 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Prior Guided Feature Representation Learning for Long-Tailed Classification
Jan 21, 2024



Real-world data are long-tailed, the lack of tail samples leads to a significant limitation in the generalization ability of the model. Although numerous approaches of class re-balancing perform well for moderate class imbalance problems, additional knowledge needs to be introduced to help the tail class recover the underlying true distribution when the observed distribution from a few tail samples does not represent its true distribution properly, thus allowing the model to learn valuable information outside the observed domain. In this work, we propose to leverage the geometric information of the feature distribution of the well-represented head class to guide the model to learn the underlying distribution of the tail class. Specifically, we first systematically define the geometry of the feature distribution and the similarity measures between the geometries, and discover four phenomena regarding the relationship between the geometries of different feature distributions. Then, based on four phenomena, feature uncertainty representation is proposed to perturb the tail features by utilizing the geometry of the head class feature distribution. It aims to make the perturbed features cover the underlying distribution of the tail class as much as possible, thus improving the model's generalization performance in the test domain. Finally, we design a three-stage training scheme enabling feature uncertainty modeling to be successfully applied. Experiments on CIFAR-10/100-LT, ImageNet-LT, and iNaturalist2018 show that our proposed approach outperforms other similar methods on most metrics. In addition, the experimental phenomena we discovered are able to provide new perspectives and theoretical foundations for subsequent studies.
A match made in consistency heaven: when large language models meet evolutionary algorithms
Jan 19, 2024Pre-trained large language models (LLMs) have powerful capabilities for generating creative natural text. Evolutionary algorithms (EAs) can discover diverse solutions to complex real-world problems. Motivated by the common collective and directionality of text sequence generation and evolution, this paper illustrates the strong consistency of LLMs and EAs, which includes multiple one-to-one key characteristics: token embedding and genotype-phenotype mapping, position encoding and fitness shaping, position embedding and selection, attention and crossover, feed-forward neural network and mutation, model training and parameter update, and multi-task learning and multi-objective optimization. Based on this consistency perspective, existing coupling studies are analyzed, including evolutionary fine-tuning and LLM-enhanced EAs. Leveraging these insights, we outline a fundamental roadmap for future research in coupling LLMs and EAs, while highlighting key challenges along the way. The consistency not only reveals the evolution mechanism behind LLMs but also facilitates the development of evolved artificial agents that approach or surpass biological organisms.
Transferring Modality-Aware Pedestrian Attentive Learning for Visible-Infrared Person Re-identification
Dec 19, 2023
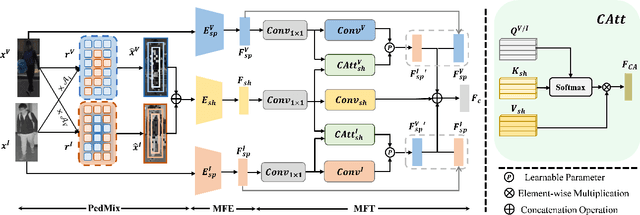


Visible-infrared person re-identification (VI-ReID) aims to search the same pedestrian of interest across visible and infrared modalities. Existing models mainly focus on compensating for modality-specific information to reduce modality variation. However, these methods often lead to a higher computational overhead and may introduce interfering information when generating the corresponding images or features. To address this issue, it is critical to leverage pedestrian-attentive features and learn modality-complete and -consistent representation. In this paper, a novel Transferring Modality-Aware Pedestrian Attentive Learning (TMPA) model is proposed, focusing on the pedestrian regions to efficiently compensate for missing modality-specific features. Specifically, we propose a region-based data augmentation module PedMix to enhance pedestrian region coherence by mixing the corresponding regions from different modalities. A lightweight hybrid compensation module, i.e., the Modality Feature Transfer (MFT), is devised to integrate cross attention and convolution networks to fully explore the discriminative modality-complete features with minimal computational overhead. Extensive experiments conducted on the benchmark SYSU-MM01 and RegDB datasets demonstrated the effectiveness of our proposed TMPA model.
Semantic Connectivity-Driven Pseudo-labeling for Cross-domain Segmentation
Dec 11, 2023



Presently, self-training stands as a prevailing approach in cross-domain semantic segmentation, enhancing model efficacy by training with pixels assigned with reliable pseudo-labels. However, we find two critical limitations in this paradigm. (1) The majority of reliable pixels exhibit a speckle-shaped pattern and are primarily located in the central semantic region. This presents challenges for the model in accurately learning semantics. (2) Category noise in speckle pixels is difficult to locate and correct, leading to error accumulation in self-training. To address these limitations, we propose a novel approach called Semantic Connectivity-driven pseudo-labeling (SeCo). This approach formulates pseudo-labels at the connectivity level and thus can facilitate learning structured and low-noise semantics. Specifically, SeCo comprises two key components: Pixel Semantic Aggregation (PSA) and Semantic Connectivity Correction (SCC). Initially, PSA divides semantics into 'stuff' and 'things' categories and aggregates speckled pseudo-labels into semantic connectivity through efficient interaction with the Segment Anything Model (SAM). This enables us not only to obtain accurate boundaries but also simplifies noise localization. Subsequently, SCC introduces a simple connectivity classification task, which enables locating and correcting connectivity noise with the guidance of loss distribution. Extensive experiments demonstrate that SeCo can be flexibly applied to various cross-domain semantic segmentation tasks, including traditional unsupervised, source-free, and black-box domain adaptation, significantly improving the performance of existing state-of-the-art methods. The code is available at https://github.com/DZhaoXd/SeCo.
Data-Centric Long-Tailed Image Recognition
Nov 03, 2023



