 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse-Case-Grounded Simulations for Explanation Evaluation
Jun 05, 2022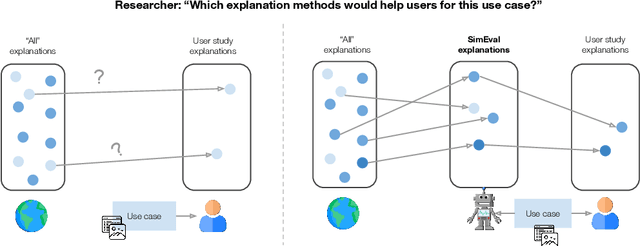
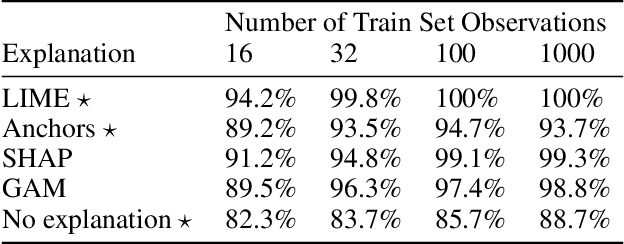
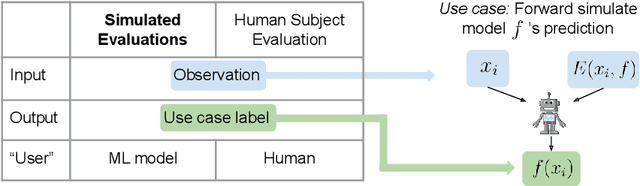
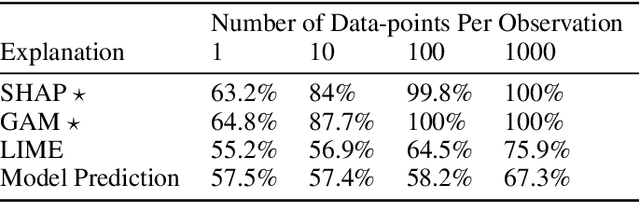
A growing body of research runs human subject evaluations to study whether providing users with explanations of machine learning models can help them with practical real-world use cases. However, running user studies is challenging and costly, and consequently each study typically only evaluates a limited number of different settings, e.g., studies often only evaluate a few arbitrarily selected explanation methods. To address these challenges and aid user study design, we introduce Use-Case-Grounded Simulated Evaluations (SimEvals). SimEvals involve training algorithmic agents that take as input the information content (such as model explanations) that would be presented to each participant in a human subject study, to predict answers to the use case of interest. The algorithmic agent's test set accuracy provides a measure of the predictiveness of the information content for the downstream use case. We run a comprehensive evaluation on three real-world use cases (forward simulation, model debugging, and counterfactual reasoning) to demonstrate that Simevals can effectively identify which explanation methods will help humans for each use case. These results provide evidence that SimEvals can be used to efficiently screen an important set of user study design decisions, e.g. selecting which explanations should be presented to the user, before running a potentially costly user study.
