 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling Multimodal Learning Challenges with Mixture-of-Expert: A Survey
May 22, 2026Mixture-of-Experts (MoE) presents a naturally compatible and scalable framework for multimodal learning, demonstrating strong adaptability across diverse modalities and tasks. Despite its growing success, a comprehensive and systematic review on the MoE metho addressing multimodal challenges remains lacking. Existing surveys tend to evaluate either multimodal learning or MoE independently from method taxonomy, overlooking the unique interplay between them. This survey fills that gap by answering a central question: \textit{How does MoE effectively resolve multimodal challenges?} We approach this from three key perspectives: (1) \textbf{MoE as an Efficient Multimodal Engine:} enabling scalable multimodal modeling by decoupling computational cost from parameter growth and mitigating modality redundancy through selective expert activation; (2) \textbf{MoE as a Multimodal Representation Learner:} integrating complementary multi-opinion expert knowledge to enrich alignment and interaction representations; and (3) \textbf{MoE as a Multimodal Adapter:} providing a modular and flexible mechanism to model imperfect data scenarios such as modality imbalance and missing modality. Through our extensive literature review, we identify critical research gaps, including interpretable routing, expert communication, modality integration, and lifelong multimodal learning. We position this survey as a foundation for future research toward interpretable and sustainable multimodal Mixture-of-Experts system.
Probing Routing-Conditional Calibration in Attention-Residual Transformers
May 11, 2026Post-hoc calibration is usually evaluated as a function of logits or softmax confidence alone, even as routing-augmented architectures increasingly accompany predictions with sample-specific internal routing traces and pair them with claims of calibration-relevant uncertainty. We ask a basic question: do these traces provide stable routing-specific evidence for post-hoc calibration beyond confidence? We study this in Attention-Residual transformers (Kimi Team, 2026) through a matched-confidence diagnostic suite that stratifies examples by routing-derived state, compares subgroup gaps against within-bin routing-permutation nulls, and evaluates matched post-hoc probes differing only in their auxiliary feature. Across our completed AR runs, scalar routing summaries do not provide stable evidence of routing-conditional miscalibration: weighted gaps remain small or seed-sensitive, and only $1$ of $30$ within-bin permutation tests rejects the conditional-null at $α=0.05$ (only on one seed; not stable across seeds in that cell). AR-CondCal, a minimal $2$-D Nadaraya--Watson probe on confidence and routing-depth variance, lies within the seed-variance band of matched confidence-only and predictive-entropy controls and does not reliably improve worst-routing-tertile ECE; bandwidth-sensitivity checks (Scott multiples, CV-NLL, global-ECE oracle) do not change this. A full-vector MLP over $(c, H_1, \ldots, H_L)$ can appear to improve over a linear confidence baseline, but the apparent gain disappears once a capacity-matched confidence-only MLP is included as a control, and shuffled routing profiles achieve comparable performance. Apparent routing-aware calibration gains in this AR setting should not be read as internal-state calibration until matched-confidence, bandwidth, capacity, and permutation controls rule out common confounds.
Calibration Attention: Instance-wise Temperature Scaling for Vision Transformers
Aug 12, 2025Probability calibration is critical when Vision Transformers are deployed in risk-sensitive applications. The standard fix, post-hoc temperature scaling, uses a single global scalar and requires a held-out validation set. We introduce Calibration Attention (CalAttn), a drop-in module that learns an adaptive, per-instance temperature directly from the ViT's CLS token. Across CIFAR-10/100, MNIST, Tiny-ImageNet, and ImageNet-1K, CalAttn reduces calibration error by up to 4x on ViT-224, DeiT, and Swin, while adding under 0.1 percent additional parameters. The learned temperatures cluster tightly around 1.0, in contrast to the large global values used by standard temperature scaling. CalAttn is simple, efficient, and architecture-agnostic, and yields more trustworthy probabilities without sacrificing accuracy. Code: [https://github.com/EagleAdelaide/CalibrationAttention-CalAttn-](https://github.com/EagleAdelaide/CalibrationAttention-CalAttn-)
PostHoc FREE Calibrating on Kolmogorov Arnold Networks
Mar 03, 2025Kolmogorov Arnold Networks (KANs) are neural architectures inspired by the Kolmogorov Arnold representation theorem that leverage B Spline parameterizations for flexible, locally adaptive function approximation. Although KANs can capture complex nonlinearities beyond those modeled by standard MultiLayer Perceptrons (MLPs), they frequently exhibit miscalibrated confidence estimates manifesting as overconfidence in dense data regions and underconfidence in sparse areas. In this work, we systematically examine the impact of four critical hyperparameters including Layer Width, Grid Order, Shortcut Function, and Grid Range on the calibration of KANs. Furthermore, we introduce a novel TemperatureScaled Loss (TSL) that integrates a temperature parameter directly into the training objective, dynamically adjusting the predictive distribution during learning. Both theoretical analysis and extensive empirical evaluations on standard benchmarks demonstrate that TSL significantly reduces calibration errors, thereby improving the reliability of probabilistic predictions. Overall, our study provides actionable insights into the design of spline based neural networks and establishes TSL as a robust loss solution for enhancing calibration.
Free-Knots Kolmogorov-Arnold Network: On the Analysis of Spline Knots and Advancing Stability
Jan 16, 2025



