 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Navigation for Autonomous Vehicles: An Open-source Hands-on Robotics Course at MIT
Jun 01, 2022
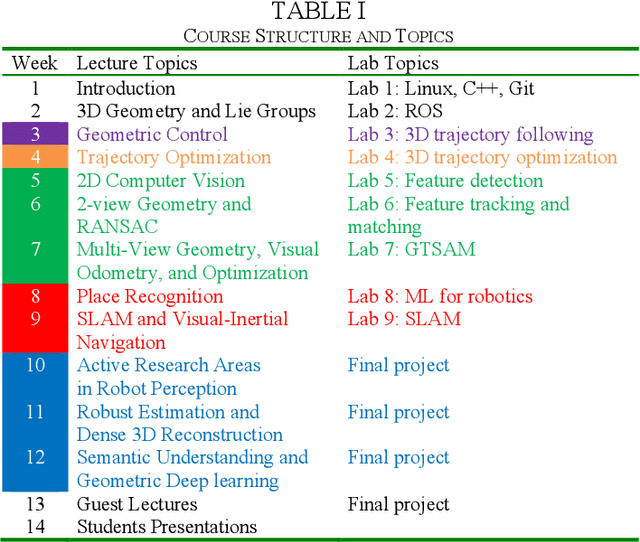
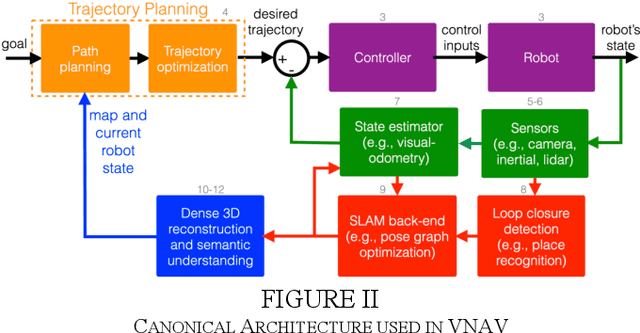
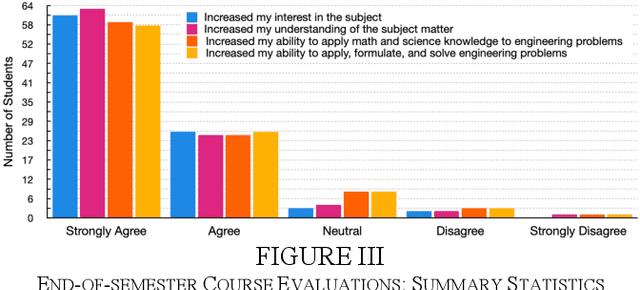
This paper reports on the development, execution, and open-sourcing of a new robotics course at MIT. The course is a modern take on "Visual Navigation for Autonomous Vehicles" (VNAV) and targets first-year graduate students and senior undergraduates with prior exposure to robotics. VNAV has the goal of preparing the students to perform research in robotics and vision-based navigation, with emphasis on drones and self-driving cars. The course spans the entire autonomous navigation pipeline; as such, it covers a broad set of topics, including geometric control and trajectory optimization, 2D and 3D computer vision, visual and visual-inertial odometry, place recognition, simultaneous localization and mapping, and geometric deep learning for perception. VNAV has three key features. First, it bridges traditional computer vision and robotics courses by exposing the challenges that are specific to embodied intelligence, e.g., limited computation and need for just-in-time and robust perception to close the loop over control and decision making. Second, it strikes a balance between depth and breadth by combining rigorous technical notes (including topics that are less explored in typical robotics courses, e.g., on-manifold optimization) with slides and videos showcasing the latest research results. Third, it provides a compelling approach to hands-on robotics education by leveraging a physical drone platform (mostly suitable for small residential courses) and a photo-realistic Unity-based simulator (open-source and scalable to large online courses). VNAV has been offered at MIT in the Falls of 2018-2021 and is now publicly available on MIT OpenCourseWare (OCW).
