 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Group: A Bottom-Up Framework for 3D Part Discovery in Unseen Categories
Feb 16, 2020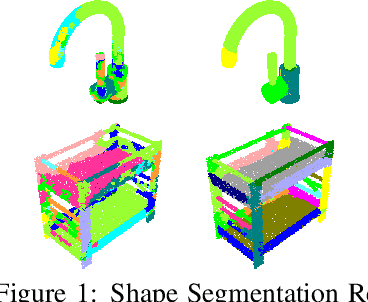
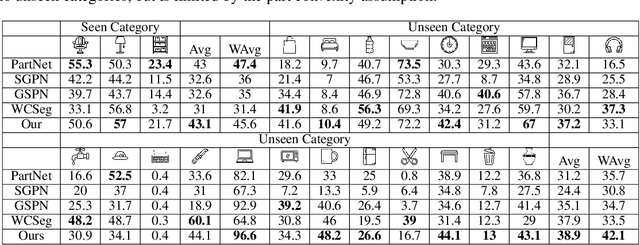
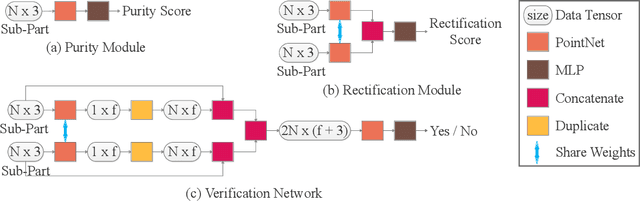
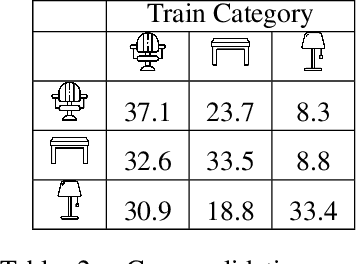
We address the problem of discovering 3D parts for objects in unseen categories. Being able to learn the geometry prior of parts and transfer this prior to unseen categories pose fundamental challenges on data-driven shape segmentation approaches. Formulated as a contextual bandit problem, we propose a learning-based agglomerative clustering framework which learns a grouping policy to progressively group small part proposals into bigger ones in a bottom-up fashion. At the core of our approach is to restrict the local context for extracting part-level features, which encourages the generalizability to unseen categories. On the large-scale fine-grained 3D part dataset, PartNet, we demonstrate that our method can transfer knowledge of parts learned from 3 training categories to 21 unseen testing categories without seeing any annotated samples. Quantitative comparisons against four shape segmentation baselines shows that our approach achieve the state-of-the-art performance.
MACER: Attack-free and Scalable Robust Training via Maximizing Certified Radius
Feb 15, 2020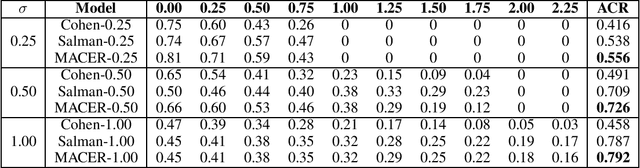
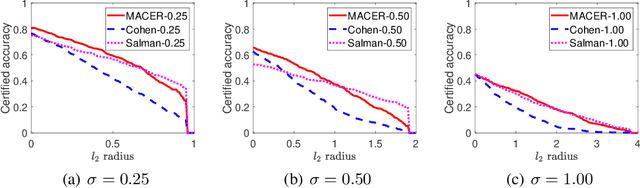
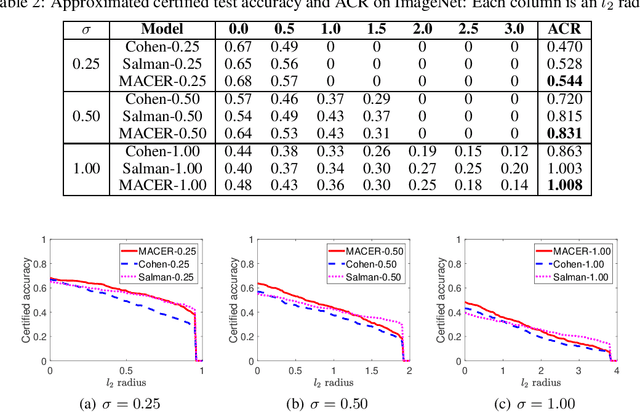
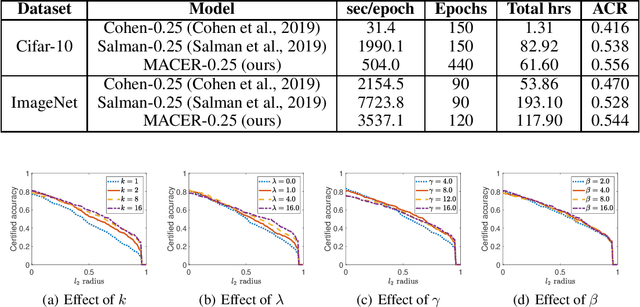
Adversarial training is one of the most popular ways to learn robust models but is usually attack-dependent and time costly. In this paper, we propose the MACER algorithm, which learns robust models without using adversarial training but performs better than all existing provable l2-defenses. Recent work shows that randomized smoothing can be used to provide a certified l2 radius to smoothed classifiers, and our algorithm trains provably robust smoothed classifiers via MAximizing the CErtified Radius (MACER). The attack-free characteristic makes MACER faster to train and easier to optimize. In our experiments, we show that our method can be applied to modern deep neural networks on a wide range of datasets, including Cifar-10, ImageNet, MNIST, and SVHN. For all tasks, MACER spends less training time than state-of-the-art adversarial training algorithms, and the learned models achieve larger average certified radius.
On Layer Normalization in the Transformer Architecture
Feb 12, 2020

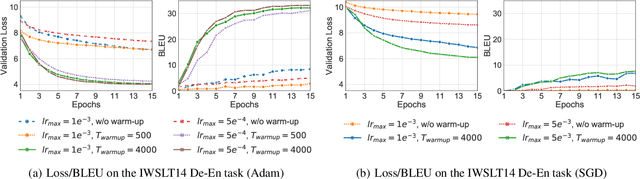