Kolmogorov-Arnold Neural Networks (KANs) have gained significant attention in the machine learning community. However, their implementation often suffers from poor training stability and heavy trainable parameter. Furthermore, there is limited understanding of the behavior of the learned activation functions derived from B-splines. In this work, we analyze the behavior of KANs through the lens of spline knots and derive the lower and upper bound for the number of knots in B-spline-based KANs. To address existing limitations, we propose a novel Free Knots KAN that enhances the performance of the original KAN while reducing the number of trainable parameters to match the trainable parameter scale of standard Multi-Layer Perceptrons (MLPs). Additionally, we introduce new a training strategy to ensure $C^2$ continuity of the learnable spline, resulting in smoother activation compared to the original KAN and improve the training stability by range expansion. The proposed method is comprehensively evaluated on 8 datasets spanning various domains, including image, text, time series, multimodal, and function approximation tasks. The promising results demonstrates the feasibility of KAN-based network and the effectiveness of proposed method.
Devil in the Tail: A Multi-Modal Framework for Drug-Drug Interaction Prediction in Long Tail Distinction
Oct 16, 2024



Drug-drug interaction (DDI) identification is a crucial aspect of pharmacology research. There are many DDI types (hundreds), and they are not evenly distributed with equal chance to occur. Some of the rarely occurred DDI types are often high risk and could be life-critical if overlooked, exemplifying the long-tailed distribution problem. Existing models falter against this distribution challenge and overlook the multi-faceted nature of drugs in DDI prediction. In this paper, a novel multi-modal deep learning-based framework, namely TFDM, is introduced to leverage multiple properties of a drug to achieve DDI classification. The proposed framework fuses multimodal features of drugs, including graph-based, molecular structure, Target and Enzyme, for DDI identification. To tackle the challenge posed by the distribution skewness across categories, a novel loss function called Tailed Focal Loss is introduced, aimed at further enhancing the model performance and address gradient vanishing problem of focal loss in extremely long-tailed dataset. Intensive experiments over 4 challenging long-tailed dataset demonstrate that the TFMD outperforms the most recent SOTA methods in long-tailed DDI classification tasks. The source code is released to reproduce our experiment results: https://github.com/IcurasLW/TFMD_Longtailed_DDI.git
Irregularity-Informed Time Series Analysis: Adaptive Modelling of Spatial and Temporal Dynamics
Oct 16, 2024



Irregular Time Series Data (IRTS) has shown increasing prevalence in real-world applications. We observed that IRTS can be divided into two specialized types: Natural Irregular Time Series (NIRTS) and Accidental Irregular Time Series (AIRTS). Various existing methods either ignore the impacts of irregular patterns or statically learn the irregular dynamics of NIRTS and AIRTS data and suffer from limited data availability due to the sparsity of IRTS. We proposed a novel transformer-based framework for general irregular time series data that treats IRTS from four views: Locality, Time, Spatio and Irregularity to motivate the data usage to the highest potential. Moreover, we design a sophisticated irregularity-gate mechanism to adaptively select task-relevant information from irregularity, which improves the generalization ability to various IRTS data. We implement extensive experiments to demonstrate the resistance of our work to three highly missing ratio datasets (88.4\%, 94.9\%, 60\% missing value) and investigate the significance of the irregularity information for both NIRTS and AIRTS by additional ablation study. We release our implementation in https://github.com/IcurasLW/MTSFormer-Irregular_Time_Series.git
Revisited Large Language Model for Time Series Analysis through Modality Alignment
Oct 16, 2024Large Language Models have demonstrated impressive performance in many pivotal web applications such as sensor data analysis. However, since LLMs are not designed for time series tasks, simpler models like linear regressions can often achieve comparable performance with far less complexity. In this study, we perform extensive experiments to assess the effectiveness of applying LLMs to key time series tasks, including forecasting, classification, imputation, and anomaly detection. We compare the performance of LLMs against simpler baseline models, such as single-layer linear models and randomly initialized LLMs. Our results reveal that LLMs offer minimal advantages for these core time series tasks and may even distort the temporal structure of the data. In contrast, simpler models consistently outperform LLMs while requiring far fewer parameters. Furthermore, we analyze existing reprogramming techniques and show, through data manifold analysis, that these methods fail to effectively align time series data with language and display pseudo-alignment behaviour in embedding space. Our findings suggest that the performance of LLM-based methods in time series tasks arises from the intrinsic characteristics and structure of time series data, rather than any meaningful alignment with the language model architecture.
SWAP: Exploiting Second-Ranked Logits for Adversarial Attacks on Time Series
Sep 06, 2023



