 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Disaggregated Multi-Stage MLLM Inference via GPU-Internal Scheduling and Resource Sharing
Dec 19, 2025Multimodal large language models (MLLMs) extend LLMs with visual understanding through a three-stage pipeline: multimodal preprocessing, vision encoding, and LLM inference. While these stages enhance capability, they introduce significant system bottlenecks. First, multimodal preprocessing-especially video decoding-often dominates Time-to-First-Token (TTFT). Most systems rely on CPU-based decoding, which severely limits throughput, while existing GPU-based approaches prioritize throughput-oriented parallelism and fail to meet the latency-sensitive requirements of MLLM inference. Second, the vision encoder is a standalone, compute-intensive stage that produces visual embeddings and cannot be co-batched with LLM prefill or decoding. This heterogeneity forces inter-stage blocking and increases token-generation latency. Even when deployed on separate GPUs, these stages underutilize available compute and memory resources, reducing overall utilization and constraining system throughput. To address these challenges, we present FlashCodec and UnifiedServe, two complementary designs that jointly optimize the end-to-end MLLM pipeline. FlashCodec accelerates the multimodal preprocessing stage through collaborative multi-GPU video decoding, reducing decoding latency while preserving high throughput. UnifiedServe optimizes the vision-to-text and inference stages using a logically decoupled their execution to eliminate inter-stage blocking, yet physically sharing GPU resources to maximize GPU system utilization. By carefully orchestrating execution across stages and minimizing interference, UnifiedServe Together, our proposed framework forms an end-to-end optimized stack that can serve up to 3.0$\times$ more requests or enforce 1.5$\times$ tighter SLOs, while achieving up to 4.4$\times$ higher throughput compared to state-of-the-art systems.
REMISVFU: Vertical Federated Unlearning via Representation Misdirection for Intermediate Output Feature
Dec 11, 2025



Data-protection regulations such as the GDPR grant every participant in a federated system a right to be forgotten. Federated unlearning has therefore emerged as a research frontier, aiming to remove a specific party's contribution from the learned model while preserving the utility of the remaining parties. However, most unlearning techniques focus on Horizontal Federated Learning (HFL), where data are partitioned by samples. In contrast, Vertical Federated Learning (VFL) allows organizations that possess complementary feature spaces to train a joint model without sharing raw data. The resulting feature-partitioned architecture renders HFL-oriented unlearning methods ineffective. In this paper, we propose REMISVFU, a plug-and-play representation misdirection framework that enables fast, client-level unlearning in splitVFL systems. When a deletion request arrives, the forgetting party collapses its encoder output to a randomly sampled anchor on the unit sphere, severing the statistical link between its features and the global model. To maintain utility for the remaining parties, the server jointly optimizes a retention loss and a forgetting loss, aligning their gradients via orthogonal projection to eliminate destructive interference. Evaluations on public benchmarks show that REMISVFU suppresses back-door attack success to the natural class-prior level and sacrifices only about 2.5% points of clean accuracy, outperforming state-of-the-art baselines.
Diversifying the Mixture-of-Experts Representation for Language Models with Orthogonal Optimizer
Oct 15, 2023The Mixture of Experts (MoE) has emerged as a highly successful technique in deep learning, based on the principle of divide-and-conquer to maximize model capacity without significant additional computational cost. Even in the era of large-scale language models (LLMs), MoE continues to play a crucial role, as some researchers have indicated that GPT-4 adopts the MoE structure to ensure diverse inference results. However, MoE is susceptible to performance degeneracy, particularly evident in the issues of imbalance and homogeneous representation among experts. While previous studies have extensively addressed the problem of imbalance, the challenge of homogeneous representation remains unresolved. In this study, we shed light on the homogeneous representation problem, wherein experts in the MoE fail to specialize and lack diversity, leading to frustratingly high similarities in their representations (up to 99% in a well-performed MoE model). This problem restricts the expressive power of the MoE and, we argue, contradicts its original intention. To tackle this issue, we propose a straightforward yet highly effective solution: OMoE, an orthogonal expert optimizer. Additionally, we introduce an alternating training strategy that encourages each expert to update in a direction orthogonal to the subspace spanned by other experts. Our algorithm facilitates MoE training in two key ways: firstly, it explicitly enhances representation diversity, and secondly, it implicitly fosters interaction between experts during orthogonal weights computation. Through extensive experiments, we demonstrate that our proposed optimization algorithm significantly improves the performance of fine-tuning the MoE model on the GLUE benchmark, SuperGLUE benchmark, question-answering task, and name entity recognition tasks.
