 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Shot Learning as Instruction Data Prospector for Large Language Models
Jan 04, 2024Aligning large language models(LLMs) with human is a critical step in effectively utilizing their pre-trained capabilities across a wide array of language tasks. Current instruction tuning practices often rely on expanding dataset size without a clear strategy for ensuring data quality, which can inadvertently introduce noise and degrade model performance. To address this challenge, we introduce Nuggets, a novel and efficient methodology that employs one shot learning to select high-quality instruction data from expansive datasets. Nuggets assesses the potential of individual instruction examples to act as effective one shot examples, thereby identifying those that can significantly enhance diverse task performance. Nuggets utilizes a scoring system based on the impact of candidate examples on the perplexity of a diverse anchor set, facilitating the selection of the most beneficial data for instruction tuning. Through rigorous testing on two benchmarks, including MT-Bench and Alpaca-Eval, we demonstrate that instruction tuning with the top 1% of Nuggets-curated examples substantially outperforms conventional methods that use the full dataset. These findings advocate for a data selection paradigm that prioritizes quality, offering a more efficient pathway to align LLMs with humans.
Pontryagin Neural Operator for Solving Parametric General-Sum Differential Games
Jan 03, 2024The values of two-player general-sum differential games are viscosity solutions to Hamilton-Jacobi-Isaacs (HJI) equations. Value and policy approximations for such games suffer from the curse of dimensionality (CoD). Alleviating CoD through physics-informed neural networks (PINN) encounters convergence issues when value discontinuity is present due to state constraints. On top of these challenges, it is often necessary to learn generalizable values and policies across a parametric space of games, e.g., for game parameter inference when information is incomplete. To address these challenges, we propose in this paper a Pontryagin-mode neural operator that outperforms existing state-of-the-art (SOTA) on safety performance across games with parametric state constraints. Our key contribution is the introduction of a costate loss defined on the discrepancy between forward and backward costate rollouts, which are computationally cheap. We show that the discontinuity of costate dynamics (in the presence of state constraints) effectively enables the learning of discontinuous values, without requiring manually supervised data as suggested by the current SOTA. More importantly, we show that the close relationship between costates and policies makes the former critical in learning feedback control policies with generalizable safety performance.
ScatterFormer: Efficient Voxel Transformer with Scattered Linear Attention
Jan 01, 2024



Window-based transformers have demonstrated strong ability in large-scale point cloud understanding by capturing context-aware representations with affordable attention computation in a more localized manner. However, because of the sparse nature of point clouds, the number of voxels per window varies significantly. Current methods partition the voxels in each window into multiple subsets of equal size, which cost expensive overhead in sorting and padding the voxels, making them run slower than sparse convolution based methods. In this paper, we present ScatterFormer, which, for the first time to our best knowledge, could directly perform attention on voxel sets with variable length. The key of ScatterFormer lies in the innovative Scatter Linear Attention (SLA) module, which leverages the linear attention mechanism to process in parallel all voxels scattered in different windows. Harnessing the hierarchical computation units of the GPU and matrix blocking algorithm, we reduce the latency of the proposed SLA module to less than 1 ms on moderate GPUs. Besides, we develop a cross-window interaction module to simultaneously enhance the local representation and allow the information flow across windows, eliminating the need for window shifting. Our proposed ScatterFormer demonstrates 73 mAP (L2) on the large-scale Waymo Open Dataset and 70.5 NDS on the NuScenes dataset, running at an outstanding detection rate of 28 FPS. Code is available at https://github.com/skyhehe123/ScatterFormer
Improving the Stability of Diffusion Models for Content Consistent Super-Resolution
Dec 30, 2023



The generative priors of pre-trained latent diffusion models have demonstrated great potential to enhance the perceptual quality of image super-resolution (SR) results. Unfortunately, the existing diffusion prior-based SR methods encounter a common problem, i.e., they tend to generate rather different outputs for the same low-resolution image with different noise samples. Such stochasticity is desired for text-to-image generation tasks but problematic for SR tasks, where the image contents are expected to be well preserved. To improve the stability of diffusion prior-based SR, we propose to employ the diffusion models to refine image structures, while employing the generative adversarial training to enhance image fine details. Specifically, we propose a non-uniform timestep learning strategy to train a compact diffusion network, which has high efficiency and stability to reproduce the image main structures, and finetune the pre-trained decoder of variational auto-encoder (VAE) by adversarial training for detail enhancement. Extensive experiments show that our proposed method, namely content consistent super-resolution (CCSR), can significantly reduce the stochasticity of diffusion prior-based SR, improving the content consistency of SR outputs and speeding up the image generation process. Codes and models can be found at {https://github.com/csslc/CCSR}.
Osprey: Pixel Understanding with Visual Instruction Tuning
Dec 25, 2023



