 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Fast Unrank in Collaborative Filtering Recommendation
Nov 10, 2025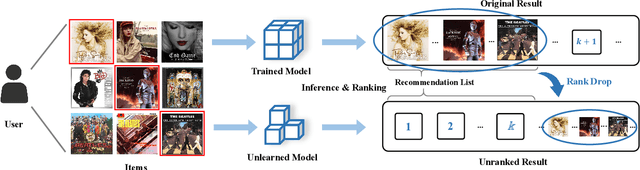
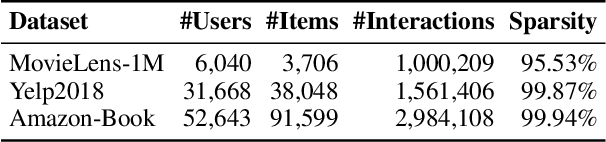
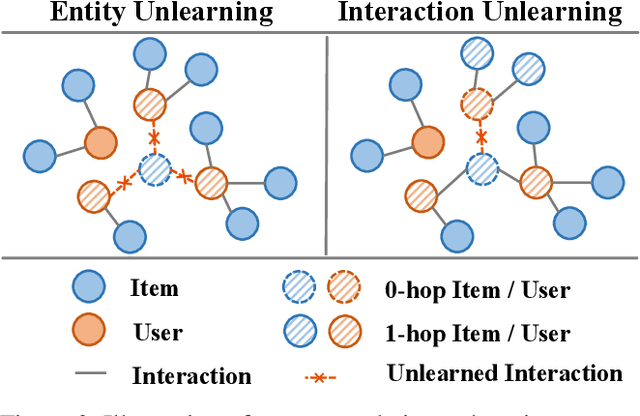
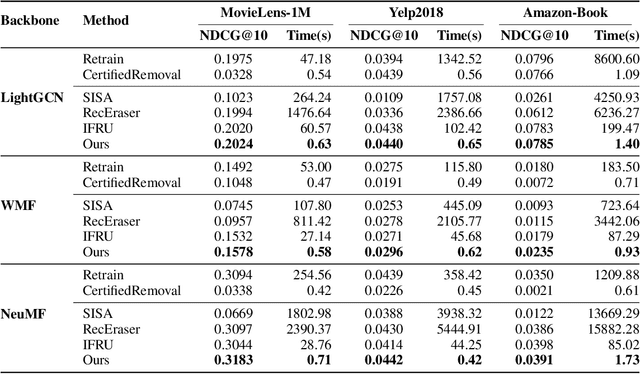
Modern data-driven recommendation systems risk memorizing sensitive user behavioral patterns, raising privacy concerns. Existing recommendation unlearning methods, while capable of removing target data influence, suffer from inefficient unlearning speed and degraded performance, failing to meet real-time unlearning demands. Considering the ranking-oriented nature of recommendation systems, we present unranking, the process of reducing the ranking positions of target items while ensuring the formal guarantees of recommendation unlearning. To achieve efficient unranking, we propose Learning to Fast Unrank in Collaborative Filtering Recommendation (L2UnRank), which operates through three key stages: (a) identifying the influenced scope via interaction-based p-hop propagation, (b) computing structural and semantic influences for entities within this scope, and (c) performing efficient, ranking-aware parameter updates guided by influence information. Extensive experiments across multiple datasets and backbone models demonstrate L2UnRank's model-agnostic nature, achieving state-of-the-art unranking effectiveness and maintaining recommendation quality comparable to retraining, while also delivering a 50x speedup over existing methods. Codes are available at https://github.com/Juniper42/L2UnRank.
