using a quadrupedal robot and demonstrate zero-shot transfer of the learned skills to real hardware. Our results show that factorization and symmetry lead to the discovery of structured human-interpretable behaviors, while the style factor and penalties enhance safety and diversity. Additionally, we show that the learned skills can be used for downstream tasks and perform on par with oracle policies trained with hand-crafted rewards.
GraspQP: Differentiable Optimization of Force Closure for Diverse and Robust Dexterous Grasping
Aug 20, 2025



Dexterous robotic hands enable versatile interactions due to the flexibility and adaptability of multi-fingered designs, allowing for a wide range of task-specific grasp configurations in diverse environments. However, to fully exploit the capabilities of dexterous hands, access to diverse and high-quality grasp data is essential -- whether for developing grasp prediction models from point clouds, training manipulation policies, or supporting high-level task planning with broader action options. Existing approaches for dataset generation typically rely on sampling-based algorithms or simplified force-closure analysis, which tend to converge to power grasps and often exhibit limited diversity. In this work, we propose a method to synthesize large-scale, diverse, and physically feasible grasps that extend beyond simple power grasps to include refined manipulations, such as pinches and tri-finger precision grasps. We introduce a rigorous, differentiable energy formulation of force closure, implicitly defined through a Quadratic Program (QP). Additionally, we present an adjusted optimization method (MALA*) that improves performance by dynamically rejecting gradient steps based on the distribution of energy values across all samples. We extensively evaluate our approach and demonstrate significant improvements in both grasp diversity and the stability of final grasp predictions. Finally, we provide a new, large-scale grasp dataset for 5,700 objects from DexGraspNet, comprising five different grippers and three distinct grasp types. Dataset and Code:https://graspqp.github.io/
Large Scale Robotic Material Handling: Learning, Planning, and Control
Aug 12, 2025Bulk material handling involves the efficient and precise moving of large quantities of materials, a core operation in many industries, including cargo ship unloading, waste sorting, construction, and demolition. These repetitive, labor-intensive, and safety-critical operations are typically performed using large hydraulic material handlers equipped with underactuated grippers. In this work, we present a comprehensive framework for the autonomous execution of large-scale material handling tasks. The system integrates specialized modules for environment perception, pile attack point selection, path planning, and motion control. The main contributions of this work are two reinforcement learning-based modules: an attack point planner that selects optimal grasping locations on the material pile to maximize removal efficiency and minimize the number of scoops, and a robust trajectory following controller that addresses the precision and safety challenges associated with underactuated grippers in movement, while utilizing their free-swinging nature to release material through dynamic throwing. We validate our framework through real-world experiments on a 40 t material handler in a representative worksite, focusing on two key tasks: high-throughput bulk pile management and high-precision truck loading. Comparative evaluations against human operators demonstrate the system's effectiveness in terms of precision, repeatability, and operational safety. To the best of our knowledge, this is the first complete automation of material handling tasks on a full scale.
Experience is the Best Teacher: Grounding VLMs for Robotics through Self-Generated Memory
Jul 22, 2025Vision-language models (VLMs) have been widely adopted in robotics to enable autonomous planning. However, grounding VLMs, originally trained on internet data, to diverse real-world robots remains a challenge. This paper presents ExpTeach, a framework that grounds VLMs to physical robots by building a self-generated memory of real-world experiences. In ExpTeach, the VLM autonomously plans actions, verifies outcomes, reflects on failures, and adapts robot behaviors in a closed loop. The self-generated experiences during this process are then summarized into a long-term memory, enabling retrieval of learned knowledge to guide future tasks via retrieval-augmented generation (RAG). Additionally, ExpTeach enhances the spatial understanding of VLMs with an on-demand image annotation module. In experiments, we show that reflection improves success rates from 36% to 84% on four challenging robotic tasks and observe the emergence of intelligent object interactions, including creative tool use. Across extensive tests on 12 real-world scenarios (including eight unseen ones), we find that grounding with long-term memory boosts single-trial success rates from 22% to 80%, demonstrating the effectiveness and generalizability of ExpTeach.