 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-aided Active User Detection with False Alarm Correction in Grant-Free Transmission
Jul 26, 2022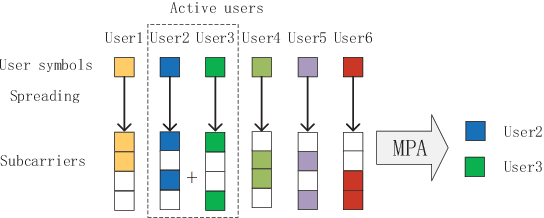
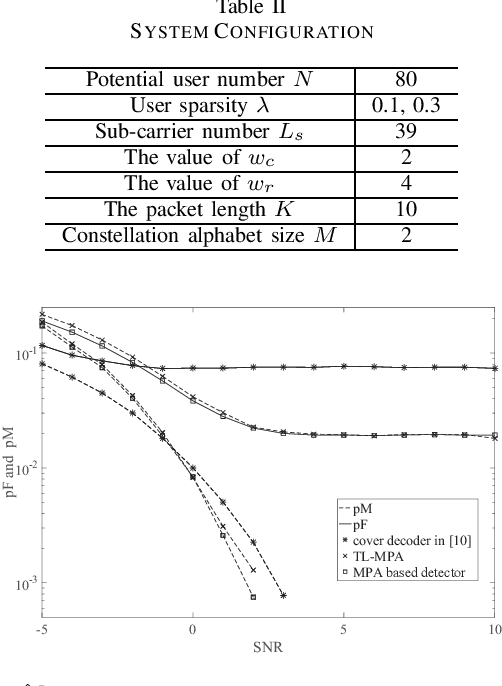
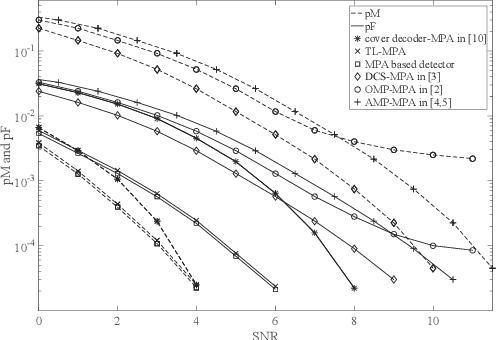
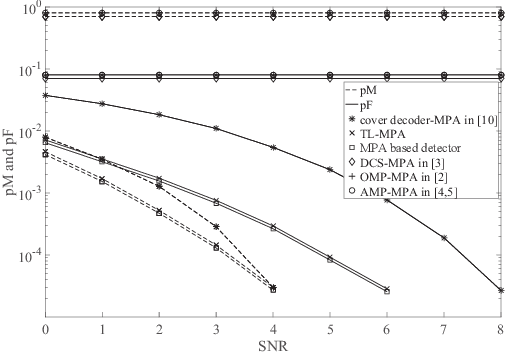
In most existing grant-free (GF) studies, the two key tasks, namely active user detection (AUD) and payload data decoding, are handled separately. In this paper, a two-step dataaided AUD scheme is proposed, namely the initial AUD step and the false alarm correction step respectively. To implement the initial AUD step, an embedded low-density-signature (LDS) based preamble pool is constructed. In addition, two message passing algorithm (MPA) based initial estimators are developed. In the false alarm correction step, a redundant factor graph is constructed based on the initial active user set, on which MPA is employed for data decoding. The remaining false detected inactive users will be further recognized by the false alarm corrector with the aid of decoded data symbols. Simulation results reveal that both the data decoding performance and the AUD performance are significantly enhanced by more than 1:5 dB at the target accuracy of 10^3 compared with the traditional compressed sensing (CS) based counterparts
Dynamic Proposals for Efficient Object Detection
Jul 12, 2022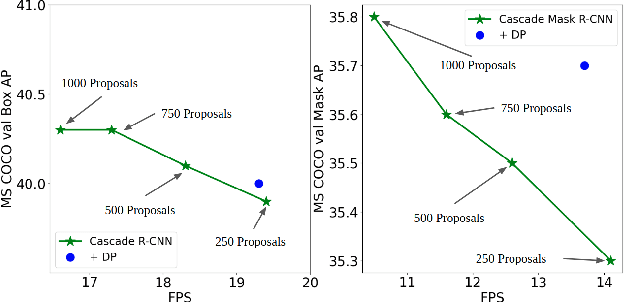
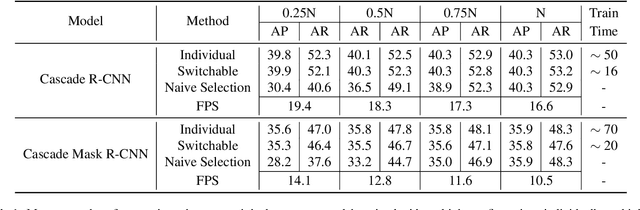
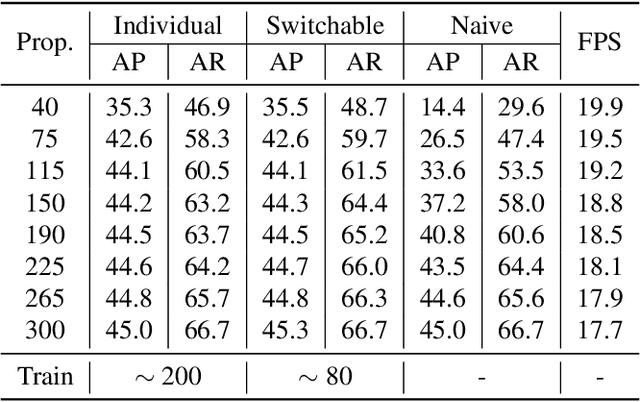
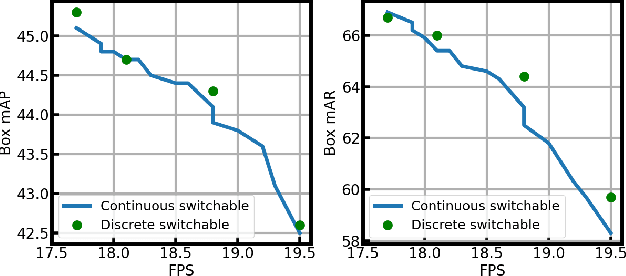