In the context of the long-tail scenario, models exhibit a strong demand for high-quality data. Data-centric approaches aim to enhance both the quantity and quality of data to improve model performance. Among these approaches, information augmentation has been progressively introduced as a crucial category. It achieves a balance in model performance by augmenting the richness and quantity of samples in the tail classes. However, there is currently a lack of research into the underlying mechanisms explaining the effectiveness of information augmentation methods. Consequently, the utilization of information augmentation in long-tail recognition tasks relies heavily on empirical and intricate fine-tuning. This work makes two primary contributions. Firstly, we approach the problem from the perspectives of feature diversity and distribution shift, introducing the concept of Feature Diversity Gain (FDG) to elucidate why information augmentation is effective. We find that the performance of information augmentation can be explained by FDG, and its performance peaks when FDG achieves an appropriate balance. Experimental results demonstrate that by using FDG to select augmented data, we can further enhance model performance without the need for any modifications to the model's architecture. Thus, data-centric approaches hold significant potential in the field of long-tail recognition, beyond the development of new model structures. Furthermore, we systematically introduce the core components and fundamental tasks of a data-centric long-tail learning framework for the first time. These core components guide the implementation and deployment of the system, while the corresponding fundamental tasks refine and expand the research area.
Orthogonal Uncertainty Representation of Data Manifold for Robust Long-Tailed Learning
Oct 16, 2023In scenarios with long-tailed distributions, the model's ability to identify tail classes is limited due to the under-representation of tail samples. Class rebalancing, information augmentation, and other techniques have been proposed to facilitate models to learn the potential distribution of tail classes. The disadvantage is that these methods generally pursue models with balanced class accuracy on the data manifold, while ignoring the ability of the model to resist interference. By constructing noisy data manifold, we found that the robustness of models trained on unbalanced data has a long-tail phenomenon. That is, even if the class accuracy is balanced on the data domain, it still has bias on the noisy data manifold. However, existing methods cannot effectively mitigate the above phenomenon, which makes the model vulnerable in long-tailed scenarios. In this work, we propose an Orthogonal Uncertainty Representation (OUR) of feature embedding and an end-to-end training strategy to improve the long-tail phenomenon of model robustness. As a general enhancement tool, OUR has excellent compatibility with other methods and does not require additional data generation, ensuring fast and efficient training. Comprehensive evaluations on long-tailed datasets show that our method significantly improves the long-tail phenomenon of robustness, bringing consistent performance gains to other long-tailed learning methods.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
Changes-Aware Transformer: Learning Generalized Changes Representation
Sep 24, 2023Difference features obtained by comparing the images of two periods play an indispensable role in the change detection (CD) task. However, a pair of bi-temporal images can exhibit diverse changes, which may cause various difference features. Identifying changed pixels with differ difference features to be the same category is thus a challenge for CD. Most nowadays' methods acquire distinctive difference features in implicit ways like enhancing image representation or supervision information. Nevertheless, informative image features only guarantee object semantics are modeled and can not guarantee that changed pixels have similar semantics in the difference feature space and are distinct from those unchanged ones. In this work, the generalized representation of various changes is learned straightforwardly in the difference feature space, and a novel Changes-Aware Transformer (CAT) for refining difference features is proposed. This generalized representation can perceive which pixels are changed and which are unchanged and further guide the update of pixels' difference features. CAT effectively accomplishes this refinement process through the stacked cosine cross-attention layer and self-attention layer. After refinement, the changed pixels in the difference feature space are closer to each other, which facilitates change detection. In addition, CAT is compatible with various backbone networks and existing CD methods. Experiments on remote sensing CD data set and street scene CD data set show that our method achieves state-of-the-art performance and has excellent generalization.
Remote Sensing Object Detection Meets Deep Learning: A Meta-review of Challenges and Advances
Sep 13, 2023



Remote sensing object detection (RSOD), one of the most fundamental and challenging tasks in the remote sensing field, has received longstanding attention. In recent years, deep learning techniques have demonstrated robust feature representation capabilities and led to a big leap in the development of RSOD techniques. In this era of rapid technical evolution, this review aims to present a comprehensive review of the recent achievements in deep learning based RSOD methods. More than 300 papers are covered in this review. We identify five main challenges in RSOD, including multi-scale object detection, rotated object detection, weak object detection, tiny object detection, and object detection with limited supervision, and systematically review the corresponding methods developed in a hierarchical division manner. We also review the widely used benchmark datasets and evaluation metrics within the field of RSOD, as well as the application scenarios for RSOD. Future research directions are provided for further promoting the research in RSOD.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.