 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Blind but Silenced: Rebalancing Vision and Language via Adversarial Counter-Commonsense Equilibrium
May 11, 2026During MLLM decoding, attention often abnormally concentrates on irrelevant image tokens. While existing research dismisses this as invalid noise and forcibly redirects attention to compel focusing on key image information, we argue these tokens are critical carriers of visual and narrative logic, and such coercive corrections exacerbate visual-language imbalance. Adopting a "decoding-as-game" perspective, we reveal that hallucinations stem from an equilibrium imbalance between linguistic priors and visual information. We propose Adversarial Counter-Commonsense Equilibrium (ACE), a training-free framework that perturbs visual context via counter-commonsense patches. Leveraging the fact that authentic visual features remain stable under perturbation while hallucinations fluctuate, ACE implements a dynamic game decoding strategy. This approach precisely suppresses perturbation-sensitive priors while compensating for stable visual signals to restore balance. Extensive experiments demonstrate that ACE, as a plug-and-play strategy, enhances model trustworthiness with negligible inference overhead.
Bridging Reasoning and Action: Hybrid LLM-RL Framework for Efficient Cross-Domain Task-Oriented Dialogue
Apr 25, 2026Cross-domain task-oriented dialogue requires reasoning over implicit and explicit feasibility constraints while planning long-horizon, multi-turn actions. Large language models (LLMs) can infer such constraints but are unreliable over long horizons, while Reinforcement learning (RL) optimizes long-horizon behavior yet cannot recover constraints from raw dialogue. Naively coupling LLMs with RL is therefore brittle: unverified or unstructured LLM outputs can corrupt state representations and misguide policy learning. Motivated by this, we propose Verified LLM-Knowledge empowered RL (VLK-RL), a hybrid framework that makes LLM-derived constraint reasoning usable for RL. VLK-RL first elicits candidate constraints with an LLM and then verifies them via a dual-role cross-examination procedure to suppress hallucinations and cross-turn inconsistencies. The verified constraints are mapped into ontology-aligned slot-value representations, yielding a structured, constraint-aware state for RL policy optimization. Experiments across multiple benchmarks demonstrate that VLK-RL significantly improves generalization and robustness, outperforming strong single-model baselines on long-horizon tasks.
3DTCR: A Physics-Based Generative Framework for Vortex-Following 3D Reconstruction to Improve Tropical Cyclone Intensity Forecasting
Mar 16, 2026Tropical cyclone (TC) intensity forecasting remains challenging as current numerical and AI-based weather models fail to satisfactorily represent extreme TC structure and intensity. Although intensity time-series forecasting has achieved significant advances, it outputs intensity sequences rather than the three-dimensional inner-core fine-scale structure and physical mechanisms governing TC evolution. High-resolution numerical simulations can capture these features but remain computationally expensive and inefficient for large-scale operational applications. Here we present 3DTCR, a physics-based generative framework combining physical constraints with generative AI efficiency for 3D TC structure reconstruction. Trained on a six-year, 3-km-resolution moving-domain WRF dataset, 3DTCR enables region-adaptive vortex-following reconstruction using conditional Flow Matching(CFM), optimized via latent domain adaptation and two-stage transfer learning. The framework mitigates limitations imposed by low-resolution targets and over-smoothed forecasts, improving the representation of TC inner-core structure and intensity while maintaining track stability. Results demonstrate that 3DTCR outperforms the ECMWF high-resolution forecasting system (ECMWF-HRES) in TC intensity prediction at nearly all lead times up to 5 days and reduces the RMSE of maximum WS10M by 36.5% relative to its FuXi inputs. These findings highlight 3DTCR as a physics-based generative framework that efficiently resolves fine-scale structures at lower computational cost, which may offer a promising avenue for improving TC intensity forecasting.
