 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRumor Detection on Social Media: Datasets, Methods and Opportunities
Nov 17, 2019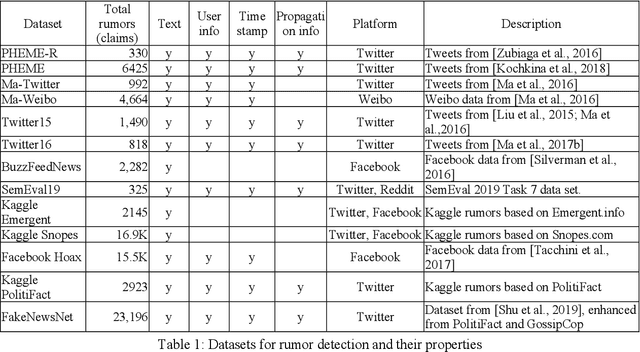
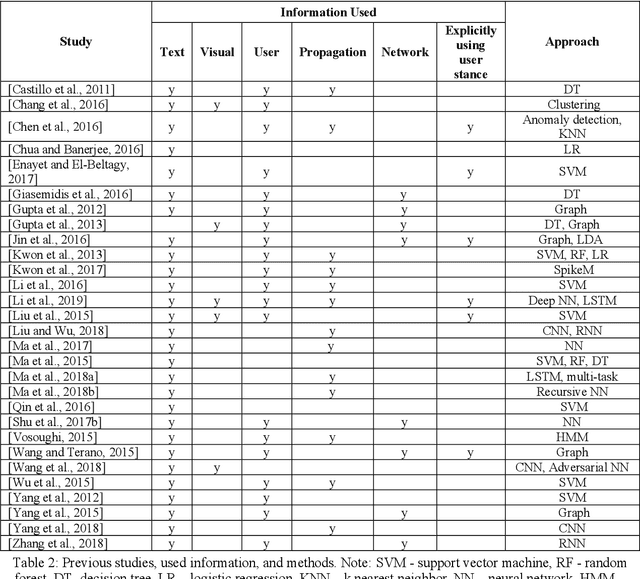
Social media platforms have been used for information and news gathering, and they are very valuable in many applications. However, they also lead to the spreading of rumors and fake news. Many efforts have been taken to detect and debunk rumors on social media by analyzing their content and social context using machine learning techniques. This paper gives an overview of the recent studies in the rumor detection field. It provides a comprehensive list of datasets used for rumor detection, and reviews the important studies based on what types of information they exploit and the approaches they take. And more importantly, we also present several new directions for future research.
* 10 pages
Review-based Question Generation with Adaptive Instance Transfer and Augmentation
Nov 05, 2019
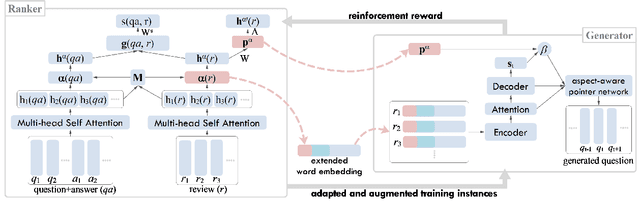
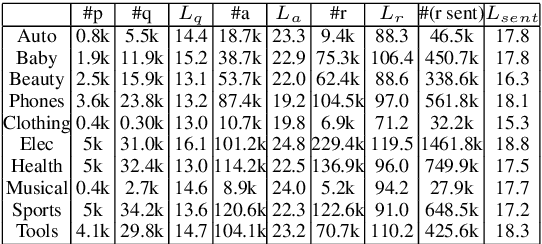
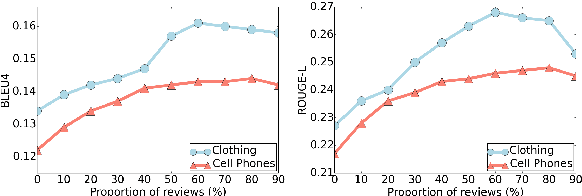
Online reviews provide rich information about products and service, while it remains inefficient for potential consumers to exploit the reviews for fulfilling their specific information need. We propose to explore question generation as a new way of exploiting review information. One major challenge of this task is the lack of review-question pairs for training a neural generation model. We propose an iterative learning framework for handling this challenge via adaptive transfer and augmentation of the training instances with the help of the available user-posed question-answer data. To capture the aspect characteristics in reviews, the augmentation and generation procedures incorporate related features extracted via unsupervised learning. Experiments on data from 10 categories of a popular E-commerce site demonstrate the effectiveness of the framework, as well as the usefulness of the new task.
