 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Parametrically Refactoring Inference for Speculative Sampling Draft Models
Feb 02, 2026Large Language Models (LLMs), constrained by their auto-regressive nature, suffer from slow decoding. Speculative decoding methods have emerged as a promising solution to accelerate LLM decoding, attracting attention from both systems and AI research communities. Recently, the pursuit of better draft quality has driven a trend toward parametrically larger draft models, which inevitably introduces substantial computational overhead. While existing work attempts to balance the trade-off between prediction accuracy and compute latency, we address this fundamental dilemma through architectural innovation. We propose PRISM, which disaggregates the computation of each predictive step across different parameter sets, refactoring the computational pathways of draft models to successfully decouple model capacity from inference cost. Through extensive experiments, we demonstrate that PRISM outperforms all existing draft architectures, achieving exceptional acceptance lengths while maintaining minimal draft latency for superior end-to-end speedup. We also re-examine scaling laws with PRISM, revealing that PRISM scales more effectively with expanding data volumes than other draft architectures. Through rigorous and fair comparison, we show that PRISM boosts the decoding throughput of an already highly optimized inference engine by more than 2.6x.
Understanding is Compression
Jun 24, 2024We have previously shown all understanding or learning are compression, under reasonable assumptions. In principle, better understanding of data should improve data compression. Traditional compression methodologies focus on encoding frequencies or some other computable properties of data. Large language models approximate the uncomputable Solomonoff distribution, opening up a whole new avenue to justify our theory. Under the new uncomputable paradigm, we present LMCompress based on the understanding of data using large models. LMCompress has significantly better lossless compression ratios than all other lossless data compression methods, doubling the compression ratios of JPEG-XL for images, FLAC for audios and H264 for videos, and tripling or quadrupling the compression ratio of bz2 for texts. The better a large model understands the data, the better LMCompress compresses.
Enhanced Language Representation with Label Knowledge for Span Extraction
Nov 01, 2021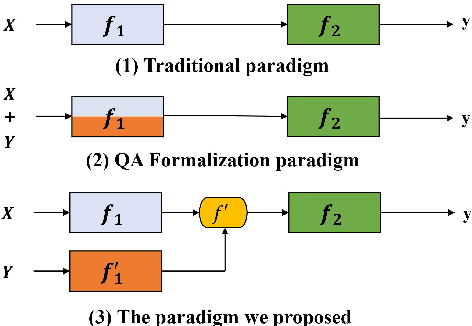


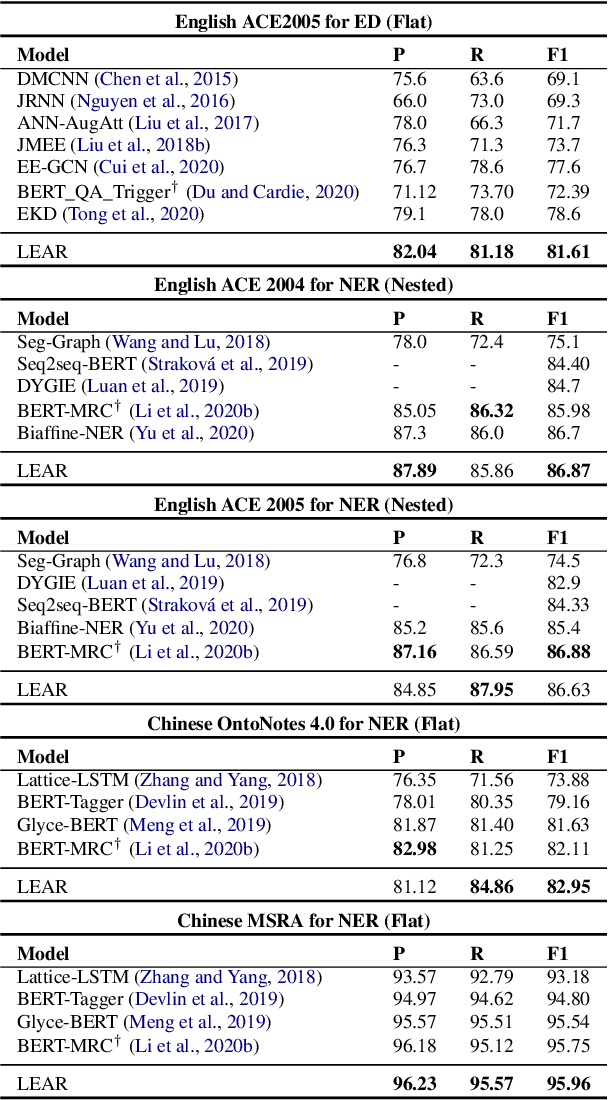
Span extraction, aiming to extract text spans (such as words or phrases) from plain texts, is a fundamental process in Information Extraction. Recent works introduce the label knowledge to enhance the text representation by formalizing the span extraction task into a question answering problem (QA Formalization), which achieves state-of-the-art performance. However, QA Formalization does not fully exploit the label knowledge and suffers from low efficiency in training/inference. To address those problems, we introduce a new paradigm to integrate label knowledge and further propose a novel model to explicitly and efficiently integrate label knowledge into text representations. Specifically, it encodes texts and label annotations independently and then integrates label knowledge into text representation with an elaborate-designed semantics fusion module. We conduct extensive experiments on three typical span extraction tasks: flat NER, nested NER, and event detection. The empirical results show that 1) our method achieves state-of-the-art performance on four benchmarks, and 2) reduces training time and inference time by 76% and 77% on average, respectively, compared with the QA Formalization paradigm. Our code and data are available at https://github.com/Akeepers/LEAR.