The Transformer is widely used in natural language processing tasks. To train a Transformer however, one usually needs a carefully designed learning rate warm-up stage, which is shown to be crucial to the final performance but will slow down the optimization and bring more hyper-parameter tunings. In this paper, we first study theoretically why the learning rate warm-up stage is essential and show that the location of layer normalization matters. Specifically, we prove with mean field theory that at initialization, for the original-designed Post-LN Transformer, which places the layer normalization between the residual blocks, the expected gradients of the parameters near the output layer are large. Therefore, using a large learning rate on those gradients makes the training unstable. The warm-up stage is practically helpful for avoiding this problem. On the other hand, our theory also shows that if the layer normalization is put inside the residual blocks (recently proposed as Pre-LN Transformer), the gradients are well-behaved at initialization. This motivates us to remove the warm-up stage for the training of Pre-LN Transformers. We show in our experiments that Pre-LN Transformers without the warm-up stage can reach comparable results with baselines while requiring significantly less training time and hyper-parameter tuning on a wide range of applications.
Combinatorial Semi-Bandit in the Non-Stationary Environment
Feb 10, 2020In this paper, we investigate the non-stationary combinatorial semi-bandit problem, both in the switching case and in the dynamic case. In the general case where (a) the reward function is non-linear, (b) arms may be probabilistically triggered, and (c) only approximate offline oracle exists \cite{wang2017improving}, our algorithm achieves $\tilde{\mathcal{O}}(\sqrt{\mathcal{S} T})$ distribution-dependent regret in the switching case, and $\tilde{\mathcal{O}}(\mathcal{V}^{1/3}T^{2/3})$ in the dynamic case, where $\mathcal S$ is the number of switchings and $\mathcal V$ is the sum of the total ``distribution changes''. The regret bounds in both scenarios are nearly optimal, but our algorithm needs to know the parameter $\mathcal S$ or $\mathcal V$ in advance. We further show that by employing another technique, our algorithm no longer needs to know the parameters $\mathcal S$ or $\mathcal V$ but the regret bounds could become suboptimal. In a special case where the reward function is linear and we have an exact oracle, we design a parameter-free algorithm that achieves nearly optimal regret both in the switching case and in the dynamic case without knowing the parameters in advance.
