 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument-level Relation Extraction with Relation Correlations
Dec 20, 2022Document-level relation extraction faces two overlooked challenges: long-tail problem and multi-label problem. Previous work focuses mainly on obtaining better contextual representations for entity pairs, hardly address the above challenges. In this paper, we analyze the co-occurrence correlation of relations, and introduce it into DocRE task for the first time. We argue that the correlations can not only transfer knowledge between data-rich relations and data-scarce ones to assist in the training of tailed relations, but also reflect semantic distance guiding the classifier to identify semantically close relations for multi-label entity pairs. Specifically, we use relation embedding as a medium, and propose two co-occurrence prediction sub-tasks from both coarse- and fine-grained perspectives to capture relation correlations. Finally, the learned correlation-aware embeddings are used to guide the extraction of relational facts. Substantial experiments on two popular DocRE datasets are conducted, and our method achieves superior results compared to baselines. Insightful analysis also demonstrates the potential of relation correlations to address the above challenges.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Federated Learning from Pre-Trained Models: A Contrastive Learning Approach
Sep 21, 2022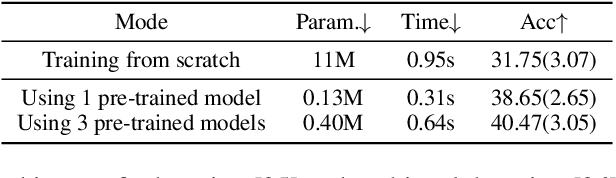
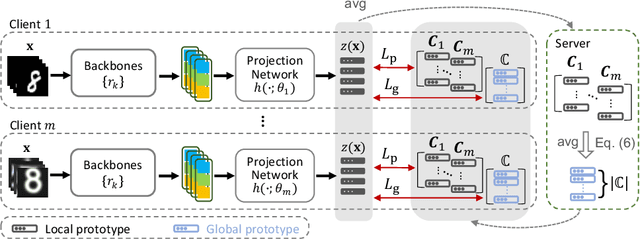
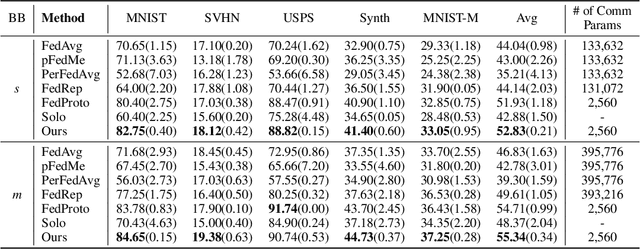
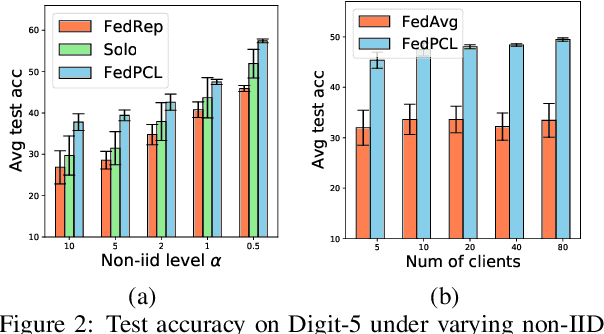
Federated Learning (FL) is a machine learning paradigm that allows decentralized clients to learn collaboratively without sharing their private data. However, excessive computation and communication demands pose challenges to current FL frameworks, especially when training large-scale models. To prevent these issues from hindering the deployment of FL systems, we propose a lightweight framework where clients jointly learn to fuse the representations generated by multiple fixed pre-trained models rather than training a large-scale model from scratch. This leads us to a more practical FL problem by considering how to capture more client-specific and class-relevant information from the pre-trained models and jointly improve each client's ability to exploit those off-the-shelf models. In this work, we design a Federated Prototype-wise Contrastive Learning (FedPCL) approach which shares knowledge across clients through their class prototypes and builds client-specific representations in a prototype-wise contrastive manner. Sharing prototypes rather than learnable model parameters allows each client to fuse the representations in a personalized way while keeping the shared knowledge in a compact form for efficient communication. We perform a thorough evaluation of the proposed FedPCL in the lightweight framework, measuring and visualizing its ability to fuse various pre-trained models on popular FL datasets.
