 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Transformer V2: Grouped Vector Attention and Partition-based Pooling
Oct 12, 2022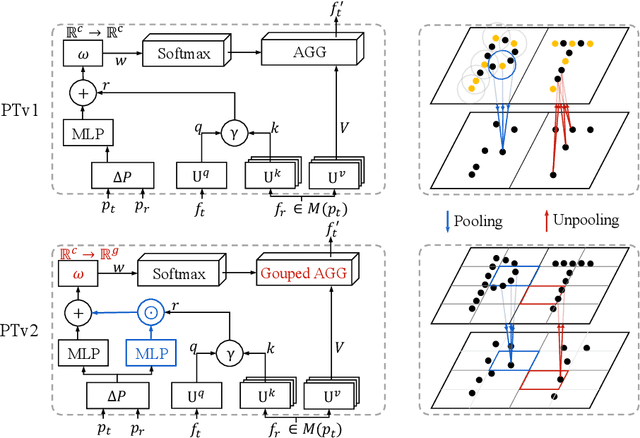
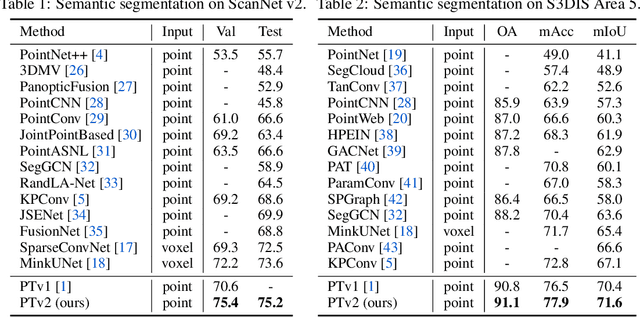


As a pioneering work exploring transformer architecture for 3D point cloud understanding, Point Transformer achieves impressive results on multiple highly competitive benchmarks. In this work, we analyze the limitations of the Point Transformer and propose our powerful and efficient Point Transformer V2 model with novel designs that overcome the limitations of previous work. In particular, we first propose group vector attention, which is more effective than the previous version of vector attention. Inheriting the advantages of both learnable weight encoding and multi-head attention, we present a highly effective implementation of grouped vector attention with a novel grouped weight encoding layer. We also strengthen the position information for attention by an additional position encoding multiplier. Furthermore, we design novel and lightweight partition-based pooling methods which enable better spatial alignment and more efficient sampling. Extensive experiments show that our model achieves better performance than its predecessor and achieves state-of-the-art on several challenging 3D point cloud understanding benchmarks, including 3D point cloud segmentation on ScanNet v2 and S3DIS and 3D point cloud classification on ModelNet40. Our code will be available at https://github.com/Gofinge/PointTransformerV2.
Motion Transformer with Global Intention Localization and Local Movement Refinement
Sep 27, 2022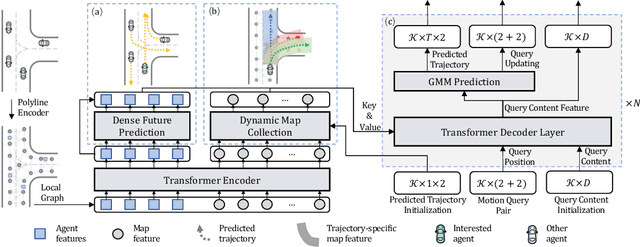
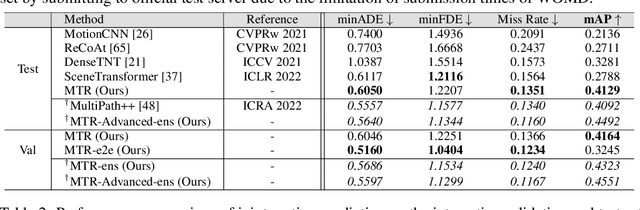
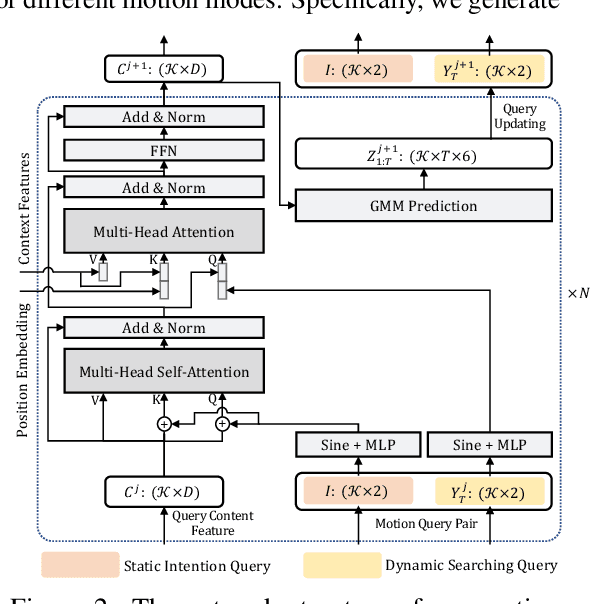
