 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDet: Dual-path Dynamic Enhancement Network for Real-World Image Super-Resolution
Feb 25, 2020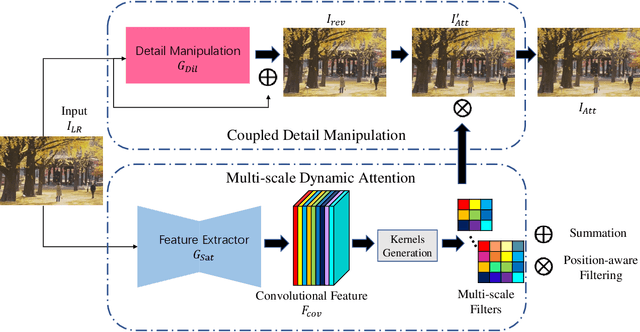
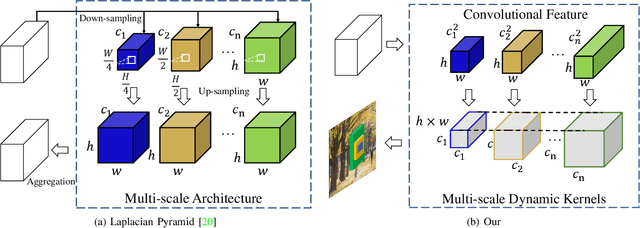

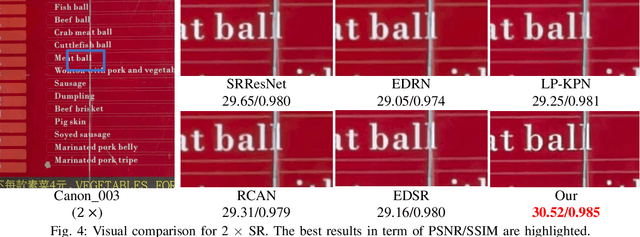
Different from traditional image super-resolution task, real image super-resolution(Real-SR) focus on the relationship between real-world high-resolution(HR) and low-resolution(LR) image. Most of the traditional image SR obtains the LR sample by applying a fixed down-sampling operator. Real-SR obtains the LR and HR image pair by incorporating different quality optical sensors. Generally, Real-SR has more challenges as well as broader application scenarios. Previous image SR methods fail to exhibit similar performance on Real-SR as the image data is not aligned inherently. In this article, we propose a Dual-path Dynamic Enhancement Network(DDet) for Real-SR, which addresses the cross-camera image mapping by realizing a dual-way dynamic sub-pixel weighted aggregation and refinement. Unlike conventional methods which stack up massive convolutional blocks for feature representation, we introduce a content-aware framework to study non-inherently aligned image pair in image SR issue. First, we use a content-adaptive component to exhibit the Multi-scale Dynamic Attention(MDA). Second, we incorporate a long-term skip connection with a Coupled Detail Manipulation(CDM) to perform collaborative compensation and manipulation. The above dual-path model is joint into a unified model and works collaboratively. Extensive experiments on the challenging benchmarks demonstrate the superiority of our model.
Depthwise Non-local Module for Fast Salient Object Detection Using a Single Thread
Jan 22, 2020
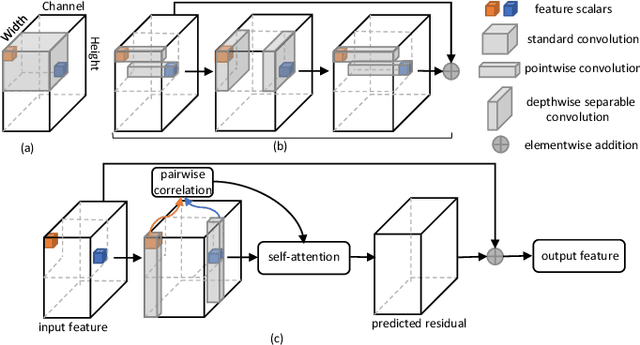
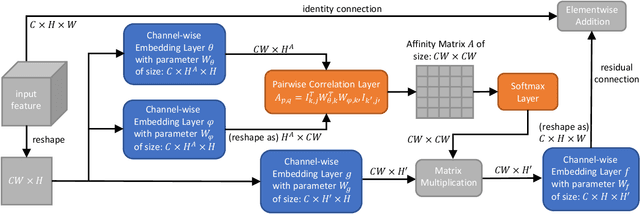
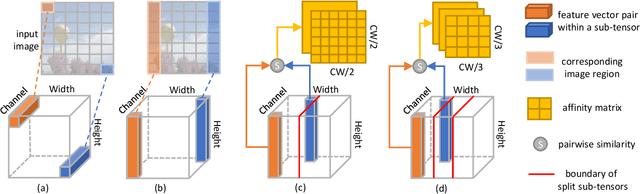
Recently deep convolutional neural networks have achieved significant success in salient object detection. However, existing state-of-the-art methods require high-end GPUs to achieve real-time performance, which makes them hard to adapt to low-cost or portable devices. Although generic network architectures have been proposed to speed up inference on mobile devices, they are tailored to the task of image