Dense RepPoints: Representing Visual Objects with Dense Point Sets
Dec 24, 2019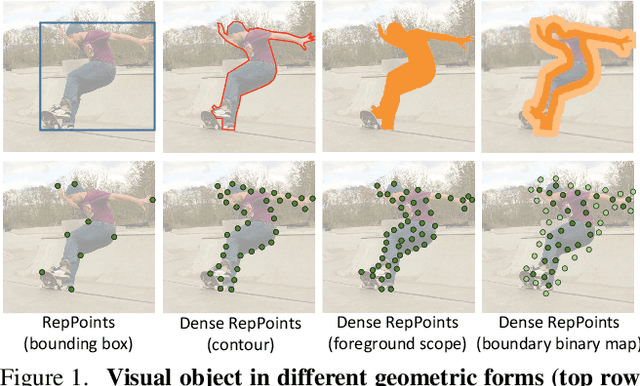
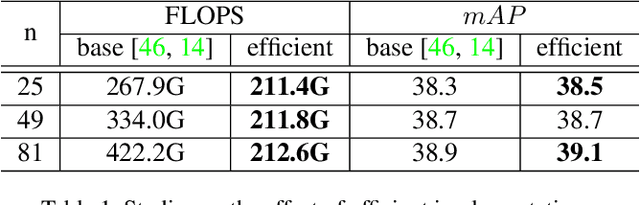
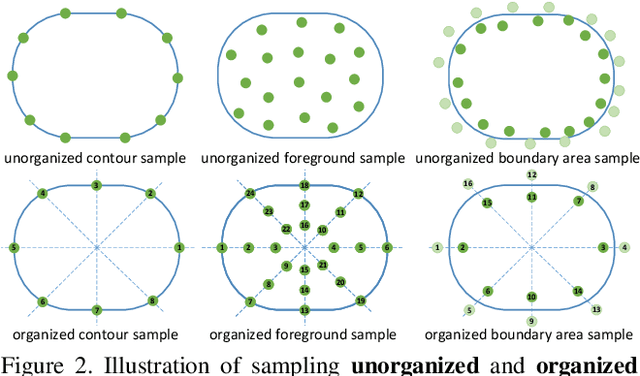
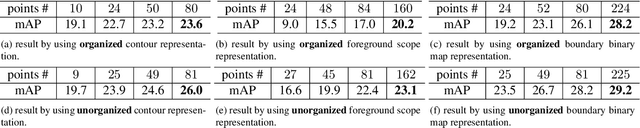
We present an object representation, called \textbf{Dense RepPoints}, for flexible and detailed modeling of object appearance and geometry. In contrast to the coarse geometric localization and feature extraction of bounding boxes, Dense RepPoints adaptively distributes a dense set of points to semantically and geometrically significant positions on an object, providing informative cues for object analysis. Techniques are developed to address challenges related to supervised training for dense point sets from image segments annotations and making this extensive representation computationally practical. In addition, the versatility of this representation is exploited to model object structure over multiple levels of granularity. Dense RepPoints significantly improves performance on geometrically-oriented visual understanding tasks, including a $1.6$ AP gain in object detection on the challenging COCO benchmark.
Defective Convolutional Layers Learn Robust CNNs
Nov 19, 2019

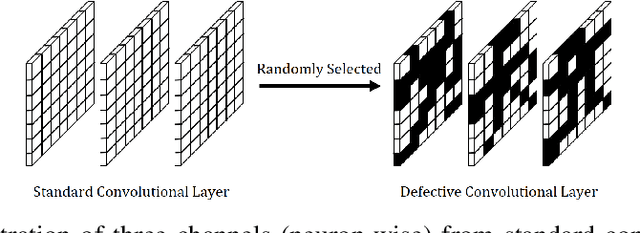
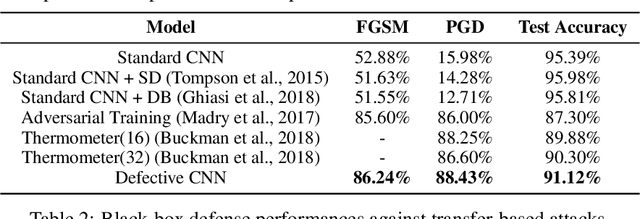
Robustness of convolutional neural networks has recently been highlighted by the adversarial examples, i.e., inputs added with well-designed perturbations which are imperceptible to humans but can cause the network to give incorrect outputs. Recent research suggests that the noises in adversarial examples break the textural structure, which eventually leads to wrong predictions by convolutional neural networks. To help a convolutional neural network make predictions relying less on textural information, we propose defective convolutional layers which contain defective neurons whose activations are set to be a constant function. As the defective neurons contain no information and are far different from the standard neurons in its spatial neighborhood, the textural features cannot be accurately extracted and the model has to seek for other features for classification, such as the shape. We first show that predictions made by the defective CNN are less dependent on textural information, but more on shape information, and further find that adversarial examples generated by the defective CNN appear to have semantic shapes. Experimental results demonstrate the defective CNN has higher defense ability than the standard CNN against various types of attack. In particular, it achieves state-of-the-art performance against transfer-based attacks without applying any adversarial training.