LAMP 2.0: A Robust Multi-Robot SLAM System for Operation in Challenging Large-Scale Underground Environments
May 31, 2022
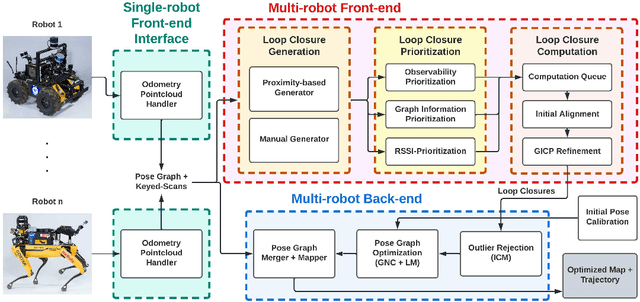
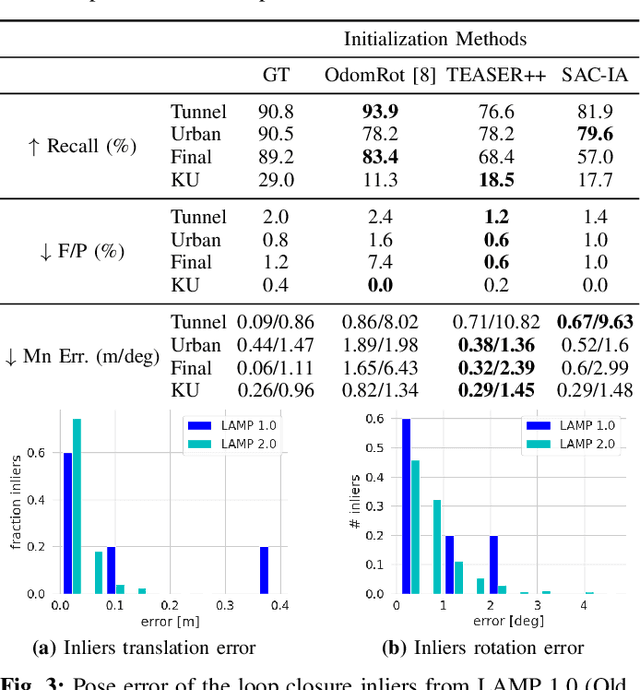
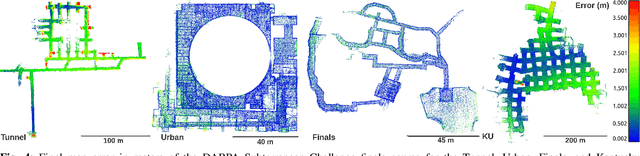
Search and rescue with a team of heterogeneous mobile robots in unknown and large-scale underground environments requires high-precision localization and mapping. This crucial requirement is faced with many challenges in complex and perceptually-degraded subterranean environments, as the onboard perception system is required to operate in off-nominal conditions (poor visibility due to darkness and dust, rugged and muddy terrain, and the presence of self-similar and ambiguous scenes). In a disaster response scenario and in the absence of prior information about the environment, robots must rely on noisy sensor data and perform Simultaneous Localization and Mapping (SLAM) to build a 3D map of the environment and localize themselves and potential survivors. To that end, this paper reports on a multi-robot SLAM system developed by team CoSTAR in the context of the DARPA Subterranean Challenge. We extend our previous work, LAMP, by incorporating a single-robot front-end interface that is adaptable to different odometry sources and lidar configurations, a scalable multi-robot front-end to support inter- and intra-robot loop closure detection for large scale environments and multi-robot teams, and a robust back-end equipped with an outlier-resilient pose graph optimization based on Graduated Non-Convexity. We provide a detailed ablation study on the multi-robot front-end and back-end, and assess the overall system performance in challenging real-world datasets collected across mines, power plants, and caves in the United States. We also release our multi-robot back-end datasets (and the corresponding ground truth), which can serve as challenging benchmarks for large-scale underground SLAM.
Loop Closure Prioritization for Efficient and Scalable Multi-Robot SLAM
May 24, 2022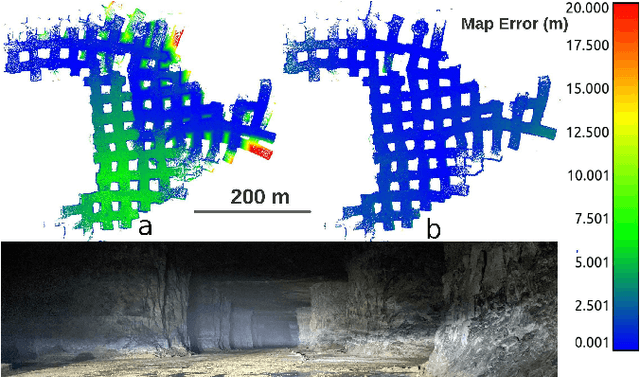
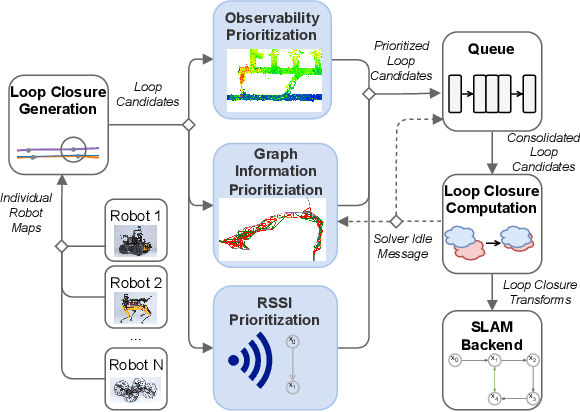
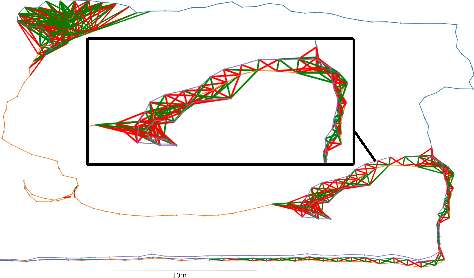
Multi-robot SLAM systems in GPS-denied environments require loop closures to maintain a drift-free centralized map. With an increasing number of robots and size of the environment, checking and computing the transformation for all the loop closure candidates becomes computationally infeasible. In this work, we describe a loop closure module that is able to prioritize which loop closures to compute based on the underlying pose graph, the proximity to known beacons, and the characteristics of the point clouds. We validate this system in the context of the DARPA Subterranean Challenge and on numerous challenging underground datasets and demonstrate the ability of this system to generate and maintain a map with low error. We find that our proposed techniques are able to select effective loop closures which results in 51% mean reduction in median error when compared to an odometric solution and 75% mean reduction in median error when compared to a baseline version of this system with no prioritization. We also find our proposed system is able to find a lower error in the mission time of one hour when compared to a system that processes every possible loop closure in four and a half hours.