Predicting multimodal future behavior of traffic participants is essential for robotic vehicles to make safe decisions. Existing works explore to directly predict future trajectories based on latent features or utilize dense goal candidates to identify agent's destinations, where the former strategy converges slowly since all motion modes are derived from the same feature while the latter strategy has efficiency issue since its performance highly relies on the density of goal candidates. In this paper, we propose Motion TRansformer (MTR) framework that models motion prediction as the joint optimization of global intention localization and local movement refinement. Instead of using goal candidates, MTR incorporates spatial intention priors by adopting a small set of learnable motion query pairs. Each motion query pair takes charge of trajectory prediction and refinement for a specific motion mode, which stabilizes the training process and facilitates better multimodal predictions. Experiments show that MTR achieves state-of-the-art performance on both the marginal and joint motion prediction challenges, ranking 1st on the leaderboards of Waymo Open Motion Dataset. Code will be available at https://github.com/sshaoshuai/MTR.
MTR-A: 1st Place Solution for 2022 Waymo Open Dataset Challenge -- Motion Prediction
Sep 20, 2022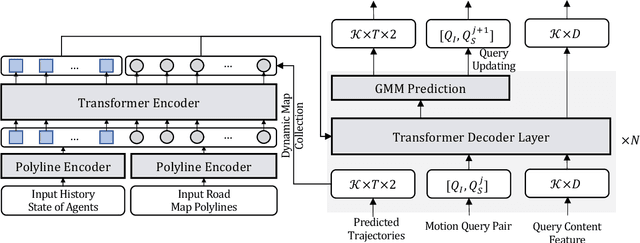
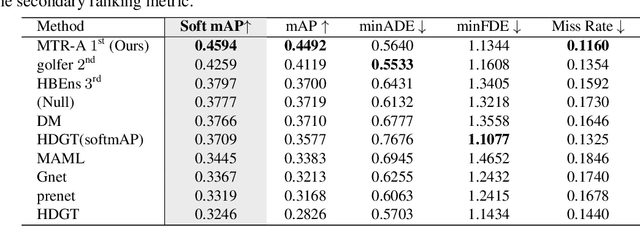
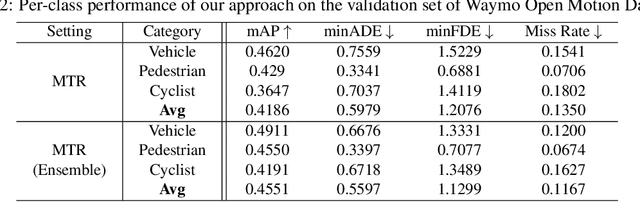
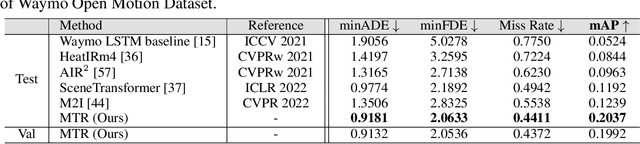
In this report, we present the 1st place solution for motion prediction track in 2022 Waymo Open Dataset Challenges. We propose a novel Motion Transformer framework for multimodal motion prediction, which introduces a small set of novel motion query pairs for generating better multimodal future trajectories by jointly performing the intention localization and iterative motion refinement. A simple model ensemble strategy with non-maximum-suppression is adopted to further boost the final performance. Our approach achieves the 1st place on the motion prediction leaderboard of 2022 Waymo Open Dataset Challenges, outperforming other methods with remarkable margins. Code will be available at https://github.com/sshaoshuai/MTR.