MAVIPER: Learning Decision Tree Policies for Interpretable Multi-Agent Reinforcement Learning
May 25, 2022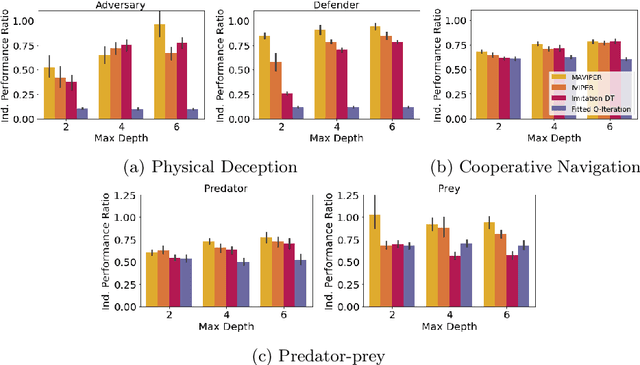
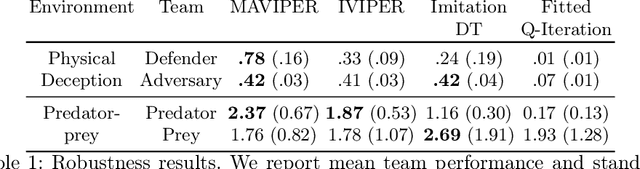
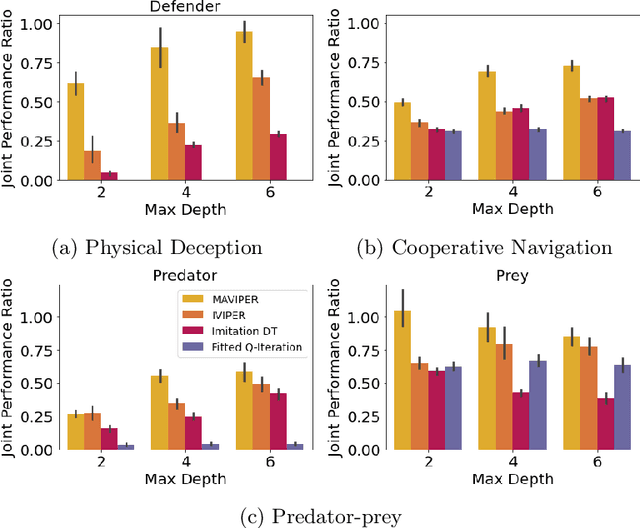
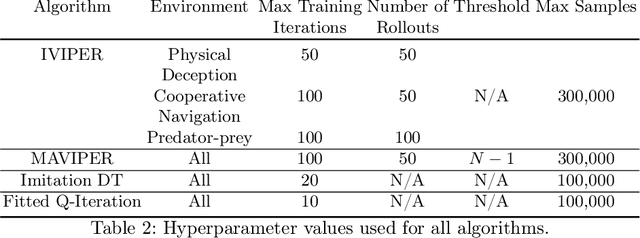
Many recent breakthroughs in multi-agent reinforcement learning (MARL) require the use of deep neural networks, which are challenging for human experts to interpret and understand. On the other hand, existing work on interpretable RL has shown promise in extracting more interpretable decision tree-based policies, but only in the single-agent setting. To fill this gap, we propose the first set of interpretable MARL algorithms that extract decision-tree policies from neural networks trained with MARL. The first algorithm, IVIPER, extends VIPER, a recent method for single-agent interpretable RL, to the multi-agent setting. We demonstrate that IVIPER can learn high-quality decision-tree policies for each agent. To better capture coordination between agents, we propose a novel centralized decision-tree training algorithm, MAVIPER. MAVIPER jointly grows the trees of each agent by predicting the behavior of the other agents using their anticipated trees, and uses resampling to focus on states that are critical for its interactions with other agents. We show that both algorithms generally outperform the baselines and that MAVIPER-trained agents achieve better-coordinated performance than IVIPER-trained agents on three different multi-agent particle-world environments.
MineRL Diamond 2021 Competition: Overview, Results, and Lessons Learned
Feb 17, 2022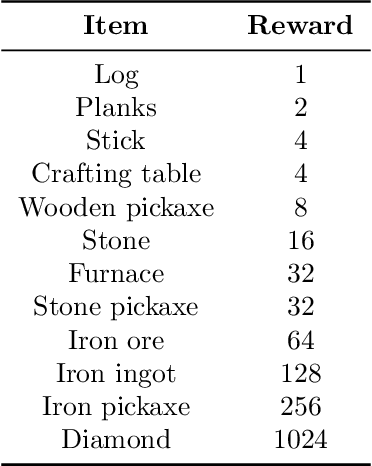
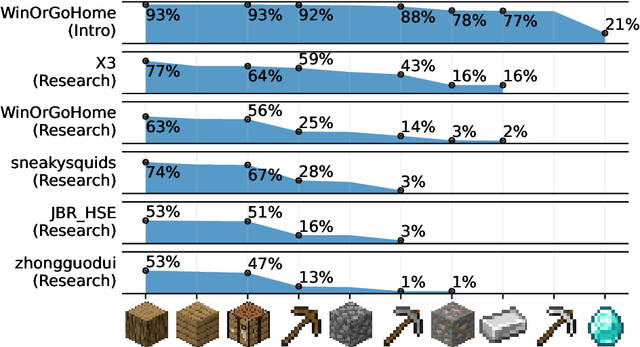
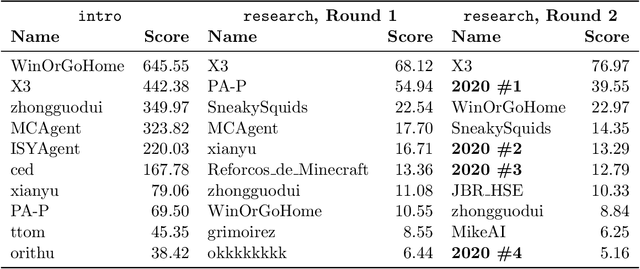
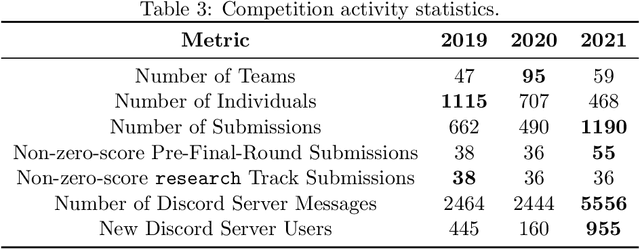
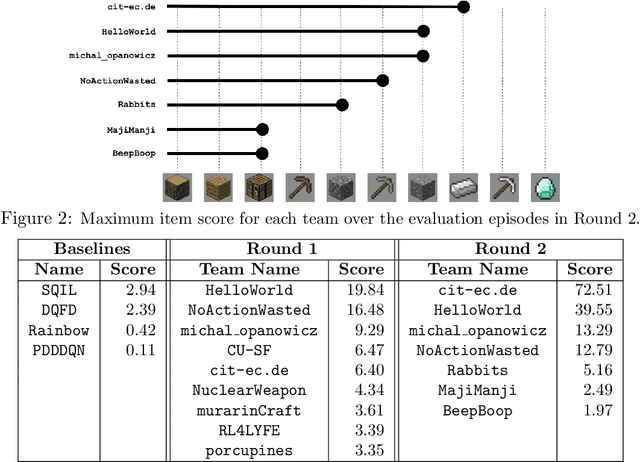