Development of Clinical Concept Extraction Applications: A Methodology Review
Oct 28, 2019
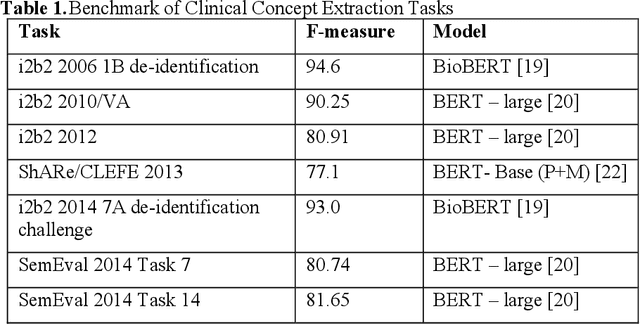
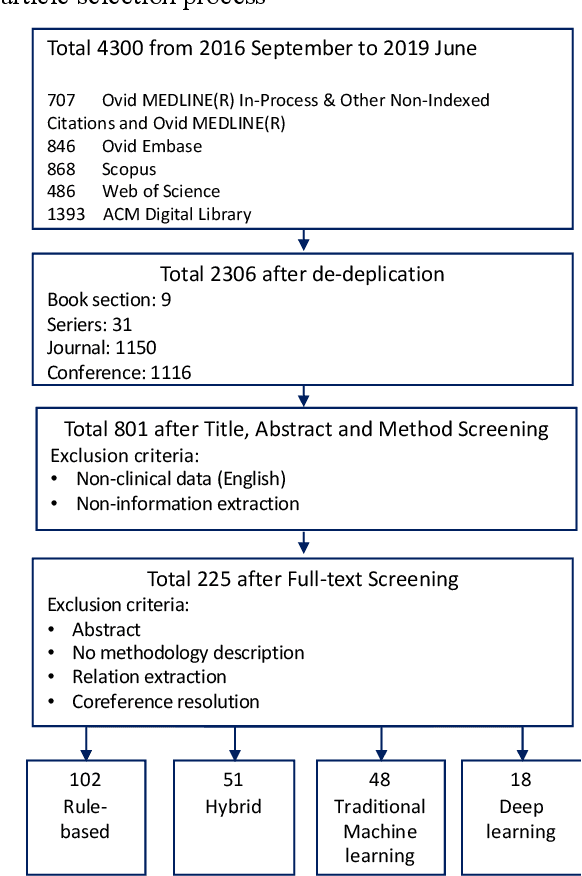
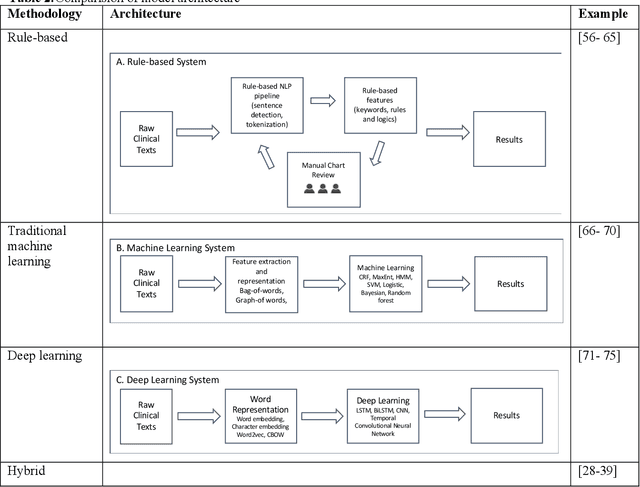
Our study provided a review of the development of clinical concept extraction applications from January 2009 to June 2019. We hope, through the studying of different approaches with variant clinical context, can enhance the decision making for the development of clinical concept extraction.