SuperVessel: Segmenting High-resolution Vessel from Low-resolution Retinal Image
Jul 28, 2022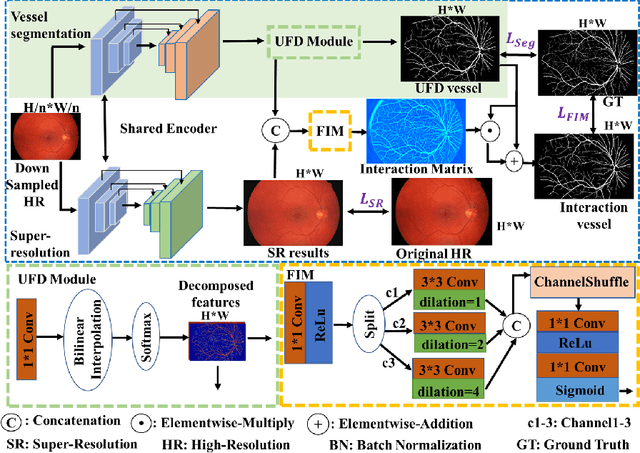
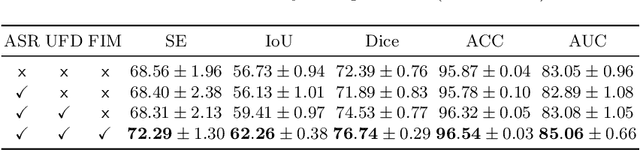
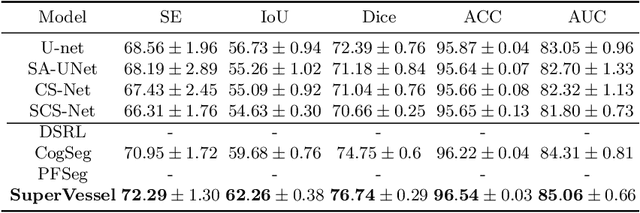
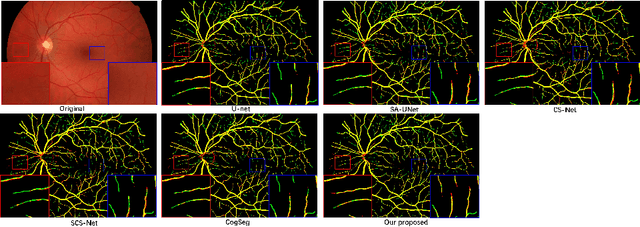
Vascular segmentation extracts blood vessels from images and serves as the basis for diagnosing various diseases, like ophthalmic diseases. Ophthalmologists often require high-resolution segmentation results for analysis, which leads to super-computational load by most existing methods. If based on low-resolution input, they easily ignore tiny vessels or cause discontinuity of segmented vessels. To solve these problems, the paper proposes an algorithm named SuperVessel, which gives out high-resolution and accurate vessel segmentation using low-resolution images as input. We first take super-resolution as our auxiliary branch to provide potential high-resolution detail features, which can be deleted in the test phase. Secondly, we propose two modules to enhance the features of the interested segmentation region, including an upsampling with feature decomposition (UFD) module and a feature interaction module (FIM) with a constraining loss to focus on the interested features. Extensive experiments on three publicly available datasets demonstrate that our proposed SuperVessel can segment more tiny vessels with higher segmentation accuracy IoU over 6%, compared with other state-of-the-art algorithms. Besides, the stability of SuperVessel is also stronger than other algorithms. We will release the code after the paper is published.
