 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-FPAN: Semi-Supervised Face Parsing in the Wild With De-Occlusion and UV GAN
Dec 18, 2022



Fine-grained semantic segmentation of a person's face and head, including facial parts and head components, has progressed a great deal in recent years. However, it remains a challenging task, whereby considering ambiguous occlusions and large pose variations are particularly difficult. To overcome these difficulties, we propose a novel framework termed Mask-FPAN. It uses a de-occlusion module that learns to parse occluded faces in a semi-supervised way. In particular, face landmark localization, face occlusionstimations, and detected head poses are taken into account. A 3D morphable face model combined with the UV GAN improves the robustness of 2D face parsing. In addition, we introduce two new datasets named FaceOccMask-HQ and CelebAMaskOcc-HQ for face paring work. The proposed Mask-FPAN framework addresses the face parsing problem in the wild and shows significant performance improvements with MIOU from 0.7353 to 0.9013 compared to the state-of-the-art on challenging face datasets.
LR-CSNet: Low-Rank Deep Unfolding Network for Image Compressive Sensing
Dec 18, 2022



Deep unfolding networks (DUNs) have proven to be a viable approach to compressive sensing (CS). In this work, we propose a DUN called low-rank CS network (LR-CSNet) for natural image CS. Real-world image patches are often well-represented by low-rank approximations. LR-CSNet exploits this property by adding a low-rank prior to the CS optimization task. We derive a corresponding iterative optimization procedure using variable splitting, which is then translated to a new DUN architecture. The architecture uses low-rank generation modules (LRGMs), which learn low-rank matrix factorizations, as well as gradient descent and proximal mappings (GDPMs), which are proposed to extract high-frequency features to refine image details. In addition, the deep features generated at each reconstruction stage in the DUN are transferred between stages to boost the performance. Our extensive experiments on three widely considered datasets demonstrate the promising performance of LR-CSNet compared to state-of-the-art methods in natural image CS.
Pre-trained Language Models can be Fully Zero-Shot Learners
Dec 14, 2022



How can we extend a pre-trained model to many language understanding tasks, without labeled or additional unlabeled data? Pre-trained language models (PLMs) have been effective for a wide range of NLP tasks. However, existing approaches either require fine-tuning on downstream labeled datasets or manually constructing proper prompts. In this paper, we propose nonparametric prompting PLM (NPPrompt) for fully zero-shot language understanding. Unlike previous methods, NPPrompt uses only pre-trained language models and does not require any labeled data or additional raw corpus for further fine-tuning, nor does it rely on humans to construct a comprehensive set of prompt label words. We evaluate NPPrompt against previous major few-shot and zero-shot learning methods on diverse NLP tasks: including text classification, text entailment, similar text retrieval, and paraphrasing. Experimental results demonstrate that our NPPrompt outperforms the previous best fully zero-shot method by big margins, with absolute gains of 12.8% in accuracy on text classification and 18.9% on the GLUE benchmark.
Converge to the Truth: Factual Error Correction via Iterative Constrained Editing
Dec 02, 2022



Given a possibly false claim sentence, how can we automatically correct it with minimal editing? Existing methods either require a large number of pairs of false and corrected claims for supervised training or do not handle well errors spanning over multiple tokens within an utterance. In this paper, we propose VENCE, a novel method for factual error correction (FEC) with minimal edits. VENCE formulates the FEC problem as iterative sampling editing actions with respect to a target density function. We carefully design the target function with predicted truthfulness scores from an offline trained fact verification model. VENCE samples the most probable editing positions based on back-calculated gradients of the truthfulness score concerning input tokens and the editing actions using a distantly-supervised language model (T5). Experiments on a public dataset show that VENCE improves the well-adopted SARI metric by 5.3 (or a relative improvement of 11.8%) over the previous best distantly-supervised methods.
Accelerating Antimicrobial Peptide Discovery with Latent Sequence-Structure Model
Nov 28, 2022



Antimicrobial peptide (AMP) is a promising therapy in the treatment of broad-spectrum antibiotics and drug-resistant infections. Recently, an increasing number of researchers have been introducing deep generative models to accelerate AMP discovery. However, current studies mainly focus on sequence attributes and ignore structure information, which is important in AMP biological functions. In this paper, we propose a latent sequence-structure model for AMPs (LSSAMP) with multi-scale VQ-VAE to incorporate secondary structures. By sampling in the latent space, LSSAMP can simultaneously generate peptides with ideal sequence attributes and secondary structures. Experimental results show that the peptides generated by LSSAMP have a high probability of AMP, and two of the 21 candidates have been verified to have good antimicrobial activity. Our model will be released to help create high-quality AMP candidates for follow-up biological experiments and accelerate the whole AMP discovery.
On Analyzing the Role of Image for Visual-enhanced Relation Extraction
Nov 14, 2022



