 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaTranS: Adapting with Boundary-based Shrinking for End-to-End Speech Translation
Dec 17, 2022To alleviate the data scarcity problem in End-to-end speech translation (ST), pre-training on data for speech recognition and machine translation is considered as an important technique. However, the modality gap between speech and text prevents the ST model from efficiently inheriting knowledge from the pre-trained models. In this work, we propose AdaTranS for end-to-end ST. It adapts the speech features with a new shrinking mechanism to mitigate the length mismatch between speech and text features by predicting word boundaries. Experiments on the MUST-C dataset demonstrate that AdaTranS achieves better performance than the other shrinking-based methods, with higher inference speed and lower memory usage. Further experiments also show that AdaTranS can be equipped with additional alignment losses to further improve performance.
SongRewriter: A Chinese Song Rewriting System with Controllable Content and Rhyme Scheme
Nov 28, 2022



Although lyrics generation has achieved significant progress in recent years, it has limited practical applications because the generated lyrics cannot be performed without composing compatible melodies. In this work, we bridge this practical gap by proposing a song rewriting system which rewrites the lyrics of an existing song such that the generated lyrics are compatible with the rhythm of the existing melody and thus singable. In particular, we propose SongRewriter, a controllable Chinese lyric generation and editing system which assists users without prior knowledge of melody composition. The system is trained by a randomized multi-level masking strategy which produces a unified model for generating entirely new lyrics or editing a few fragments. To improve the controllabiliy of the generation process, we further incorporate a keyword prompt to control the lexical choices of the content and propose novel decoding constraints and a vowel modeling task to enable flexible end and internal rhyme schemes. While prior rhyming metrics are mainly for rap lyrics, we propose three novel rhyming evaluation metrics for song lyrics. Both automatic and human evaluations show that the proposed model performs better than the state-of-the-art models in both contents and rhyming quality. Our code and models implemented in MindSpore Lite tool will be available.
FreeTransfer-X: Safe and Label-Free Cross-Lingual Transfer from Off-the-Shelf Models
Jun 14, 2022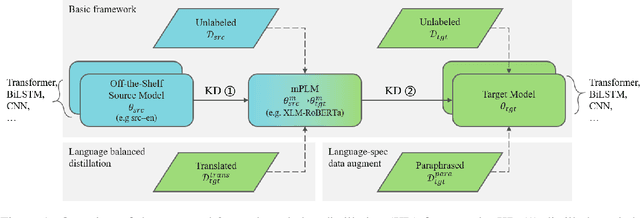
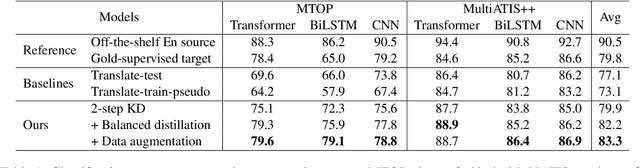
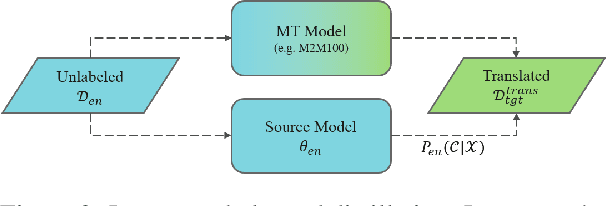
Cross-lingual transfer (CLT) is of various applications. However, labeled cross-lingual corpus is expensive or even inaccessible, especially in the fields where labels are private, such as diagnostic results of symptoms in medicine and user profiles in business. Nevertheless, there are off-the-shelf models in these sensitive fields. Instead of pursuing the original labels, a workaround for CLT is to transfer knowledge from the off-the-shelf models without labels. To this end, we define a novel CLT problem named FreeTransfer-X that aims to achieve knowledge transfer from the off-the-shelf models in rich-resource languages. To address the problem, we propose a 2-step knowledge distillation (KD, Hinton et al., 2015) framework based on multilingual pre-trained language models (mPLM). The significant improvement over strong neural machine translation (NMT) baselines demonstrates the effectiveness of the proposed method. In addition to reducing annotation cost and protecting private labels, the proposed method is compatible with different networks and easy to be deployed. Finally, a range of analyses indicate the great potential of the proposed method.