classification or semantic segmentation, and struggle to capture intra-channel and inter-channel correlations that are essential for contrast modeling in salient object detection. Motivated by the above observations, we design a new deep learning algorithm for fast salient object detection. The proposed algorithm for the first time achieves competitive accuracy and high inference efficiency simultaneously with a single CPU thread. Specifically, we propose a novel depthwise non-local moudule (DNL), which implicitly models contrast via harvesting intra-channel and inter-channel correlations in a self-attention manner. In addition, we introduce a depthwise non-local network architecture that incorporates both depthwise non-local modules and inverted residual blocks. Experimental results show that our proposed network attains very competitive accuracy on a wide range of salient object detection datasets while achieving state-of-the-art efficiency among all existing deep learning based algorithms.
Tree-Structured Policy based Progressive Reinforcement Learning for Temporally Language Grounding in Video
Jan 18, 2020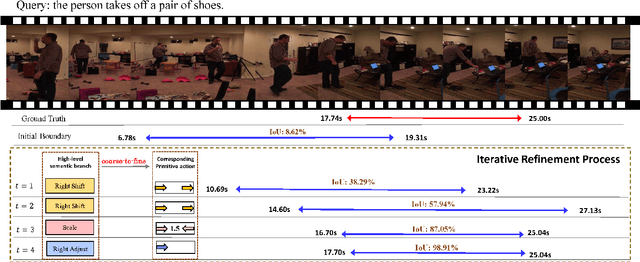
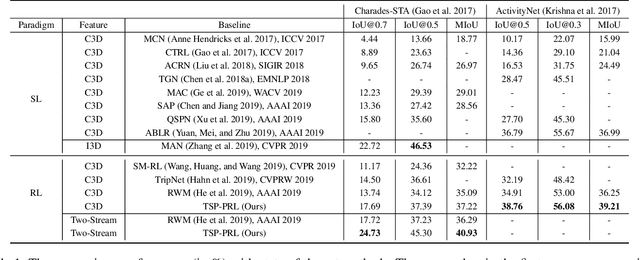
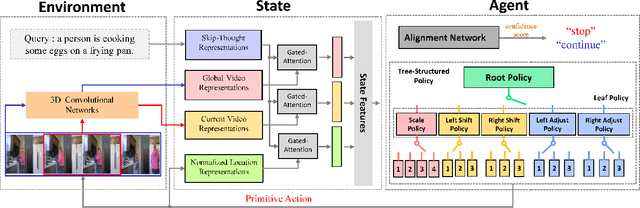
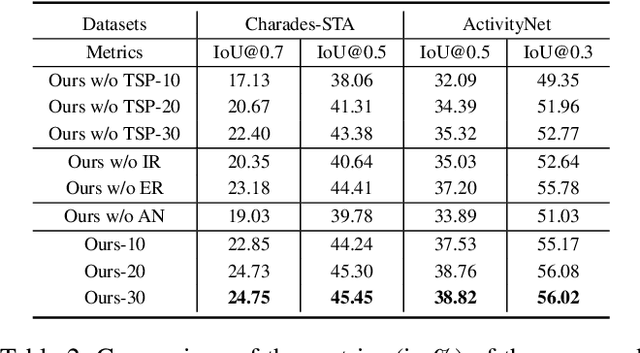
Temporally language grounding in untrimmed videos is a newly-raised task in video understanding. Most of the existing methods suffer from inferior efficiency, lacking interpretability, and deviating from the human perception mechanism. Inspired by human's coarse-to-fine decision-making paradigm, we formulate a novel Tree-Structured Policy based Progressive Reinforcement Learning (TSP-PRL) framework to sequentially regulate the temporal boundary by an iterative refinement process. The semantic concepts are explicitly represented as the branches in the policy, which contributes to efficiently decomposing complex policies into an interpretable primitive action. Progressive reinforcement learning provides correct credit assignment via two task-oriented rewards that encourage mutual promotion within the tree-structured policy. We extensively evaluate TSP-PRL on the Charades-STA and ActivityNet datasets, and experimental results show that TSP-PRL achieves competitive performance over existing state-of-the-art methods.
