 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeUV: Ground-Truth-Free Realistic Facial UV Texture Recovery via Cross-Assembly Inference Strategy
Mar 21, 2025



Recovering high-quality 3D facial textures from single-view 2D images is a challenging task, especially under constraints of limited data and complex facial details such as makeup, wrinkles, and occlusions. In this paper, we introduce FreeUV, a novel ground-truth-free UV texture recovery framework that eliminates the need for annotated or synthetic UV data. FreeUV leverages pre-trained stable diffusion model alongside a Cross-Assembly inference strategy to fulfill this objective. In FreeUV, separate networks are trained independently to focus on realistic appearance and structural consistency, and these networks are combined during inference to generate coherent textures. Our approach accurately captures intricate facial features and demonstrates robust performance across diverse poses and occlusions. Extensive experiments validate FreeUV's effectiveness, with results surpassing state-of-the-art methods in both quantitative and qualitative metrics. Additionally, FreeUV enables new applications, including local editing, facial feature interpolation, and multi-view texture recovery. By reducing data requirements, FreeUV offers a scalable solution for generating high-fidelity 3D facial textures suitable for real-world scenarios.
BeautyBank: Encoding Facial Makeup in Latent Space
Nov 18, 2024



The advancement of makeup transfer, editing, and image encoding has demonstrated their effectiveness and superior quality. However, existing makeup works primarily focus on low-dimensional features such as color distributions and patterns, limiting their versatillity across a wide range of makeup applications. Futhermore, existing high-dimensional latent encoding methods mainly target global features such as structure and style, and are less effective for tasks that require detailed attention to local color and pattern features of makeup. To overcome these limitations, we propose BeautyBank, a novel makeup encoder that disentangles pattern features of bare and makeup faces. Our method encodes makeup features into a high-dimensional space, preserving essential details necessary for makeup reconstruction and broadening the scope of potential makeup research applications. We also propose a Progressive Makeup Tuning (PMT) strategy, specifically designed to enhance the preservation of detailed makeup features while preventing the inclusion of irrelevant attributes. We further explore novel makeup applications, including facial image generation with makeup injection and makeup similarity measure. Extensive empirical experiments validate that our method offers superior task adaptability and holds significant potential for widespread application in various makeup-related fields. Furthermore, to address the lack of large-scale, high-quality paired makeup datasets in the field, we constructed the Bare-Makeup Synthesis Dataset (BMS), comprising 324,000 pairs of 512x512 pixel images of bare and makeup-enhanced faces.
TANGO: Co-Speech Gesture Video Reenactment with Hierarchical Audio Motion Embedding and Diffusion Interpolation
Oct 05, 2024



