 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiDDM-Weather: A Semi-supervised Learning Framework for All-in-one Adverse Weather Removal
Sep 29, 2024



Adverse weather removal aims to restore clear vision under adverse weather conditions. Existing methods are mostly tailored for specific weather types and rely heavily on extensive labeled data. In dealing with these two limitations, this paper presents a pioneering semi-supervised all-in-one adverse weather removal framework built on the teacher-student network with a Denoising Diffusion Model (DDM) as the backbone, termed SemiDDM-Weather. As for the design of DDM backbone in our SemiDDM-Weather, we adopt the SOTA Wavelet Diffusion Model-Wavediff with customized inputs and loss functions, devoted to facilitating the learning of many-to-one mapping distributions for efficient all-in-one adverse weather removal with limited label data. To mitigate the risk of misleading model training due to potentially inaccurate pseudo-labels generated by the teacher network in semi-supervised learning, we introduce quality assessment and content consistency constraints to screen the "optimal" outputs from the teacher network as the pseudo-labels, thus more effectively guiding the student network training with unlabeled data. Experimental results show that on both synthetic and real-world datasets, our SemiDDM-Weather consistently delivers high visual quality and superior adverse weather removal, even when compared to fully supervised competitors. Our code and pre-trained model are available at this repository.
Image Re-Identification: Where Self-supervision Meets Vision-Language Learning
Jul 30, 2024



Recently, large-scale vision-language pre-trained models like CLIP have shown impressive performance in image re-identification (ReID). In this work, we explore whether self-supervision can aid in the use of CLIP for image ReID tasks. Specifically, we propose SVLL-ReID, the first attempt to integrate self-supervision and pre-trained CLIP via two training stages to facilitate the image ReID. We observe that: 1) incorporating language self-supervision in the first training stage can make the learnable text prompts more distinguishable, and 2) incorporating vision self-supervision in the second training stage can make the image features learned by the image encoder more discriminative. These observations imply that: 1) the text prompt learning in the first stage can benefit from the language self-supervision, and 2) the image feature learning in the second stage can benefit from the vision self-supervision. These benefits jointly facilitate the performance gain of the proposed SVLL-ReID. By conducting experiments on six image ReID benchmark datasets without any concrete text labels, we find that the proposed SVLL-ReID achieves the overall best performances compared with state-of-the-arts. Codes will be publicly available at https://github.com/BinWangGzhu/SVLL-ReID.
The Devil is in the Details: Boosting Guided Depth Super-Resolution via Rethinking Cross-Modal Alignment and Aggregation
Jan 16, 2024Guided depth super-resolution (GDSR) involves restoring missing depth details using the high-resolution RGB image of the same scene. Previous approaches have struggled with the heterogeneity and complementarity of the multi-modal inputs, and neglected the issues of modal misalignment, geometrical misalignment, and feature selection. In this study, we rethink some essential components in GDSR networks and propose a simple yet effective Dynamic Dual Alignment and Aggregation network (D2A2). D2A2 mainly consists of 1) a dynamic dual alignment module that adapts to alleviate the modal misalignment via a learnable domain alignment block and geometrically align cross-modal features by learning the offset; and 2) a mask-to-pixel feature aggregate module that uses the gated mechanism and pixel attention to filter out irrelevant texture noise from RGB features and combine the useful features with depth features. By combining the strengths of RGB and depth features while minimizing disturbance introduced by the RGB image, our method with simple reuse and redesign of basic components achieves state-of-the-art performance on multiple benchmark datasets. The code is available at https://github.com/JiangXinni/D2A2.
MFMAN-YOLO: A Method for Detecting Pole-like Obstacles in Complex Environment
Jul 24, 2023



In real-world traffic, there are various uncertainties and complexities in road and weather conditions. To solve the problem that the feature information of pole-like obstacles in complex environments is easily lost, resulting in low detection accuracy and low real-time performance, a multi-scale hybrid attention mechanism detection algorithm is proposed in this paper. First, the optimal transport function Monge-Kantorovich (MK) is incorporated not only to solve the problem of overlapping multiple prediction frames with optimal matching but also the MK function can be regularized to prevent model over-fitting; then, the features at different scales are up-sampled separately according to the optimized efficient multi-scale feature pyramid. Finally, the extraction of multi-scale feature space channel information is enhanced in complex environments based on the hybrid attention mechanism, which suppresses the irrelevant complex environment background information and focuses the feature information of pole-like obstacles. Meanwhile, this paper conducts real road test experiments in a variety of complex environments. The experimental results show that the detection precision, recall, and average precision of the method are 94.7%, 93.1%, and 97.4%, respectively, and the detection frame rate is 400 f/s. This research method can detect pole-like obstacles in a complex road environment in real time and accurately, which further promotes innovation and progress in the field of automatic driving.