Physical-Virtual Collaboration Graph Network for Station-Level Metro Ridership Prediction
Jan 14, 2020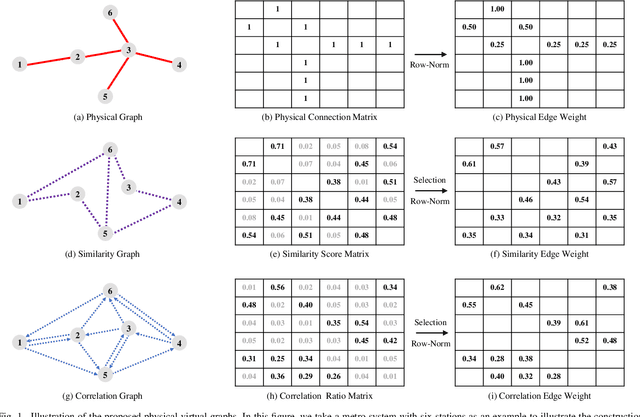
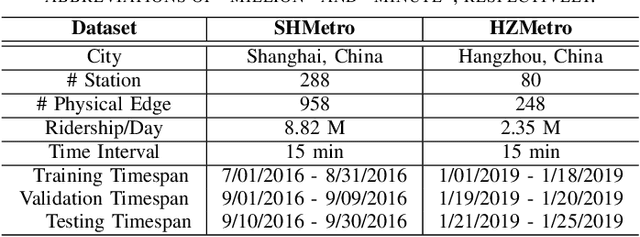
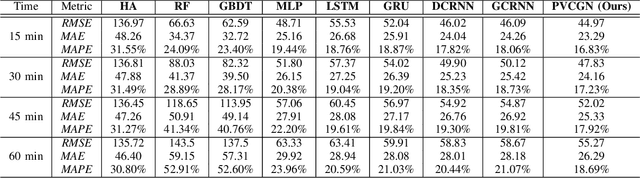
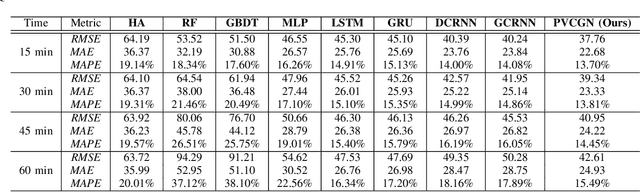
Due to the widespread applications in real-world scenarios, metro ridership prediction is a crucial but challenging task in intelligent transportation systems. However, conventional methods that either ignored the topological information of metro systems or directly learned on physical topology, can not fully explore the ridership evolution patterns. To address this problem, we model a metro system as graphs with various topologies and propose a unified Physical-Virtual Collaboration Graph Network (PVCGN), which can effectively learn the complex ridership patterns from the tailor-designed graphs. Specifically, a physical graph is directly built based on the realistic topology of the studied metro system, while a similarity graph and a correlation graph are built with virtual topologies under the guidance of the inter-station passenger flow similarity and correlation. These complementary graphs are incorporated into a Graph Convolution Gated Recurrent Unit (GC-GRU) for spatial-temporal representation learning. Further, a Fully-Connected Gated Recurrent Unit (FC-GRU) is also applied to capture the global evolution tendency. Finally, we develop a seq2seq model with GC-GRU and FC-GRU to forecast the future metro ridership sequentially. Extensive experiments on two large-scale benchmarks (e.g., Shanghai Metro and Hangzhou Metro) well demonstrate the superiority of the proposed PVCGN for station-level metro ridership prediction.