Time series classification (TSC) has emerged as a critical task in various domains, and deep neural models have shown superior performance in TSC tasks. However, these models are vulnerable to adversarial attacks, where subtle perturbations can significantly impact the prediction results. Existing adversarial methods often suffer from over-parameterization or random logit perturbation, hindering their effectiveness. Additionally, increasing the attack success rate (ASR) typically involves generating more noise, making the attack more easily detectable. To address these limitations, we propose SWAP, a novel attacking method for TSC models. SWAP focuses on enhancing the confidence of the second-ranked logits while minimizing the manipulation of other logits. This is achieved by minimizing the Kullback-Leibler divergence between the target logit distribution and the predictive logit distribution. Experimental results demonstrate that SWAP achieves state-of-the-art performance, with an ASR exceeding 50% and an 18% increase compared to existing methods.
Distantly Supervised Relation Extraction via Recursive Hierarchy-Interactive Attention and Entity-Order Perception
May 18, 2021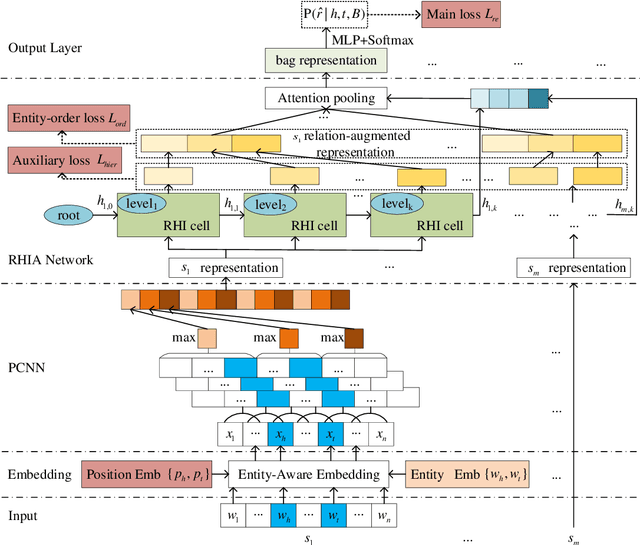
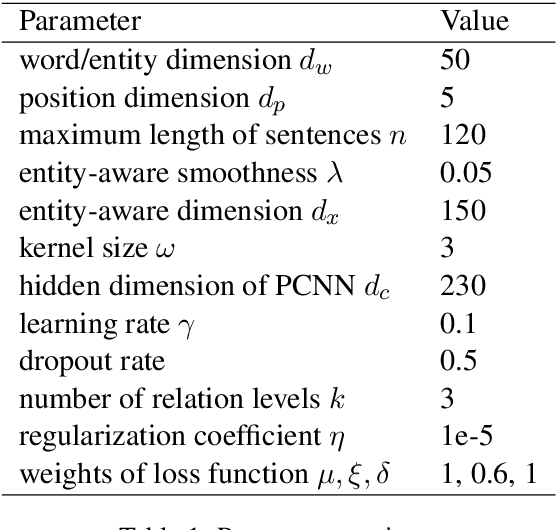
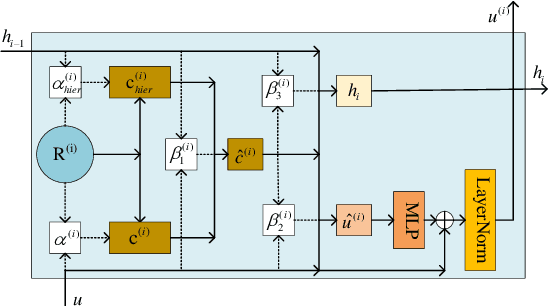

Distantly supervised relation extraction has drawn significant attention recently. However, almost all prior works ignore the fact that, in a sentence, the appearance order of two entities contributes to the understanding of its semantics. Furthermore, they leverage relation hierarchies but don't fully exploit the heuristic effect between relation levels, i.e., higher-level relations can give useful information to the lower ones. In this paper, we design a novel Recursive Hierarchy-Interactive Attention network (RHIA), which uses the hierarchical structure of the relation to model the interactive information between the relation levels to further handle long-tail relations. It generates relation-augmented sentence representations along hierarchical relation chains in a recursive structure. Besides, we introduce a newfangled training objective, called Entity-Order Perception (EOP), to make the sentence encoder retain more entity appearance information. Substantial experiments on the popular New York Times (NYT) dataset are conducted. Compared to prior baselines, our approach achieves state-of-the-art performance in terms of precision-recall (P-R) curves, AUC, Top-N precision and other evaluation metrics.