Object detection is a basic computer vision task to loccalize and categorize objects in a given image. Most state-of-the-art detection methods utilize a fixed number of proposals as an intermediate representation of object candidates, which is unable to adapt to different computational constraints during inference. In this paper, we propose a simple yet effective method which is adaptive to different computational resources by generating dynamic proposals for object detection. We first design a module to make a single query-based model to be able to inference with different numbers of proposals. Further, we extend it to a dynamic model to choose the number of proposals according to the input image, greatly reducing computational costs. Our method achieves significant speed-up across a wide range of detection models including two-stage and query-based models while obtaining similar or even better accuracy.
Robust High-Resolution Video Matting with Temporal Guidance
Aug 25, 2021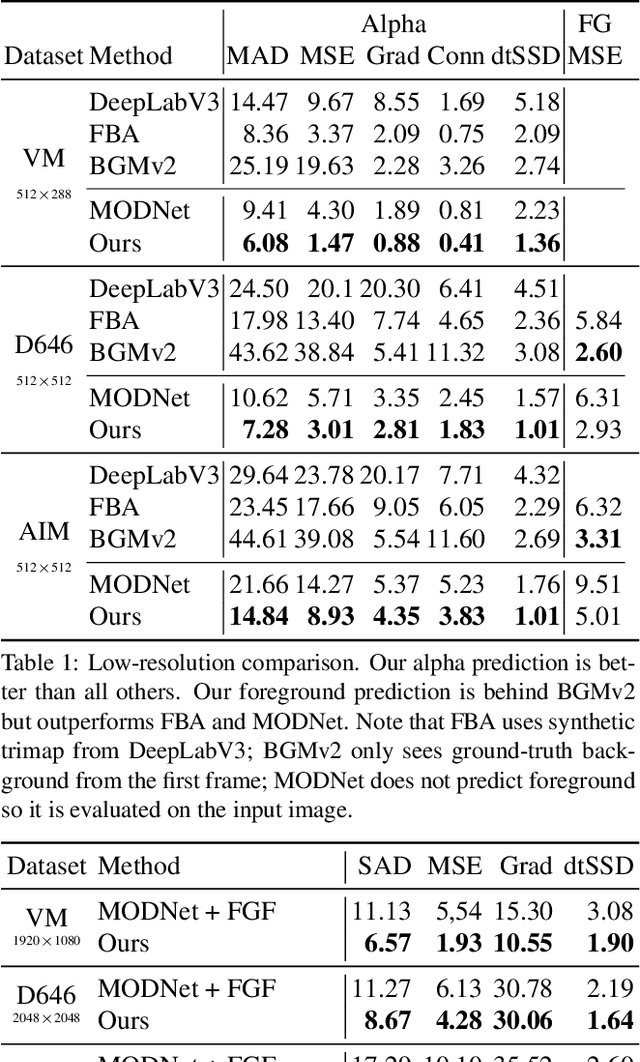
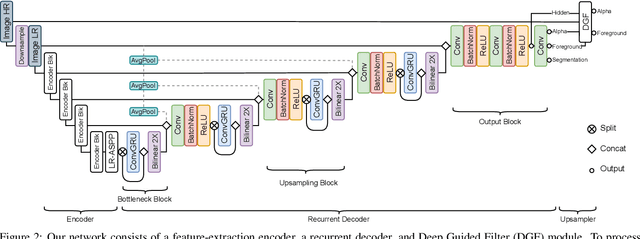
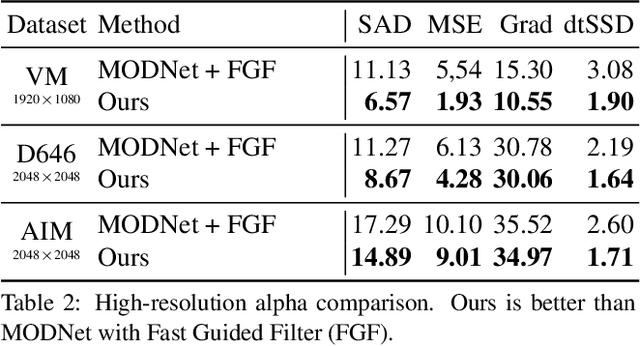
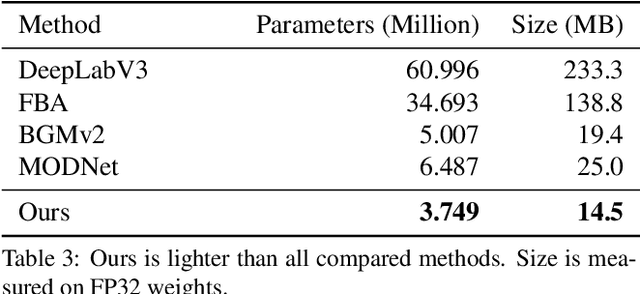
We introduce a robust, real-time, high-resolution human video matting method that achieves new state-of-the-art performance. Our method is much lighter than previous approaches and can process 4K at 76 FPS and HD at 104 FPS on an Nvidia GTX 1080Ti GPU. Unlike most existing methods that perform video matting frame-by-frame as independent images, our method uses a recurrent architecture to exploit temporal information in videos and achieves significant improvements in temporal coherence and matting quality. Furthermore, we propose a novel training strategy that enforces our network on both matting and segmentation objectives. This significantly improves our model's robustness. Our method does not require any auxiliary inputs such as a trimap or a pre-captured background image, so it can be widely applied to existing human matting applications.