An Adversarial Perturbation Oriented Domain Adaptation Approach for Semantic Segmentation
Dec 18, 2019
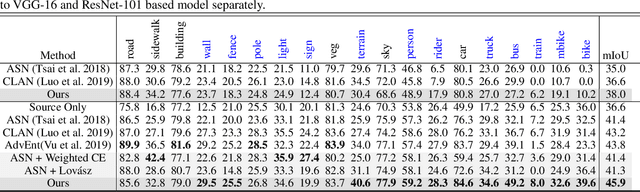
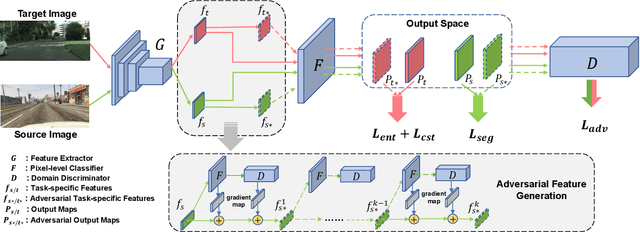
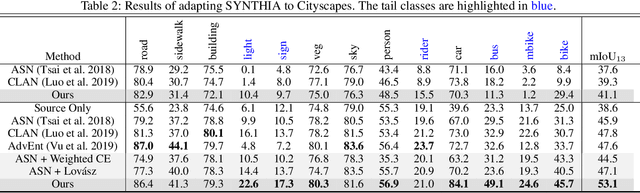
We focus on Unsupervised Domain Adaptation (UDA) for the task of semantic segmentation. Recently, adversarial alignment has been widely adopted to match the marginal distribution of feature representations across two domains globally. However, this strategy fails in adapting the representations of the tail classes or small objects for semantic segmentation since the alignment objective is dominated by head categories or large objects. In contrast to adversarial alignment, we propose to explicitly train a domain-invariant classifier by generating and defensing against pointwise feature space adversarial perturbations. Specifically, we firstly perturb the intermediate feature maps with several attack objectives (i.e., discriminator and classifier) on each individual position for both domains, and then the classifier is trained to be invariant to the perturbations. By perturbing each position individually, our model treats each location evenly regardless of the category or object size and thus circumvents the aforementioned issue. Moreover, the domain gap in feature space is reduced by extrapolating source and target perturbed features towards each other with attack on the domain discriminator. Our approach achieves the state-of-the-art performance on two challenging domain adaptation tasks for semantic segmentation: GTA5 -> Cityscapes and SYNTHIA -> Cityscapes.
Blockwisely Supervised Neural Architecture Search with Knowledge Distillation
Nov 29, 2019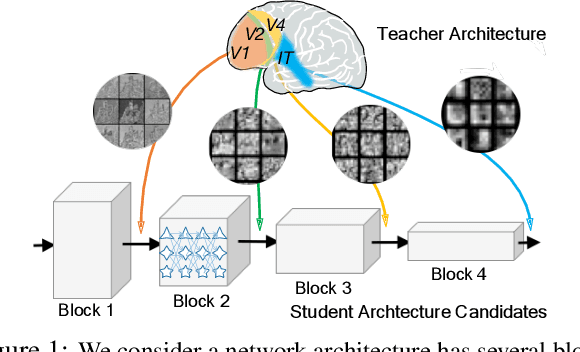
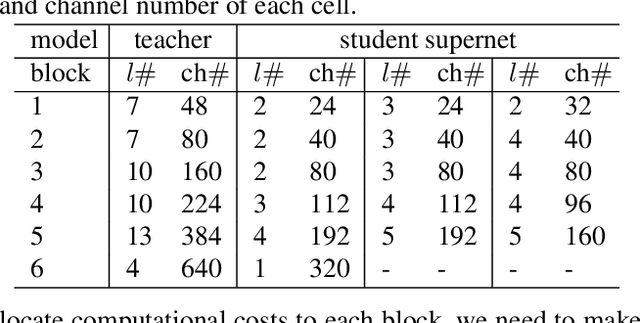
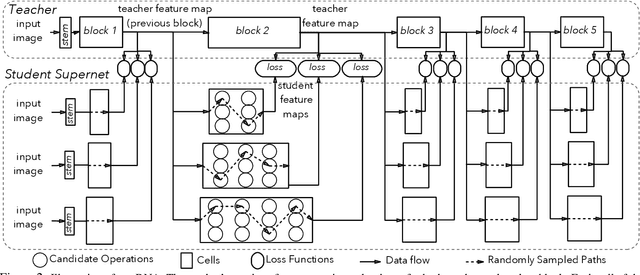
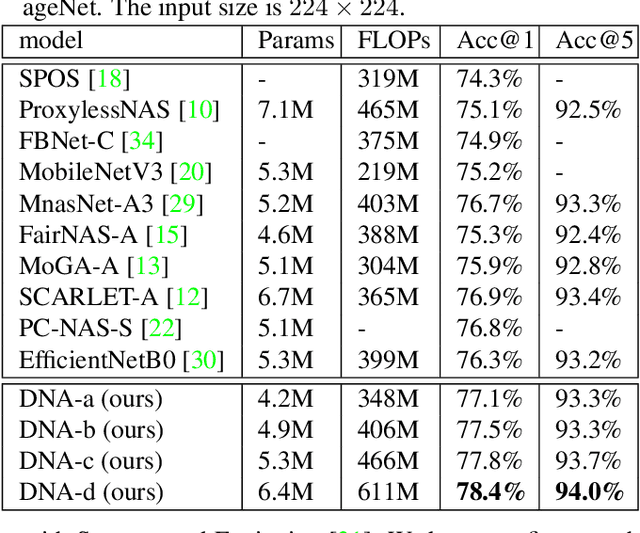
Neural Architecture Search (NAS), aiming at automatically designing network architectures by machines, is hoped and expected to bring about a new revolution in machine learning. Despite these high expectation, the effectiveness and efficiency of existing NAS solutions are unclear, with some recent works going so far as to suggest that many existing NAS solutions are no better than random architecture selection. The inefficiency of NAS solutions may be attributed to inaccurate architecture evaluation. Specifically, to speed up NAS, recent works have proposed under-training different candidate architectures in a large search space concurrently by using shared network parameters; however, this has resulted in incorrect architecture ratings and furthered the ineffectiveness of NAS. In this work, we propose to modularize the large search space of NAS into blocks to ensure that the potential candidate