Universal Conditional Masked Language Pre-training for Neural Machine Translation
Mar 20, 2022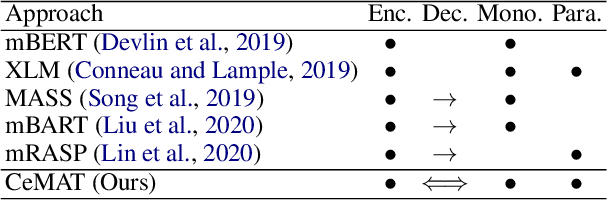
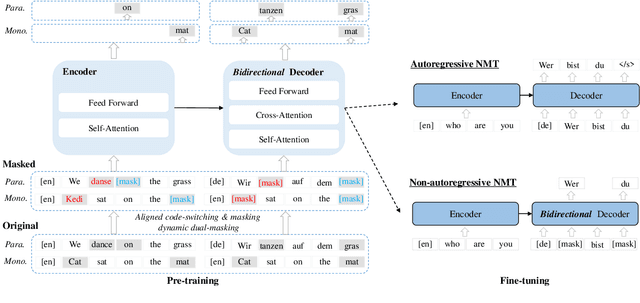
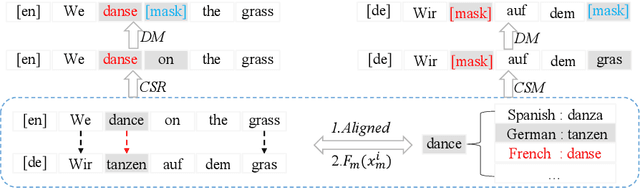
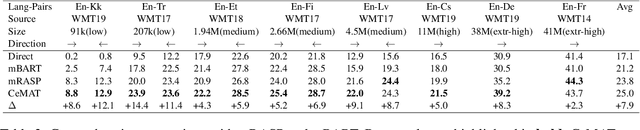
Pre-trained sequence-to-sequence models have significantly improved Neural Machine Translation (NMT). Different from prior works where pre-trained models usually adopt an unidirectional decoder, this paper demonstrates that pre-training a sequence-to-sequence model but with a bidirectional decoder can produce notable performance gains for both Autoregressive and Non-autoregressive NMT. Specifically, we propose CeMAT, a conditional masked language model pre-trained on large-scale bilingual and monolingual corpora in many languages. We also introduce two simple but effective methods to enhance the CeMAT, aligned code-switching & masking and dynamic dual-masking. We conduct extensive experiments and show that our CeMAT can achieve significant performance improvement for all scenarios from low- to extremely high-resource languages, i.e., up to +14.4 BLEU on low resource and +7.9 BLEU improvements on average for Autoregressive NMT. For Non-autoregressive NMT, we demonstrate it can also produce consistent performance gains, i.e., up to +5.3 BLEU. To the best of our knowledge, this is the first work to pre-train a unified model for fine-tuning on both NMT tasks. Code, data, and pre-trained models are available at https://github.com/huawei-noah/Pretrained-Language-Model/CeMAT
Triangular Transfer: Freezing the Pivot for Triangular Machine Translation
Mar 17, 2022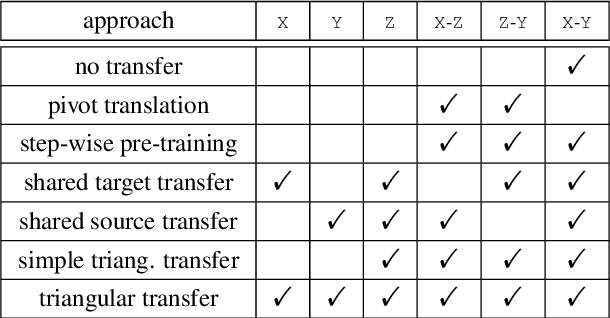
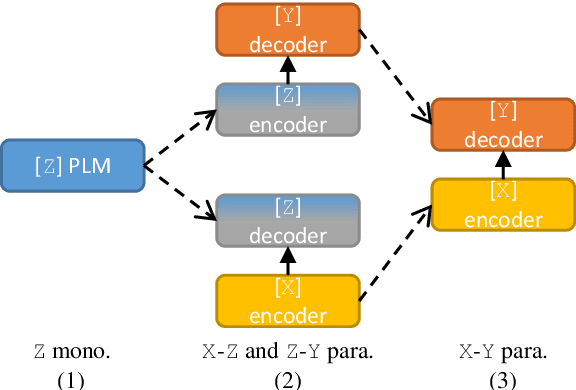
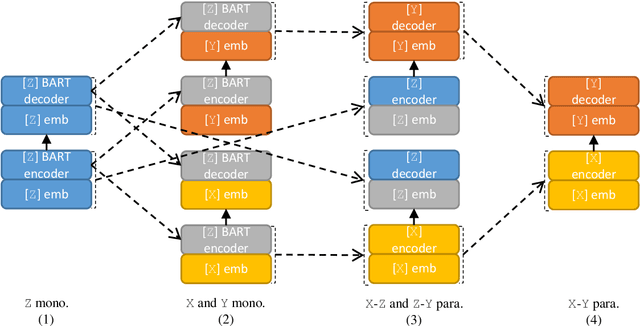
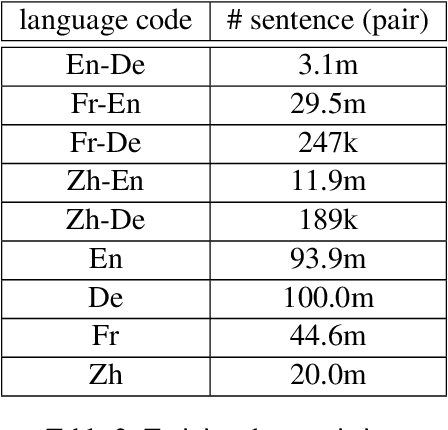