BLISS: Robust Sequence-to-Sequence Learning via Self-Supervised Input Representation
Apr 24, 2022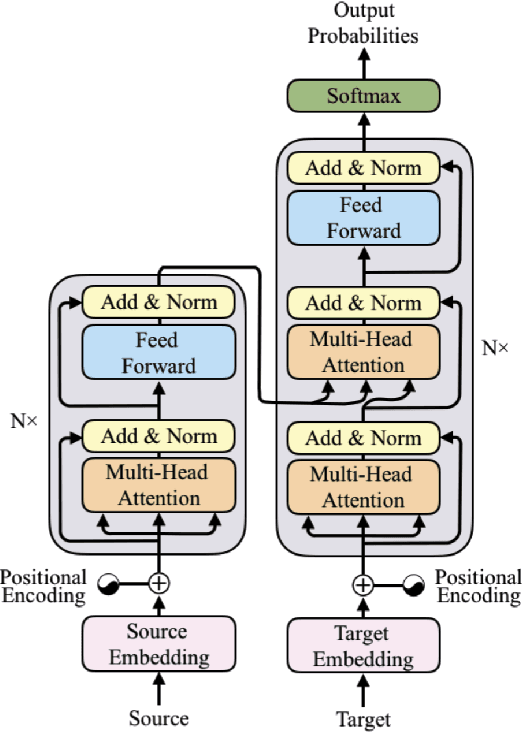
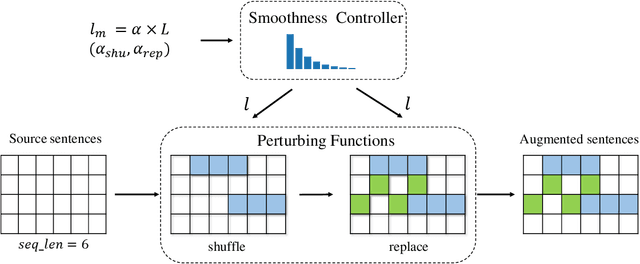
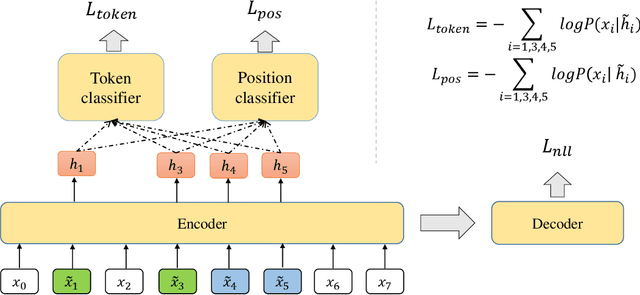
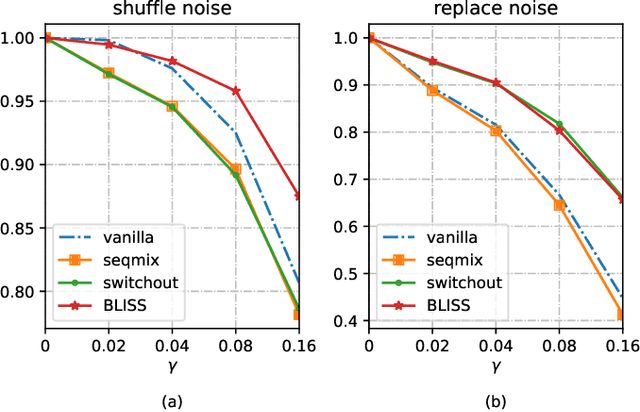
Data augmentations (DA) are the cores to achieving robust sequence-to-sequence learning on various natural language processing (NLP) tasks. However, most of the DA approaches force the decoder to make predictions conditioned on the perturbed input representation, underutilizing supervised information provided by perturbed input. In this work, we propose a framework-level robust sequence-to-sequence learning approach, named BLISS, via self-supervised input representation, which has the great potential to complement the data-level augmentation approaches. The key idea is to supervise the sequence-to-sequence framework with both the \textit{supervised} ("input$\rightarrow$output") and \textit{self-supervised} ("perturbed input$\rightarrow$input") information. We conduct comprehensive experiments to validate the effectiveness of BLISS on various tasks, including machine translation, grammatical error correction, and text summarization. The results show that BLISS outperforms significantly the vanilla Transformer and consistently works well across tasks than the other five contrastive baselines. Extensive analyses reveal that BLISS learns robust representations and rich linguistic knowledge, confirming our claim. Source code will be released upon publication.