architectures are fully trained; this reduces the representation shift caused by the shared parameters and leads to the correct rating of the candidates. Thanks to the block-wise search, we can also evaluate all of the candidate architectures within a block. Moreover, we find that the knowledge of a network model lies not only in the network parameters but also in the network architecture. Therefore, we propose to distill the neural architecture (DNA) knowledge from a teacher model as the supervision to guide our block-wise architecture search, which significantly improves the effectiveness of NAS. Remarkably, the capacity of our searched architecture has exceeded the teacher model, demonstrating the practicability and scalability of our method. Finally, our method achieves a state-of-the-art 78.4\% top-1 accuracy on ImageNet in a mobile setting, which is about a 2.1\% gain over EfficientNet-B0. All of our searched models along with the evaluation code are available online.
Knowledge Graph Transfer Network for Few-Shot Recognition
Nov 21, 2019
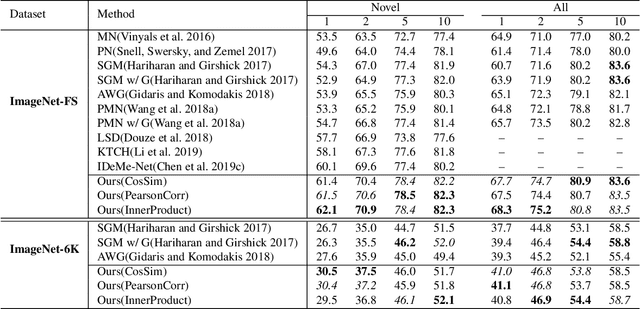
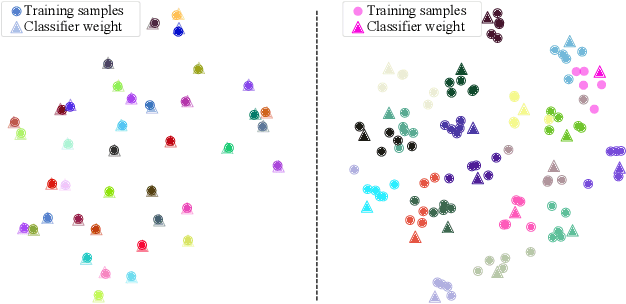
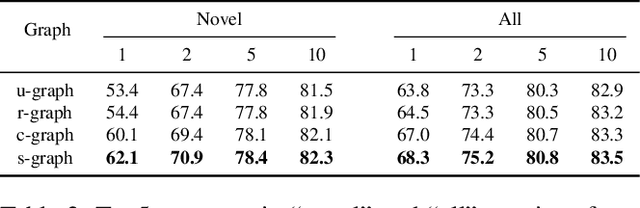
Few-shot learning aims to learn novel categories from very few samples given some base categories with sufficient training samples. The main challenge of this task is the novel categories are prone to dominated by color, texture, shape of the object or background context (namely specificity), which are distinct for the given few training samples but not common for the corresponding categories (see Figure 1). Fortunately, we find that transferring information of the correlated based categories can help learn the novel concepts and thus avoid the novel concept being dominated by the specificity. Besides, incorporating semantic correlations among different categories can effectively regularize this information transfer. In this work, we represent the semantic correlations in the form of structured knowledge graph and integrate this graph into deep neural networks to promote few-shot learning by a novel Knowledge Graph Transfer Network (KGTN). Specifically, by initializing each node with the classifier weight of the corresponding category, a propagation mechanism is learned to adaptively propagate node message through the graph to explore node interaction and transfer classifier information of the base categories to those of the novel ones. Extensive experiments on the ImageNet dataset show significant performance improvement compared with current leading competitors. Furthermore, we construct an ImageNet-6K dataset that covers larger scale categories, i.e, 6,000 categories, and experiments on this dataset further demonstrate the effectiveness of our proposed model.