Triangular machine translation is a special case of low-resource machine translation where the language pair of interest has limited parallel data, but both languages have abundant parallel data with a pivot language. Naturally, the key to triangular machine translation is the successful exploitation of such auxiliary data. In this work, we propose a transfer-learning-based approach that utilizes all types of auxiliary data. As we train auxiliary source-pivot and pivot-target translation models, we initialize some parameters of the pivot side with a pre-trained language model and freeze them to encourage both translation models to work in the same pivot language space, so that they can be smoothly transferred to the source-target translation model. Experiments show that our approach can outperform previous ones.
Adversarial Parameter Defense by Multi-Step Risk Minimization
Sep 07, 2021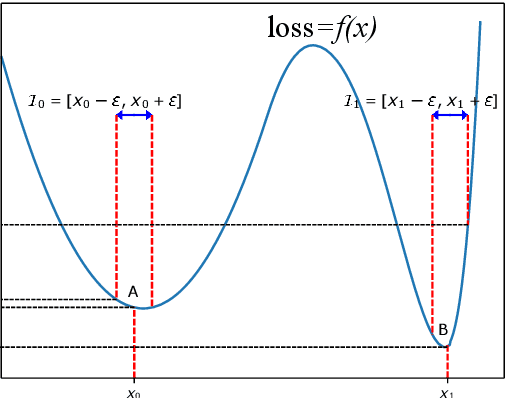

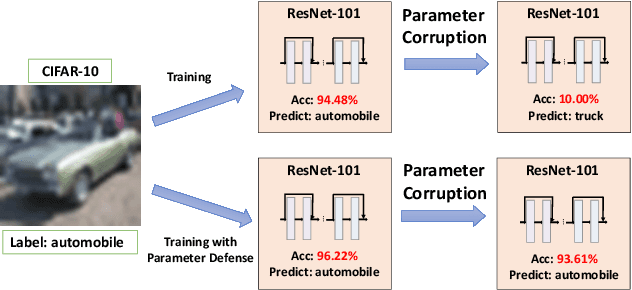
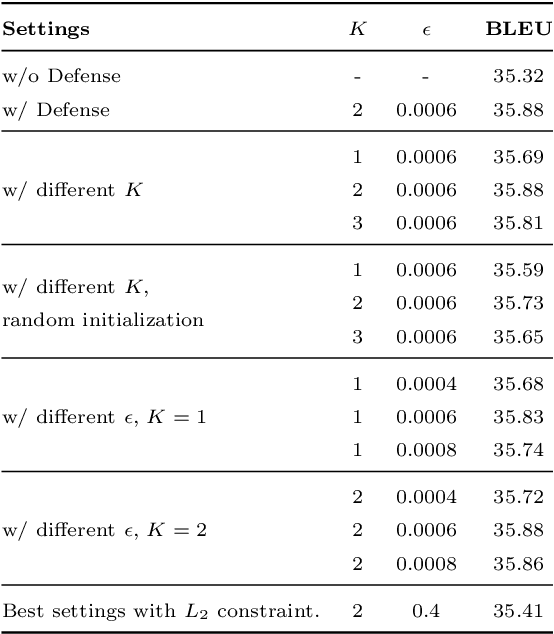
Previous studies demonstrate DNNs' vulnerability to adversarial examples and adversarial training can establish a defense to adversarial examples. In addition, recent studies show that deep neural networks also exhibit vulnerability to parameter corruptions. The vulnerability of model parameters is of crucial value to the study of model robustness and generalization. In this work, we introduce the concept of parameter corruption and propose to leverage the loss change indicators for measuring the flatness of the loss basin and the parameter robustness of neural network parameters. On such basis, we analyze parameter corruptions and propose the multi-step adversarial corruption algorithm. To enhance neural networks, we propose the adversarial parameter defense algorithm that minimizes the average risk of multiple adversarial parameter corruptions. Experimental results show that the proposed algorithm can improve both the parameter robustness and accuracy of neural networks.