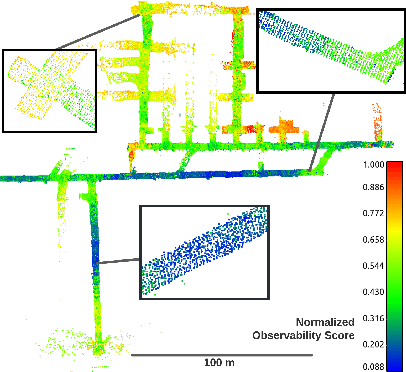
LOCUS 2.0: Robust and Computationally Efficient Lidar Odometry for Real-Time Underground 3D Mapping
May 24, 2022
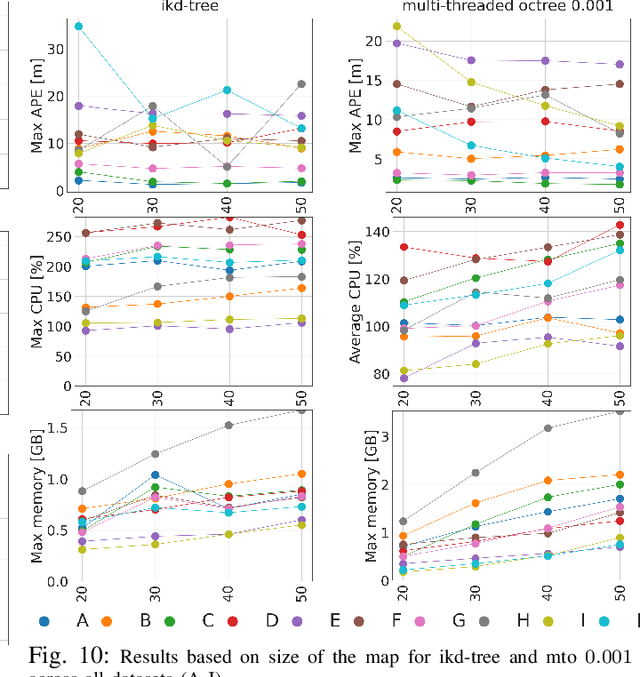
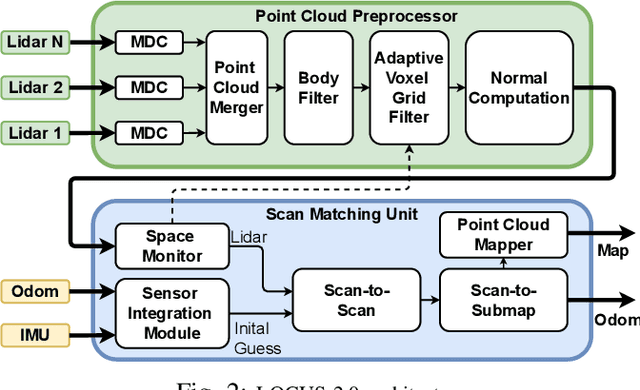
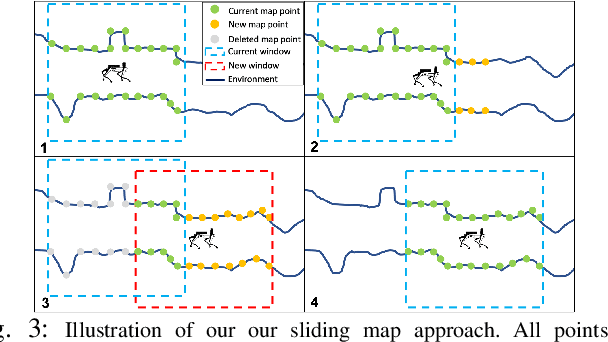
Lidar odometry has attracted considerable attention as a robust localization method for autonomous robots operating in complex GNSS-denied environments. However, achieving reliable and efficient performance on heterogeneous platforms in large-scale environments remains an open challenge due to the limitations of onboard computation and memory resources needed for autonomous operation. In this work, we present LOCUS 2.0, a robust and computationally-efficient \lidar odometry system for real-time underground 3D mapping. LOCUS 2.0 includes a novel normals-based \morrell{Generalized Iterative Closest Point (GICP)} formulation that reduces the computation time of point cloud alignment, an adaptive voxel grid filter that maintains the desired computation load regardless of the environment's geometry, and a sliding-window map approach that bounds the memory consumption. The proposed approach is shown to be suitable to be deployed on heterogeneous robotic platforms involved in large-scale explorations under severe computation and memory constraints. We demonstrate LOCUS 2.0, a key element of the CoSTAR team's entry in the DARPA Subterranean Challenge, across various underground scenarios. We release LOCUS 2.0 as an open-source library and also release a \lidar-based odometry dataset in challenging and large-scale underground environments. The dataset features legged and wheeled platforms in multiple environments including fog, dust, darkness, and geometrically degenerate surroundings with a total of $11~h$ of operations and $16~km$ of distance traveled.