HR-NAS: Searching Efficient High-Resolution Neural Architectures with Lightweight Transformers
Jun 11, 2021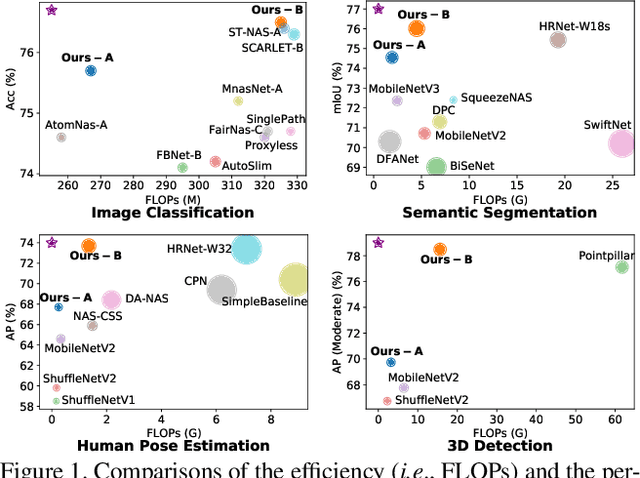
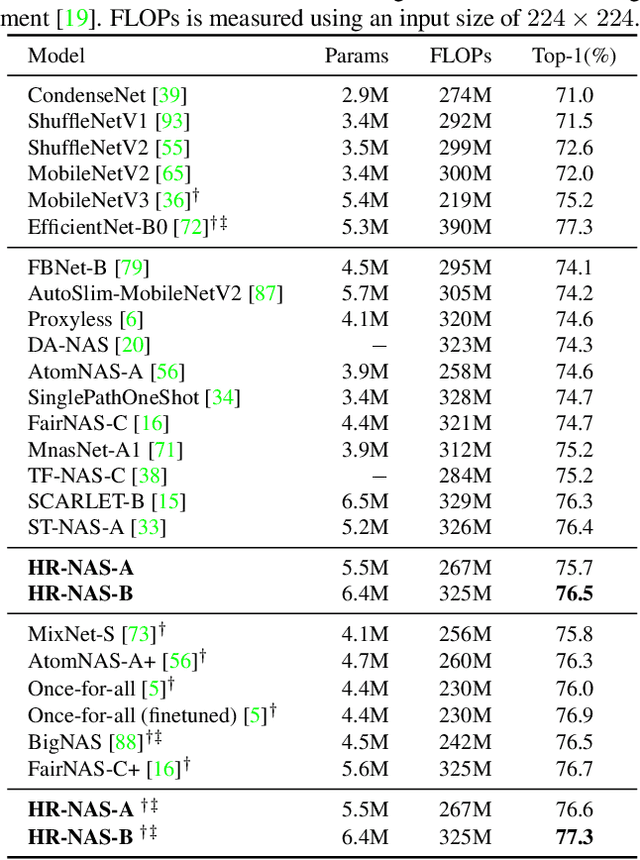
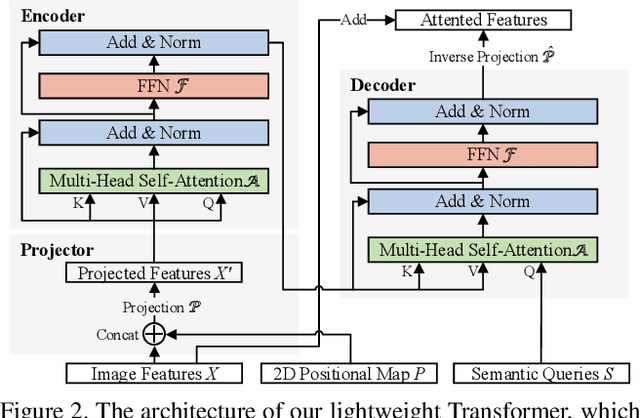
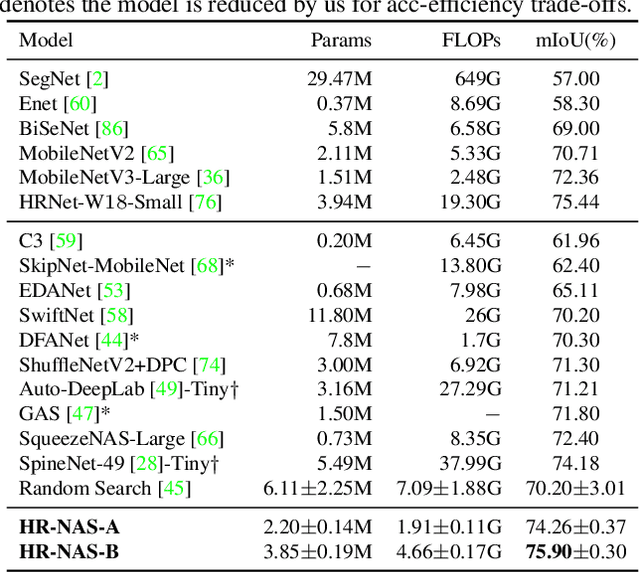
High-resolution representations (HR) are essential for dense prediction tasks such as segmentation, detection, and pose estimation. Learning HR representations is typically ignored in previous Neural Architecture Search (NAS) methods that focus on image classification. This work proposes a novel NAS method, called HR-NAS, which is able to find efficient and accurate networks for different tasks, by effectively encoding multiscale contextual information while maintaining high-resolution representations. In HR-NAS, we renovate the NAS search space as well as its searching strategy. To better encode multiscale image contexts in the search space of HR-NAS, we first carefully design a lightweight transformer, whose computational complexity can be dynamically changed with respect to different objective functions and computation budgets. To maintain high-resolution representations of the learned networks, HR-NAS adopts a multi-branch architecture that provides convolutional encoding of multiple feature resolutions, inspired by HRNet. Last, we proposed an efficient fine-grained search strategy to train HR-NAS, which effectively explores the search space, and finds optimal