Interaction-Centric Knowledge Infusion and Transfer for Open-Vocabulary Scene Graph Generation
Nov 08, 2025



Open-vocabulary scene graph generation (OVSGG) extends traditional SGG by recognizing novel objects and relationships beyond predefined categories, leveraging the knowledge from pre-trained large-scale models. Existing OVSGG methods always adopt a two-stage pipeline: 1) \textit{Infusing knowledge} into large-scale models via pre-training on large datasets; 2) \textit{Transferring knowledge} from pre-trained models with fully annotated scene graphs during supervised fine-tuning. However, due to a lack of explicit interaction modeling, these methods struggle to distinguish between interacting and non-interacting instances of the same object category. This limitation induces critical issues in both stages of OVSGG: it generates noisy pseudo-supervision from mismatched objects during knowledge infusion, and causes ambiguous query matching during knowledge transfer. To this end, in this paper, we propose an inter\textbf{AC}tion-\textbf{C}entric end-to-end OVSGG framework (\textbf{ACC}) in an interaction-driven paradigm to minimize these mismatches. For \textit{interaction-centric knowledge infusion}, ACC employs a bidirectional interaction prompt for robust pseudo-supervision generation to enhance the model's interaction knowledge. For \textit{interaction-centric knowledge transfer}, ACC first adopts interaction-guided query selection that prioritizes pairing interacting objects to reduce interference from non-interacting ones. Then, it integrates interaction-consistent knowledge distillation to bolster robustness by pushing relational foreground away from the background while retaining general knowledge. Extensive experimental results on three benchmarks show that ACC achieves state-of-the-art performance, demonstrating the potential of interaction-centric paradigms for real-world applications.
Pedicle Screw Pairing and Registration for Screw Pose Estimation from Dual C-arm Images Using CAD Models
Nov 07, 2025Accurate matching of pedicle screws in both anteroposterior (AP) and lateral (LAT) images is critical for successful spinal decompression and stabilization during surgery. However, establishing screw correspondence, especially in LAT views, remains a significant clinical challenge. This paper introduces a method to address pedicle screw correspondence and pose estimation from dual C-arm images. By comparing screw combinations, the approach demonstrates consistent accuracy in both pairing and registration tasks. The method also employs 2D-3D alignment with screw CAD 3D models to accurately pair and estimate screw pose from dual views. Our results show that the correct screw combination consistently outperforms incorrect pairings across all test cases, even prior to registration. After registration, the correct combination further enhances alignment between projections and images, significantly reducing projection error. This approach shows promise for improving surgical outcomes in spinal procedures by providing reliable feedback on screw positioning.
UniVoice: Unifying Autoregressive ASR and Flow-Matching based TTS with Large Language Models
Oct 06, 2025



Large language models (LLMs) have demonstrated promising performance in both automatic speech recognition (ASR) and text-to-speech (TTS) systems, gradually becoming the mainstream approach. However, most current approaches address these tasks separately rather than through a unified framework. This work aims to integrate these two tasks into one unified model. Although discrete speech tokenization enables joint modeling, its inherent information loss limits performance in both recognition and generation. In this work, we present UniVoice, a unified LLM framework through continuous representations that seamlessly integrates speech recognition and synthesis within a single model. Our approach combines the strengths of autoregressive modeling for speech recognition with flow matching for high-quality generation. To mitigate the inherent divergence between autoregressive and flow-matching models, we further design a dual attention mechanism, which switches between a causal mask for recognition and a bidirectional attention mask for synthesis. Furthermore, the proposed text-prefix-conditioned speech infilling method enables high-fidelity zero-shot voice cloning. Experimental results demonstrate that our method can achieve or exceed current single-task modeling methods in both ASR and zero-shot TTS tasks. This work explores new possibilities for end-to-end speech understanding and generation.
Goal-Guided Efficient Exploration via Large Language Model in Reinforcement Learning
Sep 26, 2025Real-world decision-making tasks typically occur in complex and open environments, posing significant challenges to reinforcement learning (RL) agents' exploration efficiency and long-horizon planning capabilities. A promising approach is LLM-enhanced RL, which leverages the rich prior knowledge and strong planning capabilities of LLMs to guide RL agents in efficient exploration. However, existing methods mostly rely on frequent and costly LLM invocations and suffer from limited performance due to the semantic mismatch. In this paper, we introduce a Structured Goal-guided Reinforcement Learning (SGRL) method that integrates a structured goal planner and a goal-conditioned action pruner to guide RL agents toward efficient exploration. Specifically, the structured goal planner utilizes LLMs to generate a reusable, structured function for goal generation, in which goals are prioritized. Furthermore, by utilizing LLMs to determine goals' priority weights, it dynamically generates forward-looking goals to guide the agent's policy toward more promising decision-making trajectories. The goal-conditioned action pruner employs an action masking mechanism that filters out actions misaligned with the current goal, thereby constraining the RL agent to select goal-consistent policies. We evaluate the proposed method on Crafter and Craftax-Classic, and experimental results demonstrate that SGRL achieves superior performance compared to existing state-of-the-art methods.
