 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Scoring for Machine Learning Classifier Error Impact Evaluation
Aug 06, 2025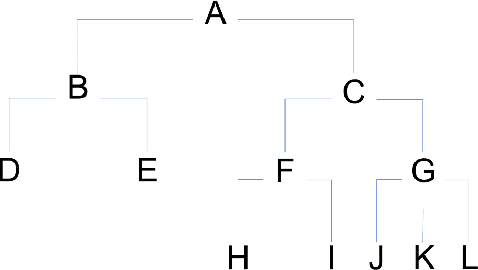
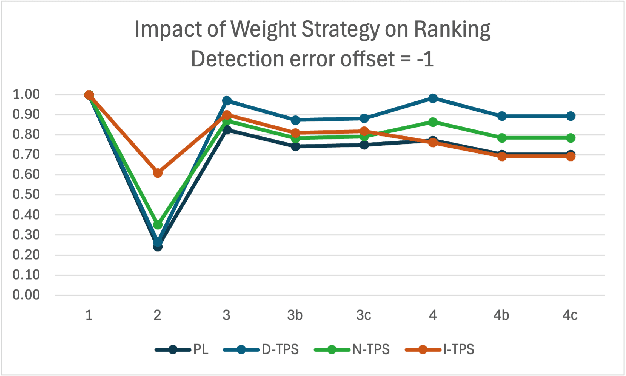
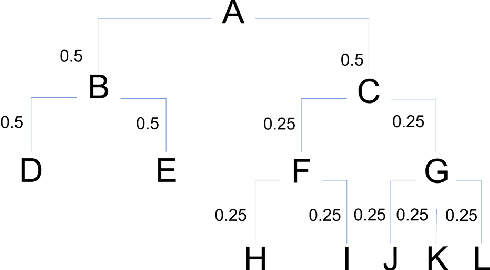
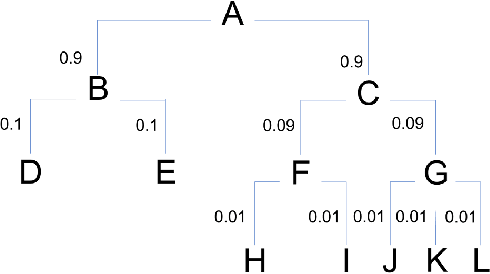
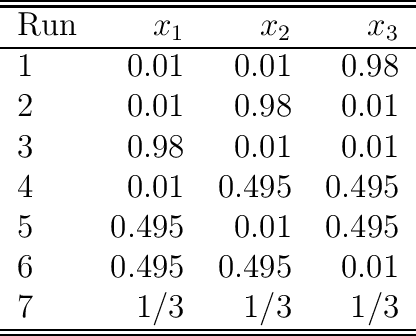
A common use of machine learning (ML) models is predicting the class of a sample. Object detection is an extension of classification that includes localization of the object via a bounding box within the sample. Classification, and by extension object detection, is typically evaluated by counting a prediction as incorrect if the predicted label does not match the ground truth label. This pass/fail scoring treats all misclassifications as equivalent. In many cases, class labels can be organized into a class taxonomy with a hierarchical structure to either reflect relationships among the data or operator valuation of misclassifications. When such a hierarchical structure exists, hierarchical scoring metrics can return the model performance of a given prediction related to the distance between the prediction and the ground truth label. Such metrics can be viewed as giving partial credit to predictions instead of pass/fail, enabling a finer-grained understanding of the impact of misclassifications. This work develops hierarchical scoring metrics varying in complexity that utilize scoring trees to encode relationships between class labels and produce metrics that reflect distance in the scoring tree. The scoring metrics are demonstrated on an abstract use case with scoring trees that represent three weighting strategies and evaluated by the kind of errors discouraged. Results demonstrate that these metrics capture errors with finer granularity and the scoring trees enable tuning. This work demonstrates an approach to evaluating ML performance that ranks models not only by how many errors are made but by the kind or impact of errors. Python implementations of the scoring metrics will be available in an open-source repository at time of publication.