architectures given various tasks and computation resources. HR-NAS is capable of achieving state-of-the-art trade-offs between performance and FLOPs for three dense prediction tasks and an image classification task, given only small computational budgets. For example, HR-NAS surpasses SqueezeNAS that is specially designed for semantic segmentation while improving efficiency by 45.9%. Code is available at https://github.com/dingmyu/HR-NAS
Is In-Domain Data Really Needed? A Pilot Study on Cross-Domain Calibration for Network Quantization
May 16, 2021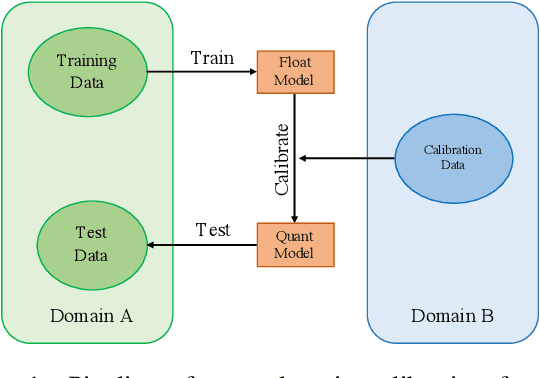
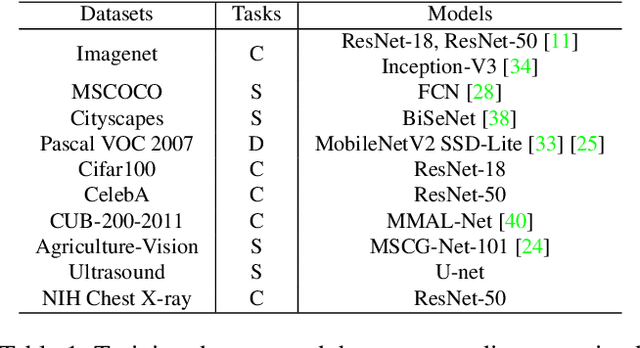

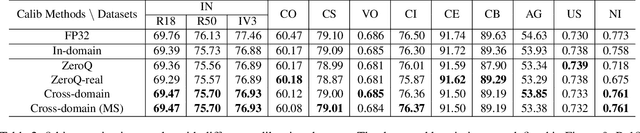
Post-training quantization methods use a set of calibration data to compute quantization ranges for network parameters and activations. The calibration data usually comes from the training dataset which could be inaccessible due to sensitivity of the data. In this work, we want to study such a problem: can we use out-of-domain data to calibrate the trained networks without knowledge of the original dataset? Specifically, we go beyond the domain of natural images to include drastically different domains such as X-ray images, satellite images and ultrasound images. We find cross-domain calibration leads to surprisingly stable performance of quantized models on 10 tasks in different image domains with 13 different calibration datasets. We also find that the performance of quantized models is correlated with the similarity of the Gram matrices between the source and calibration domains, which can be used as a criterion to choose calibration set for better performance. We believe our research opens the door to borrow cross-domain knowledge for network quantization and compression.
