 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAT: 2D Semantics Assisted Training for 3D Visual Grounding
May 24, 2021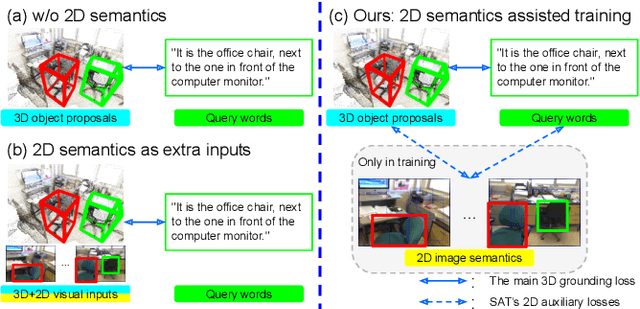
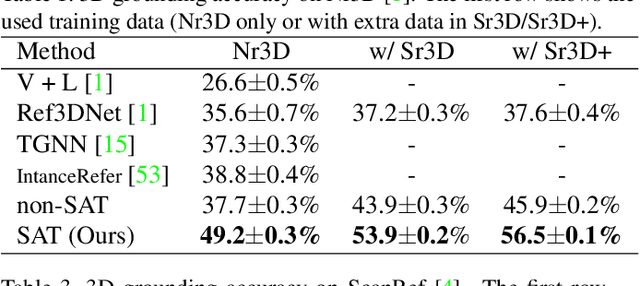
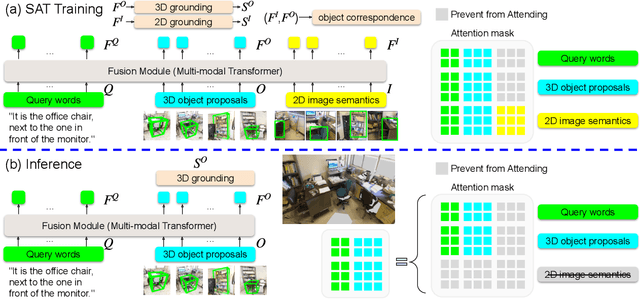
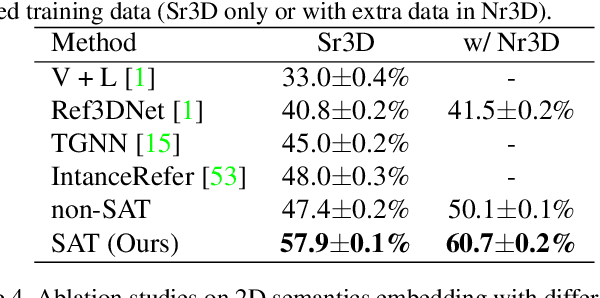
3D visual grounding aims at grounding a natural language description about a 3D scene, usually represented in the form of 3D point clouds, to the targeted object region. Point clouds are sparse, noisy, and contain limited semantic information compared with 2D images. These inherent limitations make the 3D visual grounding problem more challenging. In this study, we propose 2D Semantics Assisted Training (SAT) that utilizes 2D image semantics in the training stage to ease point-cloud-language joint representation learning and assist 3D visual grounding. The main idea is to learn auxiliary alignments between rich, clean 2D object representations and the corresponding objects or mentioned entities in 3D scenes. SAT takes 2D object semantics, i.e., object label, image feature, and 2D geometric feature, as the extra input in training but does not require such inputs during inference. By effectively utilizing 2D semantics in training, our approach boosts the accuracy on the Nr3D dataset from 37.7% to 49.2%, which significantly surpasses the non-SAT baseline with the identical network architecture and inference input. Our approach outperforms the state of the art by large margins on multiple 3D visual grounding datasets, i.e., +10.4% absolute accuracy on Nr3D, +9.9% on Sr3D, and +5.6% on ScanRef.
