 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsFT: Anchoring Safety During LLM Fine-Tuning Within Narrow Safety Basin
Jun 11, 2025



Large language models (LLMs) are vulnerable to safety risks during fine-tuning, where small amounts of malicious or harmless data can compromise safeguards. In this paper, building on the concept of alignment direction -- defined by the weight difference between aligned and unaligned models -- we observe that perturbations along this direction preserve model safety. In contrast, perturbations along directions orthogonal to this alignment are strongly linked to harmful direction perturbations, rapidly degrading safety and framing the parameter space as a narrow safety basin. Based on this insight, we propose a methodology for safety fine-tuning called AsFT (Anchoring Safety in Fine-Tuning), which integrates a regularization term into the training objective. This term uses the alignment direction as an anchor to suppress updates in harmful directions, ensuring that fine-tuning is constrained within the narrow safety basin. Extensive experiments on multiple datasets show that AsFT outperforms Safe LoRA, reducing harmful behavior by 7.60 percent, improving model performance by 3.44 percent, and maintaining robust performance across various experimental settings. Code is available at https://github.com/PKU-YuanGroup/AsFT
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
LeanPO: Lean Preference Optimization for Likelihood Alignment in Video-LLMs
Jun 05, 2025Most Video Large Language Models (Video-LLMs) adopt preference alignment techniques, e.g., DPO~\citep{rafailov2024dpo}, to optimize the reward margin between a winning response ($y_w$) and a losing response ($y_l$). However, the likelihood displacement observed in DPO indicates that both $\log \pi_\theta (y_w\mid x)$ and $\log \pi_\theta (y_l\mid x) $ often decrease during training, inadvertently boosting the probabilities of non-target responses. In this paper, we systematically revisit this phenomenon from LLMs to Video-LLMs, showing that it intensifies when dealing with the redundant complexity of video content. To alleviate the impact of this phenomenon, we propose \emph{Lean Preference Optimization} (LeanPO), a reference-free approach that reformulates the implicit reward as the average likelihood of the response with respect to the policy model. A key component of LeanPO is the reward-trustworthiness correlated self-generated preference data pipeline, which carefully infuses relevant prior knowledge into the model while continuously refining the preference data via self-reflection. This allows the policy model to obtain high-quality paired data and accurately estimate the newly defined reward, thus mitigating the unintended drop. In addition, we introduce a dynamic label smoothing strategy that mitigates the impact of noise in responses from diverse video content, preventing the model from overfitting to spurious details. Extensive experiments demonstrate that LeanPO significantly enhances the performance of state-of-the-art Video-LLMs, consistently boosting baselines of varying capacities with minimal additional training overhead. Moreover, LeanPO offers a simple yet effective solution for aligning Video-LLM preferences with human trustworthiness, paving the way toward the reliable and efficient Video-LLMs.
Multi-objective Aligned Bidword Generation Model for E-commerce Search Advertising
Jun 04, 2025



Retrieval systems primarily address the challenge of matching user queries with the most relevant advertisements, playing a crucial role in e-commerce search advertising. The diversity of user needs and expressions often produces massive long-tail queries that cannot be matched with merchant bidwords or product titles, which results in some advertisements not being recalled, ultimately harming user experience and search efficiency. Existing query rewriting research focuses on various methods such as query log mining, query-bidword vector matching, or generation-based rewriting. However, these methods often fail to simultaneously optimize the relevance and authenticity of the user's original query and rewrite and maximize the revenue potential of recalled ads. In this paper, we propose a Multi-objective aligned Bidword Generation Model (MoBGM), which is composed of a discriminator, generator, and preference alignment module, to address these challenges. To simultaneously improve the relevance and authenticity of the query and rewrite and maximize the platform revenue, we design a discriminator to optimize these key objectives. Using the feedback signal of the discriminator, we train a multi-objective aligned bidword generator that aims to maximize the combined effect of the three objectives. Extensive offline and online experiments show that our proposed algorithm significantly outperforms the state of the art. After deployment, the algorithm has created huge commercial value for the platform, further verifying its feasibility and robustness.