DeepViT: Towards Deeper Vision Transformer
Apr 19, 2021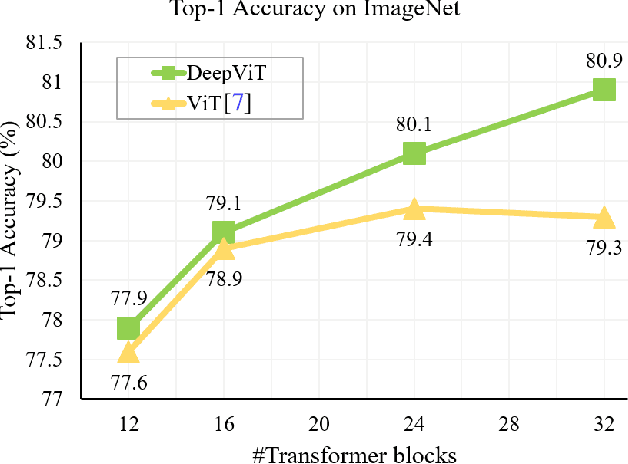
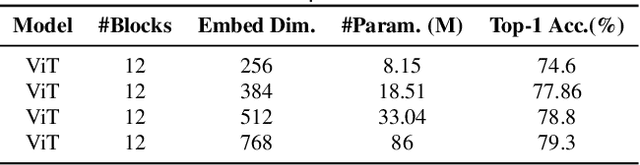
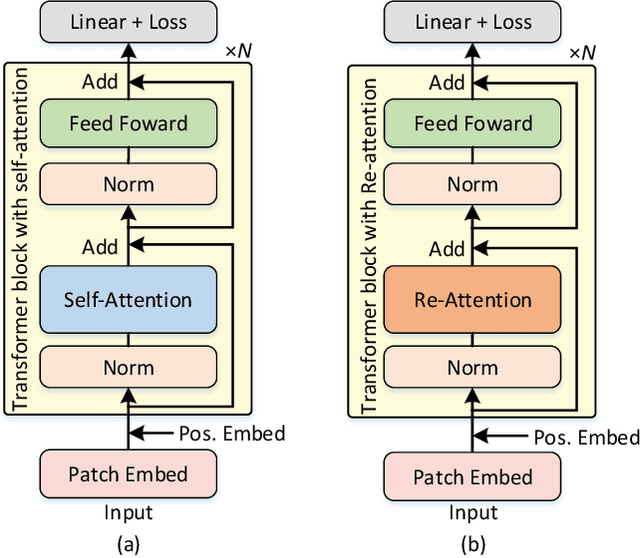

Vision transformers (ViTs) have been successfully applied in image classification tasks recently. In this paper, we show that, unlike convolution neural networks (CNNs)that can be improved by stacking more convolutional layers, the performance of ViTs saturate fast when scaled to be deeper. More specifically, we empirically observe that such scaling difficulty is caused by the attention collapse issue: as the transformer goes deeper, the attention maps gradually become similar and even much the same after certain layers. In other words, the feature maps tend to be identical in the top layers of deep ViT models. This fact demonstrates that in deeper layers of ViTs, the self-attention mechanism fails to learn effective concepts for representation learning and hinders the model from getting expected performance gain. Based on above observation, we propose a simple yet effective method, named Re-attention, to re-generate the attention maps to increase their diversity at different layers with negligible computation and memory cost. The pro-posed method makes it feasible to train deeper ViT models with consistent performance improvements via minor modification to existing ViT models. Notably, when training a deep ViT model with 32 transformer blocks, the Top-1 classification accuracy can be improved by 1.6% on ImageNet. Code is publicly available at https://github.com/zhoudaquan/dvit_repo.