Monitoring of Perception Systems: Deterministic, Probabilistic, and Learning-based Fault Detection and Identification
May 22, 2022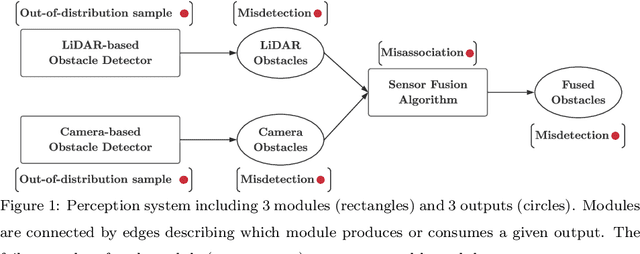
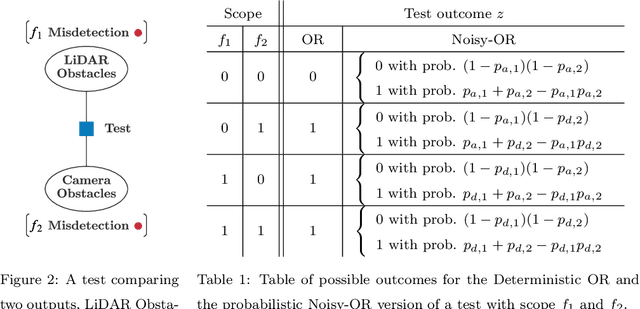

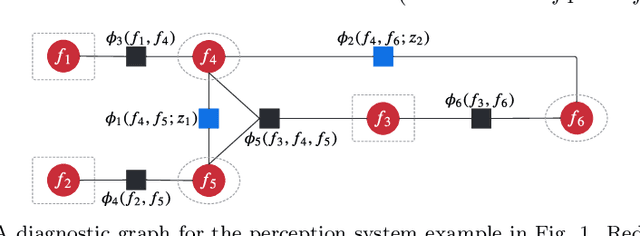
This paper investigates runtime monitoring of perception systems. Perception is a critical component of high-integrity applications of robotics and autonomous systems, such as self-driving cars. In these applications, failure of perception systems may put human life at risk, and a broad adoption of these technologies requires the development of methodologies to guarantee and monitor safe operation. Despite the paramount importance of perception, currently there is no formal approach for system-level perception monitoring. In this paper, we formalize the problem of runtime fault detection and identification in perception systems and present a framework to model diagnostic information using a diagnostic graph. We then provide a set of deterministic, probabilistic, and learning-based algorithms that use diagnostic graphs to perform fault detection and identification. Moreover, we investigate fundamental limits and provide deterministic and probabilistic guarantees on the fault detection and identification results. We conclude the paper with an extensive experimental evaluation, which recreates several realistic failure modes in the LGSVL open-source autonomous driving simulator, and applies the proposed system monitors to a state-of-the-art autonomous driving software stack (Baidu's Apollo Auto). The results show that the proposed system monitors outperform baselines, have the potential of preventing accidents in realistic autonomous driving scenarios, and incur a negligible computational overhead.