Boosting Single-Frame 3D Object Detection by Simulating Multi-Frame Point Clouds
Jul 12, 2022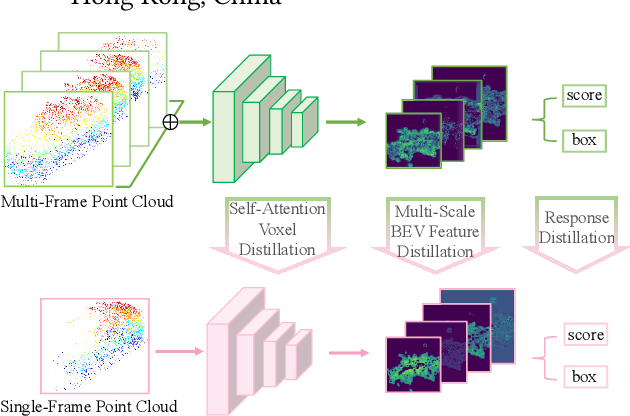
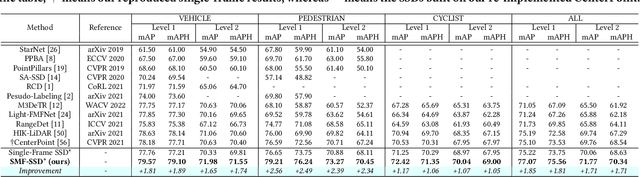
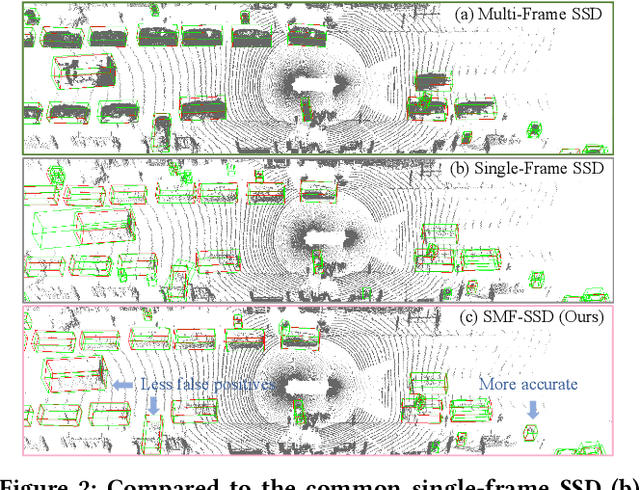
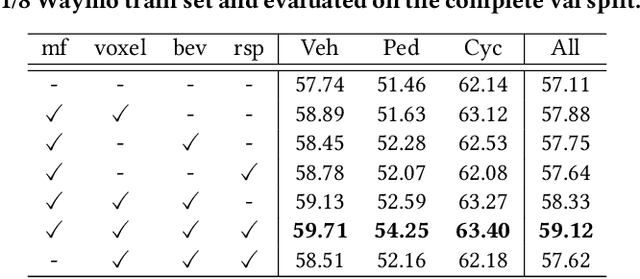
To boost a detector for single-frame 3D object detection, we present a new approach to train it to simulate features and responses following a detector trained on multi-frame point clouds. Our approach needs multi-frame point clouds only when training the single-frame detector, and once trained, it can detect objects with only single-frame point clouds as inputs during the inference. We design a novel Simulated Multi-Frame Single-Stage object Detector (SMF-SSD) framework to realize the approach: multi-view dense object fusion to densify ground-truth objects to generate a multi-frame point cloud; self-attention voxel distillation to facilitate one-to-many knowledge transfer from multi- to single-frame voxels; multi-scale BEV feature distillation to transfer knowledge in low-level spatial and high-level semantic BEV features; and adaptive response distillation to activate single-frame responses of high confidence and accurate localization. Experimental results on the Waymo test set show that our SMF-SSD consistently outperforms all state-of-the-art single-frame 3D object detectors for all object classes of difficulty levels 1 and 2 in terms of both mAP and mAPH.
Boosting 3D Object Detection by Simulating Multimodality on Point Clouds
Jun 30, 2022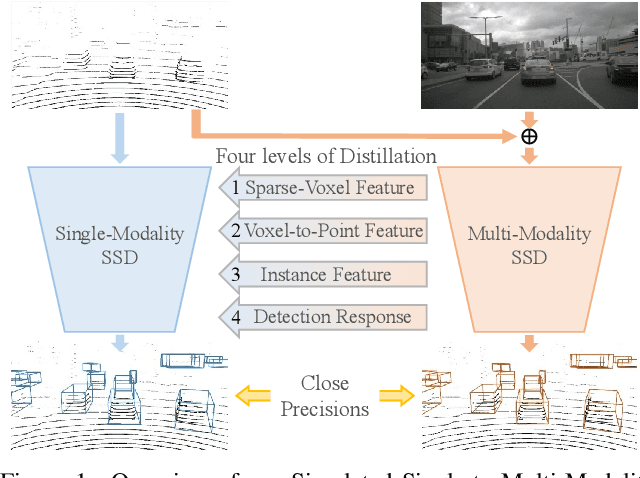


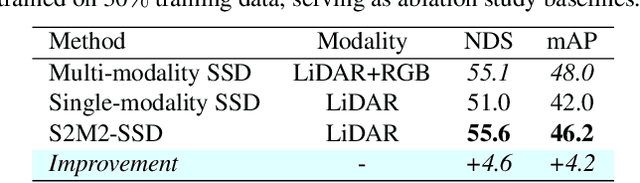
This paper presents a new approach to boost a single-modality (LiDAR) 3D object detector by teaching it to simulate features and responses that follow a multi-modality (LiDAR-image) detector. The approach needs LiDAR-image data only when training the single-modality detector, and once well-trained, it only needs LiDAR data at inference. We design a novel framework to realize the approach: response distillation to focus on the crucial response samples and avoid the background samples; sparse-voxel distillation to learn voxel semantics and relations from the estimated crucial voxels; a fine-grained voxel-to-point distillation to better attend to features of small and distant objects; and instance distillation to further enhance the deep-feature consistency. Experimental results on the nuScenes dataset show that our approach outperforms all SOTA LiDAR-only 3D detectors and even surpasses the baseline LiDAR-image detector on the key NDS metric, filling 72% mAP gap between the single- and multi-modality detectors.