Generalizing Energy-based Generative ConvNets from Particle Evolution Perspective
Oct 31, 2019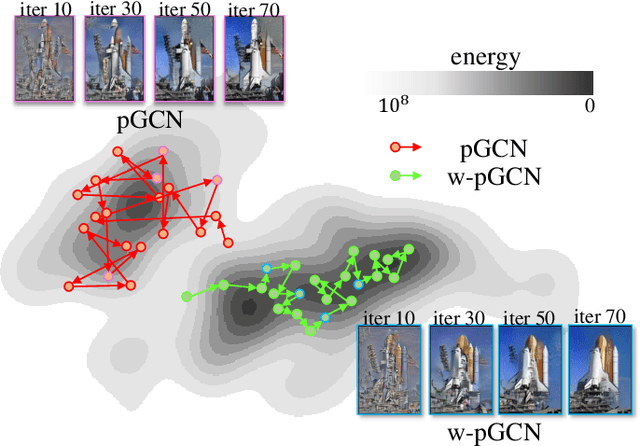
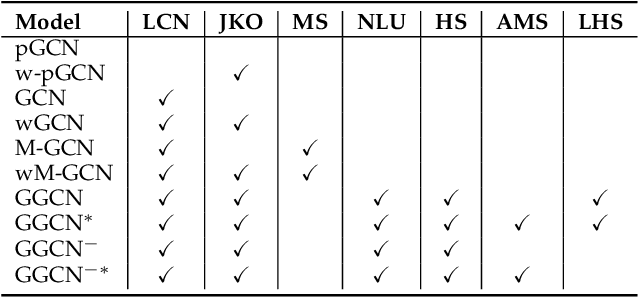
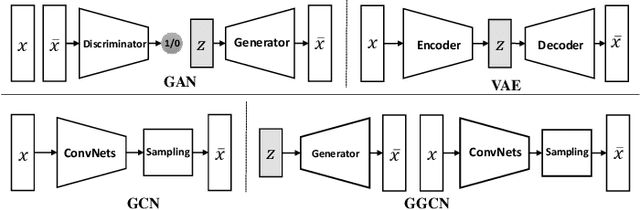
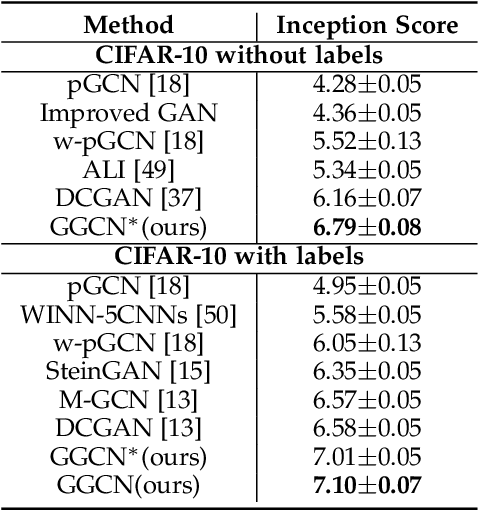
Compared with Generative Adversarial Networks (GAN), the Energy-Based generative Model (EBM) possesses two appealing properties: i) it can be directly optimized without requiring an auxiliary network during the learning and synthesizing; ii) it can better approximate underlying distribution of the observed data by learning explicitly potential functions. This paper studies a branch of EBMs, i.e., the energy-based Generative ConvNet (GCN), which minimizes its energy function defined by a bottom-up ConvNet. From the perspective of particle physics, we solve the problem of unstable energy dissipation that might damage the quality of the synthesized samples during the maximum likelihood learning. Specifically, we establish a connection between FRAME model [1] and dynamic physics process and provide a generalized formulation of FRAME in discrete flow with a certain metric measure from particle perspective. To address KL-vanishing issue, we generalize the reformulated GCN from the KL discrete flow with KL divergence measure to a Jordan-Kinderleher-Otto (JKO) discrete flow with Wasserastein distance metric and derive a Wasserastein GCN (w-GCN). To further minimize the learning bias and improve the model generalization, we present a Generalized GCN (GGCN). GGCN introduces a hidden space mapping strategy and employs a normal distribution as hidden space for the reference distribution. Besides, it applies a matching trainable non-linear upsampling function for further generalization. Considering the limitation of the efficiency problem in MCMC based learning of EBMs, an amortized learning are also proposed to improve the learning efficiency. Quantitative and qualitative experiments are conducted on several widely-used face and natural image datasets. Our experimental results surpass those of the existing models in both model stability and the quality of generated samples.