Reinforcement learning competitions advance the field by providing appropriate scope and support to develop solutions toward a specific problem. To promote the development of more broadly applicable methods, organizers need to enforce the use of general techniques, the use of sample-efficient methods, and the reproducibility of the results. While beneficial for the research community, these restrictions come at a cost -- increased difficulty. If the barrier for entry is too high, many potential participants are demoralized. With this in mind, we hosted the third edition of the MineRL ObtainDiamond competition, MineRL Diamond 2021, with a separate track in which we permitted any solution to promote the participation of newcomers. With this track and more extensive tutorials and support, we saw an increased number of submissions. The participants of this easier track were able to obtain a diamond, and the participants of the harder track progressed the generalizable solutions in the same task.
A Survey of Explainable Reinforcement Learning
Feb 17, 2022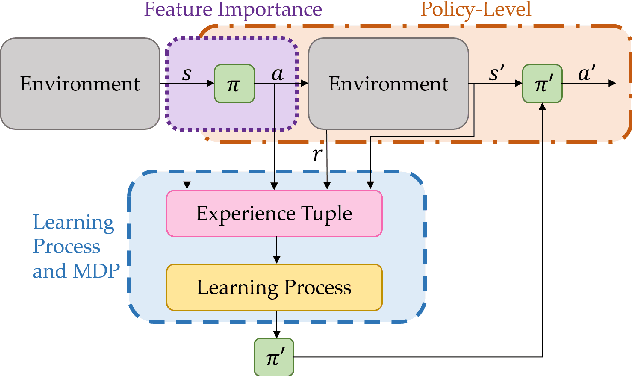
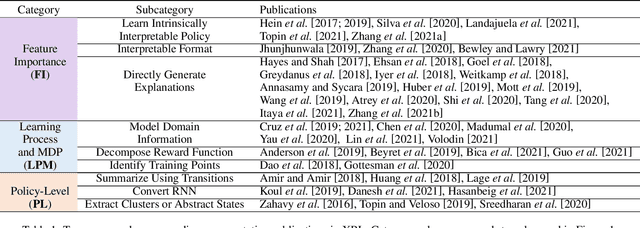
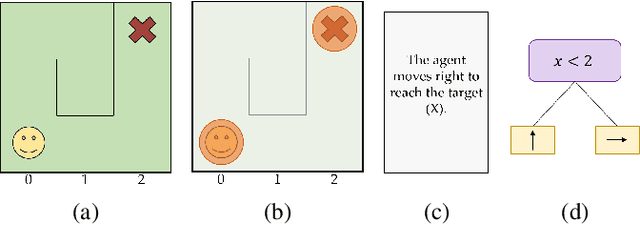
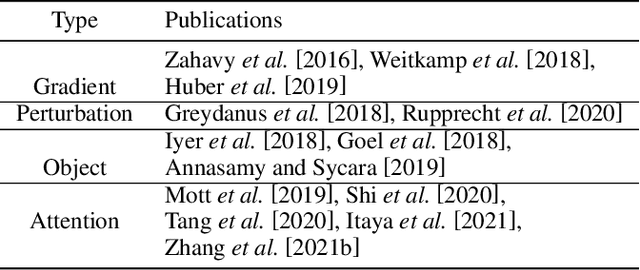
Explainable reinforcement learning (XRL) is an emerging subfield of explainable machine learning that has attracted considerable attention in recent years. The goal of XRL is to elucidate the decision-making process of learning agents in sequential decision-making settings. In this survey, we propose a novel taxonomy for organizing the XRL literature that prioritizes the RL setting. We overview techniques according to this taxonomy. We point out gaps in the literature, which we use to motivate and outline a roadmap for future work.
The MineRL BASALT Competition on Learning from Human Feedback
Jul 05, 2021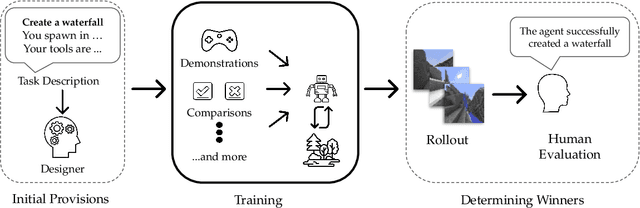