DAGN: Discourse-Aware Graph Network for Logical Reasoning
Apr 08, 2021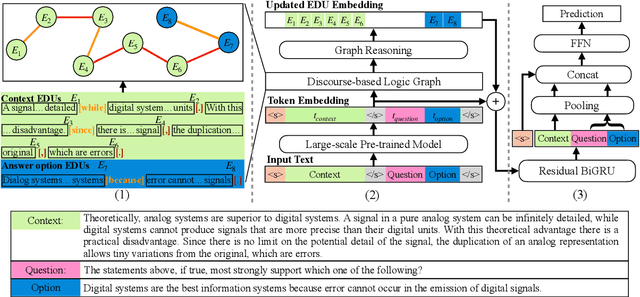
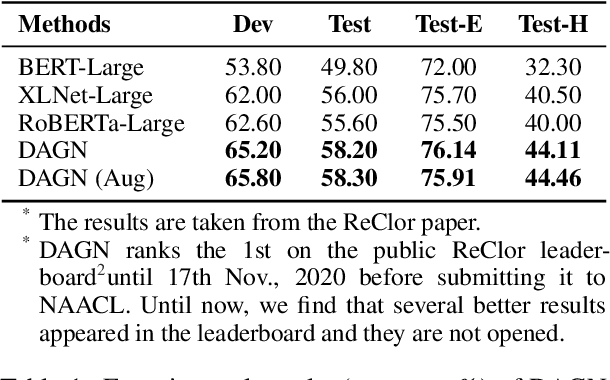
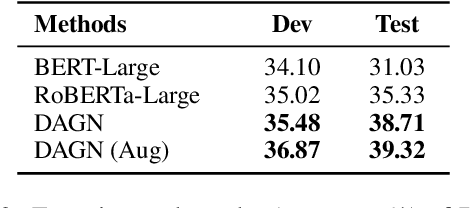

Recent QA with logical reasoning questions requires passage-level relations among the sentences. However, current approaches still focus on sentence-level relations interacting among tokens. In this work, we explore aggregating passage-level clues for solving logical reasoning QA by using discourse-based information. We propose a discourse-aware graph network (DAGN) that reasons relying on the discourse structure of the texts. The model encodes discourse information as a graph with elementary discourse units (EDUs) and discourse relations, and learns the discourse-aware features via a graph network for downstream QA tasks. Experiments are conducted on two logical reasoning QA datasets, ReClor and LogiQA, and our proposed DAGN achieves competitive results. The source code is available at https://github.com/Eleanor-H/DAGN.
Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
Mar 30, 2021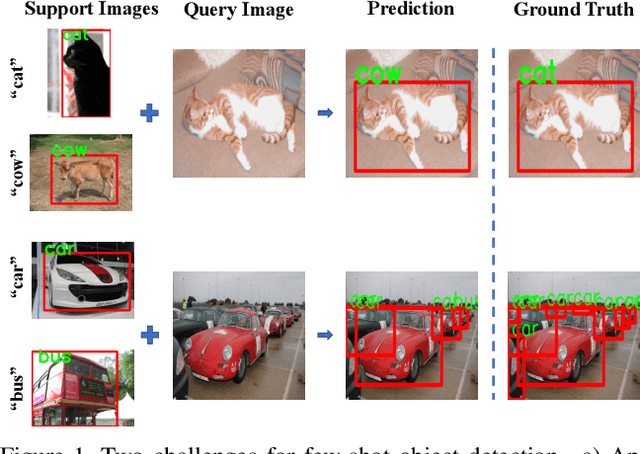
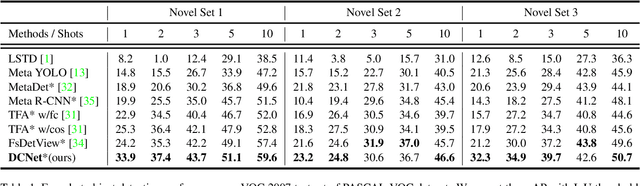
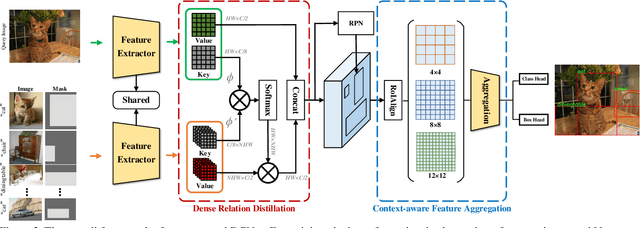
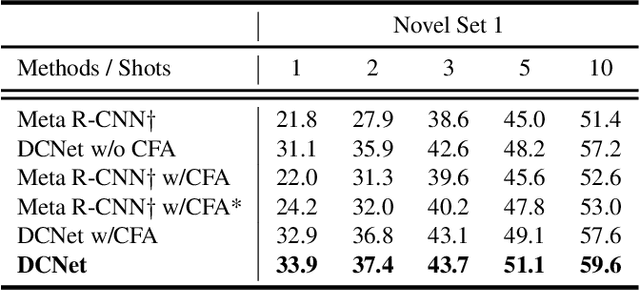
Conventional deep learning based methods for object detection require a large amount of bounding box annotations for training, which is expensive to obtain such high quality annotated data. Few-shot object detection, which learns to adapt to novel classes with only a few annotated examples, is very challenging since the fine-grained feature of novel object can be easily overlooked with only a few data available. In this work, aiming to fully exploit features of annotated novel object and capture fine-grained features of query object, we propose Dense Relation Distillation with Context-aware Aggregation (DCNet) to tackle the few-shot detection problem. Built on the meta-learning based framework, Dense Relation Distillation module targets at fully exploiting support features, where support features and query feature are densely matched, covering all spatial locations in a feed-forward fashion. The