Multi-scale Attentive Image De-raining Networks via Neural Architecture Search
Jul 02, 2022



Multi-scale architectures and attention modules have shown effectiveness in many deep learning-based image de-raining methods. However, manually designing and integrating these two components into a neural network requires a bulk of labor and extensive expertise. In this article, a high-performance multi-scale attentive neural architecture search (MANAS) framework is technically developed for image deraining. The proposed method formulates a new multi-scale attention search space with multiple flexible modules that are favorite to the image de-raining task. Under the search space, multi-scale attentive cells are built, which are further used to construct a powerful image de-raining network. The internal multiscale attentive architecture of the de-raining network is searched automatically through a gradient-based search algorithm, which avoids the daunting procedure of the manual design to some extent. Moreover, in order to obtain a robust image de-raining model, a practical and effective multi-to-one training strategy is also presented to allow the de-raining network to get sufficient background information from multiple rainy images with the same background scene, and meanwhile, multiple loss functions including external loss, internal loss, architecture regularization loss, and model complexity loss are jointly optimized to achieve robust de-raining performance and controllable model complexity. Extensive experimental results on both synthetic and realistic rainy images, as well as the down-stream vision applications (i.e., objection detection and segmentation) consistently demonstrate the superiority of our proposed method.
MoleculeKit: Machine Learning Methods for Molecular Property Prediction and Drug Discovery
Dec 02, 2020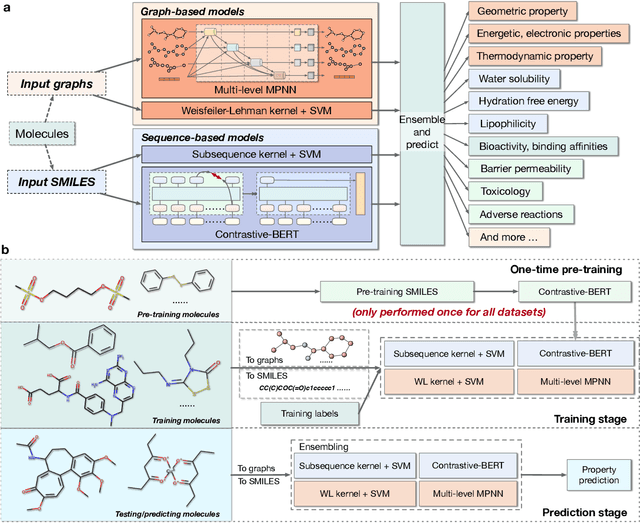
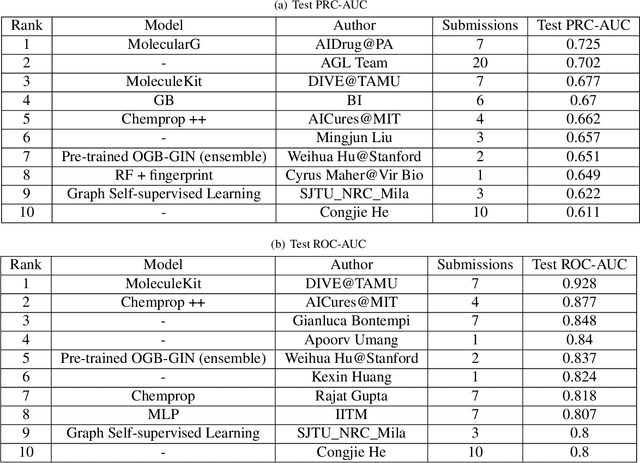
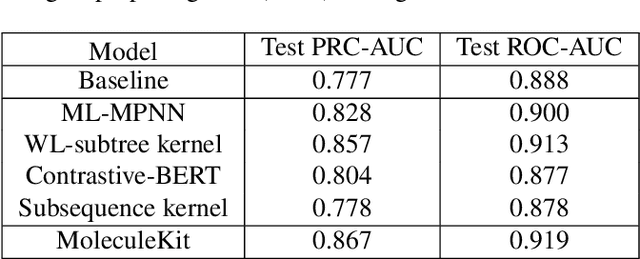
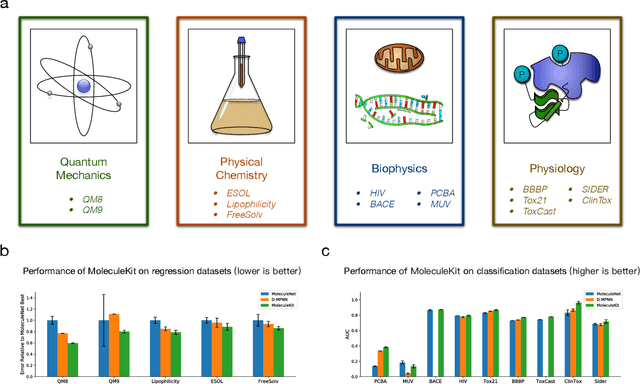
Properties of molecules are indicative of their functions and thus are useful in many applications. As a cost-effective alternative to experimental approaches, computational methods for predicting molecular properties are gaining increasing momentum and success. However, there lacks a comprehensive collection of tools and methods for this task currently. Here we develop the MoleculeKit, a suite of comprehensive machine learning tools spanning different computational models and molecular representations for molecular property prediction and drug discovery. Specifically, MoleculeKit represents molecules as both graphs and sequences. Built on these