Progressive Temporal Feature Alignment Network for Video Inpainting
Apr 08, 2021
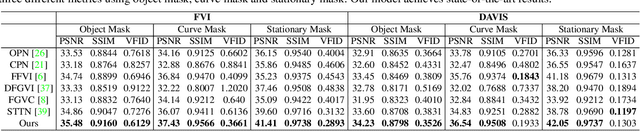
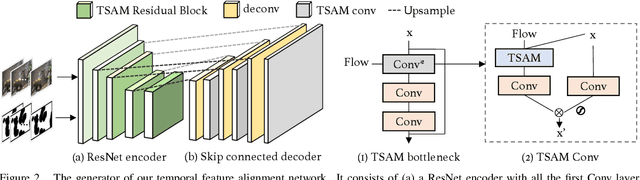

Video inpainting aims to fill spatio-temporal "corrupted" regions with plausible content. To achieve this goal, it is necessary to find correspondences from neighbouring frames to faithfully hallucinate the unknown content. Current methods achieve this goal through attention, flow-based warping, or 3D temporal convolution. However, flow-based warping can create artifacts when optical flow is not accurate, while temporal convolution may suffer from spatial misalignment. We propose 'Progressive Temporal Feature Alignment Network', which progressively enriches features extracted from the current frame with the feature warped from neighbouring frames using optical flow. Our approach corrects the spatial misalignment in the temporal feature propagation stage, greatly improving visual quality and temporal consistency of the inpainted videos. Using the proposed architecture, we achieve state-of-the-art performance on the DAVIS and FVI datasets compared to existing deep learning approaches. Code is available at https://github.com/MaureenZOU/TSAM.
Learning Versatile Neural Architectures by Propagating Network Codes
Mar 24, 2021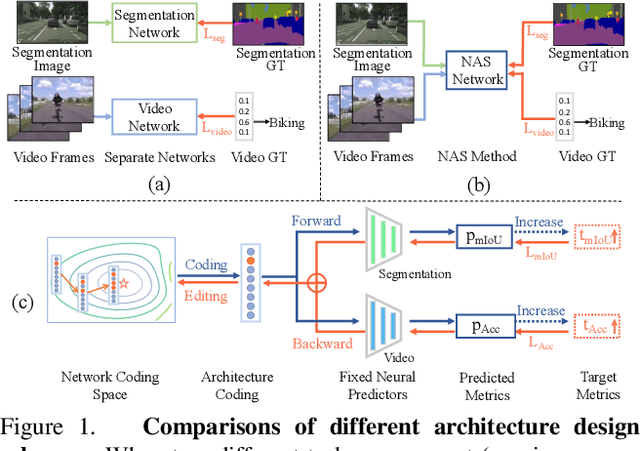

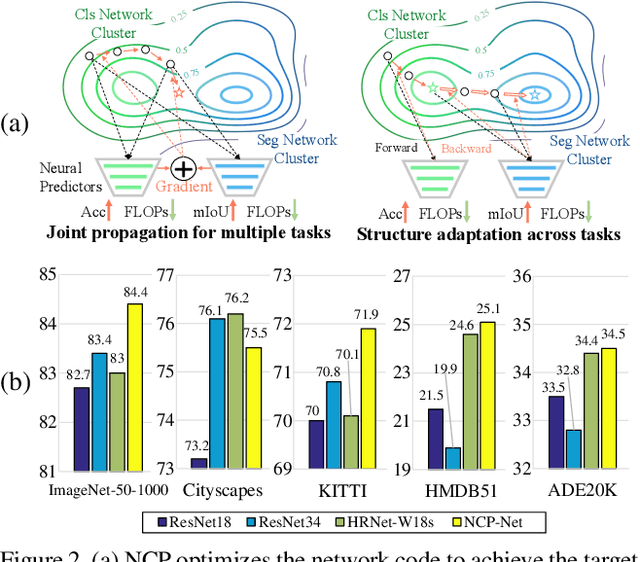
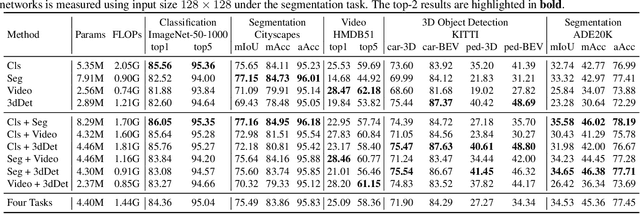
This work explores how to design a single neural network that is capable of adapting to multiple heterogeneous tasks of computer vision, such as image segmentation, 3D detection, and video recognition. This goal is challenging because network architecture designs in different tasks are inconsistent. We solve this challenge by proposing Network Coding Propagation (NCP), a novel "neural predictor", which is able to predict an architecture's performance in multiple datasets and tasks. Unlike prior arts of neural architecture search (NAS) that typically focus on a single task, NCP has several unique benefits. (1) NCP can be trained on different NAS benchmarks, such as NAS-Bench-201 and NAS-Bench-MR, which contains a novel network space designed by us for jointly searching an architecture among multiple tasks, including ImageNet, Cityscapes, KITTI, and HMDB51. (2) NCP