abundant usage of the guidance information endows model the capability to handle common challenges such as appearance changes and occlusions. Moreover, to better capture scale-aware features, Context-aware Aggregation module adaptively harnesses features from different scales for a more comprehensive feature representation. Extensive experiments illustrate that our proposed approach achieves state-of-the-art results on PASCAL VOC and MS COCO datasets. Code will be made available at https://github.com/hzhupku/DCNet.
Revisiting Language Encoding in Learning Multilingual Representations
Feb 16, 2021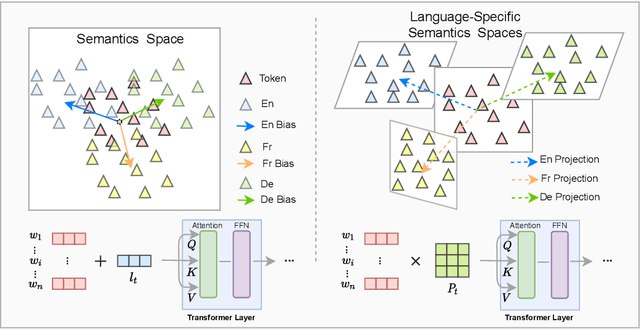
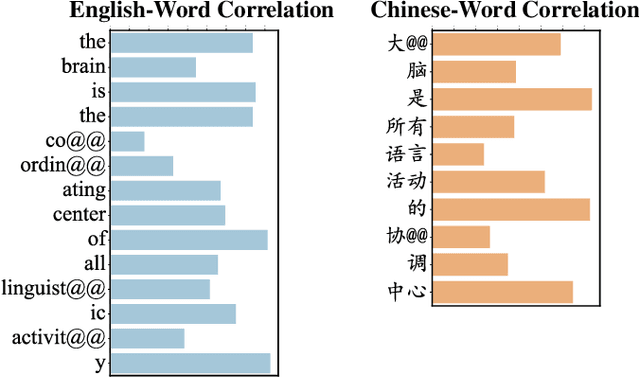

Transformer has demonstrated its great power to learn contextual word representations for multiple languages in a single model. To process multilingual sentences in the model, a learnable vector is usually assigned to each language, which is called "language embedding". The language embedding can be either added to the word embedding or attached at the beginning of the sentence. It serves as a language-specific signal for the Transformer to capture contextual representations across languages. In this paper, we revisit the use of language embedding and identify several problems in the existing formulations. By investigating the interaction between language embedding and word embedding in the self-attention module, we find that the current methods cannot reflect the language-specific word correlation well. Given these findings, we propose a new approach called Cross-lingual Language Projection (XLP) to replace language embedding. For a sentence, XLP projects the word embeddings into language-specific semantic space, and then the projected embeddings will be fed into the Transformer model to process with their language-specific meanings. In such a way, XLP achieves the purpose of appropriately encoding "language" in a multilingual Transformer model. Experimental results show that XLP can freely and significantly boost the model performance on extensive multilingual benchmark datasets. Codes and models will be released at https://github.com/lsj2408/XLP.
