 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Massive Multi-Task Reinforcement Learning via Mixture-of-Expert Decision Transformer
May 30, 2025Despite recent advancements in offline multi-task reinforcement learning (MTRL) have harnessed the powerful capabilities of the Transformer architecture, most approaches focus on a limited number of tasks, with scaling to extremely massive tasks remaining a formidable challenge. In this paper, we first revisit the key impact of task numbers on current MTRL method, and further reveal that naively expanding the parameters proves insufficient to counteract the performance degradation as the number of tasks escalates. Building upon these insights, we propose M3DT, a novel mixture-of-experts (MoE) framework that tackles task scalability by further unlocking the model's parameter scalability. Specifically, we enhance both the architecture and the optimization of the agent, where we strengthen the Decision Transformer (DT) backbone with MoE to reduce task load on parameter subsets, and introduce a three-stage training mechanism to facilitate efficient training with optimal performance. Experimental results show that, by increasing the number of experts, M3DT not only consistently enhances its performance as model expansion on the fixed task numbers, but also exhibits remarkable task scalability, successfully extending to 160 tasks with superior performance.
Unifying Multimodal Large Language Model Capabilities and Modalities via Model Merging
May 26, 2025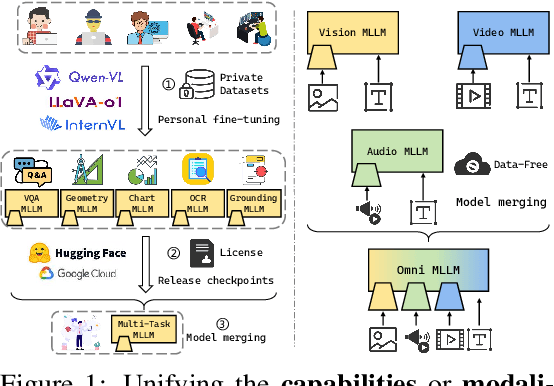

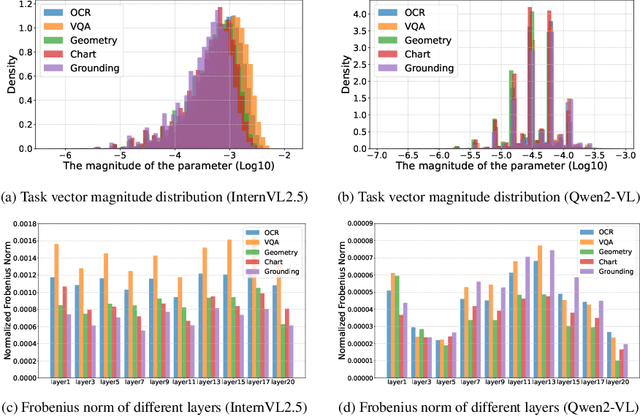
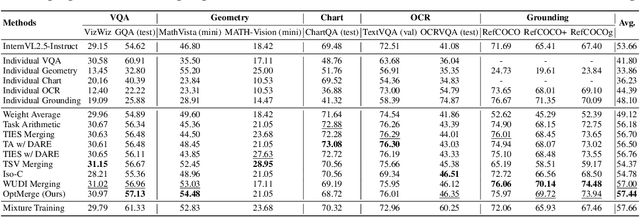
While foundation models update slowly due to resource-intensive training requirements, domain-specific models evolve between updates. Model merging aims to combine multiple expert models into a single, more capable model, thereby reducing storage and serving costs while supporting decentralized model development. Despite its potential, previous studies have primarily focused on merging visual classification models or Large Language Models (LLMs) for code and math tasks. Multimodal Large Language Models (MLLMs), which extend the capabilities of LLMs through large-scale multimodal training, have gained traction. However, there lacks a benchmark for model merging research that clearly divides the tasks for MLLM training and evaluation. In this paper, (i) we introduce the model merging benchmark for MLLMs, which includes multiple tasks such as VQA, Geometry, Chart, OCR, and Grounding, providing both LoRA and full fine-tuning models. Moreover, we explore how model merging can combine different modalities (e.g., vision-language, audio-language, and video-language models), moving toward the Omni-language model. (ii) We implement 10 model merging algorithms on the benchmark. Furthermore, we propose a novel method that removes noise from task vectors and robustly optimizes the merged vector based on a loss defined over task vector interactions, achieving an average performance gain of 2.48%. (iii) We find that model merging offers a promising way for building improved MLLMs without requiring data training. Our results also demonstrate that the complementarity among multiple modalities outperforms individual modalities.