representations, MoleculeKit includes both deep learning and traditional machine learning methods for graph and sequence data. Noticeably, we propose and develop novel deep models for learning from molecular graphs and sequences. Therefore, MoleculeKit not only serves as a comprehensive tool, but also contributes towards developing novel and advanced graph and sequence learning methodologies. Results on both online and offline antibiotics discovery and molecular property prediction tasks show that MoleculeKit achieves consistent improvements over prior methods.
Deep Low-Shot Learning for Biological Image Classification and Visualization from Limited Training Samples
Oct 20, 2020
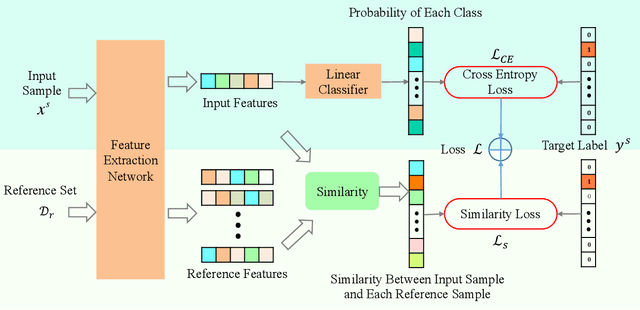
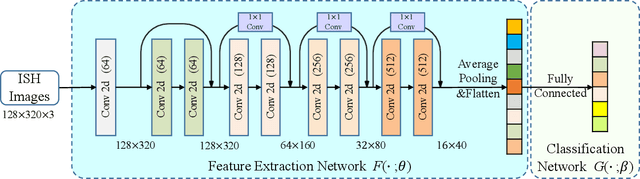
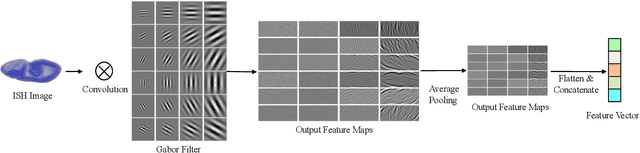
Predictive modeling is useful but very challenging in biological image analysis due to the high cost of obtaining and labeling training data. For example, in the study of gene interaction and regulation in Drosophila embryogenesis, the analysis is most biologically meaningful when in situ hybridization (ISH) gene expression pattern images from the same developmental stage are compared. However, labeling training data with precise stages is very time-consuming even for evelopmental biologists. Thus, a critical challenge is how to build accurate computational models for precise developmental stage classification from limited training samples. In addition, identification and visualization of developmental landmarks are required to enable biologists to interpret prediction results and calibrate models. To address these challenges, we propose a deep two-step low-shot learning framework to accurately classify ISH images using limited training images. Specifically, to enable accurate model training on limited training samples, we formulate the task as a deep low-shot learning problem and develop a novel two-step learning approach, including data-level learning and feature-level learning. We use a deep residual network as our base model and achieve improved performance in the precise stage prediction task of ISH images. Furthermore, the deep model can be interpreted by computing saliency maps, which consist of pixel-wise contributions of an image to its prediction result. In our task, saliency maps are used to assist the identification and visualization of developmental landmarks. Our experimental results show that the proposed model can not only make accurate predictions, but also yield biologically meaningful interpretations. We anticipate our methods to be easily generalizable to other biological image classification tasks with small training datasets.