The least-used key selection method for information retrieval in large-scale Cloud-based service repositories
Aug 16, 2022



As the number of devices connected to the Internet of Things (IoT) increases significantly, it leads to an exponential growth in the number of services that need to be processed and stored in the large-scale Cloud-based service repositories. An efficient service indexing model is critical for service retrieval and management of large-scale Cloud-based service repositories. The multilevel index model is the state-of-art service indexing model in recent years to improve service discovery and combination. This paper aims to optimize the model to consider the impact of unequal appearing probability of service retrieval request parameters and service input parameters on service retrieval and service addition operations. The least-used key selection method has been proposed to narrow the search scope of service retrieval and reduce its time. The experimental results show that the proposed least-used key selection method improves the service retrieval efficiency significantly compared with the designated key selection method in the case of the unequal appearing probability of parameters in service retrieval requests under three indexing models.
Recognizing Vector Graphics without Rasterization
Nov 12, 2021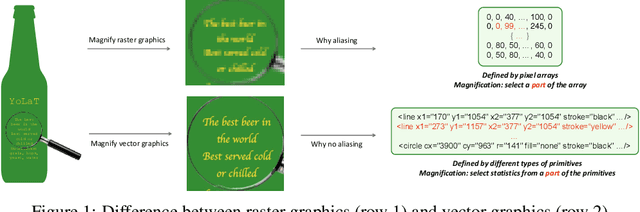
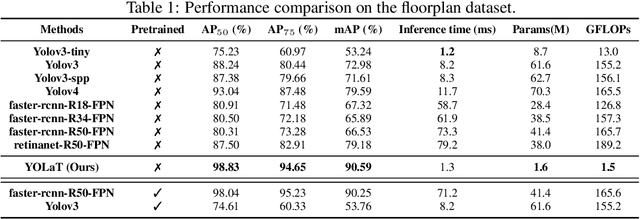
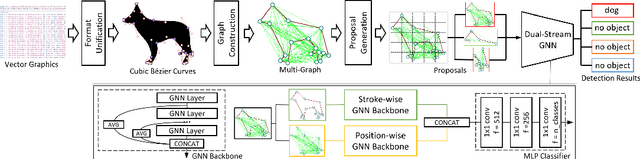
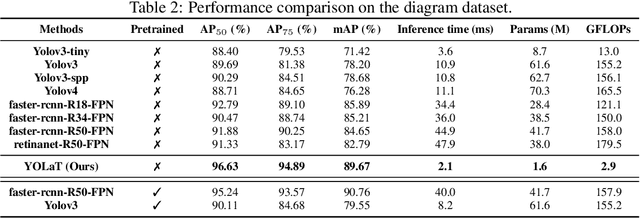
In this paper, we consider a different data format for images: vector graphics. In contrast to raster graphics which are widely used in image recognition, vector graphics can be scaled up or down into any resolution without aliasing or information loss, due to the analytic representation of the primitives in the document. Furthermore, vector graphics are able to give extra structural information on how low-level elements group together to form high level shapes or structures. These merits of graphic vectors have not been fully leveraged in existing methods. To explore this data format, we target on the fundamental recognition tasks: object localization and classification. We propose an efficient CNN-free pipeline that does not render the graphic into pixels (i.e. rasterization), and takes textual document of the vector graphics as input, called YOLaT (You Only Look at Text). YOLaT builds multi-graphs to model the structural and spatial information in vector graphics, and a dual-stream graph neural network is proposed to detect objects from the graph. Our experiments show that by directly operating on vector graphics, YOLaT out-performs raster-graphic based object detection baselines in terms of both average precision and efficiency.