Multimodal large language models (MLLMs) have recently achieved impressive general-purpose vision-language capabilities through visual instruction tuning. However, current MLLMs primarily focus on image-level or box-level understanding, falling short of achieving fine-grained vision-language alignment at the pixel level. Besides, the lack of mask-based instruction data limits their advancements. In this paper, we propose Osprey, a mask-text instruction tuning approach, to extend MLLMs by incorporating fine-grained mask regions into language instruction, aiming at achieving pixel-wise visual understanding. To achieve this goal, we first meticulously curate a mask-based region-text dataset with 724K samples, and then design a vision-language model by injecting pixel-level representation into LLM. Especially, Osprey adopts a convolutional CLIP backbone as the vision encoder and employs a mask-aware visual extractor to extract precise visual mask features from high resolution input. Experimental results demonstrate Osprey's superiority in various region understanding tasks, showcasing its new capability for pixel-level instruction tuning. In particular, Osprey can be integrated with Segment Anything Model (SAM) seamlessly to obtain multi-granularity semantics. The source code, dataset and demo can be found at https://github.com/CircleRadon/Osprey.
Toward Accurate and Temporally Consistent Video Restoration from Raw Data
Dec 25, 2023Denoising and demosaicking are two fundamental steps in reconstructing a clean full-color video from raw data, while performing video denoising and demosaicking jointly, namely VJDD, could lead to better video restoration performance than performing them separately. In addition to restoration accuracy, another key challenge to VJDD lies in the temporal consistency of consecutive frames. This issue exacerbates when perceptual regularization terms are introduced to enhance video perceptual quality. To address these challenges, we present a new VJDD framework by consistent and accurate latent space propagation, which leverages the estimation of previous frames as prior knowledge to ensure consistent recovery of the current frame. A data temporal consistency (DTC) loss and a relational perception consistency (RPC) loss are accordingly designed. Compared with the commonly used flow-based losses, the proposed losses can circumvent the error accumulation problem caused by inaccurate flow estimation and effectively handle intensity changes in videos, improving much the temporal consistency of output videos while preserving texture details. Extensive experiments demonstrate the leading VJDD performance of our method in term of restoration accuracy, perceptual quality and temporal consistency. Codes and dataset are available at \url{https://github.com/GuoShi28/VJDD}.
A Closed-Loop Multi-perspective Visual Servoing Approach with Reinforcement Learning
Dec 25, 2023



Traditional visual servoing methods suffer from serving between scenes from multiple perspectives, which humans can complete with visual signals alone. In this paper, we investigated how multi-perspective visual servoing could be solved under robot-specific constraints, including self-collision, singularity problems. We presented a novel learning-based multi-perspective visual servoing framework, which iteratively estimates robot actions from latent space representations of visual states using reinforcement learning. Furthermore, our approaches were trained and validated in a Gazebo simulation environment with connection to OpenAI/Gym. Through simulation experiments, we showed that our method can successfully learn an optimal control policy given initial images from different perspectives, and it outperformed the Direct Visual Servoing algorithm with mean success rate of 97.0%.
Perception-Distortion Balanced Super-Resolution: A Multi-Objective Optimization Perspective
Dec 24, 2023High perceptual quality and low distortion degree are two important goals in image restoration tasks such as super-resolution (SR). Most of the existing SR methods aim to achieve these goals by minimizing the corresponding yet conflicting losses, such as the $\ell_1$ loss and the adversarial loss. Unfortunately, the commonly used gradient-based optimizers, such as Adam, are hard to balance these objectives due to the opposite gradient decent directions of the contradictory losses. In this paper, we formulate the perception-distortion trade-off in SR as a multi-objective optimization problem and develop a new optimizer by integrating the gradient-free evolutionary algorithm (EA) with gradient-based Adam, where EA and Adam focus on the divergence and convergence of the optimization directions respectively. As a result, a population of optimal models with different perception-distortion preferences is obtained. We then design a fusion network to merge these models into a single stronger one for an effective perception-distortion trade-off. Experiments demonstrate that with the same backbone network, the perception-distortion balanced SR model trained by our method can achieve better perceptual quality than its competitors while attaining better reconstruction fidelity. Codes and models can be found at https://github.com/csslc/EA-Adam.
TMP: Temporal Motion Propagation for Online Video Super-Resolution
Dec 18, 2023



