 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Network Identification of Limnonectes Species and New Class Detection Using Image Data
Nov 15, 2023



As is true of many complex tasks, the work of discovering, describing, and understanding the diversity of life on Earth (viz., biological systematics and taxonomy) requires many tools. Some of this work can be accomplished as it has been done in the past, but some aspects present us with challenges which traditional knowledge and tools cannot adequately resolve. One such challenge is presented by species complexes in which the morphological similarities among the group members make it difficult to reliably identify known species and detect new ones. We address this challenge by developing new tools using the principles of machine learning to resolve two specific questions related to species complexes. The first question is formulated as a classification problem in statistics and machine learning and the second question is an out-of-distribution (OOD) detection problem. We apply these tools to a species complex comprising Southeast Asian stream frogs (Limnonectes kuhlii complex) and employ a morphological character (hind limb skin texture) traditionally treated qualitatively in a quantitative and objective manner. We demonstrate that deep neural networks can successfully automate the classification of an image into a known species group for which it has been trained. We further demonstrate that the algorithm can successfully classify an image into a new class if the image does not belong to the existing classes. Additionally, we use the larger MNIST dataset to test the performance of our OOD detection algorithm. We finish our paper with some concluding remarks regarding the application of these methods to species complexes and our efforts to document true biodiversity. This paper has online supplementary materials.
Intention-Aware Planner for Robust and Safe Aerial Tracking
Sep 16, 2023



The intention of the target can help us to estimate its future motion state more accurately. This paper proposes an intention-aware planner to enhance safety and robustness in aerial tracking applications. Firstly, we utilize the Mediapipe framework to estimate target's pose. A risk assessment function and a state observation function are designed to predict the target intention. Afterwards, an intention-driven hybrid A* method is proposed for target motion prediction, ensuring that the target's future positions align with its intention. Finally, an intention-aware optimization approach, in conjunction with particular penalty formulations, is designed to generate a spatial-temporal optimal trajectory. Benchmark comparisons validate the superior performance of our proposed methodology across diverse scenarios. This is attributed to the integration of the target intention into the planner through coupled formulations.
Bridged-GNN: Knowledge Bridge Learning for Effective Knowledge Transfer
Aug 18, 2023



The data-hungry problem, characterized by insufficiency and low-quality of data, poses obstacles for deep learning models. Transfer learning has been a feasible way to transfer knowledge from high-quality external data of source domains to limited data of target domains, which follows a domain-level knowledge transfer to learn a shared posterior distribution. However, they are usually built on strong assumptions, e.g., the domain invariant posterior distribution, which is usually unsatisfied and may introduce noises, resulting in poor generalization ability on target domains. Inspired by Graph Neural Networks (GNNs) that aggregate information from neighboring nodes, we redefine the paradigm as learning a knowledge-enhanced posterior distribution for target domains, namely Knowledge Bridge Learning (KBL). KBL first learns the scope of knowledge transfer by constructing a Bridged-Graph that connects knowledgeable samples to each target sample and then performs sample-wise knowledge transfer via GNNs.KBL is free from strong assumptions and is robust to noises in the source data. Guided by KBL, we propose the Bridged-GNN} including an Adaptive Knowledge Retrieval module to build Bridged-Graph and a Graph Knowledge Transfer module. Comprehensive experiments on both un-relational and relational data-hungry scenarios demonstrate the significant improvements of Bridged-GNN compared with SOTA methods
Towards Robust SDRTV-to-HDRTV via Dual Inverse Degradation Network
Jul 07, 2023



Recently, the transformation of standard dynamic range TV (SDRTV) to high dynamic range TV (HDRTV) is in high demand due to the scarcity of HDRTV content. However, the conversion of SDRTV to HDRTV often amplifies the existing coding artifacts in SDRTV which deteriorate the visual quality of the output. In this study, we propose a dual inverse degradation SDRTV-to-HDRTV network DIDNet to address the issue of coding artifact restoration in converted HDRTV, which has not been previously studied. Specifically, we propose a temporal-spatial feature alignment module and dual modulation convolution to remove coding artifacts and enhance color restoration ability. Furthermore, a wavelet attention module is proposed to improve SDRTV features in the frequency domain. An auxiliary loss is introduced to decouple the learning process for effectively restoring from dual degradation. The proposed method outperforms the current state-of-the-art method in terms of quantitative results, visual quality, and inference times, thus enhancing the performance of the SDRTV-to-HDRTV method in real-world scenarios.
Multi-modal Pre-training for Medical Vision-language Understanding and Generation: An Empirical Study with A New Benchmark
Jun 10, 2023With the availability of large-scale, comprehensive, and general-purpose vision-language (VL) datasets such as MSCOCO, vision-language pre-training (VLP) has become an active area of research and proven to be effective for various VL tasks such as visual-question answering. However, studies on VLP in the medical domain have so far been scanty. To provide a comprehensive perspective on VLP for medical VL tasks, we conduct a thorough experimental analysis to study key factors that may affect the performance of VLP with a unified vision-language Transformer. To allow making sound and quick pre-training decisions, we propose RadioGraphy Captions (RGC), a high-quality, multi-modality radiographic dataset containing 18,434 image-caption pairs collected from an open-access online database MedPix. RGC can be used as a pre-training dataset or a new benchmark for medical report generation and medical image-text retrieval. By utilizing RGC and other available datasets for pre-training, we develop several key insights that can guide future medical VLP research and new strong baselines for various medical VL tasks.
Meta Compositional Referring Expression Segmentation
Apr 12, 2023