We present TANGO, a framework for generating co-speech body-gesture videos. Given a few-minute, single-speaker reference video and target speech audio, TANGO produces high-fidelity videos with synchronized body gestures. TANGO builds on Gesture Video Reenactment (GVR), which splits and retrieves video clips using a directed graph structure - representing video frames as nodes and valid transitions as edges. We address two key limitations of GVR: audio-motion misalignment and visual artifacts in GAN-generated transition frames. In particular, (i) we propose retrieving gestures using latent feature distance to improve cross-modal alignment. To ensure the latent features could effectively model the relationship between speech audio and gesture motion, we implement a hierarchical joint embedding space (AuMoCLIP); (ii) we introduce the diffusion-based model to generate high-quality transition frames. Our diffusion model, Appearance Consistent Interpolation (ACInterp), is built upon AnimateAnyone and includes a reference motion module and homography background flow to preserve appearance consistency between generated and reference videos. By integrating these components into the graph-based retrieval framework, TANGO reliably produces realistic, audio-synchronized videos and outperforms all existing generative and retrieval methods. Our codes and pretrained models are available: \url{https://pantomatrix.github.io/TANGO/}
Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering for HDR View Synthesis
Jun 10, 2024Volumetric rendering based methods, like NeRF, excel in HDR view synthesis from RAWimages, especially for nighttime scenes. While, they suffer from long training times and cannot perform real-time rendering due to dense sampling requirements. The advent of 3D Gaussian Splatting (3DGS) enables real-time rendering and faster training. However, implementing RAW image-based view synthesis directly using 3DGS is challenging due to its inherent drawbacks: 1) in nighttime scenes, extremely low SNR leads to poor structure-from-motion (SfM) estimation in distant views; 2) the limited representation capacity of spherical harmonics (SH) function is unsuitable for RAW linear color space; and 3) inaccurate scene structure hampers downstream tasks such as refocusing. To address these issues, we propose LE3D (Lighting Every darkness with 3DGS). Our method proposes Cone Scatter Initialization to enrich the estimation of SfM, and replaces SH with a Color MLP to represent the RAW linear color space. Additionally, we introduce depth distortion and near-far regularizations to improve the accuracy of scene structure for downstream tasks. These designs enable LE3D to perform real-time novel view synthesis, HDR rendering, refocusing, and tone-mapping changes. Compared to previous volumetric rendering based methods, LE3D reduces training time to 1% and improves rendering speed by up to 4,000 times for 2K resolution images in terms of FPS. Code and viewer can be found in https://github.com/Srameo/LE3D .
Makeup Prior Models for 3D Facial Makeup Estimation and Applications
Mar 26, 2024



In this work, we introduce two types of makeup prior models to extend existing 3D face prior models: PCA-based and StyleGAN2-based priors. The PCA-based prior model is a linear model that is easy to construct and is computationally efficient. However, it retains only low-frequency information. Conversely, the StyleGAN2-based model can represent high-frequency information with relatively higher computational cost than the PCA-based model. Although there is a trade-off between the two models, both are applicable to 3D facial makeup estimation and related applications. By leveraging makeup prior models and designing a makeup consistency module, we effectively address the challenges that previous methods faced in robustly estimating makeup, particularly in the context of handling self-occluded faces. In experiments, we demonstrate that our approach reduces computational costs by several orders of magnitude, achieving speeds up to 180 times faster. In addition, by improving the accuracy of the estimated makeup, we confirm that our methods are highly advantageous for various 3D facial makeup applications such as 3D makeup face reconstruction, user-friendly makeup editing, makeup transfer, and interpolation.
BlendFace: Re-designing Identity Encoders for Face-Swapping
Jul 20, 2023



The great advancements of generative adversarial networks and face recognition models in computer vision have made it possible to swap identities on images from single sources. Although a lot of studies seems to have proposed almost satisfactory solutions, we notice previous methods still suffer from an identity-attribute entanglement that causes undesired attributes swapping because widely used identity encoders, eg, ArcFace, have some crucial attribute biases owing to their pretraining on face recognition tasks. To address this issue, we design BlendFace, a novel identity encoder for face-swapping. The key idea behind BlendFace is training face recognition models on blended images whose attributes are replaced with those of another mitigates inter-personal biases such as hairsyles. BlendFace feeds disentangled identity features into generators and guides generators properly as an identity loss function. Extensive experiments demonstrate that BlendFace improves the identity-attribute disentanglement in face-swapping models, maintaining a comparable quantitative performance to previous methods.
Towards Robust SDRTV-to-HDRTV via Dual Inverse Degradation Network
Jul 07, 2023