OpenS2V-Nexus: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation
May 28, 2025Subject-to-Video (S2V) generation aims to create videos that faithfully incorporate reference content, providing enhanced flexibility in the production of videos. To establish the infrastructure for S2V generation, we propose OpenS2V-Nexus, consisting of (i) OpenS2V-Eval, a fine-grained benchmark, and (ii) OpenS2V-5M, a million-scale dataset. In contrast to existing S2V benchmarks inherited from VBench that focus on global and coarse-grained assessment of generated videos, OpenS2V-Eval focuses on the model's ability to generate subject-consistent videos with natural subject appearance and identity fidelity. For these purposes, OpenS2V-Eval introduces 180 prompts from seven major categories of S2V, which incorporate both real and synthetic test data. Furthermore, to accurately align human preferences with S2V benchmarks, we propose three automatic metrics, NexusScore, NaturalScore and GmeScore, to separately quantify subject consistency, naturalness, and text relevance in generated videos. Building on this, we conduct a comprehensive evaluation of 16 representative S2V models, highlighting their strengths and weaknesses across different content. Moreover, we create the first open-source large-scale S2V generation dataset OpenS2V-5M, which consists of five million high-quality 720P subject-text-video triples. Specifically, we ensure subject-information diversity in our dataset by (1) segmenting subjects and building pairing information via cross-video associations and (2) prompting GPT-Image-1 on raw frames to synthesize multi-view representations. Through OpenS2V-Nexus, we deliver a robust infrastructure to accelerate future S2V generation research.
Sci-Fi: Symmetric Constraint for Frame Inbetweening
May 27, 2025



Frame inbetweening aims to synthesize intermediate video sequences conditioned on the given start and end frames. Current state-of-the-art methods mainly extend large-scale pre-trained Image-to-Video Diffusion models (I2V-DMs) by incorporating end-frame constraints via directly fine-tuning or omitting training. We identify a critical limitation in their design: Their injections of the end-frame constraint usually utilize the same mechanism that originally imposed the start-frame (single image) constraint. However, since the original I2V-DMs are adequately trained for the start-frame condition in advance, naively introducing the end-frame constraint by the same mechanism with much less (even zero) specialized training probably can't make the end frame have a strong enough impact on the intermediate content like the start frame. This asymmetric control strength of the two frames over the intermediate content likely leads to inconsistent motion or appearance collapse in generated frames. To efficiently achieve symmetric constraints of start and end frames, we propose a novel framework, termed Sci-Fi, which applies a stronger injection for the constraint of a smaller training scale. Specifically, it deals with the start-frame constraint as before, while introducing the end-frame constraint by an improved mechanism. The new mechanism is based on a well-designed lightweight module, named EF-Net, which encodes only the end frame and expands it into temporally adaptive frame-wise features injected into the I2V-DM. This makes the end-frame constraint as strong as the start-frame constraint, enabling our Sci-Fi to produce more harmonious transitions in various scenarios. Extensive experiments prove the superiority of our Sci-Fi compared with other baselines.
Beyond Chemical QA: Evaluating LLM's Chemical Reasoning with Modular Chemical Operations
May 27, 2025While large language models (LLMs) with Chain-of-Thought (CoT) reasoning excel in mathematics and coding, their potential for systematic reasoning in chemistry, a domain demanding rigorous structural analysis for real-world tasks like drug design and reaction engineering, remains untapped. Current benchmarks focus on simple knowledge retrieval, neglecting step-by-step reasoning required for complex tasks such as molecular optimization and reaction prediction. To address this, we introduce ChemCoTBench, a reasoning framework that bridges molecular structure understanding with arithmetic-inspired operations, including addition, deletion, and substitution, to formalize chemical problem-solving into transparent, step-by-step workflows. By treating molecular transformations as modular "chemical operations", the framework enables slow-thinking reasoning, mirroring the logic of mathematical proofs while grounding solutions in real-world chemical constraints. We evaluate models on two high-impact tasks: Molecular Property Optimization and Chemical Reaction Prediction. These tasks mirror real-world challenges while providing structured evaluability. By providing annotated datasets, a reasoning taxonomy, and baseline evaluations, ChemCoTBench bridges the gap between abstract reasoning methods and practical chemical discovery, establishing a foundation for advancing LLMs as tools for AI-driven scientific innovation.