Rescue Conversations from Dead-ends: Efficient Exploration for Task-oriented Dialogue Policy Optimization
May 05, 2023Training a dialogue policy using deep reinforcement learning requires a lot of exploration of the environment. The amount of wasted invalid exploration makes their learning inefficient. In this paper, we find and define an important reason for the invalid exploration: dead-ends. When a conversation enters a dead-end state, regardless of the actions taken afterward, it will continue in a dead-end trajectory until the agent reaches a termination state or maximum turn. We propose a dead-end resurrection (DDR) algorithm that detects the initial dead-end state in a timely and efficient manner and provides a rescue action to guide and correct the exploration direction. To prevent dialogue policies from repeatedly making the same mistake, DDR also performs dialogue data augmentation by adding relevant experiences containing dead-end states. We first validate the dead-end detection reliability and then demonstrate the effectiveness and generality of the method by reporting experimental results on several dialogue datasets from different domains.
Automatic Curriculum Learning With Over-repetition Penalty for Dialogue Policy Learning
Dec 28, 2020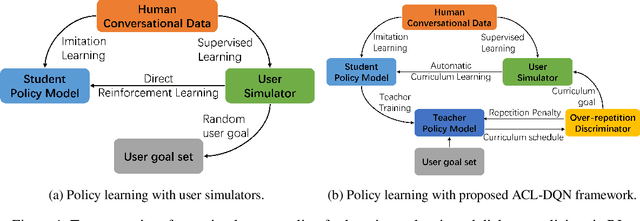

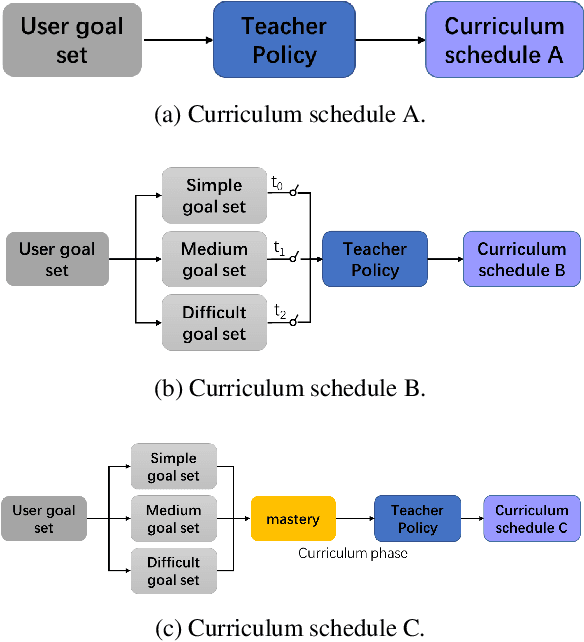
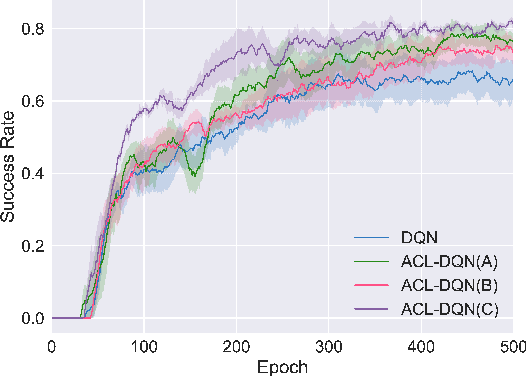
Dialogue policy learning based on reinforcement learning is difficult to be applied to real users to train dialogue agents from scratch because of the high cost. User simulators, which choose random user goals for the dialogue agent to train on, have been considered as an affordable substitute for real users. However, this random sampling method ignores the law of human learning, making the learned dialogue policy inefficient and unstable. We propose a novel framework, Automatic Curriculum Learning-based Deep Q-Network (ACL-DQN), which replaces the traditional random sampling method with a teacher policy model to realize the dialogue policy for automatic curriculum learning. The teacher model arranges a meaningful ordered curriculum and automatically adjusts it by monitoring the learning progress of the dialogue agent and the over-repetition penalty without any requirement of prior knowledge. The learning progress of the dialogue agent reflects the relationship between the dialogue agent's ability and the sampled goals' difficulty for sample efficiency. The over-repetition penalty guarantees the sampled diversity. Experiments show that the ACL-DQN significantly improves the effectiveness and stability of dialogue tasks with a statistically significant margin. Furthermore, the framework can be further improved by equipping with different curriculum schedules, which demonstrates that the framework has strong generalizability.