Towards Certifying $\ell_\infty$ Robustness using Neural Networks with $\ell_\infty$-dist Neurons
Feb 10, 2021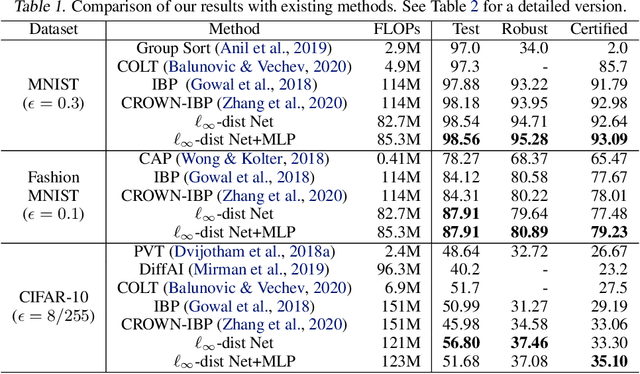
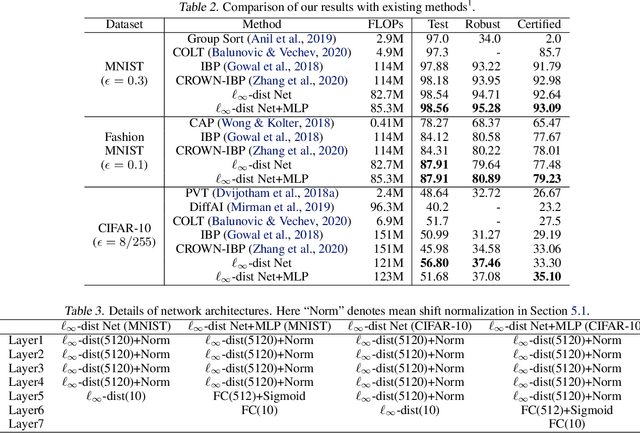
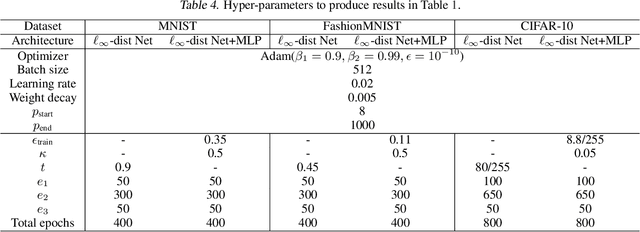

It is well-known that standard neural networks, even with a high classification accuracy, are vulnerable to small $\ell_\infty$-norm bounded adversarial perturbations. Although many attempts have been made, most previous works either can only provide empirical verification of the defense to a particular attack method, or can only develop a certified guarantee of the model robustness in limited scenarios. In this paper, we seek for a new approach to develop a theoretically principled neural network that inherently resists $\ell_\infty$ perturbations. In particular, we design a novel neuron that uses $\ell_\infty$-distance as its basic operation (which we call $\ell_\infty$-dist neuron), and show that any neural network constructed with $\ell_\infty$-dist neurons (called $\ell_{\infty}$-dist net) is naturally a 1-Lipschitz function with respect to $\ell_\infty$-norm. This directly provides a rigorous guarantee of the certified robustness based on the margin of prediction outputs. We also prove that such networks have enough expressive power to approximate any 1-Lipschitz function with robust generalization guarantee. Our experimental results show that the proposed network is promising. Using $\ell_{\infty}$-dist nets as the basic building blocks, we consistently achieve state-of-the-art performance on commonly used datasets: 93.09% certified accuracy on MNIST ($\epsilon=0.3$), 79.23% on Fashion MNIST ($\epsilon=0.1$) and 35.10% on CIFAR-10 ($\epsilon=8/255$).
Near-optimal Representation Learning for Linear Bandits and Linear RL
Feb 08, 2021This paper studies representation learning for multi-task linear bandits and multi-task episodic RL with linear value function approximation. We first consider the setting where we play $M$ linear bandits with dimension $d$ concurrently, and these bandits share a common $k$-dimensional linear representation so that $k\ll d$ and $k \ll M$. We propose a sample-efficient algorithm, MTLR-OFUL, which leverages the shared representation to achieve $\tilde{O}(M\sqrt{dkT} + d\sqrt{kMT} )$ regret, with $T$ being the number of total steps. Our regret significantly improves upon the baseline $\tilde{O}(Md\sqrt{T})$ achieved by solving each task independently. We further develop a lower bound that shows our regret is near-optimal when $d > M$. Furthermore, we extend the algorithm and analysis to multi-task episodic RL with linear value function approximation under low inherent Bellman error \citep{zanette2020learning}. To the best of our knowledge, this is the first theoretical result that characterizes the benefits of multi-task representation learning for exploration in RL with function approximation.