Decision Flow Policy Optimization
May 26, 2025In recent years, generative models have shown remarkable capabilities across diverse fields, including images, videos, language, and decision-making. By applying powerful generative models such as flow-based models to reinforcement learning, we can effectively model complex multi-modal action distributions and achieve superior robotic control in continuous action spaces, surpassing the limitations of single-modal action distributions with traditional Gaussian-based policies. Previous methods usually adopt the generative models as behavior models to fit state-conditioned action distributions from datasets, with policy optimization conducted separately through additional policies using value-based sample weighting or gradient-based updates. However, this separation prevents the simultaneous optimization of multi-modal distribution fitting and policy improvement, ultimately hindering the training of models and degrading the performance. To address this issue, we propose Decision Flow, a unified framework that integrates multi-modal action distribution modeling and policy optimization. Specifically, our method formulates the action generation procedure of flow-based models as a flow decision-making process, where each action generation step corresponds to one flow decision. Consequently, our method seamlessly optimizes the flow policy while capturing multi-modal action distributions. We provide rigorous proofs of Decision Flow and validate the effectiveness through extensive experiments across dozens of offline RL environments. Compared with established offline RL baselines, the results demonstrate that our method achieves or matches the SOTA performance.
Vad-R1: Towards Video Anomaly Reasoning via Perception-to-Cognition Chain-of-Thought
May 26, 2025Recent advancements in reasoning capability of Multimodal Large Language Models (MLLMs) demonstrate its effectiveness in tackling complex visual tasks. However, existing MLLM-based Video Anomaly Detection (VAD) methods remain limited to shallow anomaly descriptions without deep reasoning. In this paper, we propose a new task named Video Anomaly Reasoning (VAR), which aims to enable deep analysis and understanding of anomalies in the video by requiring MLLMs to think explicitly before answering. To this end, we propose Vad-R1, an end-to-end MLLM-based framework for VAR. Specifically, we design a Perception-to-Cognition Chain-of-Thought (P2C-CoT) that simulates the human process of recognizing anomalies, guiding the MLLM to reason anomaly step-by-step. Based on the structured P2C-CoT, we construct Vad-Reasoning, a dedicated dataset for VAR. Furthermore, we propose an improved reinforcement learning algorithm AVA-GRPO, which explicitly incentivizes the anomaly reasoning capability of MLLMs through a self-verification mechanism with limited annotations. Experimental results demonstrate that Vad-R1 achieves superior performance, outperforming both open-source and proprietary models on VAD and VAR tasks. Codes and datasets will be released at https://github.com/wbfwonderful/Vad-R1.
MLLM-Guided VLM Fine-Tuning with Joint Inference for Zero-Shot Composed Image Retrieval
May 26, 2025Existing Zero-Shot Composed Image Retrieval (ZS-CIR) methods typically train adapters that convert reference images into pseudo-text tokens, which are concatenated with the modifying text and processed by frozen text encoders in pretrained VLMs or LLMs. While this design leverages the strengths of large pretrained models, it only supervises the adapter to produce encoder-compatible tokens that loosely preserve visual semantics. Crucially, it does not directly optimize the composed query representation to capture the full intent of the composition or to align with the target semantics, thereby limiting retrieval performance, particularly in cases involving fine-grained or complex visual transformations. To address this problem, we propose MLLM-Guided VLM Fine-Tuning with Joint Inference (MVFT-JI), a novel approach that leverages a pretrained multimodal large language model (MLLM) to construct two complementary training tasks using only unlabeled images: target text retrieval taskand text-to-image retrieval task. By jointly optimizing these tasks, our method enables the VLM to inherently acquire robust compositional retrieval capabilities, supported by the provided theoretical justifications and empirical validation. Furthermore, during inference, we further prompt the MLLM to generate target texts from composed queries and compute retrieval scores by integrating similarities between (i) the composed query and candidate images, and (ii) the MLLM-generated target text and candidate images. This strategy effectively combines the VLM's semantic alignment strengths with the MLLM's reasoning capabilities.
Multimodal Reasoning Agent for Zero-Shot Composed Image Retrieval
May 26, 2025Zero-Shot Composed Image Retrieval (ZS-CIR) aims to retrieve target images given a compositional query, consisting of a reference image and a modifying text-without relying on annotated training data. Existing approaches often generate a synthetic target text using large language models (LLMs) to serve as an intermediate anchor between the compositional query and the target image. Models are then trained to align the compositional query with the generated text, and separately align images with their corresponding texts using contrastive learning. However, this reliance on intermediate text introduces error propagation, as inaccuracies in query-to-text and text-to-image mappings accumulate, ultimately degrading retrieval performance. To address these problems, we propose a novel framework by employing a Multimodal Reasoning Agent (MRA) for ZS-CIR. MRA eliminates the dependence on textual intermediaries by directly constructing triplets, <reference image, modification text, target image>, using only unlabeled image data. By training on these synthetic triplets, our model learns to capture the relationships between compositional queries and candidate images directly. Extensive experiments on three standard CIR benchmarks demonstrate the effectiveness of our approach. On the FashionIQ dataset, our method improves Average R@10 by at least 7.5\% over existing baselines; on CIRR, it boosts R@1 by 9.6\%; and on CIRCO, it increases mAP@5 by 9.5\%.