Hydra: A Real-time Spatial Perception Engine for 3D Scene Graph Construction and Optimization
Jan 31, 2022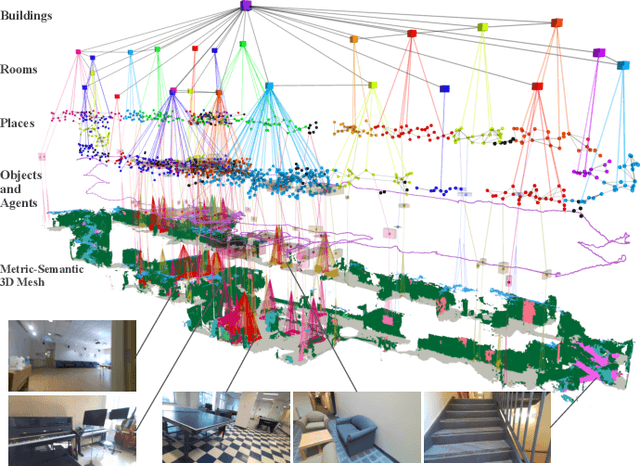
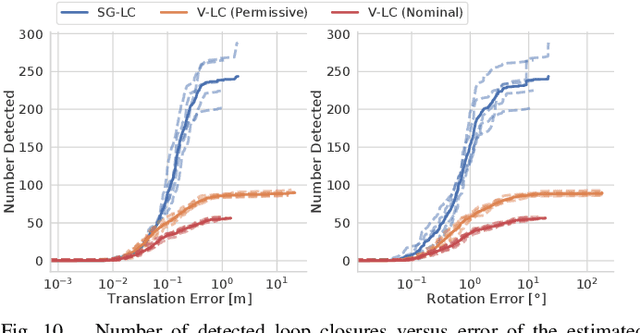
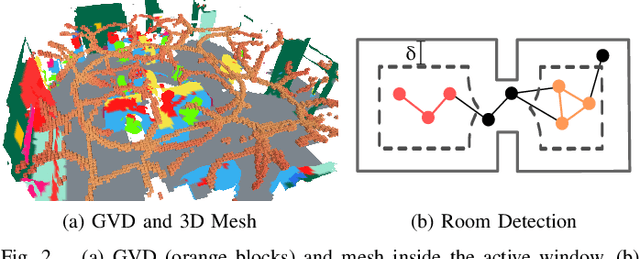
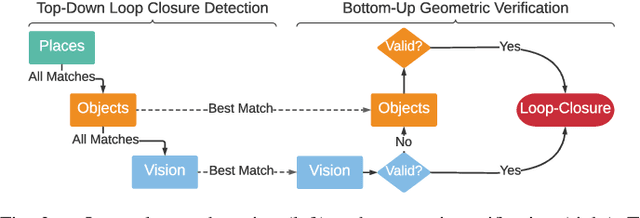
3D scene graphs have recently emerged as a powerful high-level representation of 3D environments. A 3D scene graph describes the environment as a layered graph where nodes represent spatial concepts at multiple levels of abstraction and edges represent relations between concepts. While 3D scene graphs can serve as an advanced "mental model" for robots, how to build such a rich representation in real-time is still uncharted territory. This paper describes the first real-time Spatial Perception engINe (SPIN), a suite of algorithms to build a 3D scene graph from sensor data in real-time. Our first contribution is to develop real-time algorithms to incrementally construct the layers of a scene graph as the robot explores the environment; these algorithms build a local Euclidean Signed Distance Function (ESDF) around the current robot location, extract a topological map of places from the ESDF, and then segment the places into rooms using an approach inspired by community-detection techniques. Our second contribution is to investigate loop closure detection and optimization in 3D scene graphs. We show that 3D scene graphs allow defining hierarchical descriptors for loop closure detection; our descriptors capture statistics across layers in the scene graph, ranging from low-level visual appearance, to summary statistics about objects and places. We then propose the first algorithm to optimize a 3D scene graph in response to loop closures; our approach relies on embedded deformation graphs to simultaneously correct all layers of the scene graph. We implement the proposed SPIN into a highly parallelized architecture, named Hydra, that combines fast early and mid-level perception processes with slower high-level perception. We evaluate Hydra on simulated and real data and show it is able to reconstruct 3D scene graphs with an accuracy comparable with batch offline methods, while running online.