Referring expression segmentation aims to segment an object described by a language expression from an image. Despite the recent progress on this task, existing models tackling this task may not be able to fully capture semantics and visual representations of individual concepts, which limits their generalization capability, especially when handling novel compositions of learned concepts. In this work, through the lens of meta learning, we propose a Meta Compositional Referring Expression Segmentation (MCRES) framework to enhance model compositional generalization performance. Specifically, to handle various levels of novel compositions, our framework first uses training data to construct a virtual training set and multiple virtual testing sets, where data samples in each virtual testing set contain a level of novel compositions w.r.t. the virtual training set. Then, following a novel meta optimization scheme to optimize the model to obtain good testing performance on the virtual testing sets after training on the virtual training set, our framework can effectively drive the model to better capture semantics and visual representations of individual concepts, and thus obtain robust generalization performance even when handling novel compositions. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our framework.
Predicting the Silent Majority on Graphs: Knowledge Transferable Graph Neural Network
Feb 02, 2023



Graphs consisting of vocal nodes ("the vocal minority") and silent nodes ("the silent majority"), namely VS-Graph, are ubiquitous in the real world. The vocal nodes tend to have abundant features and labels. In contrast, silent nodes only have incomplete features and rare labels, e.g., the description and political tendency of politicians (vocal) are abundant while not for ordinary people (silent) on the twitter's social network. Predicting the silent majority remains a crucial yet challenging problem. However, most existing message-passing based GNNs assume that all nodes belong to the same domain, without considering the missing features and distribution-shift between domains, leading to poor ability to deal with VS-Graph. To combat the above challenges, we propose Knowledge Transferable Graph Neural Network (KT-GNN), which models distribution shifts during message passing and representation learning by transferring knowledge from vocal nodes to silent nodes. Specifically, we design the domain-adapted "feature completion and message passing mechanism" for node representation learning while preserving domain difference. And a knowledge transferable classifier based on KL-divergence is followed. Comprehensive experiments on real-world scenarios (i.e., company financial risk assessment and political elections) demonstrate the superior performance of our method. Our source code has been open sourced.
SDRTV-to-HDRTV Conversion via Spatial-Temporal Feature Fusion