MeanFlowSE: one-step generative speech enhancement via conditional mean flow
Sep 18, 2025


Multistep inference is a bottleneck for real-time generative speech enhancement because flow- and diffusion-based systems learn an instantaneous velocity field and therefore rely on iterative ordinary differential equation (ODE) solvers. We introduce MeanFlowSE, a conditional generative model that learns the average velocity over finite intervals along a trajectory. Using a Jacobian-vector product (JVP) to instantiate the MeanFlow identity, we derive a local training objective that directly supervises finite-interval displacement while remaining consistent with the instantaneous-field constraint on the diagonal. At inference, MeanFlowSE performs single-step generation via a backward-in-time displacement, removing the need for multistep solvers; an optional few-step variant offers additional refinement. On VoiceBank-DEMAND, the single-step model achieves strong intelligibility, fidelity, and perceptual quality with substantially lower computational cost than multistep baselines. The method requires no knowledge distillation or external teachers, providing an efficient, high-fidelity framework for real-time generative speech enhancement.
Transplant-Ready? Evaluating AI Lung Segmentation Models in Candidates with Severe Lung Disease
Sep 18, 2025



This study evaluates publicly available deep-learning based lung segmentation models in transplant-eligible patients to determine their performance across disease severity levels, pathology categories, and lung sides, and to identify limitations impacting their use in preoperative planning in lung transplantation. This retrospective study included 32 patients who underwent chest CT scans at Duke University Health System between 2017 and 2019 (total of 3,645 2D axial slices). Patients with standard axial CT scans were selected based on the presence of two or more lung pathologies of varying severity. Lung segmentation was performed using three previously developed deep learning models: Unet-R231, TotalSegmentator, MedSAM. Performance was assessed using quantitative metrics (volumetric similarity, Dice similarity coefficient, Hausdorff distance) and a qualitative measure (four-point clinical acceptability scale). Unet-R231 consistently outperformed TotalSegmentator and MedSAM in general, for different severity levels, and pathology categories (p<0.05). All models showed significant performance declines from mild to moderate-to-severe cases, particularly in volumetric similarity (p<0.05), without significant differences among lung sides or pathology types. Unet-R231 provided the most accurate automated lung segmentation among evaluated models with TotalSegmentator being a close second, though their performance declined significantly in moderate-to-severe cases, emphasizing the need for specialized model fine-tuning in severe pathology contexts.
VoxHammer: Training-Free Precise and Coherent 3D Editing in Native 3D Space
Aug 26, 2025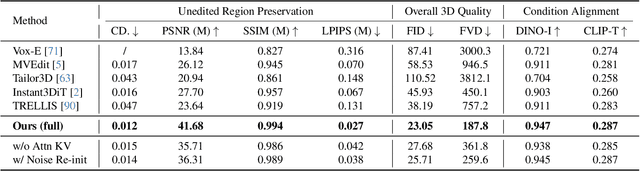
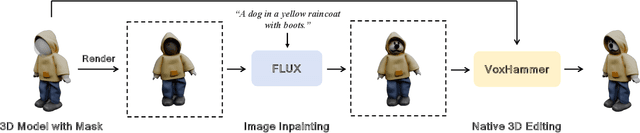

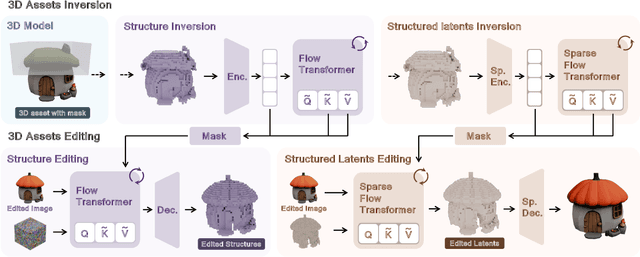
3D local editing of specified regions is crucial for game industry and robot interaction. Recent methods typically edit rendered multi-view images and then reconstruct 3D models, but they face challenges in precisely preserving unedited regions and overall coherence. Inspired by structured 3D generative models, we propose VoxHammer, a novel training-free approach that performs precise and coherent editing in 3D latent space. Given a 3D model, VoxHammer first predicts its inversion trajectory and obtains its inverted latents and key-value tokens at each timestep. Subsequently, in the denoising and editing phase, we replace the denoising features of preserved regions with the corresponding inverted latents and cached key-value tokens. By retaining these contextual features, this approach ensures consistent reconstruction of preserved