Beyond Robustness: A Taxonomy of Approaches towards Resilient Multi-Robot Systems
Sep 25, 2021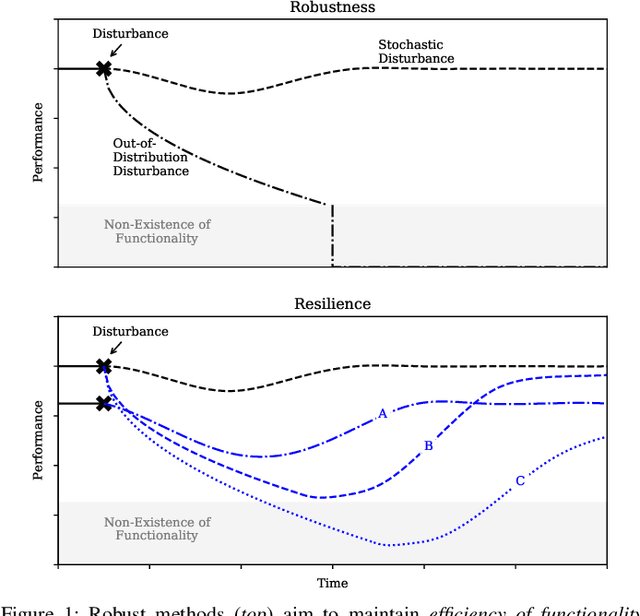
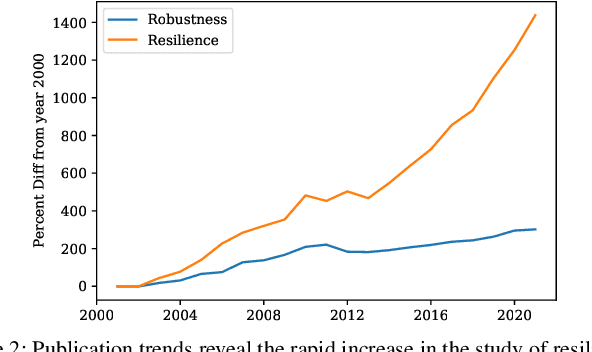

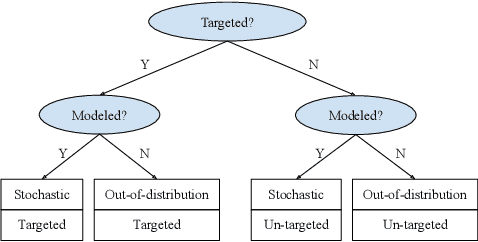
Robustness is key to engineering, automation, and science as a whole. However, the property of robustness is often underpinned by costly requirements such as over-provisioning, known uncertainty and predictive models, and known adversaries. These conditions are idealistic, and often not satisfiable. Resilience on the other hand is the capability to endure unexpected disruptions, to recover swiftly from negative events, and bounce back to normality. In this survey article, we analyze how resilience is achieved in networks of agents and multi-robot systems that are able to overcome adversity by leveraging system-wide complementarity, diversity, and redundancy - often involving a reconfiguration of robotic capabilities to provide some key ability that was not present in the system a priori. As society increasingly depends on connected automated systems to provide key infrastructure services (e.g., logistics, transport, and precision agriculture), providing the means to achieving resilient multi-robot systems is paramount. By enumerating the consequences of a system that is not resilient (fragile), we argue that resilience must become a central engineering design consideration. Towards this goal, the community needs to gain clarity on how it is defined, measured, and maintained. We address these questions across foundational robotics domains, spanning perception, control, planning, and learning. One of our key contributions is a formal taxonomy of approaches, which also helps us discuss the defining factors and stressors for a resilient system. Finally, this survey article gives insight as to how resilience may be achieved. Importantly, we highlight open problems that remain to be tackled in order to reap the benefits of resilient robotic systems.
Certifiable Outlier-Robust Geometric Perception: Exact Semidefinite Relaxations and Scalable Global Optimization
Sep 07, 2021
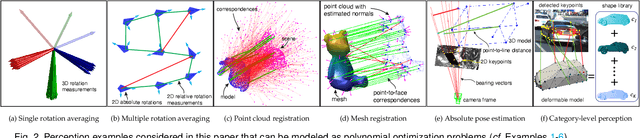

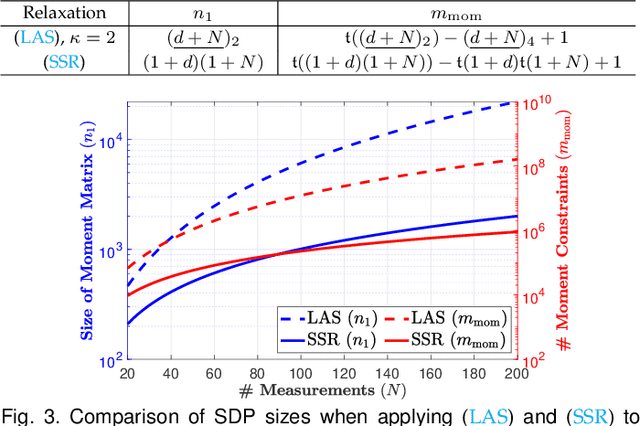
We propose the first general and scalable framework to design certifiable algorithms for robust geometric perception in the presence of outliers. Our first contribution is to show that estimation using common robust costs, such as truncated least squares (TLS), maximum consensus, Geman-McClure, Tukey's biweight, among others, can be reformulated as polynomial optimization problems (POPs). By focusing on the TLS cost, our second contribution is to exploit sparsity in the POP and propose a sparse semidefinite programming (SDP) relaxation that is much smaller than the standard Lasserre's hierarchy while preserving exactness, i.e., the SDP recovers the optimizer of the nonconvex POP with an optimality certificate. Our