Uncover Sexual Harassment Patterns from Personal Stories by Joint Key Element Extraction and Categorization
Nov 01, 2019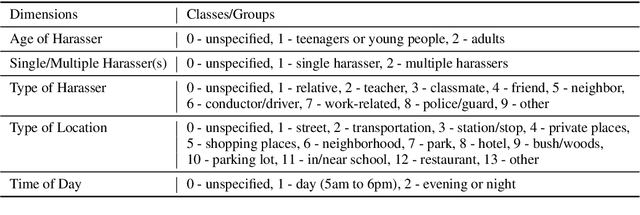
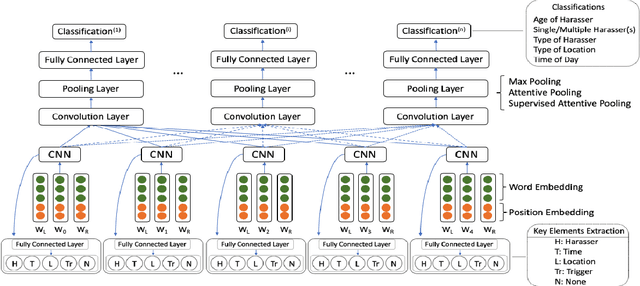
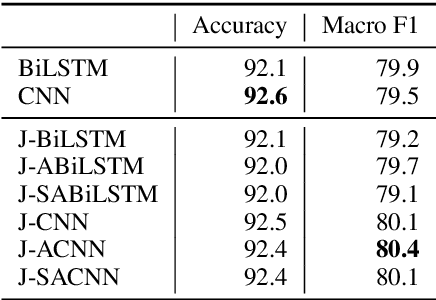
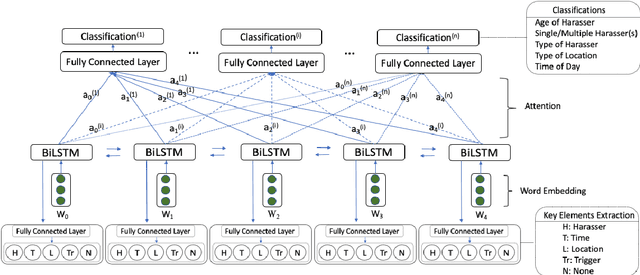
The number of personal stories about sexual harassment shared online has increased exponentially in recent years. This is in part inspired by the \#MeToo and \#TimesUp movements. Safecity is an online forum for people who experienced or witnessed sexual harassment to share their personal experiences. It has collected \textgreater 10,000 stories so far. Sexual harassment occurred in a variety of situations, and categorization of the stories and extraction of their key elements will provide great help for the related parties to understand and address sexual harassment. In this study, we manually annotated those stories with labels in the dimensions of location, time, and harassers' characteristics, and marked the key elements related to these dimensions. Furthermore, we applied natural language processing technologies with joint learning schemes to automatically categorize these stories in those dimensions and extract key elements at the same time. We also uncovered significant patterns from the categorized sexual harassment stories. We believe our annotated data set, proposed algorithms, and analysis will help people who have been harassed, authorities, researchers and other related parties in various ways, such as automatically filling reports, enlightening the public in order to prevent future harassment, and enabling more effective, faster action to be taken.