McDiarmid-Type Inequalities for Graph-Dependent Variables and Stability Bounds
Sep 09, 2019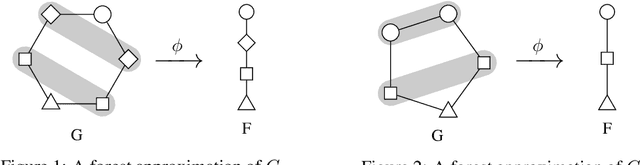
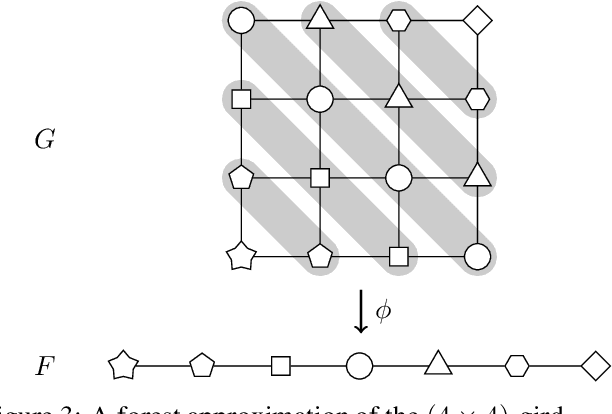
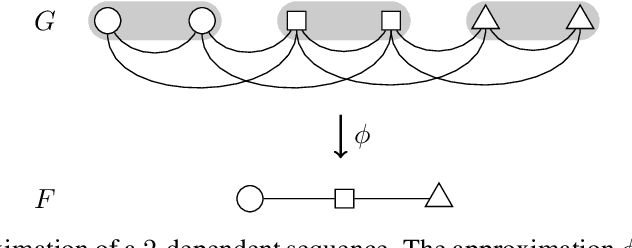
A crucial assumption in most statistical learning theory is that samples are independently and identically distributed (i.i.d.). However, for many real applications, the i.i.d. assumption does not hold. We consider learning problems in which examples are dependent and their dependency relation is characterized by a graph. To establish algorithm-dependent generalization theory for learning with non-i.i.d. data, we first prove novel McDiarmid-type concentration inequalities for Lipschitz functions of graph-dependent random variables. We show that concentration relies on the forest complexity of the graph, which characterizes the strength of the dependency. We demonstrate that for many types of dependent data, the forest complexity is small and thus implies good concentration. Based on our new inequalities we are able to build stability bounds for learning from graph-dependent data.
On the ERM Principle with Networked Data
Nov 22, 2017
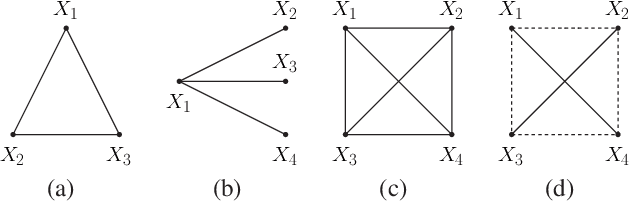
Networked data, in which every training example involves two objects and may share some common objects with others, is used in many machine learning tasks such as learning to rank and link prediction. A challenge of learning from networked examples is that target values are not known for some pairs of objects. In this case, neither the classical i.i.d.\ assumption nor techniques based on complete U-statistics can be used. Most existing theoretical results of this problem only deal with the classical empirical risk minimization (ERM) principle that always weights every example equally, but this strategy leads to unsatisfactory bounds. We consider general weighted ERM and show new universal risk bounds for this problem. These new bounds naturally define an optimization problem which leads to appropriate weights for networked examples. Though this optimization problem is not convex in general, we devise a new fully polynomial-time approximation scheme (FPTAS) to solve it.