third contribution is to solve the SDP relaxations at an unprecedented scale and accuracy by presenting STRIDE, a solver that blends global descent on the convex SDP with fast local search on the nonconvex POP. Our fourth contribution is an evaluation of the proposed framework on six geometric perception problems including single and multiple rotation averaging, point cloud and mesh registration, absolute pose estimation, and category-level object pose and shape estimation. Our experiments demonstrate that (i) our sparse SDP relaxation is exact with up to 60%-90% outliers across applications; (ii) while still being far from real-time, STRIDE is up to 100 times faster than existing SDP solvers on medium-scale problems, and is the only solver that can solve large-scale SDPs with hundreds of thousands of constraints to high accuracy; (iii) STRIDE provides a safeguard to existing fast heuristics for robust estimation (e.g., RANSAC or Graduated Non-Convexity), i.e., it certifies global optimality if the heuristic estimates are optimal, or detects and allows escaping local optima when the heuristic estimates are suboptimal.
Computation and Communication Co-Design for Real-Time Monitoring and Control in Multi-Agent Systems
Aug 09, 2021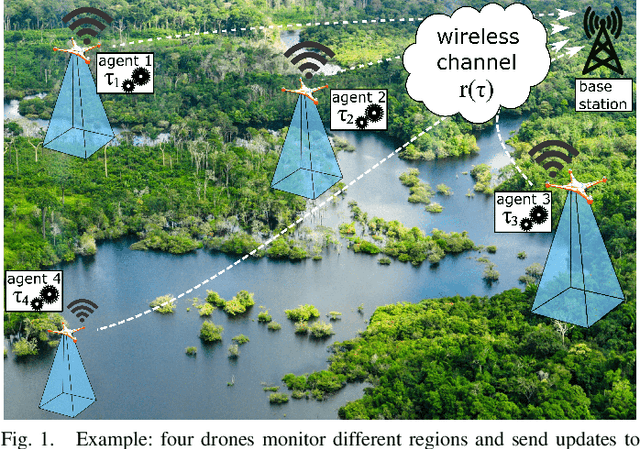
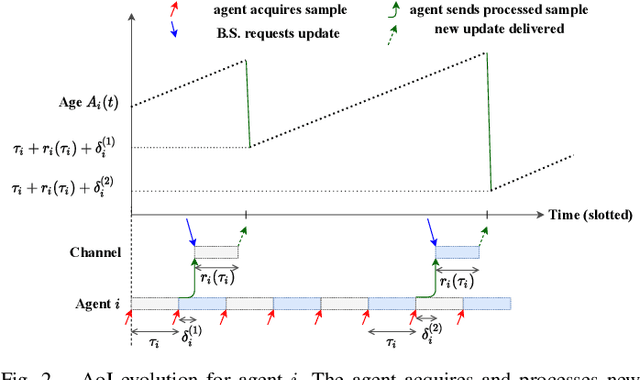
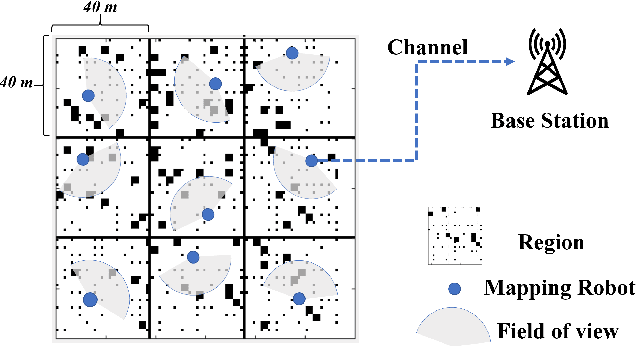
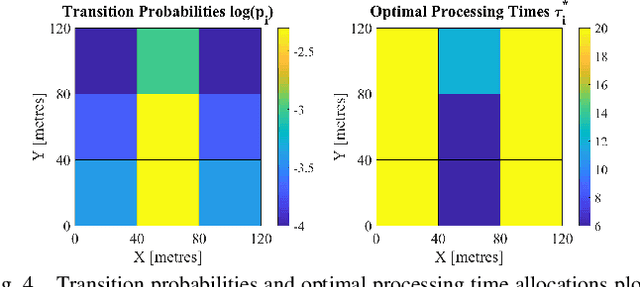
We investigate the problem of co-designing computation and communication in a multi-agent system (e.g. a sensor network or a multi-robot team). We consider the realistic setting where each agent acquires sensor data and is capable of local processing before sending updates to a base station, which is in charge of making decisions or monitoring phenomena of interest in real time. Longer processing at an agent leads to more informative updates but also larger delays, giving rise to a delay-accuracy-tradeoff in choosing the right amount of local processing at each agent. We assume that the available communication resources are limited due to interference, bandwidth, and power constraints. Thus, a scheduling policy needs to be designed to suitably share the communication channel among the agents. To that end, we develop a general formulation to jointly optimize the local processing at the agents and the scheduling of transmissions. Our novel formulation leverages the notion of Age of Information to quantify the freshness of data and capture the delays caused by computation and communication. We develop efficient resource allocation algorithms using the Whittle index approach and demonstrate our proposed algorithms in two practical applications: multi-agent occupancy grid mapping in time-varying environments, and ride sharing in autonomous vehicle networks. Our experiments show that the proposed co-design approach leads to a substantial performance improvement (18-82% in our tests).