Cloning one's voice using very limited data in the wild
Oct 08, 2021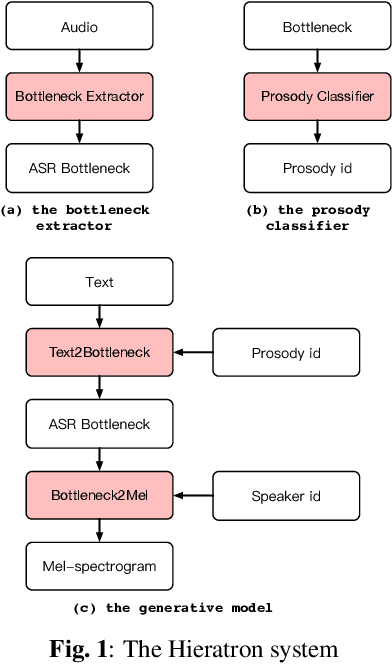
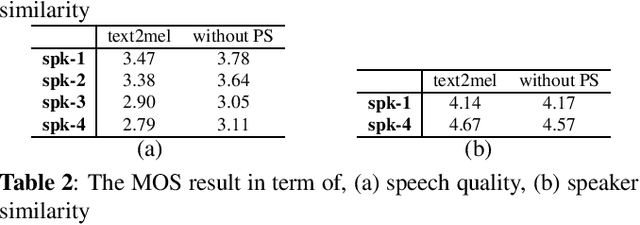
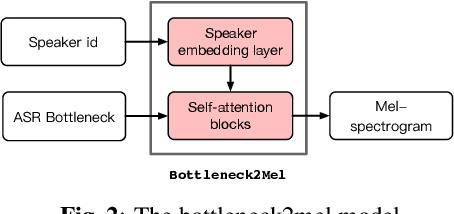
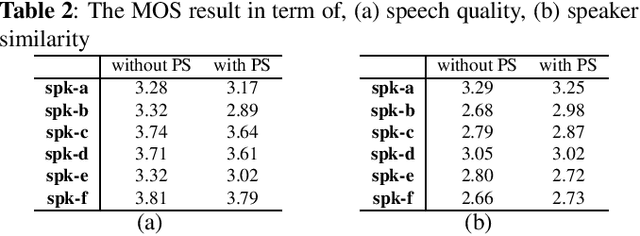
With the increasing popularity of speech synthesis products, the industry has put forward more requirements for personalized speech synthesis: (1) How to use low-resource, easily accessible data to clone a person's voice. (2) How to clone a person's voice while controlling the style and prosody. To solve the above two problems, we proposed the Hieratron model framework in which the prosody and timbre are modeled separately using two modules, therefore, the independent control of timbre and the other characteristics of audio can be achieved while generating speech. The practice shows that, for very limited target speaker data in the wild, Hieratron has obvious advantages over the traditional method, in addition to controlling the style and language of the generated speech, the mean opinion score on speech quality of the generated speech has also been improved by more than 0.2 points.
Full-Cycle Energy Consumption Benchmark for Low-Carbon Computer Vision
Aug 30, 2021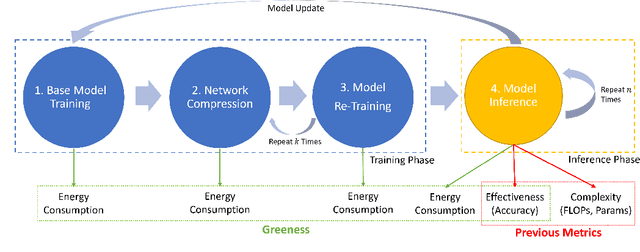
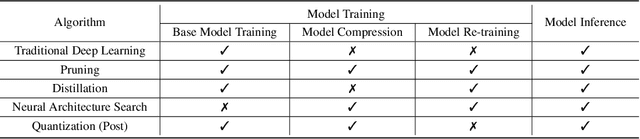

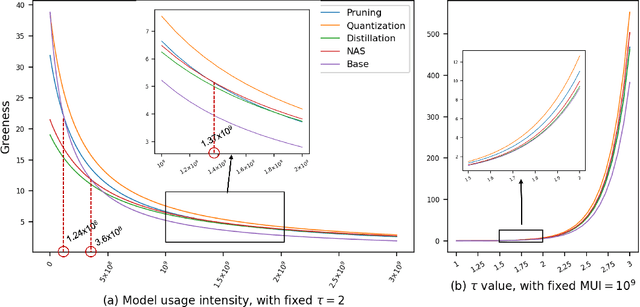
The energy consumption of deep learning models is increasing at a breathtaking rate, which raises concerns due to potential negative effects on carbon neutrality in the context of global warming and climate change. With the progress of efficient deep learning techniques, e.g., model compression, researchers can obtain efficient models with fewer parameters and smaller latency. However, most of the existing efficient deep learning methods do not explicitly consider energy consumption as a key performance indicator. Furthermore, existing methods mostly focus on the inference costs of the resulting efficient models, but neglect the notable energy consumption throughout the entire life cycle of the algorithm. In this paper, we present the first large-scale energy consumption benchmark for efficient computer vision models, where a new metric is proposed to explicitly evaluate the full-cycle energy consumption under different model usage intensity. The benchmark can provide insights for low carbon emission when selecting efficient deep learning algorithms in different model usage scenarios.