Line Graph Neural Networks for Link Prediction
Oct 20, 2020
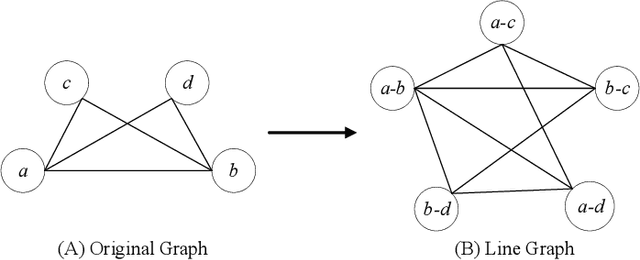
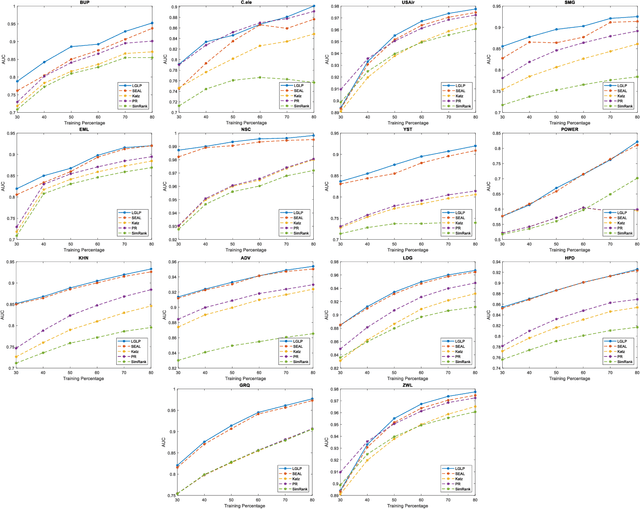
We consider the graph link prediction task, which is a classic graph analytical problem with many real-world applications. With the advances of deep learning, current link prediction methods commonly compute features from subgraphs centered at two neighboring nodes and use the features to predict the label of the link between these two nodes. In this formalism, a link prediction problem is converted to a graph classification task. In order to extract fixed-size features for classification, graph pooling layers are necessary in the deep learning model, thereby incurring information loss. To overcome this key limitation, we propose to seek a radically different and novel path by making use of the line graphs in graph theory. In particular, each node in a line graph corresponds to a unique edge in the original graph. Therefore, link prediction problems in the original graph can be equivalently solved as a node classification problem in its corresponding line graph, instead of a graph classification task. Experimental results on fourteen datasets from different applications demonstrate that our proposed method consistently outperforms the state-of-the-art methods, while it has fewer parameters and high training efficiency.