areas and coherent integration of edited parts. To evaluate the consistency of preserved regions, we constructed Edit3D-Bench, a human-annotated dataset comprising hundreds of samples, each with carefully labeled 3D editing regions. Experiments demonstrate that VoxHammer significantly outperforms existing methods in terms of both 3D consistency of preserved regions and overall quality. Our method holds promise for synthesizing high-quality edited paired data, thereby laying the data foundation for in-context 3D generation. See our project page at https://huanngzh.github.io/VoxHammer-Page/.
Synchrosqueezed X-Ray Wavelet-Chirplet Transform for Accurate Chirp Rate Estimation and Retrieval of Modes from Multicomponent Signals with Crossover Instantaneous Frequencies
Aug 25, 2025Recent advances in the chirplet transform and wavelet-chirplet transform (WCT) have enabled the estimation of instantaneous frequencies (IFs) and chirprates, as well as mode retrieval from multicomponent signals with crossover IF curves. However, chirprate estimation via these approaches remains less accurate than IF estimation, primarily due to the slow decay of the chirplet transform or WCT along the chirprate direction. To address this, the synchrosqueezed chirplet transform (SCT) and multiple SCT methods were proposed, achieving moderate improvements in IF and chirprate estimation accuracy. Nevertheless, a novel approach is still needed to enhance the transform's decay along the chirprate direction. This paper introduces an X-ray transform-based wavelet-chirprate transform, termed the X-ray wavelet-chirplet transform (XWCT), which exhibits superior decay along the chirprate direction compared to the WCT. Furthermore, third-order synchrosqueezed variants of the WCT and XWCT are developed to yield sharp time-frequency-chirprate representations of signals. Experimental results demonstrate that the XWCT achieves significantly faster decay along the chirprate axis, while the third-order synchrosqueezed XWCT enables accurate IF and chirprate estimation, as well as mode retrieval, without requiring multiple synchrosqueezing operations.
Enhancing Transferability and Consistency in Cross-Domain Recommendations via Supervised Disentanglement
Jul 23, 2025Cross-domain recommendation (CDR) aims to alleviate the data sparsity by transferring knowledge across domains. Disentangled representation learning provides an effective solution to model complex user preferences by separating intra-domain features (domain-shared and domain-specific features), thereby enhancing robustness and interpretability. However, disentanglement-based CDR methods employing generative modeling or GNNs with contrastive objectives face two key challenges: (i) pre-separation strategies decouple features before extracting collaborative signals, disrupting intra-domain interactions and introducing noise; (ii) unsupervised disentanglement objectives lack explicit task-specific guidance, resulting in limited consistency and suboptimal alignment. To address these challenges, we propose DGCDR, a GNN-enhanced encoder-decoder framework. To handle challenge (i), DGCDR first applies GNN to extract high-order collaborative signals, providing enriched representations as a robust foundation for disentanglement. The encoder then dynamically disentangles features into domain-shared and -specific spaces, preserving collaborative information during the separation process. To handle challenge (ii), the decoder introduces an anchor-based supervision that leverages hierarchical feature relationships to enhance intra-domain consistency and cross-domain alignment. Extensive experiments on real-world datasets demonstrate that DGCDR achieves state-of-the-art performance, with improvements of up to 11.59% across key metrics. Qualitative analyses further validate its superior disentanglement quality and transferability. Our source code and datasets are available on GitHub for further comparison.