Towards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021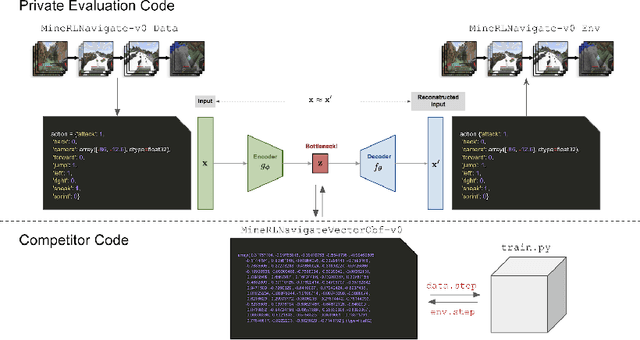

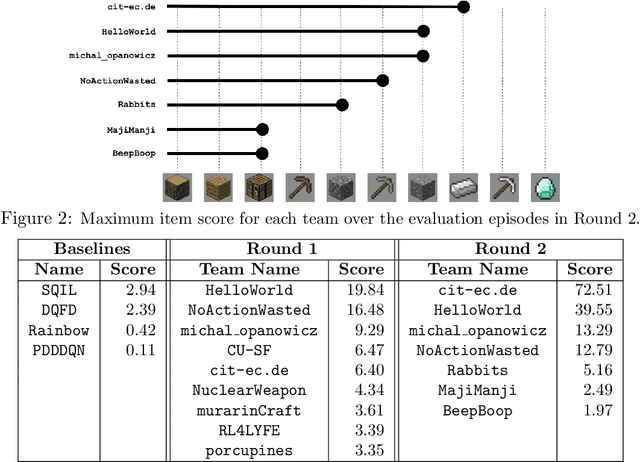
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.
Distantly Supervised Relation Extraction via Recursive Hierarchy-Interactive Attention and Entity-Order Perception
May 18, 2021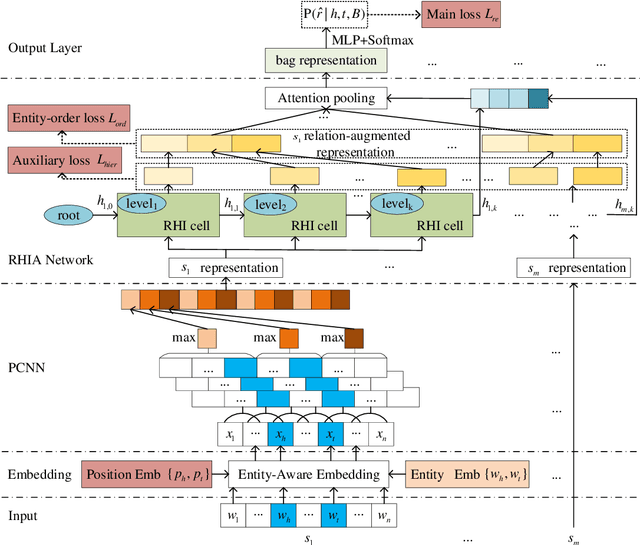
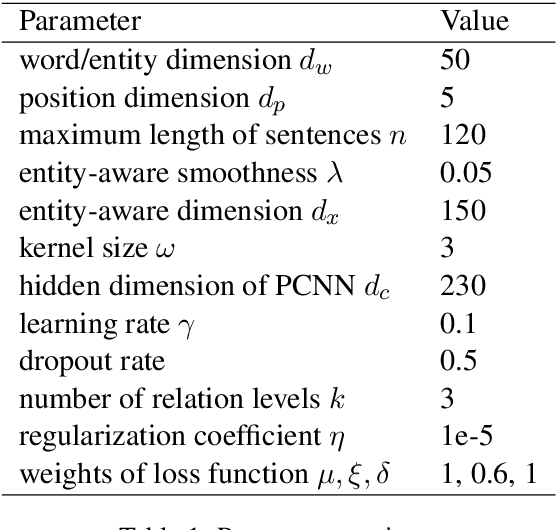
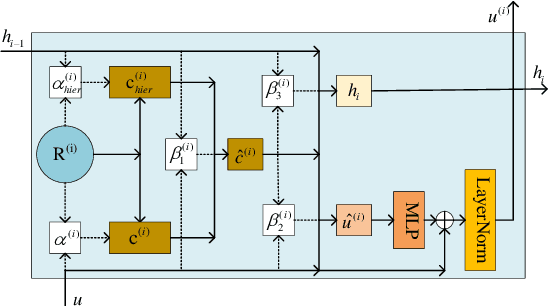

Distantly supervised relation extraction has drawn significant attention recently. However, almost all prior works ignore the fact that, in a sentence, the appearance order of two entities contributes to the understanding of its semantics. Furthermore, they leverage relation hierarchies but don't fully exploit the heuristic effect between relation levels, i.e., higher-level relations can give useful information to the lower ones. In this paper, we design a novel Recursive Hierarchy-Interactive Attention network (RHIA), which uses the hierarchical structure of the relation to model the interactive information between the relation levels to further handle long-tail relations. It generates relation-augmented sentence representations along hierarchical relation chains in a recursive structure. Besides, we introduce a newfangled training objective, called Entity-Order Perception (EOP), to make the sentence encoder retain more entity appearance information. Substantial experiments