Layout-Graph Reasoning for Fashion Landmark Detection
Oct 04, 2019
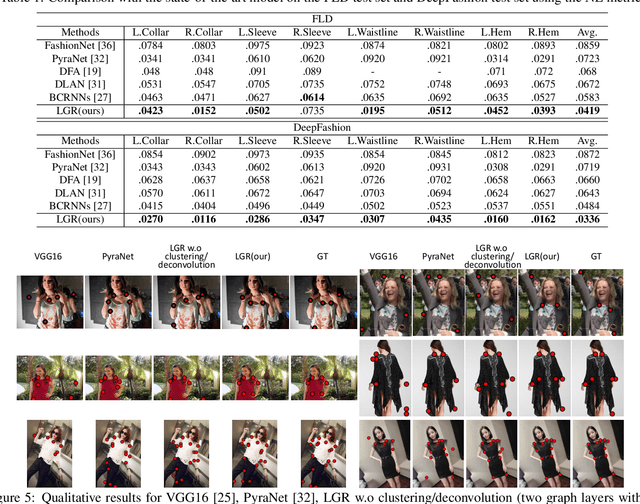

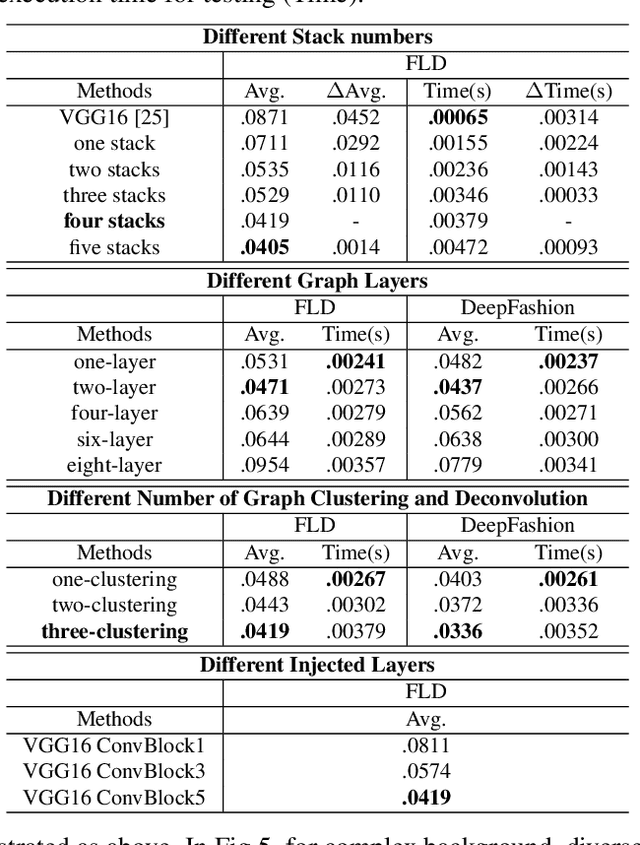
Detecting dense landmarks for diverse clothes, as a fundamental technique for clothes analysis, has attracted increasing research attention due to its huge application potential. However, due to the lack of modeling underlying semantic layout constraints among landmarks, prior works often detect ambiguous and structure-inconsistent landmarks of multiple overlapped clothes in one person. In this paper, we propose to seamlessly enforce structural layout relationships among landmarks on the intermediate representations via multiple stacked layout-graph reasoning layers. We define the layout-graph as a hierarchical structure including a root node, body-part nodes (e.g. upper body, lower body), coarse clothes-part nodes (e.g. collar, sleeve) and leaf landmark nodes (e.g. left-collar, right-collar). Each Layout-Graph Reasoning(LGR) layer aims to map feature representations into structural graph nodes via a Map-to-Node module, performs reasoning over structural graph nodes to achieve global layout coherency via a layout-graph reasoning module, and then maps graph nodes back to enhance feature representations via a Node-to-Map module. The layout-graph reasoning module integrates a graph clustering operation to generate representations of intermediate nodes (bottom-up inference) and then a graph deconvolution operation (top-down inference) over the whole graph. Extensive experiments on two public fashion landmark datasets demonstrate the superiority of our model. Furthermore, to advance the fine-grained fashion landmark research for supporting more comprehensive clothes generation and attribute recognition, we contribute the first Fine-grained Fashion Landmark Dataset (FFLD) containing 200k images annotated with at most 32 key-points for 13 clothes types.