Global Mixup: Eliminating Ambiguity with Clustering
Jun 06, 2022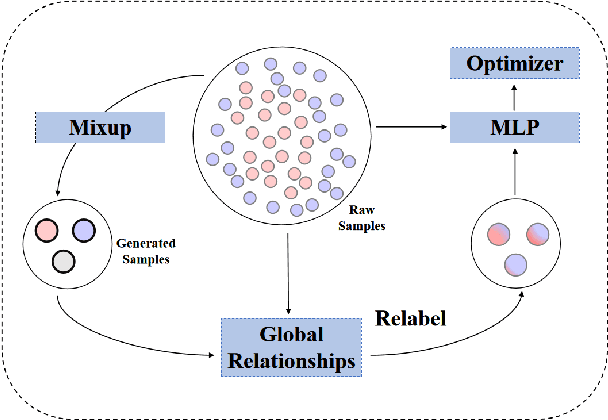
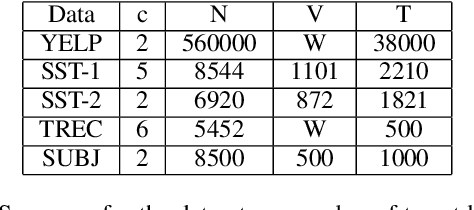
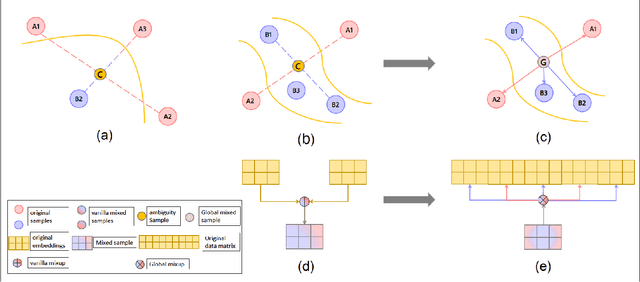
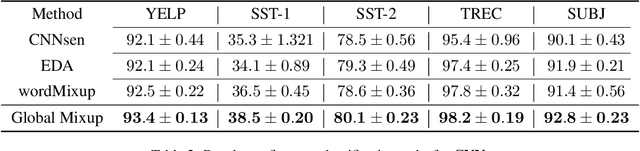
Data augmentation with \textbf{Mixup} has been proven an effective method to regularize the current deep neural networks. Mixup generates virtual samples and corresponding labels at once through linear interpolation. However, this one-stage generation paradigm and the use of linear interpolation have the following two defects: (1) The label of the generated sample is directly combined from the labels of the original sample pairs without reasonable judgment, which makes the labels likely to be ambiguous. (2) linear combination significantly limits the sampling space for generating samples. To tackle these problems, we propose a novel and effective augmentation method based on global clustering relationships named \textbf{Global Mixup}. Specifically, we transform the previous one-stage augmentation process into two-stage, decoupling the process of generating virtual samples from the labeling. And for the labels of the generated samples, relabeling is performed based on clustering by calculating the global relationships of the generated samples. In addition, we are no longer limited to linear relationships but generate more reliable virtual samples in a larger sampling space. Extensive experiments for \textbf{CNN}, \textbf{LSTM}, and \textbf{BERT} on five tasks show that Global Mixup significantly outperforms previous state-of-the-art baselines. Further experiments also demonstrate the advantage of Global Mixup in low-resource scenarios.