Robust Dialogue Utterance Rewriting as Sequence Tagging
Dec 29, 2020
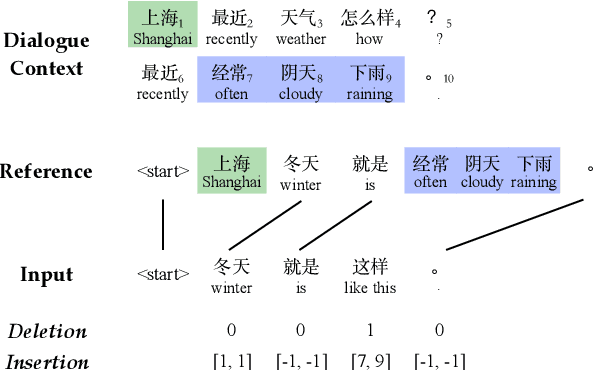
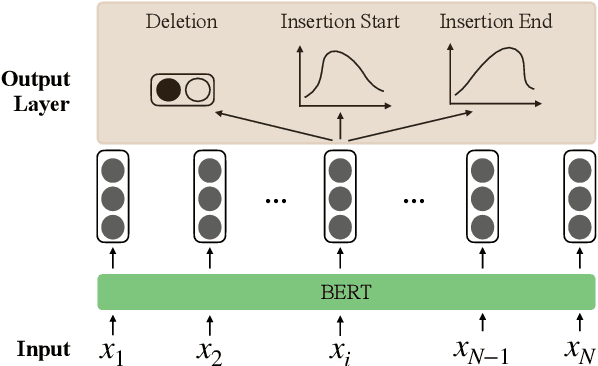

The task of dialogue rewriting aims to reconstruct the latest dialogue utterance by copying the missing content from the dialogue context. Until now, the existing models for this task suffer from the robustness issue, i.e., performances drop dramatically when testing on a different domain. We address this robustness issue by proposing a novel sequence-tagging-based model so that the search space is significantly reduced, yet the core of this task is still well covered. As a common issue of most tagging models for text generation, the model's outputs may lack fluency. To alleviate this issue, we inject the loss signal from BLEU or GPT-2 under a REINFORCE framework. Experiments show huge improvements of our model over the current state-of-the-art systems on domain transfer.
Fully Convolutional Networks for Panoptic Segmentation
Dec 01, 2020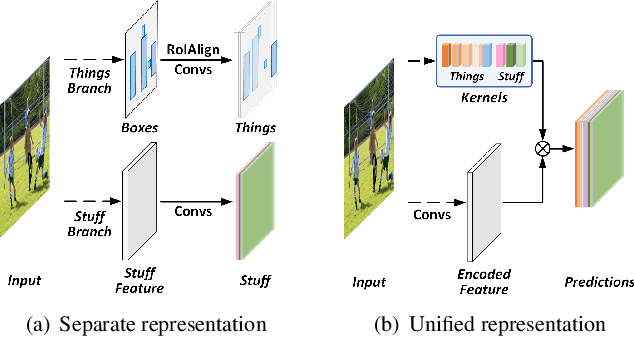
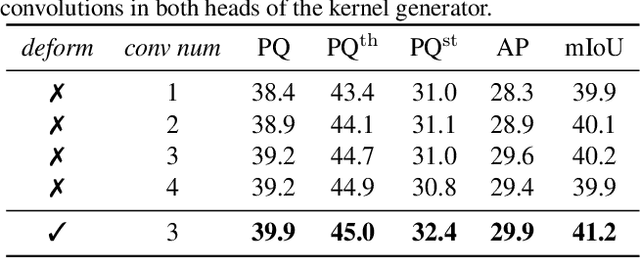
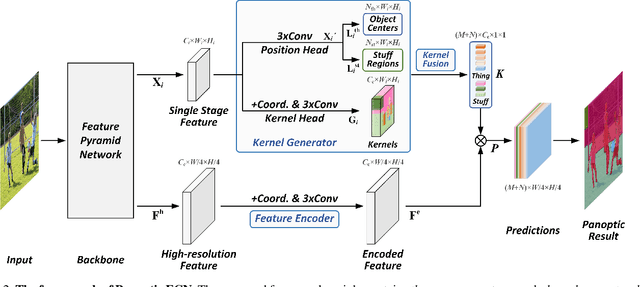
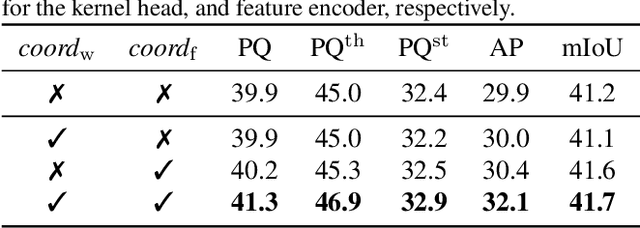
In this paper, we present a conceptually simple, strong, and efficient framework for panoptic segmentation, called Panoptic FCN. Our approach aims to represent and predict foreground things and background stuff in a unified fully convolutional pipeline. In particular, Panoptic FCN encodes each object instance or stuff category into a specific kernel weight with the proposed kernel generator and produces the prediction by convolving the high-resolution feature directly. With this approach, instance-aware and semantically consistent properties for things and stuff