Syntax-Enhanced Self-Attention-Based Semantic Role Labeling
Oct 24, 2019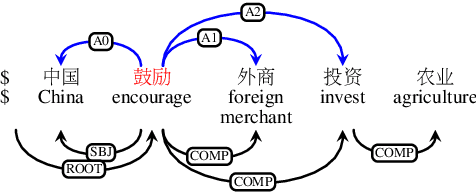
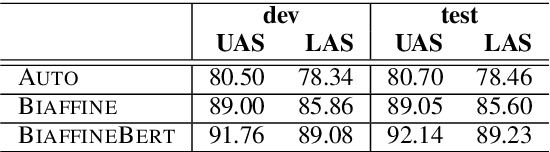
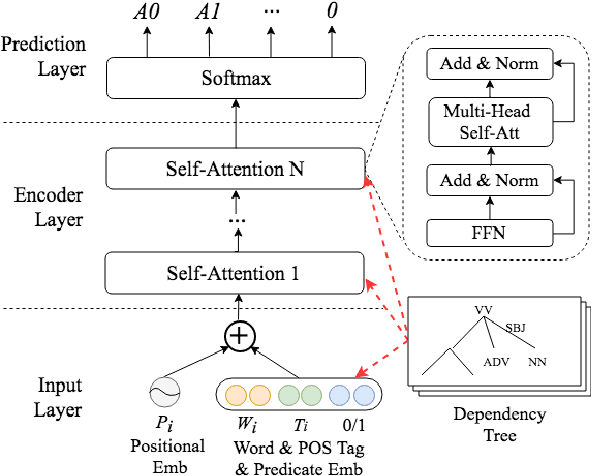
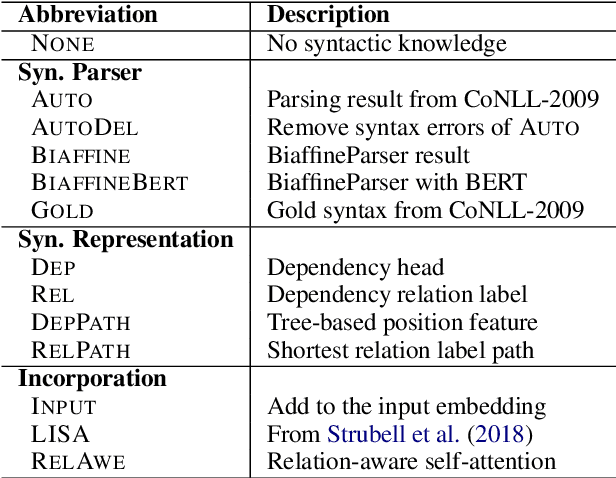
As a fundamental NLP task, semantic role labeling (SRL) aims to discover the semantic roles for each predicate within one sentence. This paper investigates how to incorporate syntactic knowledge into the SRL task effectively. We present different approaches of encoding the syntactic information derived from dependency trees of different quality and representations; we propose a syntax-enhanced self-attention model and compare it with other two strong baseline methods; and we conduct experiments with newly published deep contextualized word representations as well. The experiment results demonstrate that with proper incorporation of the high quality syntactic information, our model achieves a new state-of-the-art performance for the Chinese SRL task on the CoNLL-2009 dataset.
Human-Like Decision Making: Document-level Aspect Sentiment Classification via Hierarchical Reinforcement Learning
Oct 21, 2019
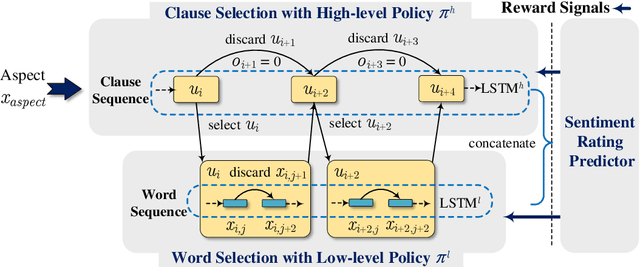
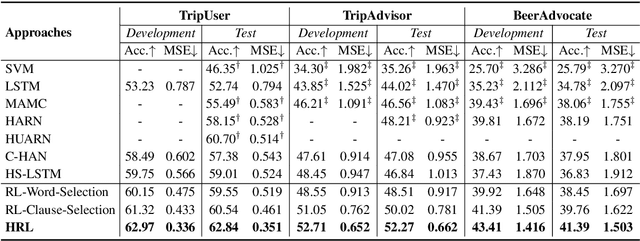
Recently, neural networks have shown promising results on Document-level Aspect Sentiment Classification (DASC). However, these approaches often offer little transparency w.r.t. their inner working mechanisms and lack interpretability. In this paper, to simulating the steps of analyzing aspect sentiment in a document by human beings, we propose a new Hierarchical Reinforcement Learning (HRL) approach to DASC. This approach incorporates clause selection and word selection strategies to tackle the data noise problem in the task of DASC. First, a high-level policy is proposed to select aspect-relevant clauses and discard noisy clauses. Then, a low-level policy is proposed to select sentiment-relevant words and discard noisy words inside the selected clauses. Finally, a sentiment rating predictor is designed to provide reward signals to guide both clause and word selection. Experimental results demonstrate the impressive effectiveness of the proposed approach to DASC over the state-of-the-art baselines.