learns from network codes but not original data, enabling it to update the architecture efficiently across datasets. (3) Extensive experiments evaluate NCP on object classification, detection, segmentation, and video recognition. For example, with 17\% fewer FLOPs, a single architecture returned by NCP achieves 86\% and 77.16\% on ImageNet-50-1000 and Cityscapes respectively, outperforming its counterparts. More interestingly, NCP enables a single architecture applicable to both image segmentation and video recognition, which achieves competitive performance on both HMDB51 and ADE20K compared to the singular counterparts. Code is available at https://github.com/dingmyu/NCP}{https://github.com/dingmyu/NCP.
AutoSpace: Neural Architecture Search with Less Human Interference
Mar 22, 2021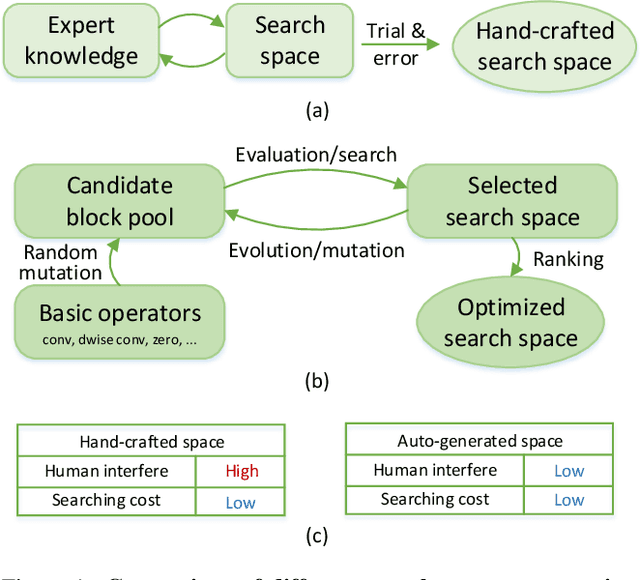
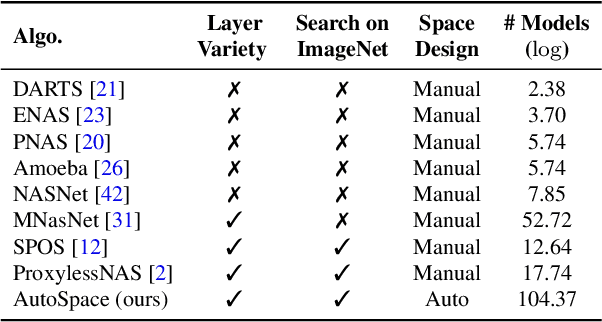
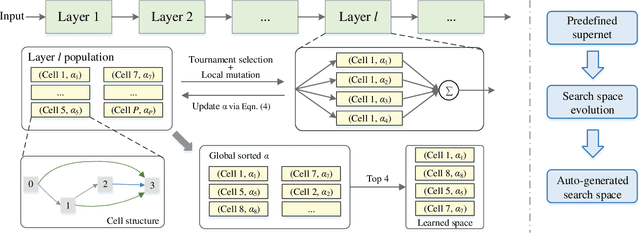
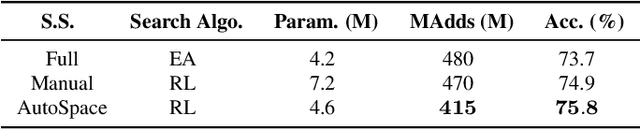
Current neural architecture search (NAS) algorithms still require expert knowledge and effort to design a search space for network construction. In this paper, we consider automating the search space design to minimize human interference, which however faces two challenges: the explosive complexity of the exploration space and the expensive computation cost to evaluate the quality of different search spaces. To solve them, we propose a novel differentiable evolutionary framework named AutoSpace, which evolves the search space to an optimal one with following novel techniques: a differentiable fitness scoring function to efficiently evaluate the performance of cells and a reference architecture to speedup the evolution procedure and avoid falling into sub-optimal solutions. The framework is generic and compatible with additional computational constraints, making it feasible to learn specialized search spaces that fit different computational budgets. With the learned search space, the performance of recent NAS algorithms can be improved significantly compared with using previously manually designed spaces. Remarkably, the models generated from the new search space achieve 77.8% top-1 accuracy on ImageNet under the mobile setting (MAdds < 500M), out-performing previous SOTA EfficientNet-B0 by 0.7%. All codes will be made public.