can be respectively satisfied in a simple generate-kernel-then-segment workflow. Without extra boxes for localization or instance separation, the proposed approach outperforms previous box-based and -free models with high efficiency on COCO, Cityscapes, and Mapillary Vistas datasets with single scale input. Our code is made publicly available at https://github.com/yanwei-li/PanopticFCN.
Learnable Boundary Guided Adversarial Training
Nov 23, 2020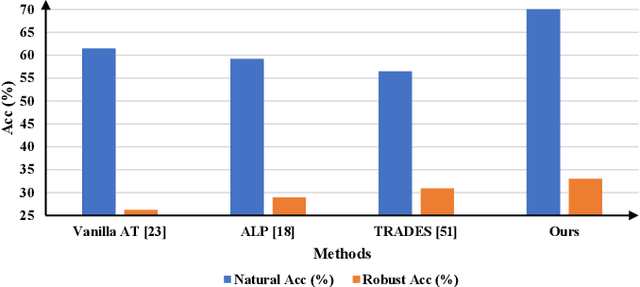
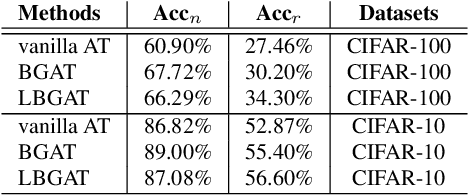
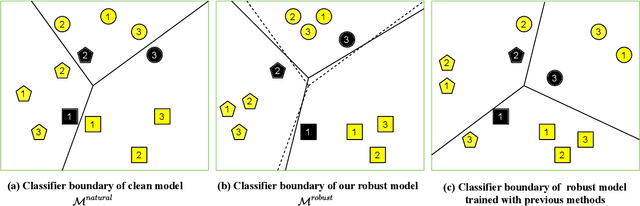
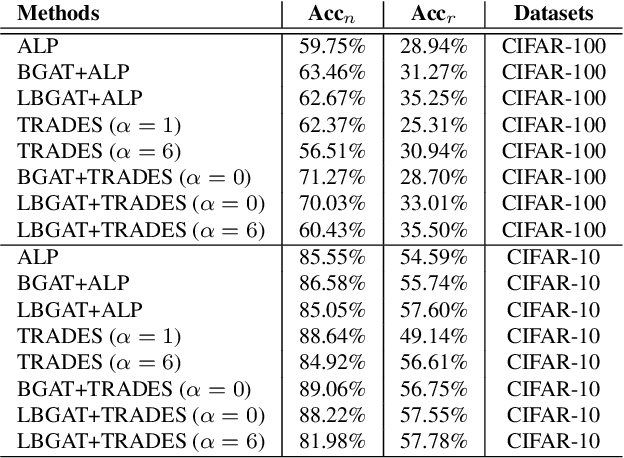
Previous adversarial training raises model robustness under the compromise of accuracy on natural data. In this paper, our target is to reduce natural accuracy degradation. We use the model logits from one clean model $\mathcal{M}^{natural}$ to guide learning of the robust model $\mathcal{M}^{robust}$, taking into consideration that logits from the well trained clean model $\mathcal{M}^{natural}$ embed the most discriminative features of natural data, {\it e.g.}, generalizable classifier boundary. Our solution is to constrain logits from the robust model $\mathcal{M}^{robust}$ that takes adversarial examples as input and make it similar to those from a clean model $\mathcal{M}^{natural}$ fed with corresponding natural data. It lets $\mathcal{M}^{robust}$ inherit the classifier boundary of $\mathcal{M}^{natural}$. Thus, we name our method Boundary Guided Adversarial Training (BGAT). Moreover, we generalize BGAT to Learnable Boundary Guided Adversarial Training (LBGAT) by training $\mathcal{M}^{natural}$ and $\mathcal{M}^{robust}$ simultaneously and collaboratively to learn one most robustness-friendly classifier boundary for the strongest robustness. Extensive experiments are conducted on CIFAR-10, CIFAR-100, and challenging Tiny ImageNet datasets. Along with other state-of-the-art adversarial training approaches, {\it e.g.