Recently, the transformation of standard dynamic range TV (SDRTV) to high dynamic range TV (HDRTV) is in high demand due to the scarcity of HDRTV content. However, the conversion of SDRTV to HDRTV often amplifies the existing coding artifacts in SDRTV which deteriorate the visual quality of the output. In this study, we propose a dual inverse degradation SDRTV-to-HDRTV network DIDNet to address the issue of coding artifact restoration in converted HDRTV, which has not been previously studied. Specifically, we propose a temporal-spatial feature alignment module and dual modulation convolution to remove coding artifacts and enhance color restoration ability. Furthermore, a wavelet attention module is proposed to improve SDRTV features in the frequency domain. An auxiliary loss is introduced to decouple the learning process for effectively restoring from dual degradation. The proposed method outperforms the current state-of-the-art method in terms of quantitative results, visual quality, and inference times, thus enhancing the performance of the SDRTV-to-HDRTV method in real-world scenarios.
Makeup Extraction of 3D Representation via Illumination-Aware Image Decomposition
Feb 26, 2023Facial makeup enriches the beauty of not only real humans but also virtual characters; therefore, makeup for 3D facial models is highly in demand in productions. However, painting directly on 3D faces and capturing real-world makeup are costly, and extracting makeup from 2D images often struggles with shading effects and occlusions. This paper presents the first method for extracting makeup for 3D facial models from a single makeup portrait. Our method consists of the following three steps. First, we exploit the strong prior of 3D morphable models via regression-based inverse rendering to extract coarse materials such as geometry and diffuse/specular albedos that are represented in the UV space. Second, we refine the coarse materials, which may have missing pixels due to occlusions. We apply inpainting and optimization. Finally, we extract the bare skin, makeup, and an alpha matte from the diffuse albedo. Our method offers various applications for not only 3D facial models but also 2D portrait images. The extracted makeup is well-aligned in the UV space, from which we build a large-scale makeup dataset and a parametric makeup model for 3D faces. Our disentangled materials also yield robust makeup transfer and illumination-aware makeup interpolation/removal without a reference image.
BareSkinNet: De-makeup and De-lighting via 3D Face Reconstruction
Sep 19, 2022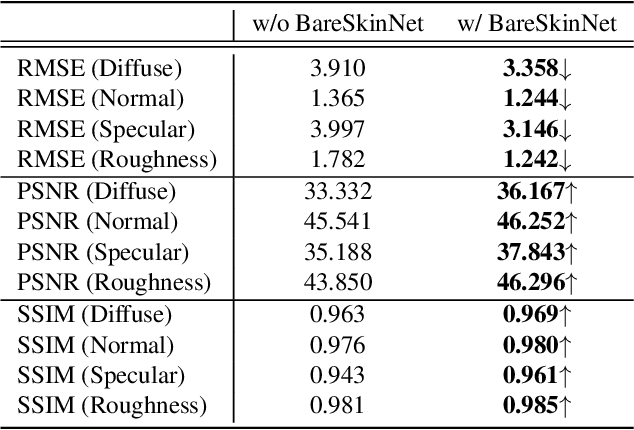
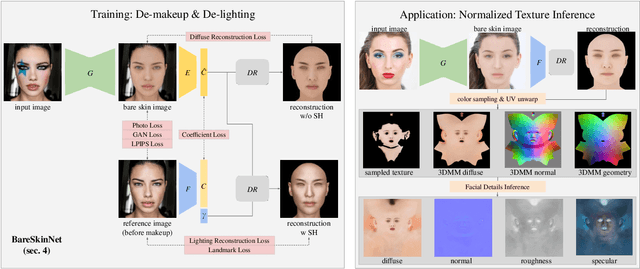


We propose BareSkinNet, a novel method that simultaneously removes makeup and lighting influences from the face image. Our method leverages a 3D morphable model and does not require a reference clean face image or a specified light condition. By combining the process of 3D face reconstruction, we can easily obtain 3D geometry and coarse 3D textures. Using this information, we can infer normalized 3D face texture maps (diffuse, normal, roughness, and specular) by an image-translation network. Consequently, reconstructed 3D face textures without undesirable information will significantly benefit subsequent processes, such as re-lighting or re-makeup. In experiments, we show that BareSkinNet outperforms state-of-the-art makeup removal methods. In addition, our method is remarkably helpful in removing makeup to generate consistent high-fidelity texture maps, which makes it extendable to many realistic face generation applications. It can also automatically build graphic assets of face makeup images before and after with corresponding 3D data. This will assist artists in accelerating their work, such as 3D makeup avatar creation.