Symmetric Regularization based BERT for Pair-wise Semantic Reasoning
Sep 08, 2019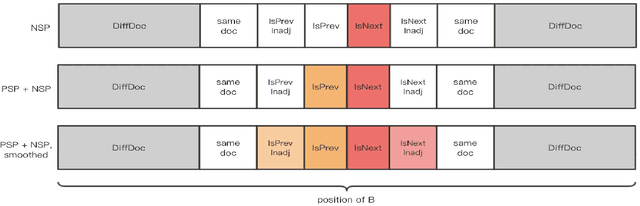
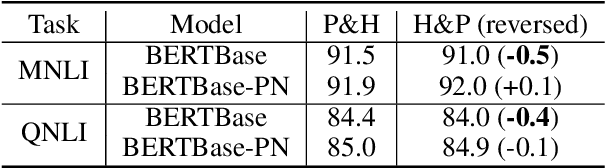
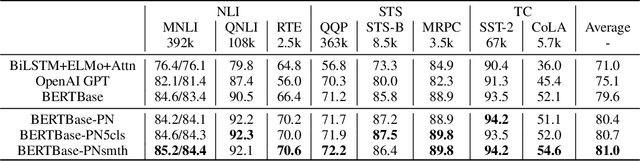
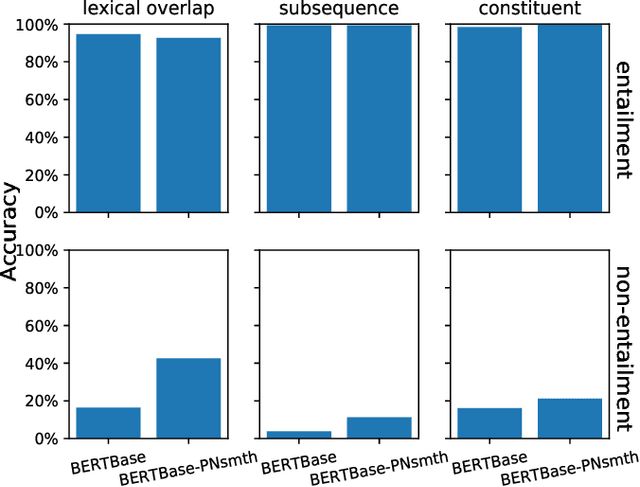
The ability of semantic reasoning over the sentence pair is essential for many natural language understanding tasks, e.g., natural language inference and machine reading comprehension. A recent significant improvement in these tasks comes from BERT. As reported, the next sentence prediction (NSP) in BERT, which learns the contextual relationship between two sentences, is of great significance for downstream problems with sentence-pair input. Despite the effectiveness of NSP, we suggest that NSP still lacks the essential signal to distinguish between entailment and shallow correlation. To remedy this, we propose to augment the NSP task to a 3-class categorization task, which includes a category for previous sentence prediction (PSP). The involvement of PSP encourages the model to focus on the informative semantics to determine the sentence order, thereby improves the ability of semantic understanding. This simple modification yields remarkable improvement against vanilla BERT. To further incorporate the document-level information, the scope of NSP and PSP is expanded into a broader range, i.e., NSP and PSP also include close but nonsuccessive sentences, the noise of which is mitigated by the label-smoothing technique. Both qualitative and quantitative experimental results demonstrate the effectiveness of the proposed method. Our method consistently improves the performance on the NLI and MRC benchmarks, including the challenging HANS dataset~\cite{hans}, suggesting that the document-level task is still promising for the pre-training.
Open Named Entity Modeling from Embedding Distribution
Aug 31, 2019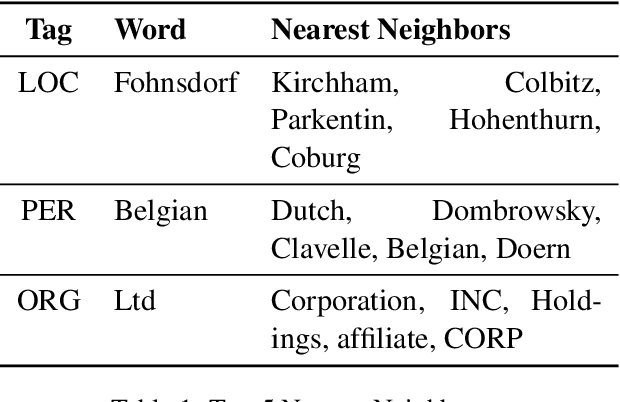
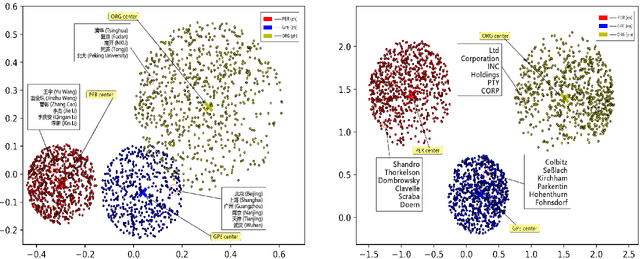

In this paper, we report our discovery on named entity distribution in general word embedding space, which helps an open definition on multilingual named entity definition rather than previous closed and constraint definition on named entities through a named entity dictionary, which is usually derived from huaman labor and replies on schedual update. Our initial visualization of monolingual word embeddings indicates named entities tend to gather together despite of named entity types and language difference, which enable us to model all named entities using a specific geometric structure inside embedding space,namely, the named entity hypersphere. For monolingual case, the proposed named entity model gives an open description on diverse named entity types and different languages. For cross-lingual case, mapping the proposed named entity model provides a novel way to build named entity dataset for resource-poor languages. At last, the proposed named entity model may be shown as a very useful clue to significantly enhance state-of-the-art named entity recognition systems generally.