i-MYO: A Hybrid Prosthetic Hand Control System based on Eye-tracking, Augmented Reality and Myoelectric signal
May 18, 2022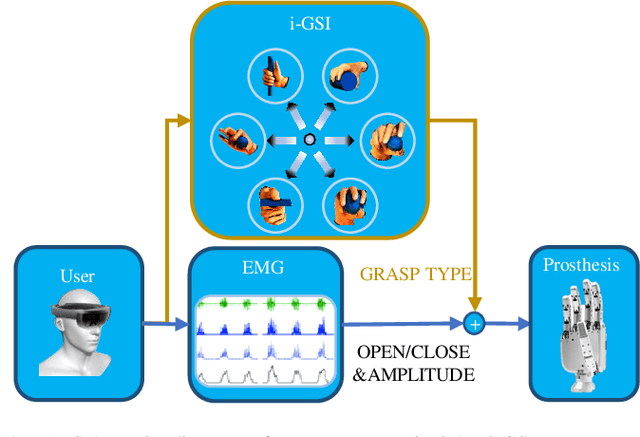
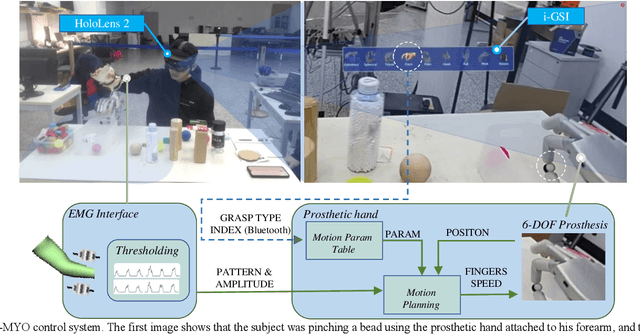
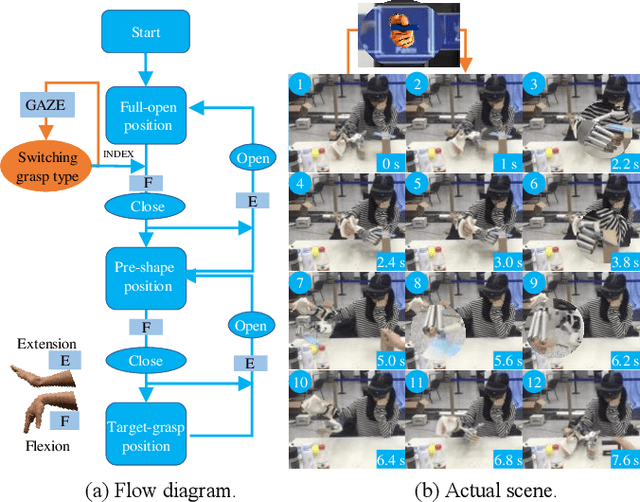
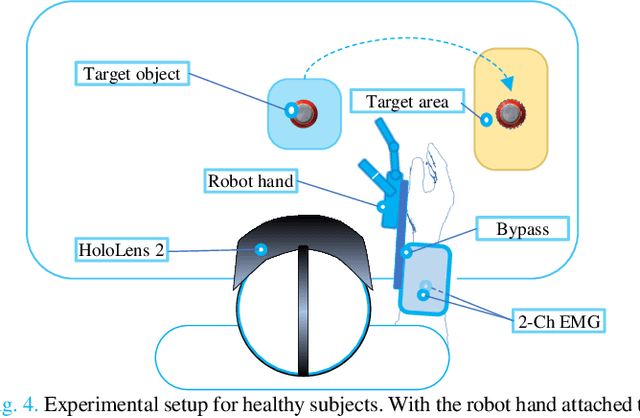
Dexterous prosthetic hands have better grasp performance than traditional ones. However, patients still find it difficult to use these hands without a suitable control system. A new hybrid myoelectric control system, termed i-MYO, is presented and evaluated to solve this problem. The core component of the i-MYO is a novel grasp-type switching interface based on eye-tracking and augmented reality (AR), termed i-GSI. With the i-GSI, the user can easily switch a grasp type (six total) for a prosthetic hand by gazing at a GazeButton. The i-GSI is implemented in an AR helmet and is integrated, as an individual module, into the i-MYO system. In the i-MYO system, the myoelectric signal was used to control hand opening /closing proportionally. The operation of the i-MYO was tested on nine healthy subjects who wore HIT-V hand on the forearm and manipulated objects in a reach-and-grasp task. It was also tested on one patient who had an inferior myoelectric signal and was required to control the HIT-V hand to grasp objects. Results showed that in 91.6% of the trials, inexperienced healthy subjects accomplished the task within 5.9 s, and most failed trials were caused by a lack of experience in fine grasping. In addition, in about 1.5% of trials, the subjects also successfully transferred the objects but with a non-optimal grasp type. In 97.0% of the trials, the subjects spent ~1.3 s switching the optimal grasp types. A higher success rate in grasp type (99.1%) for the untrained patient has been observed thanks to more trials conducted. In 98.7 % of trials, the patient only needed another 2 s to control the hand to grasp the object after switching to the optimal grasp type. The tests demonstrate the control capability of the new system in multi-DOF prosthetics, and all inexperienced subjects were able to master the operation of the i-MYO quickly within a few pieces of training and apply it easily.