CompFeat: Comprehensive Feature Aggregation for Video Instance Segmentation
Dec 07, 2020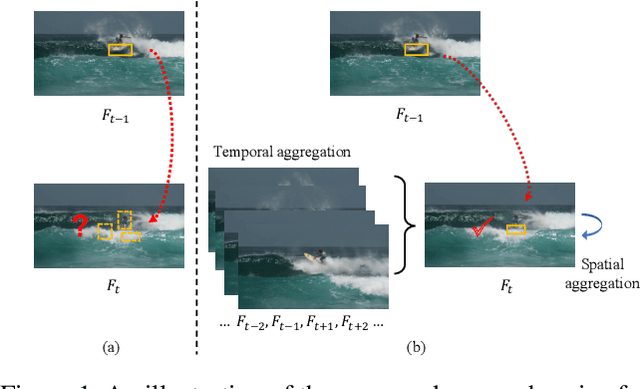

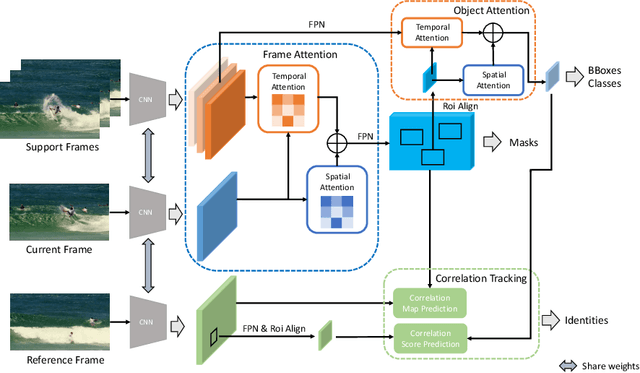
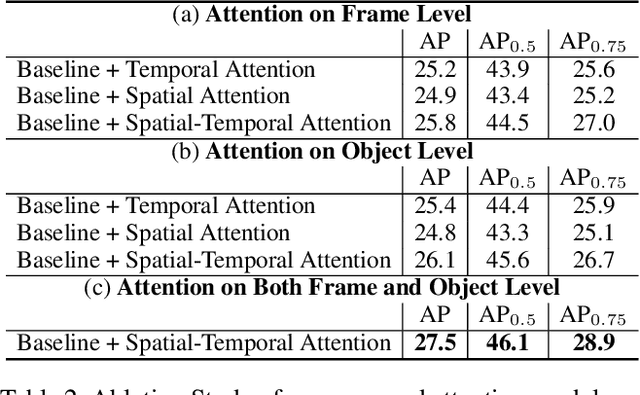
Video instance segmentation is a complex task in which we need to detect, segment, and track each object for any given video. Previous approaches only utilize single-frame features for the detection, segmentation, and tracking of objects and they suffer in the video scenario due to several distinct challenges such as motion blur and drastic appearance change. To eliminate ambiguities introduced by only using single-frame features, we propose a novel comprehensive feature aggregation approach (CompFeat) to refine features at both frame-level and object-level with temporal and spatial context information. The aggregation process is carefully designed with a new attention mechanism which significantly increases the discriminative power of the learned features. We further improve the tracking capability of our model through a siamese design by incorporating both feature similarities and spatial similarities. Experiments conducted on the YouTube-VIS dataset validate the effectiveness of proposed CompFeat. Our code will be available at https://github.com/SHI-Labs/CompFeat-for-Video-Instance-Segmentation.