Nov 04, 2022HDR(High Dynamic Range) video can reproduce realistic scenes more realistically, with a wider gamut and broader brightness range. HDR video resources are still scarce, and most videos are still stored in SDR (Standard Dynamic Range) format. Therefore, SDRTV-to-HDRTV Conversion (SDR video to HDR video) can significantly enhance the user's video viewing experience. Since the correlation between adjacent video frames is very high, the method utilizing the information of multiple frames can improve the quality of the converted HDRTV. Therefore, we propose a multi-frame fusion neural network \textbf{DSLNet} for SDRTV to HDRTV conversion. We first propose a dynamic spatial-temporal feature alignment module \textbf{DMFA}, which can align and fuse multi-frame. Then a novel spatial-temporal feature modulation module \textbf{STFM}, STFM extracts spatial-temporal information of adjacent frames for more accurate feature modulation. Finally, we design a quality enhancement module \textbf{LKQE} with large kernels, which can enhance the quality of generated HDR videos. To evaluate the performance of the proposed method, we construct a corresponding multi-frame dataset using HDR video of the HDR10 standard to conduct a comprehensive evaluation of different methods. The experimental results show that our method obtains state-of-the-art performance. The dataset and code will be released.
Individualized Conditioning and Negative Distances for Speaker Separation
Oct 12, 2022
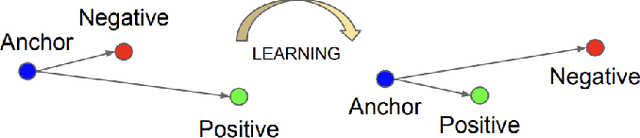
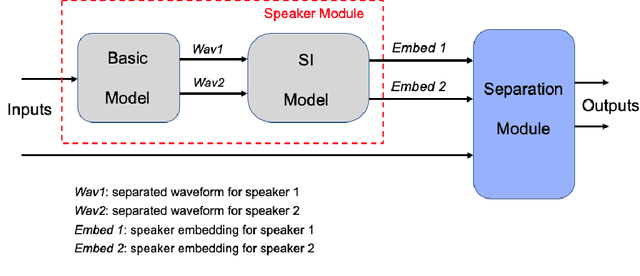
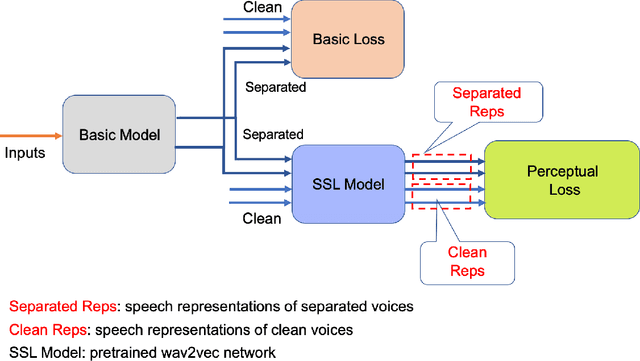
Speaker separation aims to extract multiple voices from a mixed signal. In this paper, we propose two speaker-aware designs to improve the existing speaker separation solutions. The first model is a speaker conditioning network that integrates speech samples to generate individualized speaker conditions, which then provide informed guidance for a separation module to produce well-separated outputs. The second design aims to reduce non-target voices in the separated speech. To this end, we propose negative distances to penalize the appearance of any non-target voice in the channel outputs, and positive distances to drive the separated voices closer to the clean targets. We explore two different setups, weighted-sum and triplet-like, to integrate these two distances to form a combined auxiliary loss for the separation networks. Experiments conducted on LibriMix demonstrate the effectiveness of our proposed models.
Heatmap Distribution Matching for Human Pose Estimation
Oct 04, 2022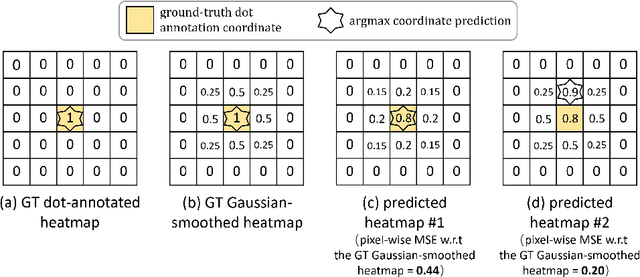
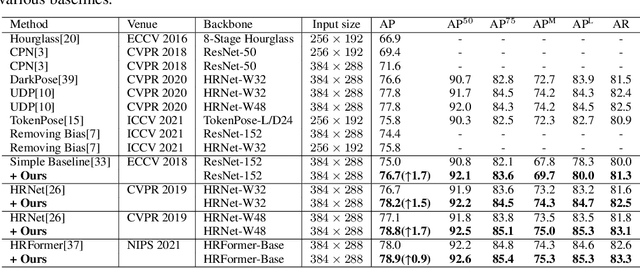
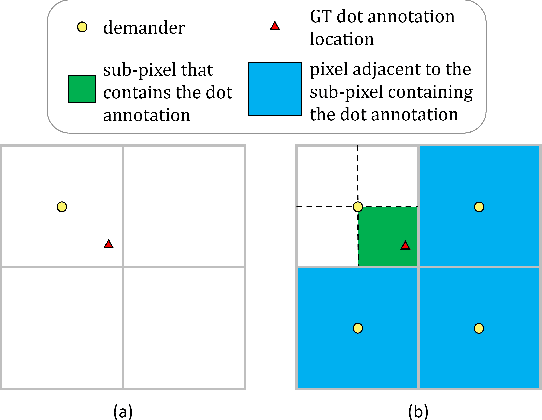
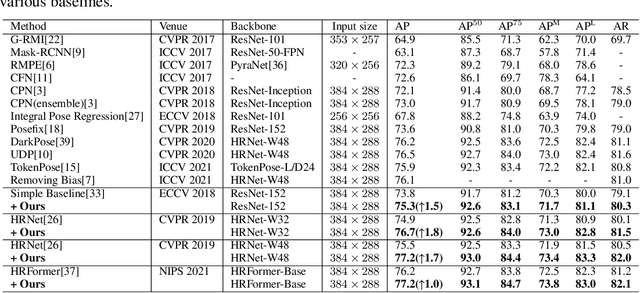
For tackling the task of 2D human pose estimation, the great majority of the recent methods regard this task as a heatmap estimation problem, and optimize the heatmap prediction using the Gaussian-smoothed heatmap as the optimization objective and using the pixel-wise loss (e.g. MSE) as the loss function. In this paper, we show that optimizing the heatmap prediction in such a way, the model performance of body joint localization, which is the intrinsic objective of this task, may not be consistently improved during the optimization process of the heatmap prediction. To address this problem, from a novel perspective, we propose to formulate the optimization of the heatmap prediction as a distribution matching problem between the predicted heatmap and the dot annotation of the body joint directly. By doing so, our proposed method does not need to construct the Gaussian-smoothed heatmap and can achieve a more consistent model performance improvement during the optimization of the heatmap prediction. We show the effectiveness of our proposed method through extensive experiments on the COCO dataset and the MPII dataset.