ImgEdit: A Unified Image Editing Dataset and Benchmark
May 26, 2025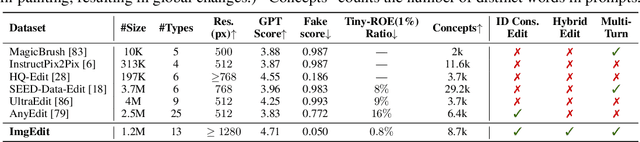
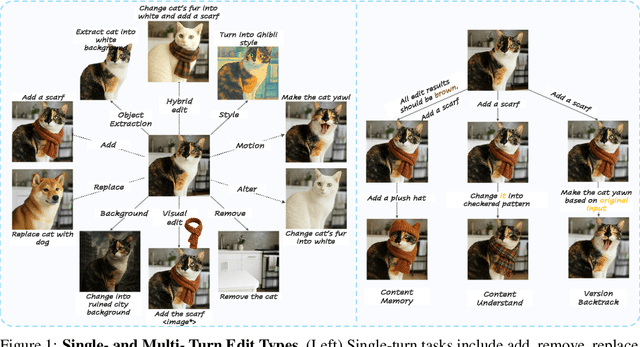
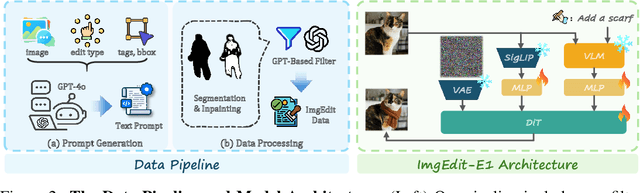

Recent advancements in generative models have enabled high-fidelity text-to-image generation. However, open-source image-editing models still lag behind their proprietary counterparts, primarily due to limited high-quality data and insufficient benchmarks. To overcome these limitations, we introduce ImgEdit, a large-scale, high-quality image-editing dataset comprising 1.2 million carefully curated edit pairs, which contain both novel and complex single-turn edits, as well as challenging multi-turn tasks. To ensure the data quality, we employ a multi-stage pipeline that integrates a cutting-edge vision-language model, a detection model, a segmentation model, alongside task-specific in-painting procedures and strict post-processing. ImgEdit surpasses existing datasets in both task novelty and data quality. Using ImgEdit, we train ImgEdit-E1, an editing model using Vision Language Model to process the reference image and editing prompt, which outperforms existing open-source models on multiple tasks, highlighting the value of ImgEdit and model design. For comprehensive evaluation, we introduce ImgEdit-Bench, a benchmark designed to evaluate image editing performance in terms of instruction adherence, editing quality, and detail preservation. It includes a basic testsuite, a challenging single-turn suite, and a dedicated multi-turn suite. We evaluate both open-source and proprietary models, as well as ImgEdit-E1, providing deep analysis and actionable insights into the current behavior of image-editing models. The source data are publicly available on https://github.com/PKU-YuanGroup/ImgEdit.
Rethinking Text-based Protein Understanding: Retrieval or LLM?
May 26, 2025In recent years, protein-text models have gained significant attention for their potential in protein generation and understanding. Current approaches focus on integrating protein-related knowledge into large language models through continued pretraining and multi-modal alignment, enabling simultaneous comprehension of textual descriptions and protein sequences. Through a thorough analysis of existing model architectures and text-based protein understanding benchmarks, we identify significant data leakage issues present in current benchmarks. Moreover, conventional metrics derived from natural language processing fail to accurately assess the model's performance in this domain. To address these limitations, we reorganize existing datasets and introduce a novel evaluation framework based on biological entities. Motivated by our observation, we propose a retrieval-enhanced method, which significantly outperforms fine-tuned LLMs for protein-to-text generation and shows accuracy and efficiency in training-free scenarios. Our code and data can be seen at https://github.com/IDEA-XL/RAPM.
CAD: A General Multimodal Framework for Video Deepfake Detection via Cross-Modal Alignment and Distillation
May 21, 2025The rapid emergence of multimodal deepfakes (visual and auditory content are manipulated in concert) undermines the reliability of existing detectors that rely solely on modality-specific artifacts or cross-modal inconsistencies. In this work, we first demonstrate that modality-specific forensic traces (e.g., face-swap artifacts or spectral distortions) and modality-shared semantic misalignments (e.g., lip-speech asynchrony) offer complementary evidence, and that neglecting either aspect limits detection performance. Existing approaches either naively fuse modality-specific features without reconciling their conflicting characteristics or focus predominantly on semantic misalignment at the expense of modality-specific fine-grained artifact cues. To address these shortcomings, we propose a general multimodal framework for video deepfake detection via Cross-Modal Alignment and Distillation (CAD). CAD comprises two core components: 1) Cross-modal alignment that identifies inconsistencies in high-level semantic synchronization (e.g., lip-speech mismatches); 2) Cross-modal distillation that mitigates feature conflicts during fusion while preserving modality-specific forensic traces (e.g., spectral distortions in synthetic audio). Extensive experiments on both multimodal and unimodal (e.g., image-only/video-only)deepfake benchmarks demonstrate that CAD significantly outperforms previous methods, validating the necessity of harmonious integration of multimodal complementary information.