On the Anomalous Generalization of GANs
Oct 06, 2019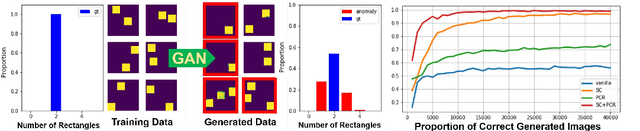
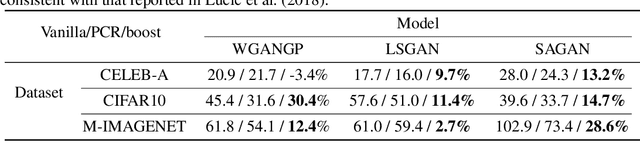
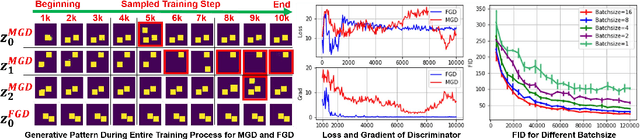
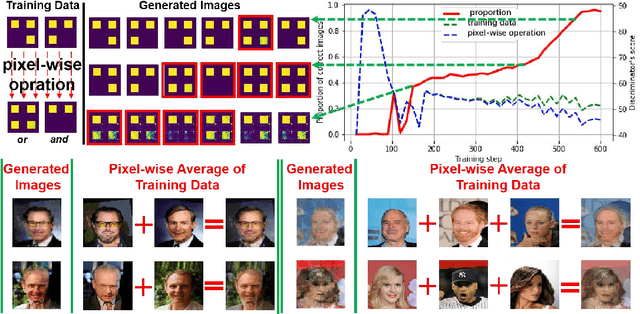
Generative models, especially Generative Adversarial Networks (GANs), have received significant attention recently. However, it has been observed that in terms of some attributes, e.g. the number of simple geometric primitives in an image, GANs are not able to learn the target distribution in practice. Motivated by this observation, we discover two specific problems of GANs leading to anomalous generalization behaviour, which we refer to as the sample insufficiency and the pixel-wise combination. For the first problem of sample insufficiency, we show theoretically and empirically that the batchsize of the training samples in practice may be insufficient for the discriminator to learn an accurate discrimination function. It could result in unstable training dynamics for the generator, leading to anomalous generalization. For the second problem of pixel-wise combination, we find that besides recognizing the positive training samples as real, under certain circumstances, the discriminator could be fooled to recognize the pixel-wise combinations (e.g. pixel-wise average) of the positive training samples as real. However, those combinations could be visually different from the real samples in the target distribution. With the fooled discriminator as reference, the generator would obtain biased supervision further, leading to the anomalous generalization behaviour. Additionally, in this paper, we propose methods to mitigate the anomalous generalization of GANs. Extensive experiments on benchmark show our proposed methods improve the FID score up to 30\% on natural image dataset.
