 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised segmentation of irradiation$\unicode{x2010}$induced order$\unicode{x2010}$disorder phase transitions in electron microscopy
Nov 14, 2023We present a method for the unsupervised segmentation of electron microscopy images, which are powerful descriptors of materials and chemical systems. Images are oversegmented into overlapping chips, and similarity graphs are generated from embeddings extracted from a domain$\unicode{x2010}$pretrained convolutional neural network (CNN). The Louvain method for community detection is then applied to perform segmentation. The graph representation provides an intuitive way of presenting the relationship between chips and communities. We demonstrate our method to track irradiation$\unicode{x2010}$induced amorphous fronts in thin films used for catalysis and electronics. This method has potential for "on$\unicode{x2010}$the$\unicode{x2010}$fly" segmentation to guide emerging automated electron microscopes.
Designing a Better Asymmetric VQGAN for StableDiffusion
Jun 07, 2023



StableDiffusion is a revolutionary text-to-image generator that is causing a stir in the world of image generation and editing. Unlike traditional methods that learn a diffusion model in pixel space, StableDiffusion learns a diffusion model in the latent space via a VQGAN, ensuring both efficiency and quality. It not only supports image generation tasks, but also enables image editing for real images, such as image inpainting and local editing. However, we have observed that the vanilla VQGAN used in StableDiffusion leads to significant information loss, causing distortion artifacts even in non-edited image regions. To this end, we propose a new asymmetric VQGAN with two simple designs. Firstly, in addition to the input from the encoder, the decoder contains a conditional branch that incorporates information from task-specific priors, such as the unmasked image region in inpainting. Secondly, the decoder is much heavier than the encoder, allowing for more detailed recovery while only slightly increasing the total inference cost. The training cost of our asymmetric VQGAN is cheap, and we only need to retrain a new asymmetric decoder while keeping the vanilla VQGAN encoder and StableDiffusion unchanged. Our asymmetric VQGAN can be widely used in StableDiffusion-based inpainting and local editing methods. Extensive experiments demonstrate that it can significantly improve the inpainting and editing performance, while maintaining the original text-to-image capability. The code is available at \url{https://github.com/buxiangzhiren/Asymmetric_VQGAN}.
MotionTrack: Learning Robust Short-term and Long-term Motions for Multi-Object Tracking
Mar 18, 2023



The main challenge of Multi-Object Tracking~(MOT) lies in maintaining a continuous trajectory for each target. Existing methods often learn reliable motion patterns to match the same target between adjacent frames and discriminative appearance features to re-identify the lost targets after a long period. However, the reliability of motion prediction and the discriminability of appearances can be easily hurt by dense crowds and extreme occlusions in the tracking process. In this paper, we propose a simple yet effective multi-object tracker, i.e., MotionTrack, which learns robust short-term and long-term motions in a unified framework to associate trajectories from a short to long range. For dense crowds, we design a novel Interaction Module to learn interaction-aware motions from short-term trajectories, which can estimate the complex movement of each target. For extreme occlusions, we build a novel Refind Module to learn reliable long-term motions from the target's history trajectory, which can link the interrupted trajectory with its corresponding detection. Our Interaction Module and Refind Module are embedded in the well-known tracking-by-detection paradigm, which can work in tandem to maintain superior performance. Extensive experimental results on MOT17 and MOT20 datasets demonstrate the superiority of our approach in challenging scenarios, and it achieves state-of-the-art performances at various MOT metrics.
Exploring Discrete Diffusion Models for Image Captioning
Dec 09, 2022



The image captioning task is typically realized by an auto-regressive method that decodes the text tokens one by one. We present a diffusion-based captioning model, dubbed the name DDCap, to allow more decoding flexibility. Unlike image generation, where the output is continuous and redundant with a fixed length, texts in image captions are categorical and short with varied lengths. Therefore, naively applying the discrete diffusion model to text decoding does not work well, as shown in our experiments. To address the performance gap, we propose several key techniques including best-first inference, concentrated attention mask, text length prediction, and image-free training. On COCO without additional caption pre-training, it achieves a CIDEr score of 117.8, which is +5.0 higher than the auto-regressive baseline with the same architecture in the controlled setting. It also performs +26.8 higher CIDEr score than the auto-regressive baseline (230.3 v.s.203.5) on a caption infilling task. With 4M vision-language pre-training images and the base-sized model, we reach a CIDEr score of 125.1 on COCO, which is competitive to the best well-developed auto-regressive frameworks. The code is available at https://github.com/buxiangzhiren/DDCap.
Physical Logic Enhanced Network for Small-Sample Bi-Layer Metallic Tubes Bending Springback Prediction
Sep 20, 2022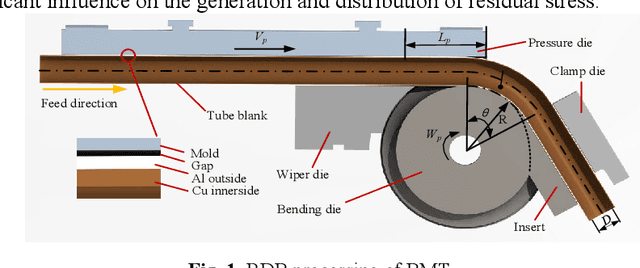