Multimodal relation extraction is an essential task for knowledge graph construction. In this paper, we take an in-depth empirical analysis that indicates the inaccurate information in the visual scene graph leads to poor modal alignment weights, further degrading performance. Moreover, the visual shuffle experiments illustrate that the current approaches may not take full advantage of visual information. Based on the above observation, we further propose a strong baseline with an implicit fine-grained multimodal alignment based on Transformer for multimodal relation extraction. Experimental results demonstrate the better performance of our method. Codes are available at https://github.com/zjunlp/DeepKE/tree/main/example/re/multimodal.
MyoPS-Net: Myocardial Pathology Segmentation with Flexible Combination of Multi-Sequence CMR Images
Nov 06, 2022



Myocardial pathology segmentation (MyoPS) can be a prerequisite for the accurate diagnosis and treatment planning of myocardial infarction. However, achieving this segmentation is challenging, mainly due to the inadequate and indistinct information from an image. In this work, we develop an end-to-end deep neural network, referred to as MyoPS-Net, to flexibly combine five-sequence cardiac magnetic resonance (CMR) images for MyoPS. To extract precise and adequate information, we design an effective yet flexible architecture to extract and fuse cross-modal features. This architecture can tackle different numbers of CMR images and complex combinations of modalities, with output branches targeting specific pathologies. To impose anatomical knowledge on the segmentation results, we first propose a module to regularize myocardium consistency and localize the pathologies, and then introduce an inclusiveness loss to utilize relations between myocardial scars and edema. We evaluated the proposed MyoPS-Net on two datasets, i.e., a private one consisting of 50 paired multi-sequence CMR images and a public one from MICCAI2020 MyoPS Challenge. Experimental results showed that MyoPS-Net could achieve state-of-the-art performance in various scenarios. Note that in practical clinics, the subjects may not have full sequences, such as missing LGE CMR or mapping CMR scans. We therefore conducted extensive experiments to investigate the performance of the proposed method in dealing with such complex combinations of different CMR sequences. Results proved the superiority and generalizability of MyoPS-Net, and more importantly, indicated a practical clinical application.
Gradient Knowledge Distillation for Pre-trained Language Models
Nov 02, 2022