* Accepted to Neural Networks. arXiv admin note: text overlap with arXiv:2006.05620
Uncertainty-Aware Balancing for Multilingual and Multi-Domain Neural Machine Translation Training
Sep 06, 2021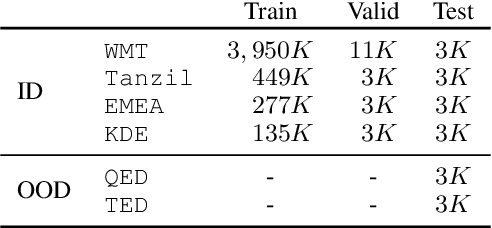
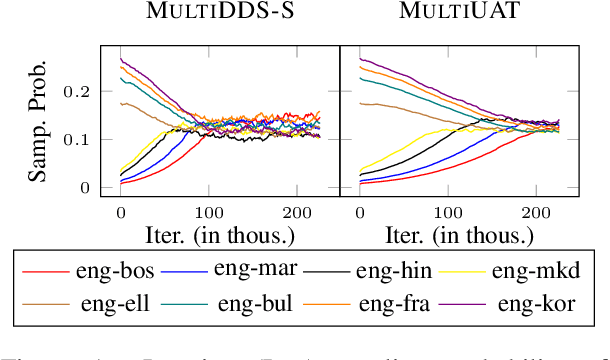
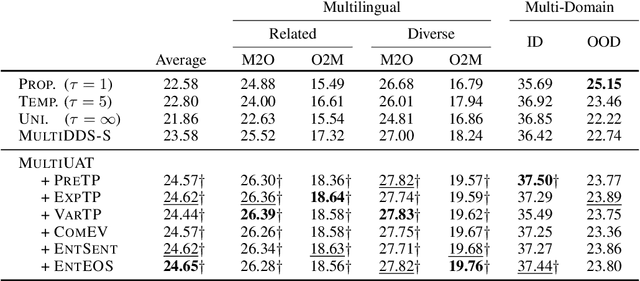
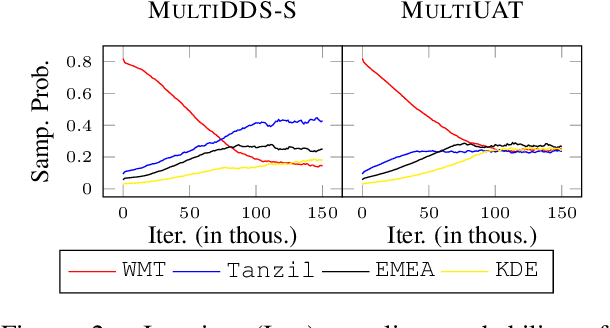
Learning multilingual and multi-domain translation model is challenging as the heterogeneous and imbalanced data make the model converge inconsistently over different corpora in real world. One common practice is to adjust the share of each corpus in the training, so that the learning process is balanced and low-resource cases can benefit from the high resource ones. However, automatic balancing methods usually depend on the intra- and inter-dataset characteristics, which is usually agnostic or requires human priors. In this work, we propose an approach, MultiUAT, that dynamically adjusts the training data usage based on the model's uncertainty on a small set of trusted clean data for multi-corpus machine translation. We experiments with two classes of uncertainty measures on multilingual (16 languages with 4 settings) and multi-domain settings (4 for in-domain and 2 for out-of-domain on English-German translation) and demonstrate our approach MultiUAT substantially outperforms its baselines, including both static and dynamic strategies. We analyze the cross-domain transfer and show the deficiency of static and similarity based methods.