DODA: Data-oriented Sim-to-Real Domain Adaptation for 3D Indoor Semantic Segmentation
Apr 04, 2022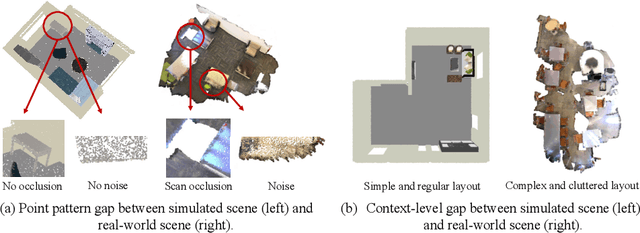
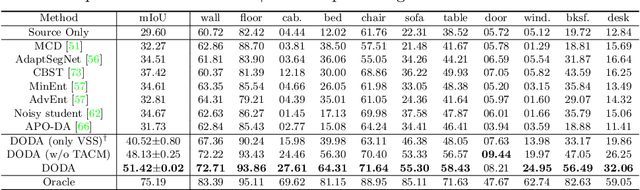
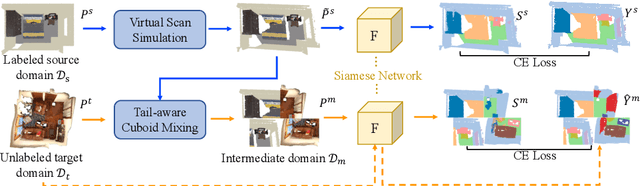
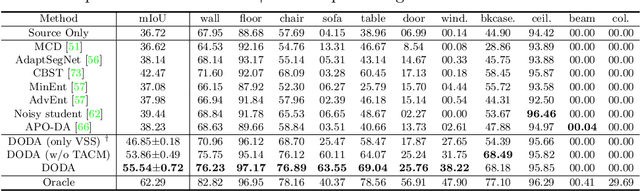
Deep learning approaches achieve prominent success in 3D semantic segmentation. However, collecting densely annotated real-world 3D datasets is extremely time-consuming and expensive. Training models on synthetic data and generalizing on real-world scenarios becomes an appealing alternative, but unfortunately suffers from notorious domain shifts. In this work, we propose a Data-Oriented Domain Adaptation (DODA) framework to mitigate pattern and context gaps caused by different sensing mechanisms and layout placements across domains. Our DODA encompasses virtual scan simulation to imitate real-world point cloud patterns and tail-aware cuboid mixing to alleviate the interior context gap with a cuboid-based intermediate domain. The first unsupervised sim-to-real adaptation benchmark on 3D indoor semantic segmentation is also built on 3D-FRONT, ScanNet and S3DIS along with 7 popular Unsupervised Domain Adaptation (UDA) methods. Our DODA surpasses existing UDA approaches by over 13% on both 3D-FRONT $\rightarrow$ ScanNet and 3D-FRONT $\rightarrow$ S3DIS. Code will be available.