The last decade has seen a significant increase of interest in deep learning research, with many public successes that have demonstrated its potential. As such, these systems are now being incorporated into commercial products. With this comes an additional challenge: how can we build AI systems that solve tasks where there is not a crisp, well-defined specification? While multiple solutions have been proposed, in this competition we focus on one in particular: learning from human feedback. Rather than training AI systems using a predefined reward function or using a labeled dataset with a predefined set of categories, we instead train the AI system using a learning signal derived from some form of human feedback, which can evolve over time as the understanding of the task changes, or as the capabilities of the AI system improve. The MineRL BASALT competition aims to spur forward research on this important class of techniques. We design a suite of four tasks in Minecraft for which we expect it will be hard to write down hardcoded reward functions. These tasks are defined by a paragraph of natural language: for example, "create a waterfall and take a scenic picture of it", with additional clarifying details. Participants must train a separate agent for each task, using any method they want. Agents are then evaluated by humans who have read the task description. To help participants get started, we provide a dataset of human demonstrations on each of the four tasks, as well as an imitation learning baseline that leverages these demonstrations. Our hope is that this competition will improve our ability to build AI systems that do what their designers intend them to do, even when the intent cannot be easily formalized. Besides allowing AI to solve more tasks, this can also enable more effective regulation of AI systems, as well as making progress on the value alignment problem.