Refining Few-Step Text-to-Multiview Diffusion via Reinforcement Learning
May 26, 2025Text-to-multiview (T2MV) generation, which produces coherent multiview images from a single text prompt, remains computationally intensive, while accelerated T2MV methods using few-step diffusion models often sacrifice image fidelity and view consistency. To address this, we propose a novel reinforcement learning (RL) finetuning framework tailored for few-step T2MV diffusion models to jointly optimize per-view fidelity and cross-view consistency. Specifically, we first reformulate T2MV denoising across all views as a single unified Markov decision process, enabling multiview-aware policy optimization driven by a joint-view reward objective. Next, we introduce ZMV-Sampling, a test-time T2MV sampling technique that adds an inversion-denoising pass to reinforce both viewpoint and text conditioning, resulting in improved T2MV generation at the cost of inference time. To internalize its performance gains into the base sampling policy, we develop MV-ZigAL, a novel policy optimization strategy that uses reward advantages of ZMV-Sampling over standard sampling as learning signals for policy updates. Finally, noting that the joint-view reward objective under-optimizes per-view fidelity but naively optimizing single-view metrics neglects cross-view alignment, we reframe RL finetuning for T2MV diffusion models as a constrained optimization problem that maximizes per-view fidelity subject to an explicit joint-view constraint, thereby enabling more efficient and balanced policy updates. By integrating this constrained optimization paradigm with MV-ZigAL, we establish our complete RL finetuning framework, referred to as MVC-ZigAL, which effectively refines the few-step T2MV diffusion baseline in both fidelity and consistency while preserving its few-step efficiency.
R1-ShareVL: Incentivizing Reasoning Capability of Multimodal Large Language Models via Share-GRPO
May 22, 2025In this work, we aim to incentivize the reasoning ability of Multimodal Large Language Models (MLLMs) via reinforcement learning (RL) and develop an effective approach that mitigates the sparse reward and advantage vanishing issues during RL. To this end, we propose Share-GRPO, a novel RL approach that tackle these issues by exploring and sharing diverse reasoning trajectories over expanded question space. Specifically, Share-GRPO first expands the question space for a given question via data transformation techniques, and then encourages MLLM to effectively explore diverse reasoning trajectories over the expanded question space and shares the discovered reasoning trajectories across the expanded questions during RL. In addition, Share-GRPO also shares reward information during advantage computation, which estimates solution advantages hierarchically across and within question variants, allowing more accurate estimation of relative advantages and improving the stability of policy training. Extensive evaluations over six widely-used reasoning benchmarks showcase the superior performance of our method. Code will be available at https://github.com/HJYao00/R1-ShareVL.
FreshRetailNet-50K: A Stockout-Annotated Censored Demand Dataset for Latent Demand Recovery and Forecasting in Fresh Retail
May 22, 2025



Accurate demand estimation is critical for the retail business in guiding the inventory and pricing policies of perishable products. However, it faces fundamental challenges from censored sales data during stockouts, where unobserved demand creates systemic policy biases. Existing datasets lack the temporal resolution and annotations needed to address this censoring effect. To fill this gap, we present FreshRetailNet-50K, the first large-scale benchmark for censored demand estimation. It comprises 50,000 store-product time series of detailed hourly sales data from 898 stores in 18 major cities, encompassing 863 perishable SKUs meticulously annotated for stockout events. The hourly stock status records unique to this dataset, combined with rich contextual covariates, including promotional discounts, precipitation, and temporal features, enable innovative research beyond existing solutions. We demonstrate one such use case of two-stage demand modeling: first, we reconstruct the latent demand during stockouts using precise hourly annotations. We then leverage the recovered demand to train robust demand forecasting models in the second stage. Experimental results show that this approach achieves a 2.73\% improvement in prediction accuracy while reducing the systematic demand underestimation from 7.37\% to near-zero bias. With unprecedented temporal granularity and comprehensive real-world information, FreshRetailNet-50K opens new research directions in demand imputation, perishable inventory optimization, and causal retail analytics. The unique annotation quality and scale of the dataset address long-standing limitations in retail AI, providing immediate solutions and a platform for future methodological innovation. The data (https://huggingface.co/datasets/Dingdong-Inc/FreshRetailNet-50K) and code (https://github.com/Dingdong-Inc/frn-50k-baseline}) are openly released.
R1-Compress: Long Chain-of-Thought Compression via Chunk Compression and Search
May 22, 2025Chain-of-Thought (CoT) reasoning enhances large language models (LLMs) by enabling step-by-step problem-solving, yet its extension to Long-CoT introduces substantial computational overhead due to increased token length. Existing compression approaches -- instance-level and token-level -- either sacrifice essential local reasoning signals like reflection or yield incoherent outputs. To address these limitations, we propose R1-Compress, a two-stage chunk-level compression framework that preserves both local information and coherence. Our method segments Long-CoT into manageable chunks, applies LLM-driven inner-chunk compression, and employs an inter-chunk search mechanism to select the short and coherent sequence. Experiments on Qwen2.5-Instruct models across MATH500, AIME24, and GPQA-Diamond demonstrate that R1-Compress significantly reduces token usage while maintaining comparable reasoning accuracy. On MATH500, R1-Compress achieves an accuracy of 92.4%, with only a 0.6% drop compared to the Long-CoT baseline, while reducing token usage by about 20%. Source code will be available at https://github.com/w-yibo/R1-Compress