Deep Neural Network Identification of Limnonectes Species and New Class Detection Using Image Data
Nov 15, 2023



As is true of many complex tasks, the work of discovering, describing, and understanding the diversity of life on Earth (viz., biological systematics and taxonomy) requires many tools. Some of this work can be accomplished as it has been done in the past, but some aspects present us with challenges which traditional knowledge and tools cannot adequately resolve. One such challenge is presented by species complexes in which the morphological similarities among the group members make it difficult to reliably identify known species and detect new ones. We address this challenge by developing new tools using the principles of machine learning to resolve two specific questions related to species complexes. The first question is formulated as a classification problem in statistics and machine learning and the second question is an out-of-distribution (OOD) detection problem. We apply these tools to a species complex comprising Southeast Asian stream frogs (Limnonectes kuhlii complex) and employ a morphological character (hind limb skin texture) traditionally treated qualitatively in a quantitative and objective manner. We demonstrate that deep neural networks can successfully automate the classification of an image into a known species group for which it has been trained. We further demonstrate that the algorithm can successfully classify an image into a new class if the image does not belong to the existing classes. Additionally, we use the larger MNIST dataset to test the performance of our OOD detection algorithm. We finish our paper with some concluding remarks regarding the application of these methods to species complexes and our efforts to document true biodiversity. This paper has online supplementary materials.
Statistical Perspectives on Reliability of Artificial Intelligence Systems
Nov 09, 2021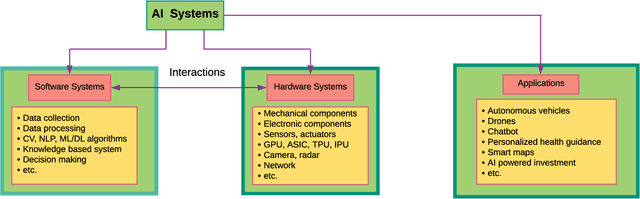
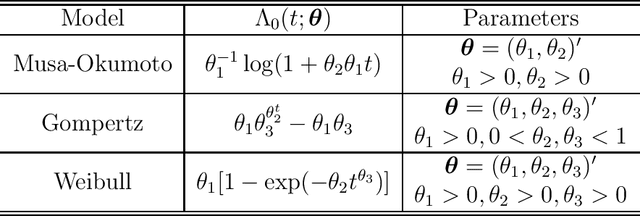
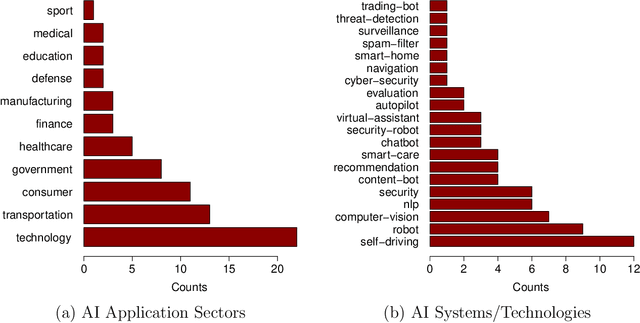
Artificial intelligence (AI) systems have become increasingly popular in many areas. Nevertheless, AI technologies are still in their developing stages, and many issues need to be addressed. Among those, the reliability of AI systems needs to be demonstrated so that the AI systems can be used with confidence by the general public. In this paper, we provide statistical perspectives on the reliability of AI systems. Different from other considerations, the reliability of AI systems focuses on the time dimension. That is, the system can perform its designed functionality for the intended period. We introduce a so-called SMART statistical framework for AI reliability research, which includes five components: Structure of the system, Metrics of reliability, Analysis of failure causes, Reliability assessment, and Test planning. We review traditional methods in reliability data analysis and software reliability, and discuss how those existing methods can be transformed for reliability modeling and assessment of AI systems. We also describe recent developments in modeling and analysis of AI reliability and outline statistical research challenges in this area, including out-of-distribution detection, the effect of the training set, adversarial attacks, model accuracy, and uncertainty quantification, and discuss how those topics can be related to AI reliability, with illustrative examples. Finally, we discuss data collection and test planning for AI reliability assessment and how to improve system designs for higher AI reliability. The paper closes with some concluding remarks.