Towards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021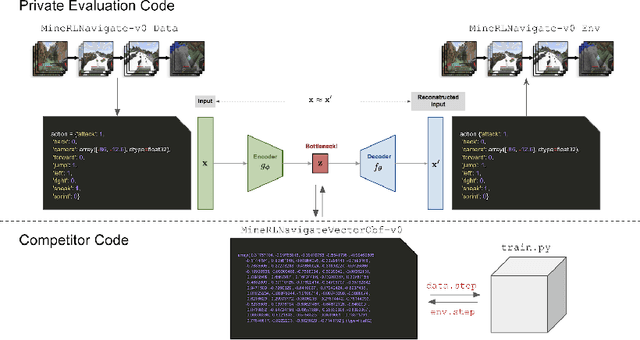

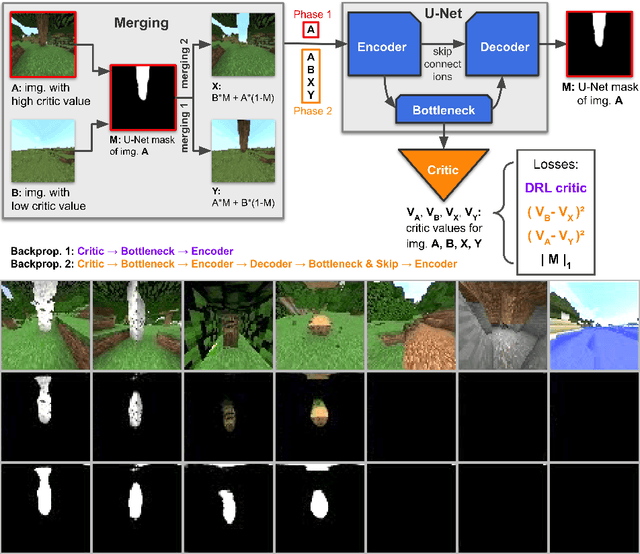
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.
Iterative Bounding MDPs: Learning Interpretable Policies via Non-Interpretable Methods
Feb 25, 2021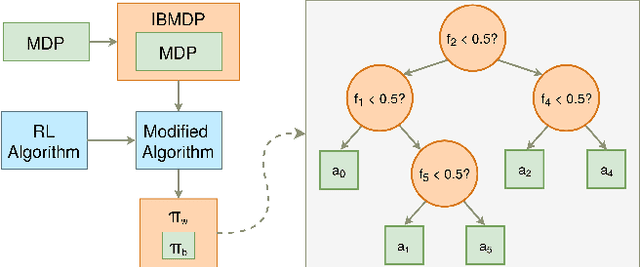
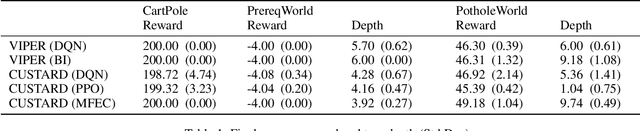
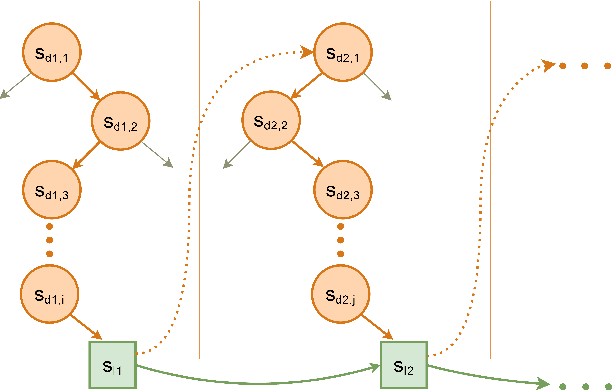
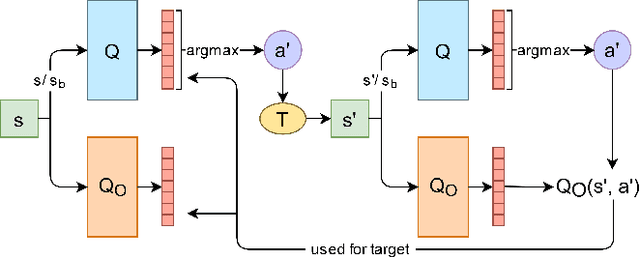
Current work in explainable reinforcement learning generally produces policies in the form of a decision tree over the state space. Such policies can be used for formal safety verification, agent behavior prediction, and manual inspection of important features. However, existing approaches fit a decision tree after training or use a custom learning procedure which is not compatible with new learning techniques, such as those which use neural networks. To address this limitation, we propose a novel Markov Decision Process (MDP) type for learning decision tree policies: Iterative Bounding MDPs (IBMDPs). An IBMDP is constructed around a base MDP so each IBMDP policy is guaranteed to correspond to a decision tree policy for the base MDP when using a method-agnostic masking procedure. Because of this decision tree equivalence, any function approximator can be used during training, including a neural network, while yielding a decision tree policy for the base MDP. We present the required masking procedure as well as a modified value update step which allows IBMDPs to be solved using existing algorithms. We apply this procedure to produce IBMDP variants of recent reinforcement learning methods. We empirically show the benefits of our approach by solving IBMDPs to produce decision tree policies for the base MDPs.