Stratified Transformer for 3D Point Cloud Segmentation
Mar 28, 2022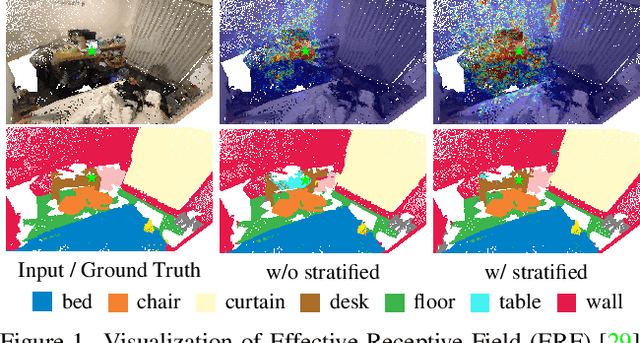
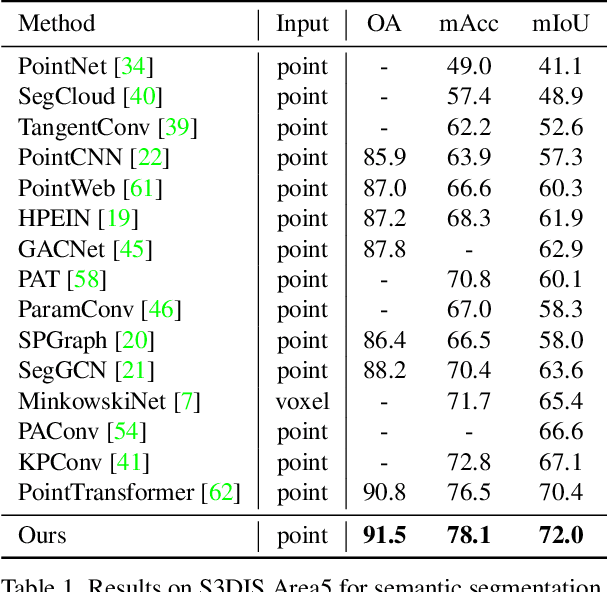
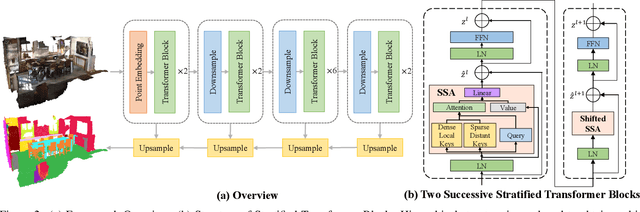
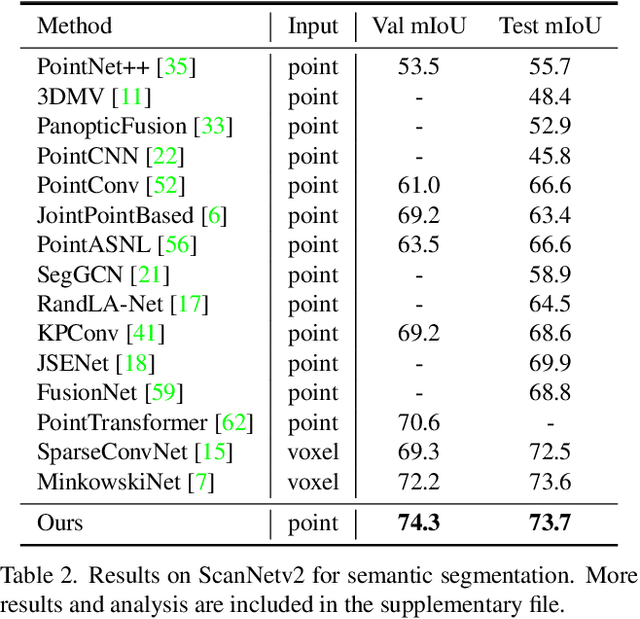
3D point cloud segmentation has made tremendous progress in recent years. Most current methods focus on aggregating local features, but fail to directly model long-range dependencies. In this paper, we propose Stratified Transformer that is able to capture long-range contexts and demonstrates strong generalization ability and high performance. Specifically, we first put forward a novel key sampling strategy. For each query point, we sample nearby points densely and distant points sparsely as its keys in a stratified way, which enables the model to enlarge the effective receptive field and enjoy long-range contexts at a low computational cost. Also, to combat the challenges posed by irregular point arrangements, we propose first-layer point embedding to aggregate local information, which facilitates convergence and boosts performance. Besides, we adopt contextual relative position encoding to adaptively capture position information. Finally, a memory-efficient implementation is introduced to overcome the issue of varying point numbers in each window. Extensive experiments demonstrate the effectiveness and superiority of our method on S3DIS, ScanNetv2 and ShapeNetPart datasets. Code is available at https://github.com/dvlab-research/Stratified-Transformer.