The HW-TSC's Offline Speech Translation Systems for IWSLT 2021 Evaluation
Aug 09, 2021
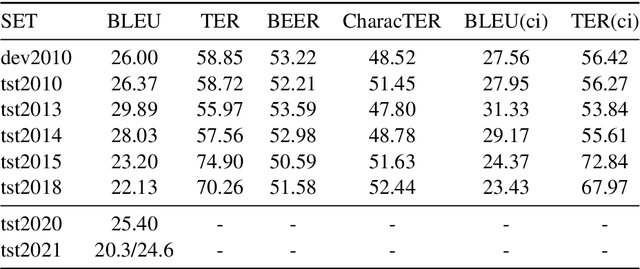
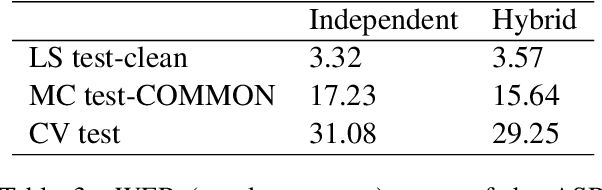
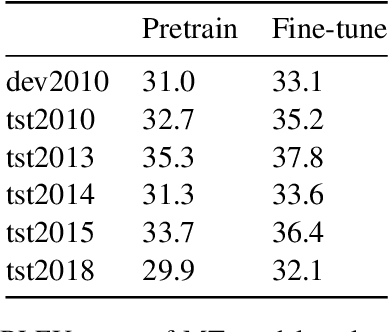
This paper describes our work in participation of the IWSLT-2021 offline speech translation task. Our system was built in a cascade form, including a speaker diarization module, an Automatic Speech Recognition (ASR) module and a Machine Translation (MT) module. We directly use the LIUM SpkDiarization tool as the diarization module. The ASR module is trained with three ASR datasets from different sources, by multi-source training, using a modified Transformer encoder. The MT module is pretrained on the large-scale WMT news translation dataset and fine-tuned on the TED corpus. Our method achieves 24.6 BLEU score on the 2021 test set.
Multilingual Speech Translation with Unified Transformer: Huawei Noah's Ark Lab at IWSLT 2021
Jun 22, 2021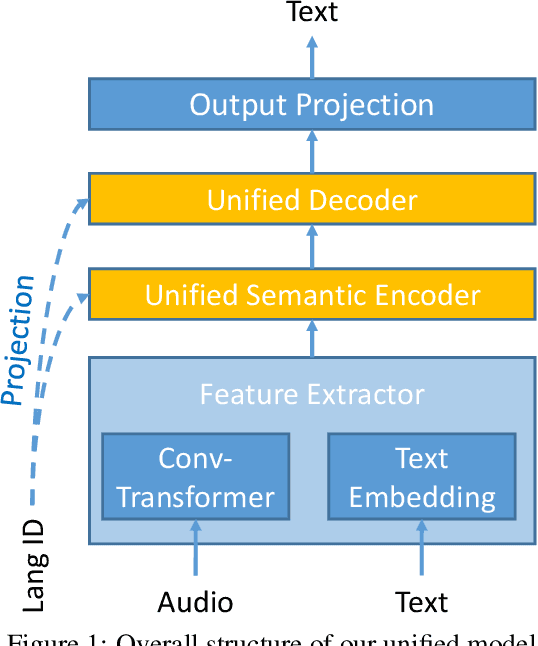
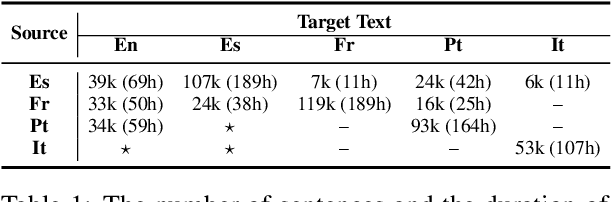
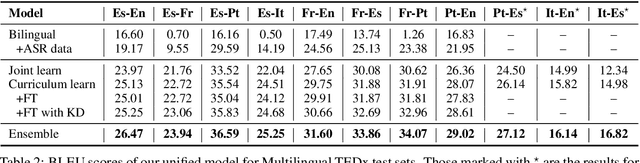
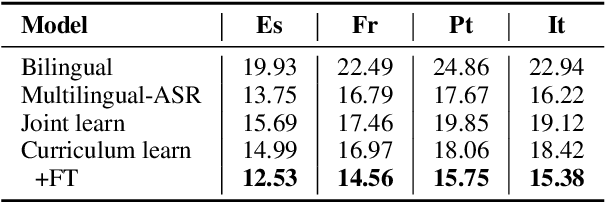
This paper describes the system submitted to the IWSLT 2021 Multilingual Speech Translation (MultiST) task from Huawei Noah's Ark Lab. We use a unified transformer architecture for our MultiST model, so that the data from different modalities (i.e., speech and text) and different tasks (i.e., Speech Recognition, Machine Translation, and Speech Translation) can be exploited to enhance the model's ability. Specifically, speech and text inputs are firstly fed to different feature extractors to extract