on the popular New York Times (NYT) dataset are conducted. Compared to prior baselines, our approach achieves state-of-the-art performance in terms of precision-recall (P-R) curves, AUC, Top-N precision and other evaluation metrics.
Human Object Interaction Detection using Two-Direction Spatial Enhancement and Exclusive Object Prior
May 07, 2021
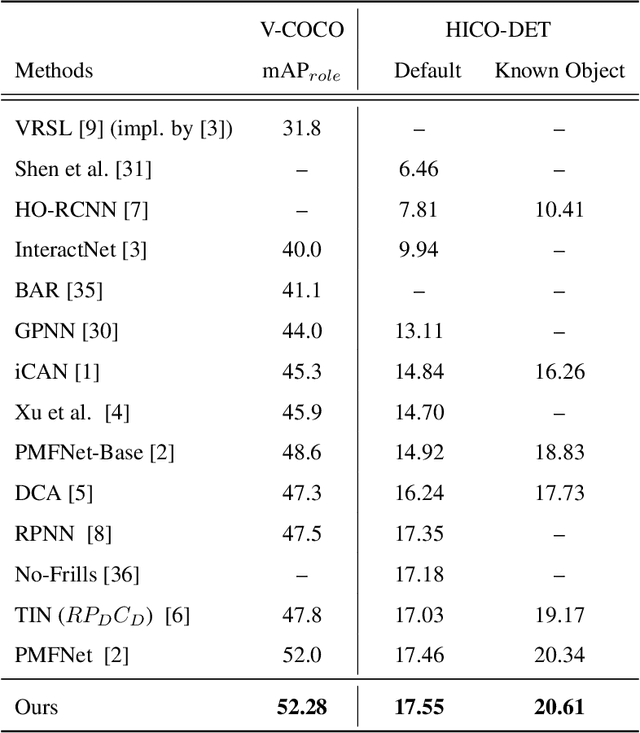
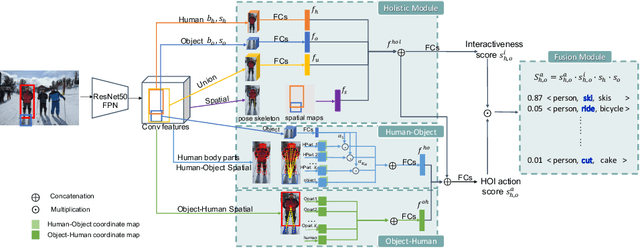

Human-Object Interaction (HOI) detection aims to detect visual relations between human and objects in images. One significant problem of HOI detection is that non-interactive human-object pair can be easily mis-grouped and misclassified as an action, especially when humans are close and performing similar actions in the scene. To address the mis-grouping problem, we propose a spatial enhancement approach to enforce fine-level spatial constraints in two directions from human body parts to the object center, and from object parts to the human center. At inference, we propose a human-object regrouping approach by considering the object-exclusive property of an action, where the target object should not be shared by more than one human. By suppressing non-interactive pairs, our approach can decrease the false positives. Experiments on V-COCO and HICO-DET datasets demonstrate our approach is more robust compared to the existing methods under the presence of multiple humans and objects in the scene.