The MineRL 2020 Competition on Sample Efficient Reinforcement Learning using Human Priors
Jan 26, 2021
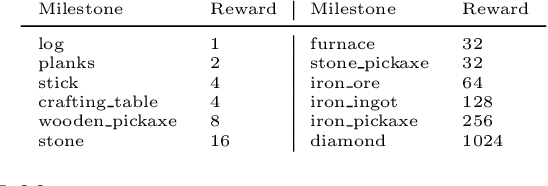
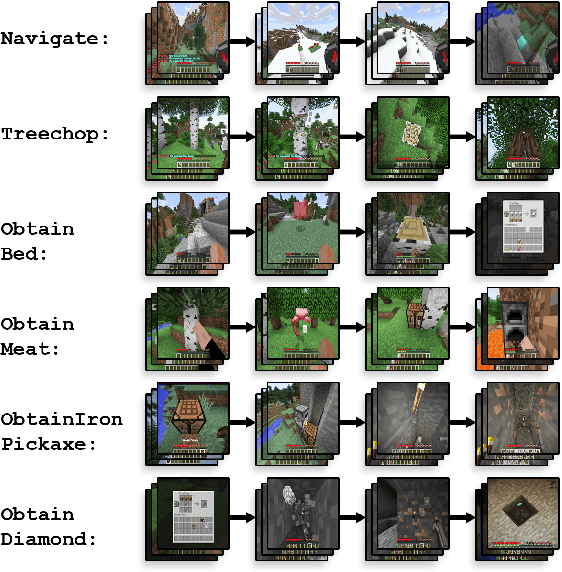
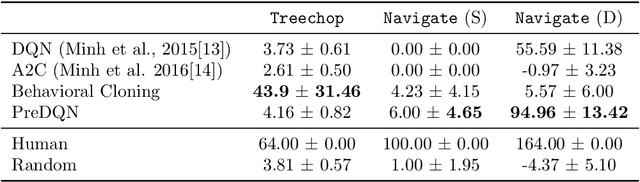
Although deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples, affording only a shrinking segment of the AI community access to their development. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we propose this second iteration of the MineRL Competition. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, participants compete under a limited environment sample-complexity budget to develop systems which solve the MineRL ObtainDiamond task in Minecraft, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures and shaders. At the end of each round, competitors submit containerized versions of their learning algorithms to the AIcrowd platform where they are trained from scratch on a hold-out dataset-environment pair for a total of 4-days on a pre-specified hardware platform. In this follow-up iteration to the NeurIPS 2019 MineRL Competition, we implement new features to expand the scale and reach of the competition. In response to the feedback of the previous participants, we introduce a second minor track focusing on solutions without access to environment interactions of any kind except during test-time. Further we aim to prompt domain agnostic submissions by implementing several novel competition mechanics including action-space randomization and desemantization of observations and actions.
Guaranteeing Reproducibility in Deep Learning Competitions
May 12, 2020To encourage the development of methods with reproducible and robust training behavior, we propose a challenge paradigm where competitors are evaluated directly on the performance of their learning procedures rather than pre-trained agents. Since competition organizers re-train proposed methods in a controlled setting they can guarantee reproducibility, and -- by retraining submissions using a held-out test set -- help ensure generalization past the environments on which they were trained.
Retrospective Analysis of the 2019 MineRL Competition on Sample Efficient Reinforcement Learning
Mar 27, 2020To facilitate research in the direction of sample-efficient reinforcement learning, we held the MineRL Competition on Sample-Efficient Reinforcement Learning Using Human Priors at the Thirty-fourth Conference on Neural Information Processing Systems (NeurIPS 2019). The primary goal of this competition was to promote the development of algorithms that use human demonstrations alongside reinforcement learning to reduce the number of samples needed to solve complex, hierarchical, and sparse environments. We describe the competition and provide an overview of the top solutions, each of which uses deep reinforcement learning and/or imitation learning. We also discuss the impact of our organizational decisions on the competition as well as future directions for improvement.