Meta R-CNN : Towards General Solver for Instance-level Low-shot Learning
Sep 28, 2019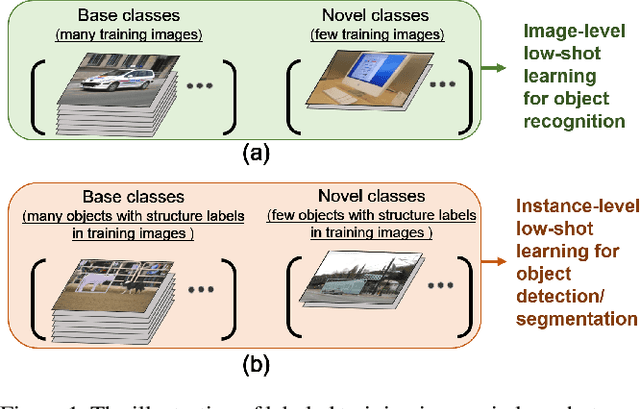
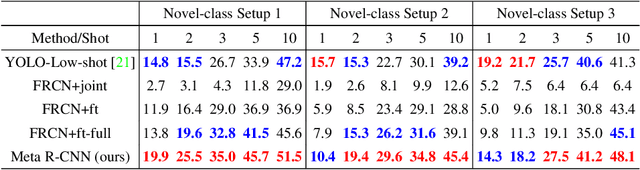
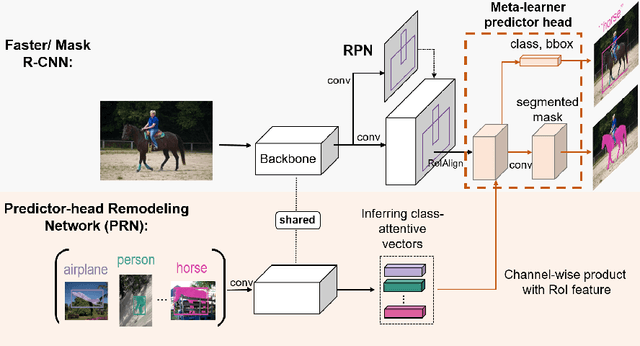
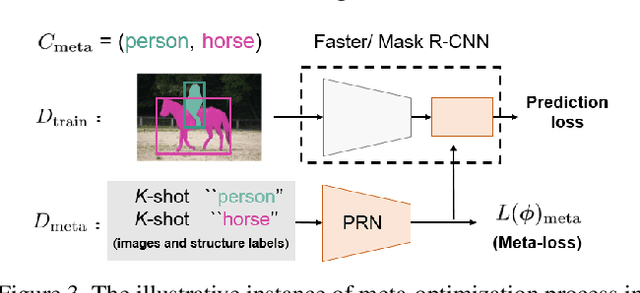
Resembling the rapid learning capability of human, low-shot learning empowers vision systems to understand new concepts by training with few samples. Leading approaches derived from meta-learning on images with a single visual object. Obfuscated by a complex background and multiple objects in one image, they are hard to promote the research of low-shot object detection/segmentation. In this work, we present a flexible and general methodology to achieve these tasks. Our work extends Faster /Mask R-CNN by proposing meta-learning over RoI (Region-of-Interest) features instead of a full image feature. This simple spirit disentangles multi-object information merged with the background, without bells and whistles, enabling Faster /Mask R-CNN turn into a meta-learner to achieve the tasks. Specifically, we introduce a Predictor-head Remodeling Network (PRN) that shares its main backbone with Faster /Mask R-CNN. PRN receives images containing low-shot objects with their bounding boxes or masks to infer their class attentive vectors. The vectors take channel-wise soft-attention on RoI features, remodeling those R-CNN predictor heads to detect or segment the objects that are consistent with the classes these vectors represent. In our experiments, Meta R-CNN yields the state of the art in low-shot object detection and improves low-shot object segmentation by Mask R-CNN.