 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Heterogeneous Multi-Robot Collaborative Exploration for Indoor and Outdoor 3D Environments
Apr 26, 2026Heterogeneous multi-robot systems feature significant adaptability for complex environments. However, effective collaboration that fully exploits the robots' potential remains a core challenge. This paper proposes a decentralized collaborative framework for heterogeneous multi-robot systems to autonomously explore indoor and outdoor 3D environments. First, a basic perception map that integrates terrain and observation metrics is designed. Improved supervoxel segmentation is developed to simplify the map structure and form a high-level representation that supports lightweight communication. Second, the traversal and observation capabilities of heterogeneous robots are modeled to evaluate the requirements of task views derived from incomplete supervoxels. These task views are grouped by requirements and clustered to streamline assignment. Subsequently, the view-cluster assignment is formulated as a heterogeneous multi-depot multi-traveling salesman problem (HMDMTSP) that incorporates constraints between view-cluster requirements and robot capabilities. An improved genetic algorithm is developed to efficiently solve this problem while ensuring global consistency. Based on the assignments, redundant views within clusters are eliminated to refine exploration routes. Finally, conflicts between robots' motion paths are resolved. Simulations and field experiments in cluttered indoor and outdoor environments demonstrate that our approach effectively coordinates exploration tasks among heterogeneous robots, achieving superior exploration efficiency and communication savings compared to state-of-the-art approaches.
Multimodal Backdoor Attack on VLMs for Autonomous Driving via Graffiti and Cross-Lingual Triggers
Apr 06, 2026Visual language model (VLM) is rapidly being integrated into safety-critical systems such as autonomous driving, making it an important attack surface for potential backdoor attacks. Existing backdoor attacks mainly rely on unimodal, explicit, and easily detectable triggers, making it difficult to construct both covert and stable attack channels in autonomous driving scenarios. GLA introduces two naturalistic triggers: graffiti-based visual patterns generated via stable diffusion inpainting, which seamlessly blend into urban scenes, and cross-language text triggers, which introduce distributional shifts while maintaining semantic consistency to build robust language-side trigger signals. Experiments on DriveVLM show that GLA requires only a 10\% poisoning ratio to achieve a 90\% Attack Success Rate (ASR) and a 0\% False Positive Rate (FPR). More insidiously, the backdoor does not weaken the model on clean tasks, but instead improves metrics such as BLEU-1, making it difficult for traditional performance-degradation-based detection methods to identify the attack. This study reveals underestimated security threats in self-driving VLMs and provides a new attack paradigm for backdoor evaluation in safety-critical multimodal systems.
Enhancing CTR Prediction with De-correlated Expert Networks
May 23, 2025Modeling feature interactions is essential for accurate click-through rate (CTR) prediction in advertising systems. Recent studies have adopted the Mixture-of-Experts (MoE) approach to improve performance by ensembling multiple feature interaction experts. These studies employ various strategies, such as learning independent embedding tables for each expert or utilizing heterogeneous expert architectures, to differentiate the experts, which we refer to expert \emph{de-correlation}. However, it remains unclear whether these strategies effectively achieve de-correlated experts. To address this, we propose a De-Correlated MoE (D-MoE) framework, which introduces a Cross-Expert De-Correlation loss to minimize expert correlations.Additionally, we propose a novel metric, termed Cross-Expert Correlation, to quantitatively evaluate the expert de-correlation degree. Based on this metric, we identify a key finding for MoE framework design: \emph{different de-correlation strategies are mutually compatible, and progressively employing them leads to reduced correlation and enhanced performance}.Extensive experiments have been conducted to validate the effectiveness of D-MoE and the de-correlation principle. Moreover, online A/B testing on Tencent's advertising platforms demonstrates that D-MoE achieves a significant 1.19\% Gross Merchandise Volume (GMV) lift compared to the Multi-Embedding MoE baseline.
CoCo-Bench: A Comprehensive Code Benchmark For Multi-task Large Language Model Evaluation
Apr 29, 2025Large language models (LLMs) play a crucial role in software engineering, excelling in tasks like code generation and maintenance. However, existing benchmarks are often narrow in scope, focusing on a specific task and lack a comprehensive evaluation framework that reflects real-world applications. To address these gaps, we introduce CoCo-Bench (Comprehensive Code Benchmark), designed to evaluate LLMs across four critical dimensions: code understanding, code generation, code modification, and code review. These dimensions capture essential developer needs, ensuring a more systematic and representative evaluation. CoCo-Bench includes multiple programming languages and varying task difficulties, with rigorous manual review to ensure data quality and accuracy. Empirical results show that CoCo-Bench aligns with existing benchmarks while uncovering significant variations in model performance, effectively highlighting strengths and weaknesses. By offering a holistic and objective evaluation, CoCo-Bench provides valuable insights to guide future research and technological advancements in code-oriented LLMs, establishing a reliable benchmark for the field.
Human-Like Decision Making: Document-level Aspect Sentiment Classification via Hierarchical Reinforcement Learning
Oct 21, 2019
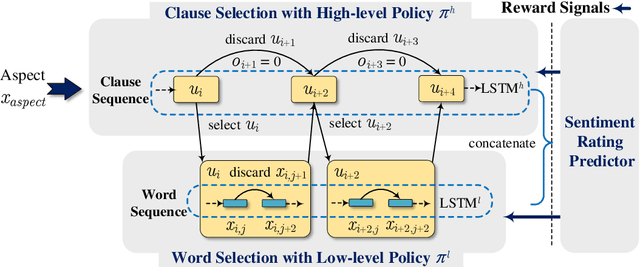
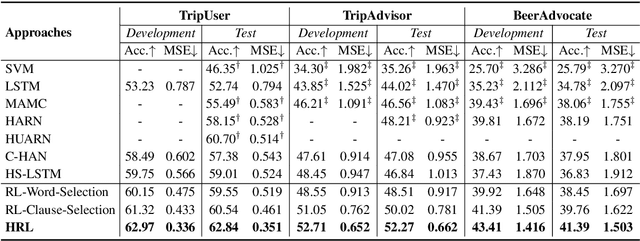
Recently, neural networks have shown promising results on Document-level Aspect Sentiment Classification (DASC). However, these approaches often offer little transparency w.r.t. their inner working mechanisms and lack interpretability. In this paper, to simulating the steps of analyzing aspect sentiment in a document by human beings, we propose a new Hierarchical Reinforcement Learning (HRL) approach to DASC. This approach incorporates clause selection and word selection strategies to tackle the data noise problem in the task of DASC. First, a high-level policy is proposed to select aspect-relevant clauses and discard noisy clauses. Then, a low-level policy is proposed to select sentiment-relevant words and discard noisy words inside the selected clauses. Finally, a sentiment rating predictor is designed to provide reward signals to guide both clause and word selection. Experimental results demonstrate the impressive effectiveness of the proposed approach to DASC over the state-of-the-art baselines.