Smooth Mesh Estimation from Depth Data using Non-Smooth Convex Optimization
Aug 06, 2021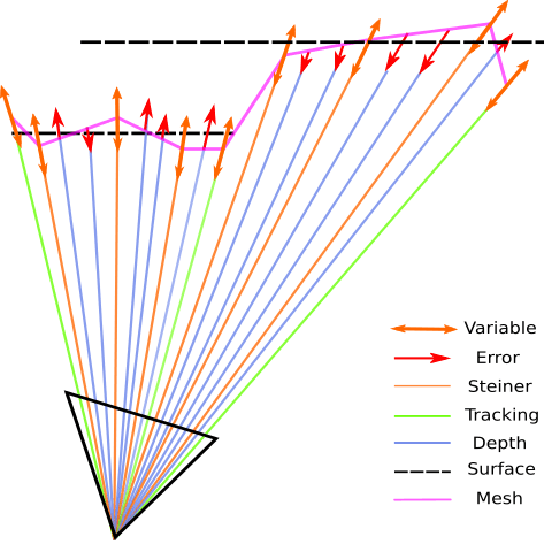
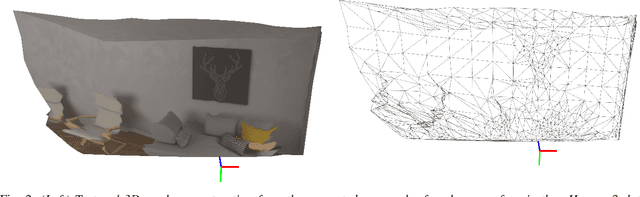
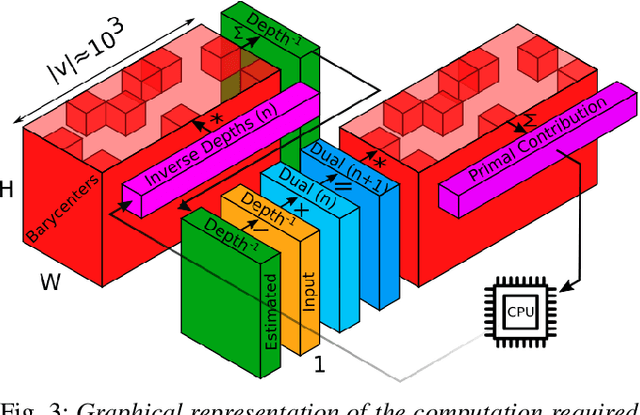
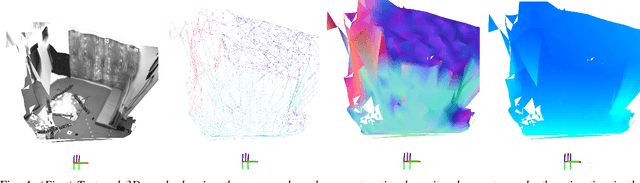
Meshes are commonly used as 3D maps since they encode the topology of the scene while being lightweight. Unfortunately, 3D meshes are mathematically difficult to handle directly because of their combinatorial and discrete nature. Therefore, most approaches generate 3D meshes of a scene after fusing depth data using volumetric or other representations. Nevertheless, volumetric fusion remains computationally expensive both in terms of speed and memory. In this paper, we leapfrog these intermediate representations and build a 3D mesh directly from a depth map and the sparse landmarks triangulated with visual odometry. To this end, we formulate a non-smooth convex optimization problem that we solve using a primal-dual method. Our approach generates a smooth and accurate 3D mesh that substantially improves the state-of-the-art on direct mesh reconstruction while running in real-time.