Robust Local Features for Improving the Generalization of Adversarial Training
Sep 23, 2019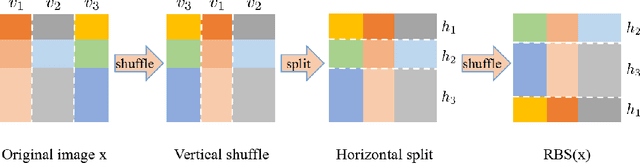
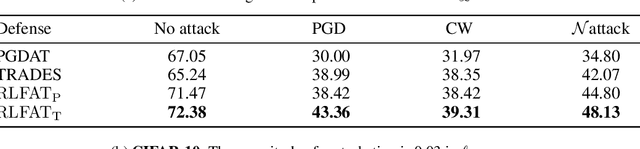

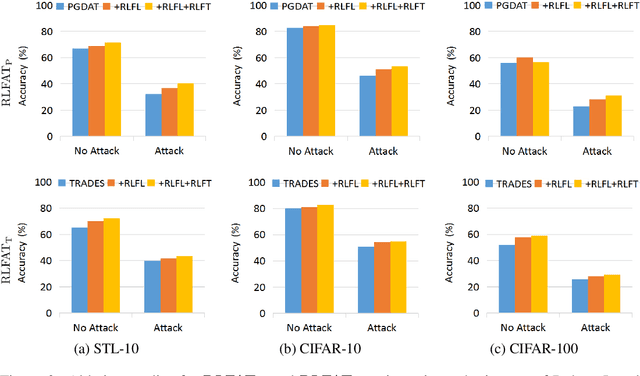
Adversarial training has been demonstrated as one of the most effective methods for training robust models so as to defend against adversarial examples. However, adversarial training often lacks adversarially robust generalization on unseen data. Recent works show that adversarially trained models may be more biased towards global structure features. Instead, in this work, we would like to investigate the relationship between the generalization of adversarial training and the robust local features, as the local features generalize well for unseen shape variation. To learn the robust local features, we develop a Random Block Shuffle (RBS) transformation to break up the global structure features on normal adversarial examples. We continue to propose a new approach called Robust Local Features for Adversarial Training (RLFAT), which first learns the robust local features by adversarial training on the RBS-transformed adversarial examples, and then transfers the robust local features into the training of normal adversarial examples. Finally, we implement RLFAT in two currently state-of-the-art adversarial training frameworks. Extensive experiments on STL-10, CIFAR-10, CIFAR-100 datasets show that RLFAT improves the adversarially robust generalization as well as the standard generalization of adversarial training. Additionally, we demonstrate that our method captures more local features of the object, aligning better with human perception.
Hint-Based Training for Non-Autoregressive Machine Translation
Sep 15, 2019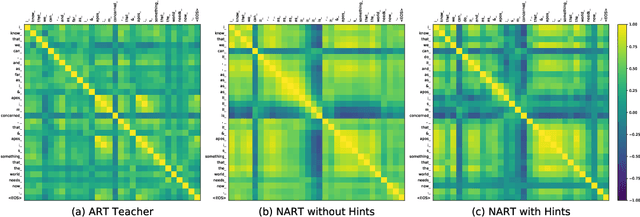
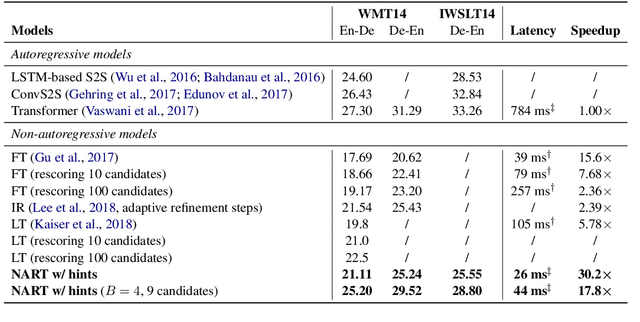
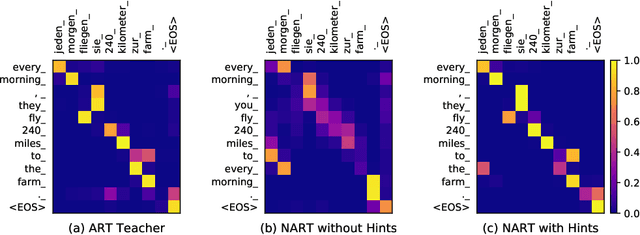
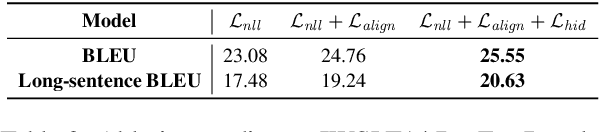
Due to the unparallelizable nature of the autoregressive factorization, AutoRegressive Translation (ART) models have to generate tokens sequentially during decoding and thus suffer from high inference latency. Non-AutoRegressive Translation (NART) models were proposed to reduce the inference time, but could only achieve inferior translation accuracy. In this paper, we proposed a novel approach to leveraging the hints from hidden states and word alignments to help the training of NART models. The results achieve significant improvement over previous NART models for the WMT14 En-De and De-En datasets and are even comparable to a strong LSTM-based ART baseline but one order of magnitude faster in inference.