Online video super-resolution (online-VSR) highly relies on an effective alignment module to aggregate temporal information, while the strict latency requirement makes accurate and efficient alignment very challenging. Though much progress has been achieved, most of the existing online-VSR methods estimate the motion fields of each frame separately to perform alignment, which is computationally redundant and ignores the fact that the motion fields of adjacent frames are correlated. In this work, we propose an efficient Temporal Motion Propagation (TMP) method, which leverages the continuity of motion field to achieve fast pixel-level alignment among consecutive frames. Specifically, we first propagate the offsets from previous frames to the current frame, and then refine them in the neighborhood, which significantly reduces the matching space and speeds up the offset estimation process. Furthermore, to enhance the robustness of alignment, we perform spatial-wise weighting on the warped features, where the positions with more precise offsets are assigned higher importance. Experiments on benchmark datasets demonstrate that the proposed TMP method achieves leading online-VSR accuracy as well as inference speed. The source code of TMP can be found at https://github.com/xtudbxk/TMP.
Marathon: A Race Through the Realm of Long Context with Large Language Models
Dec 15, 2023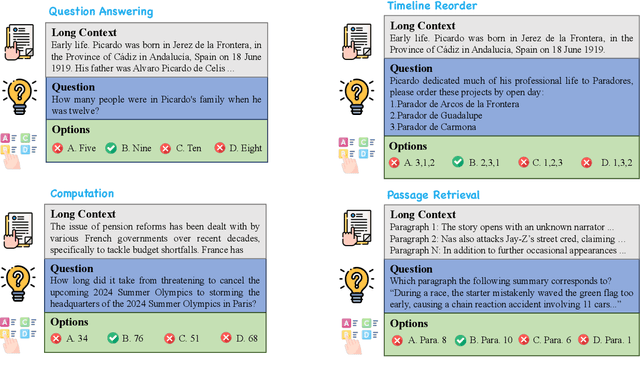
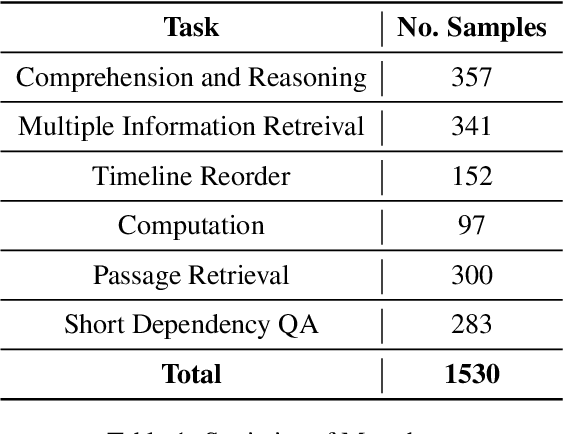
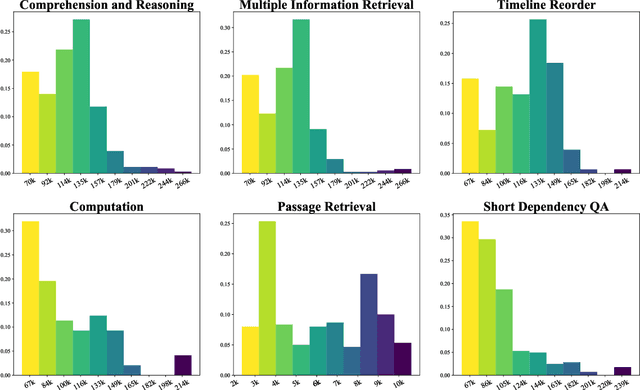
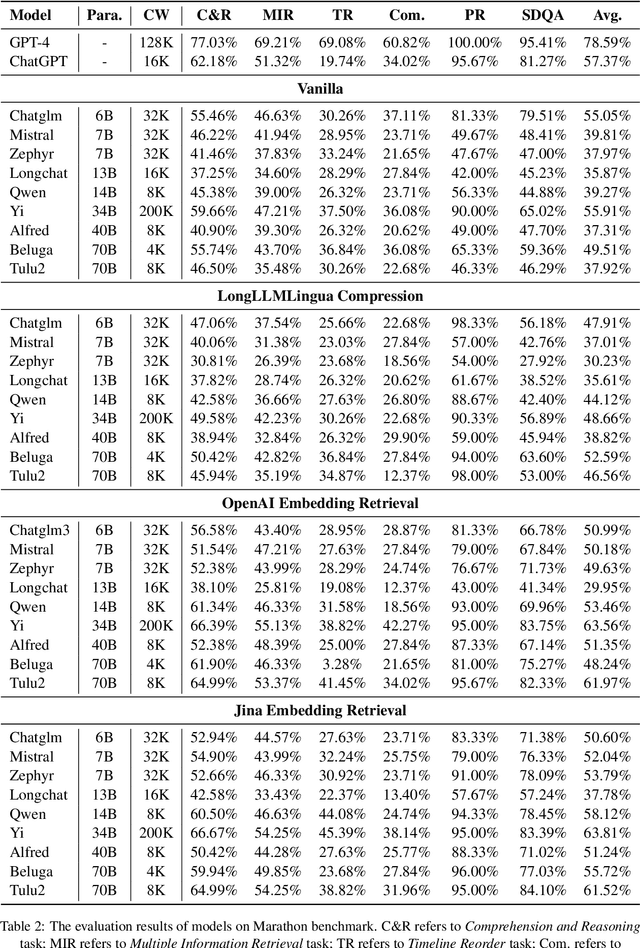
Although there are currently many benchmarks available for evaluating the long context understanding and reasoning capability of large language models, with the expansion of the context window in these models, the existing long context benchmarks are no longer sufficient for evaluating the long context understanding and reasoning capability of large language models. In this paper, we have developed a fresh long context evaluation benchmark, which we name it Marathon in the form of multiple choice questions, inspired by benchmarks such as MMLU, for assessing the long context comprehension capability of large language models quickly, accurately, and objectively. We have evaluated several of the latest and most popular large language models, as well as three recent and effective long context optimization methods, on our benchmark. This showcases the long context reasoning and comprehension capabilities of these large language models and validates the effectiveness of these optimization methods. Marathon is available at https://huggingface.co/datasets/Lemoncoke/Marathon.