Knowledge distillation (KD) is an effective framework to transfer knowledge from a large-scale teacher to a compact yet well-performing student. Previous KD practices for pre-trained language models mainly transfer knowledge by aligning instance-wise outputs between the teacher and student, while neglecting an important knowledge source, i.e., the gradient of the teacher. The gradient characterizes how the teacher responds to changes in inputs, which we assume is beneficial for the student to better approximate the underlying mapping function of the teacher. Therefore, we propose Gradient Knowledge Distillation (GKD) to incorporate the gradient alignment objective into the distillation process. Experimental results show that GKD outperforms previous KD methods regarding student performance. Further analysis shows that incorporating gradient knowledge makes the student behave more consistently with the teacher, improving the interpretability greatly.
Learning Multi-resolution Functional Maps with Spectral Attention for Robust Shape Matching
Oct 12, 2022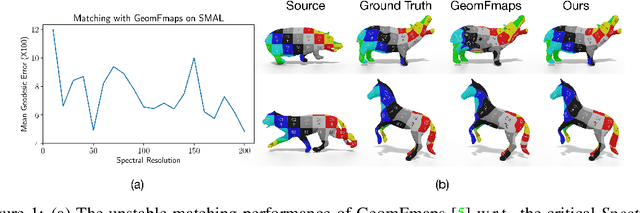
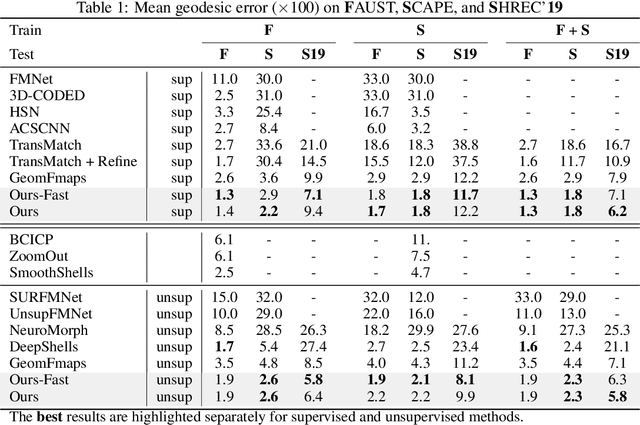
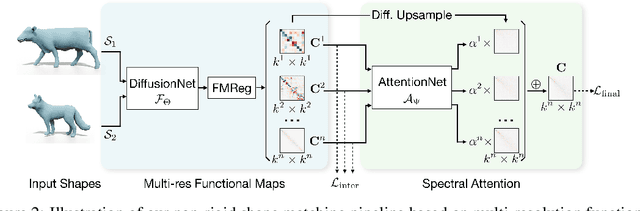
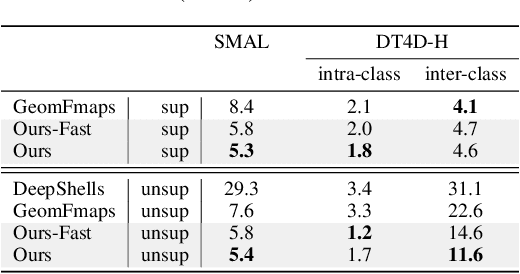
In this work, we present a novel non-rigid shape matching framework based on multi-resolution functional maps with spectral attention. Existing functional map learning methods all rely on the critical choice of the spectral resolution hyperparameter, which can severely affect the overall accuracy or lead to overfitting, if not chosen carefully. In this paper, we show that spectral resolution tuning can be alleviated by introducing spectral attention. Our framework is applicable in both supervised and unsupervised settings, and we show that it is possible to train the network so that it can adapt the spectral resolution, depending on the given shape input. More specifically, we propose to compute multi-resolution functional maps that characterize correspondence across a range of spectral resolutions, and introduce a spectral attention network that helps to combine this representation into a single coherent final correspondence. Our approach is not only accurate with near-isometric input, for which a high spectral resolution is typically preferred, but also robust and able to produce reasonable matching even in the presence of significant non-isometric distortion, which poses great challenges to existing methods. We demonstrate the superior performance of our approach through experiments on a suite of challenging near-isometric and non-isometric shape matching benchmarks.
From Mimicking to Integrating: Knowledge Integration for Pre-Trained Language Models
Oct 11, 2022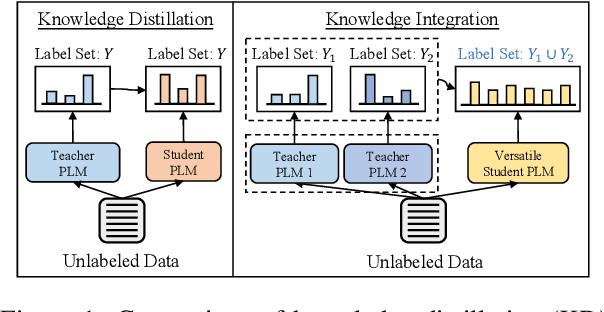
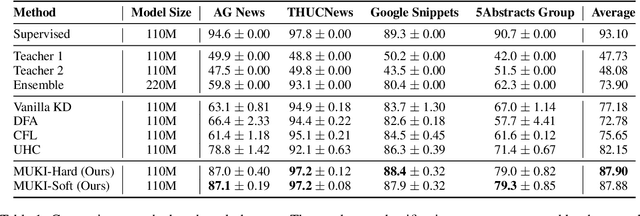
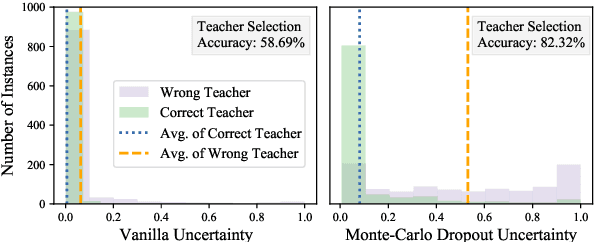
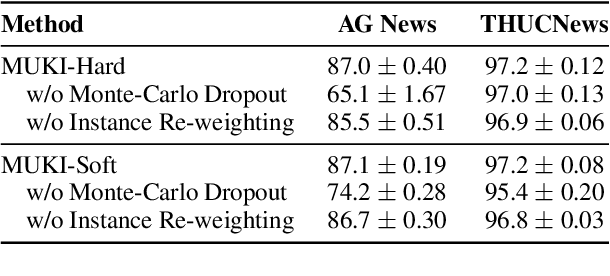
Investigating better ways to reuse the released pre-trained language models (PLMs) can significantly reduce the computational cost and the potential environmental side-effects. This paper explores a novel PLM reuse paradigm, Knowledge Integration (KI). Without human annotations available, KI aims to merge the knowledge from different teacher-PLMs, each of which specializes in a different classification problem, into a versatile student model. To achieve this, we first derive the correlation between virtual golden supervision and teacher predictions. We then design a Model Uncertainty--aware Knowledge Integration (MUKI) framework to recover the golden supervision for the student. Specifically, MUKI adopts Monte-Carlo Dropout to estimate model uncertainty for the supervision integration. An instance-wise re-weighting mechanism based on the margin of uncertainty scores is further incorporated, to deal with the potential conflicting supervision from teachers. Experimental results demonstrate that MUKI achieves substantial improvements over baselines on benchmark datasets. Further analysis shows that MUKI can generalize well for merging teacher models with heterogeneous architectures, and even teachers major in cross-lingual datasets.