Detect Camouflaged Spam Content via StoneSkipping: Graph and Text Joint Embedding for Chinese Character Variation Representation
Aug 30, 2019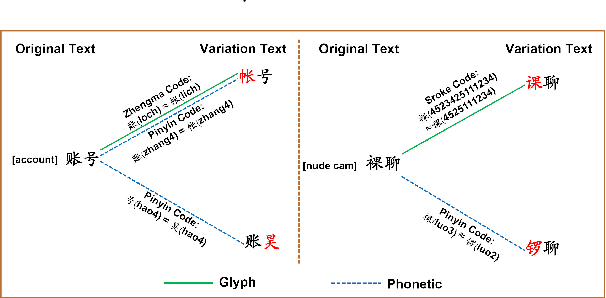
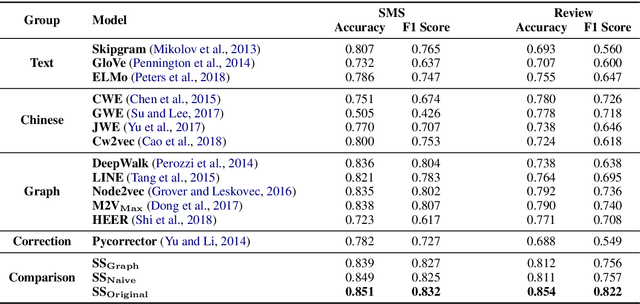
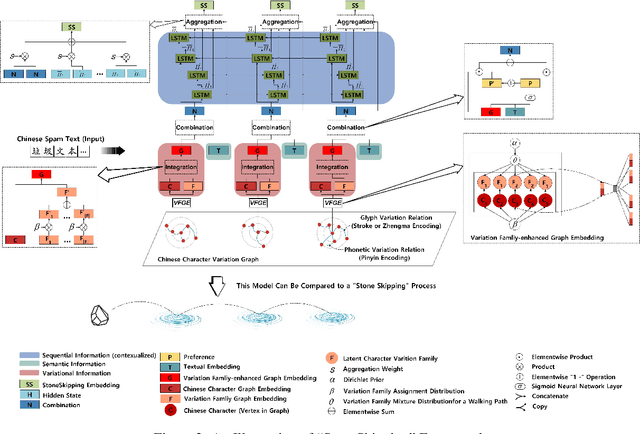
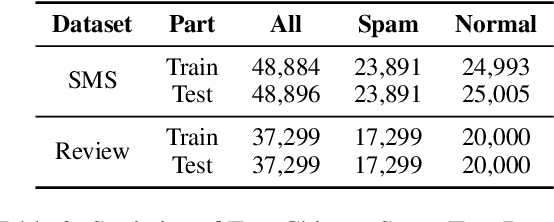
The task of Chinese text spam detection is very challenging due to both glyph and phonetic variations of Chinese characters. This paper proposes a novel framework to jointly model Chinese variational, semantic, and contextualized representations for Chinese text spam detection task. In particular, a Variation Family-enhanced Graph Embedding (VFGE) algorithm is designed based on a Chinese character variation graph. The VFGE can learn both the graph embeddings of the Chinese characters (local) and the latent variation families (global). Furthermore, an enhanced bidirectional language model, with a combination gate function and an aggregation learning function, is proposed to integrate the graph and text information while capturing the sequential information. Extensive experiments have been conducted on both SMS and review datasets, to show the proposed method outperforms a series of state-of-the-art models for Chinese spam detection.
StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding
Aug 16, 2019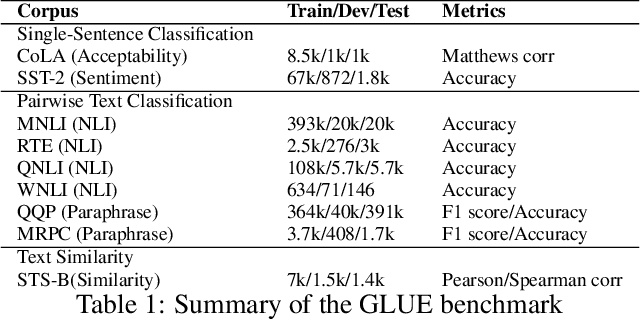

Recently, the pre-trained language model, BERT, has attracted a lot of attention in natural language understanding (NLU), and achieved state-of-the-art accuracy in various NLU tasks, such as sentiment classification, natural language inference, semantic textual similarity and question answering. Inspired by the linearization exploration work of Elman, we extend BERT to a new model, StructBERT, by incorporating language structures into pre-training. Specifically, we pre-train StructBERT with two auxiliary tasks to make the most of the sequential order of words and sentences, which leverage language structures at the word and sentence levels, respectively. As a result, the new model is adapted to different levels of language understanding required by downstream tasks. The StructBERT with structural pre-training gives surprisingly good empirical results on a variety of downstream tasks, including pushing the state-of-the-art on the GLUE benchmark to 84.5 (with Top 1 achievement on the Leaderboard at the time of paper submission), the F1 score on SQuAD v1.1 question answering to 93.0, the accuracy on SNLI to 91.7.
Syntax-aware Neural Semantic Role Labeling
Jul 22, 2019
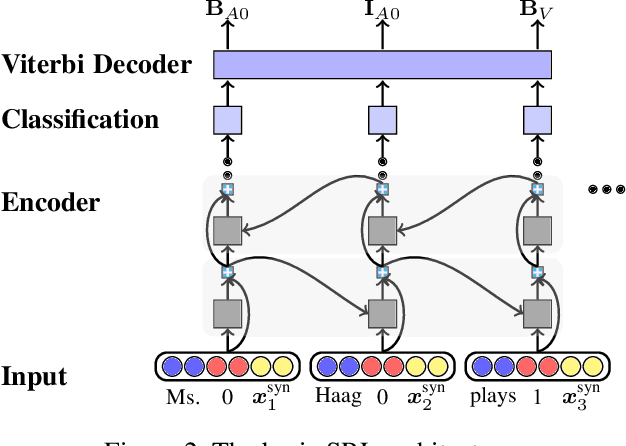
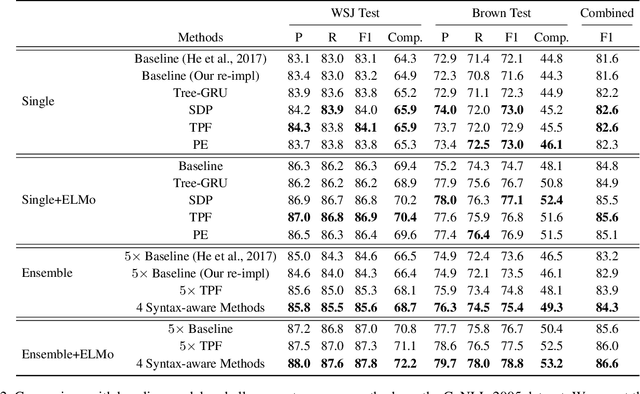
Semantic role labeling (SRL), also known as shallow semantic parsing, is an important yet challenging task in NLP. Motivated by the close correlation between syntactic and semantic structures, traditional discrete-feature-based SRL approaches make heavy use of syntactic features. In contrast, deep-neural-network-based approaches usually encode the input sentence as a word sequence without considering the syntactic structures. In this work, we investigate several previous approaches for encoding syntactic trees, and make a thorough study on whether extra syntax-aware representations are beneficial for neural SRL models. Experiments on the benchmark CoNLL-2005 dataset show that syntax-aware SRL approaches can effectively improve performance over a strong baseline with external word representations from ELMo. With the extra syntax-aware representations, our approaches achieve new state-of-the-art 85.6 F1 (single model) and 86.6 F1 (ensemble) on the test data, outperforming the corresponding strong baselines with ELMo by 0.8 and 1.0, respectively. Detailed error analysis are conducted to gain more insights on the investigated approaches.