}, Adversarial Logit Pairing (ALP) and TRADES, the performance is further enhanced.
Improved Analysis of Clipping Algorithms for Non-convex Optimization
Oct 29, 2020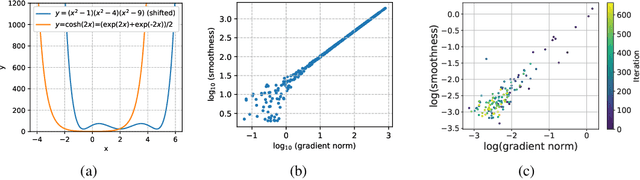

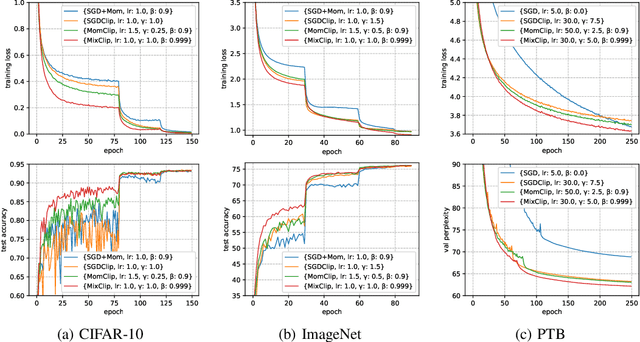
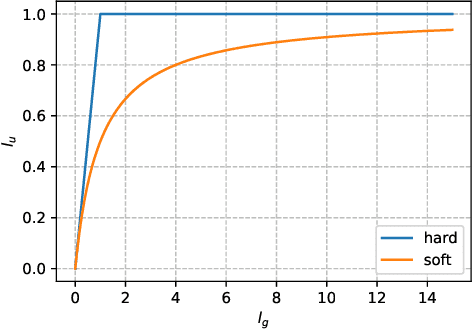
Gradient clipping is commonly used in training deep neural networks partly due to its practicability in relieving the exploding gradient problem. Recently, \citet{zhang2019gradient} show that clipped (stochastic) Gradient Descent (GD) converges faster than vanilla GD/SGD via introducing a new assumption called $(L_0, L_1)$-smoothness, which characterizes the violent fluctuation of gradients typically encountered in deep neural networks. However, their iteration complexities on the problem-dependent parameters are rather pessimistic, and theoretical justification of clipping combined with other crucial techniques, e.g. momentum acceleration, are still lacking. In this paper, we bridge the gap by presenting a general framework to study the clipping algorithms, which also takes momentum methods into consideration. We provide convergence analysis of the framework in both deterministic and stochastic setting, and demonstrate the tightness of our results by comparing them with existing lower bounds. Our results imply that the efficiency of clipping methods will not degenerate even in highly non-smooth regions of the landscape. Experiments confirm the superiority of clipping-based methods in deep learning tasks.