Structural Plan of Indoor Scenes with Personalized Preferences
Aug 05, 2020
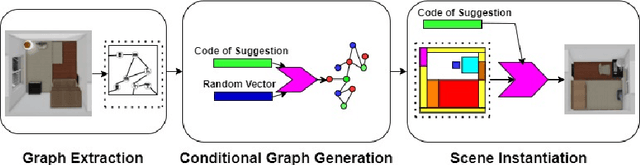
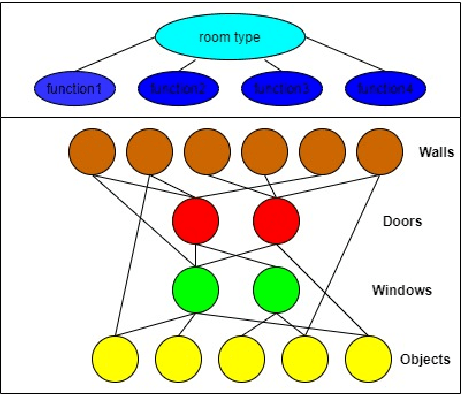
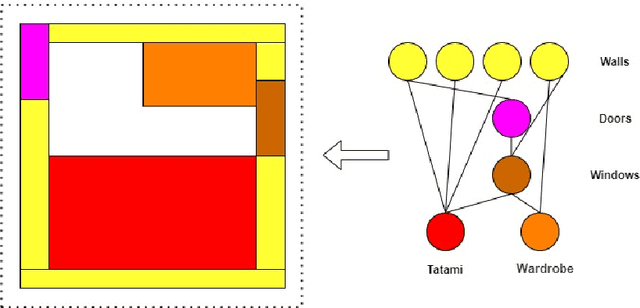
In this paper, we propose an assistive model that supports professional interior designers to produce industrial interior decoration solutions and to meet the personalized preferences of the property owners. The proposed model is able to automatically produce the layout of objects of a particular indoor scene according to property owners' preferences. In particular, the model consists of the extraction of abstract graph, conditional graph generation, and conditional scene instantiation. We provide an interior layout dataset that contains real-world 11000 designs from professional designers. Our numerical results on the dataset demonstrate the effectiveness of the proposed model compared with the state-of-art methods.
Deep Learning of High-Order Interactions for Protein Interface Prediction
Jul 18, 2020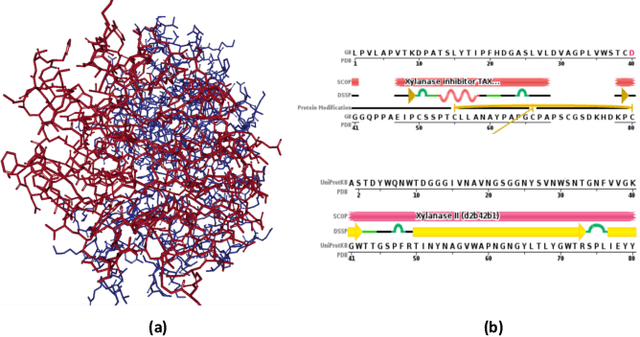
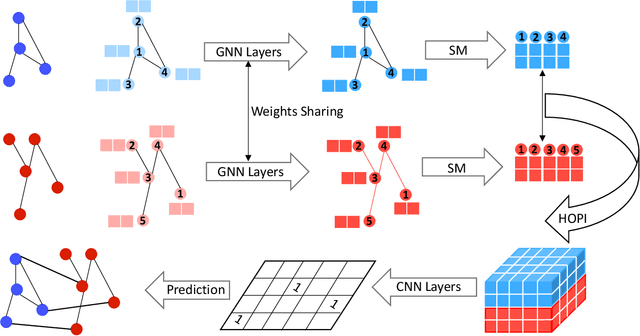
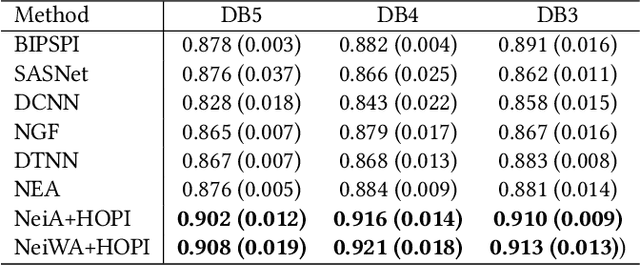
Protein interactions are important in a broad range of biological processes. Traditionally, computational methods have been developed to automatically predict protein interface from hand-crafted features. Recent approaches employ deep neural networks and predict the interaction of each amino acid pair independently. However, these methods do not incorporate the important sequential information from amino acid chains and the high-order pairwise interactions. Intuitively, the prediction of an amino acid pair should depend on both their features and the information of other amino acid pairs. In this work, we propose to formulate the protein interface prediction as a 2D dense prediction problem. In addition, we propose a novel deep model to incorporate the sequential information and high-order pairwise interactions to perform interface predictions. We represent proteins as graphs and employ graph neural networks to learn node features. Then we propose the sequential modeling method to incorporate the sequential information and reorder the feature matrix. Next, we incorporate high-order pairwise interactions to generate a 3D tensor containing different pairwise interactions. Finally, we employ convolutional neural networks to perform 2D dense predictions. Experimental results on multiple benchmarks demonstrate that our proposed method can consistently improve the protein interface prediction performance.