acoustic and textual features, respectively. Then, these features are processed by a shared encoder--decoder architecture. We apply several training techniques to improve the performance, including multi-task learning, task-level curriculum learning, data augmentation, etc. Our final system achieves significantly better results than bilingual baselines on supervised language pairs and yields reasonable results on zero-shot language pairs.
Learning Multilingual Representation for Natural Language Understanding with Enhanced Cross-Lingual Supervision
Jun 09, 2021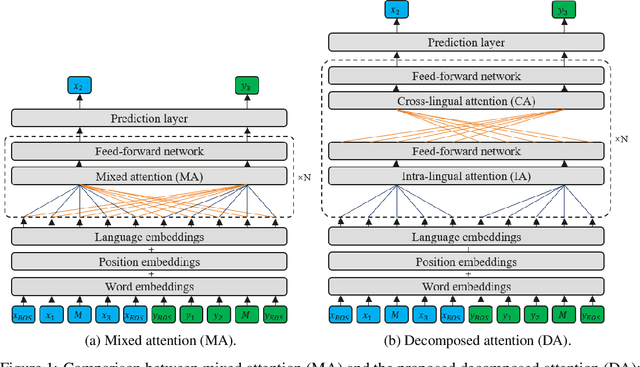

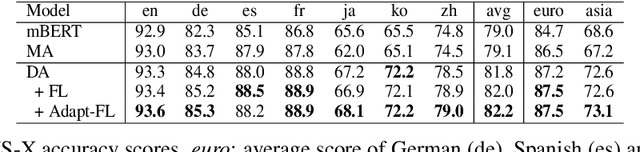
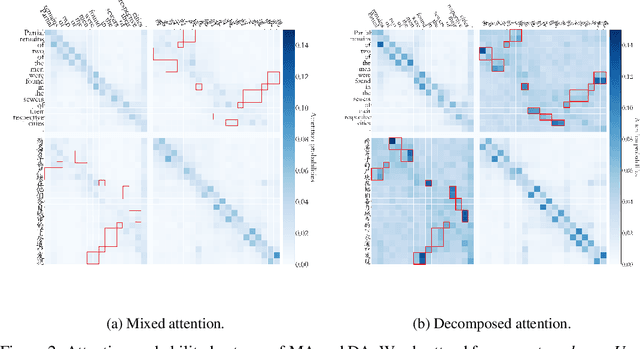
Recently, pre-training multilingual language models has shown great potential in learning multilingual representation, a crucial topic of natural language processing. Prior works generally use a single mixed attention (MA) module, following TLM (Conneau and Lample, 2019), for attending to intra-lingual and cross-lingual contexts equivalently and simultaneously. In this paper, we propose a network named decomposed attention (DA) as a replacement of MA. The DA consists of an intra-lingual attention (IA) and a cross-lingual attention (CA), which model intralingual and cross-lingual supervisions respectively. In addition, we introduce a language-adaptive re-weighting strategy during training to further boost the model's performance. Experiments on various cross-lingual natural language understanding (NLU) tasks show that the proposed architecture and learning strategy significantly improve the model's cross-lingual transferability.