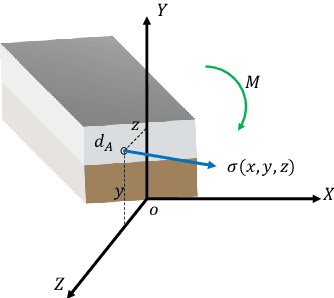

Bi-layer metallic tube (BMT) plays an extremely crucial role in engineering applications, with rotary draw bending (RDB) the high-precision bending processing can be achieved, however, the product will further springback. Due to the complex structure of BMT and the high cost of dataset acquisi-tion, the existing methods based on mechanism research and machine learn-ing cannot meet the engineering requirements of springback prediction. Based on the preliminary mechanism analysis, a physical logic enhanced network (PE-NET) is proposed. The architecture includes ES-NET which equivalent the BMT to the single-layer tube, and SP-NET for the final predic-tion of springback with sufficient single-layer tube samples. Specifically, in the first stage, with the theory-driven pre-exploration and the data-driven pretraining, the ES-NET and SP-NET are constructed, respectively. In the second stage, under the physical logic, the PE-NET is assembled by ES-NET and SP-NET and then fine-tuned with the small sample BMT dataset and composite loss function. The validity and stability of the proposed method are verified by the FE simulation dataset, the small-sample dataset BMT springback angle prediction is achieved, and the method potential in inter-pretability and engineering applications are demonstrated.
Learning to Refactor Action and Co-occurrence Features for Temporal Action Localization
Jun 23, 2022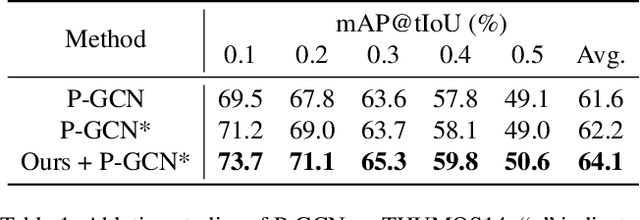
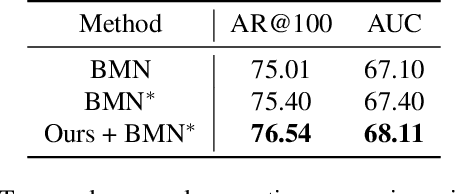
The main challenge of Temporal Action Localization is to retrieve subtle human actions from various co-occurring ingredients, e.g., context and background, in an untrimmed video. While prior approaches have achieved substantial progress through devising advanced action detectors, they still suffer from these co-occurring ingredients which often dominate the actual action content in videos. In this paper, we explore two orthogonal but complementary aspects of a video snippet, i.e., the action features and the co-occurrence features. Especially, we develop a novel auxiliary task by decoupling these two types of features within a video snippet and recombining them to generate a new feature representation with more salient action information for accurate action localization. We term our method RefactorNet, which first explicitly factorizes the action content and regularizes its co-occurrence features, and then synthesizes a new action-dominated video representation. Extensive experimental results and ablation studies on THUMOS14 and ActivityNet v1.3 demonstrate that our new representation, combined with a simple action detector, can significantly improve the action localization performance.
Social Interpretable Tree for Pedestrian Trajectory Prediction
May 26, 2022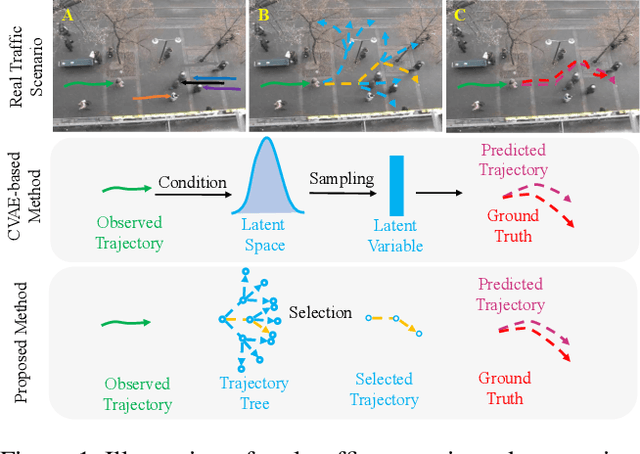
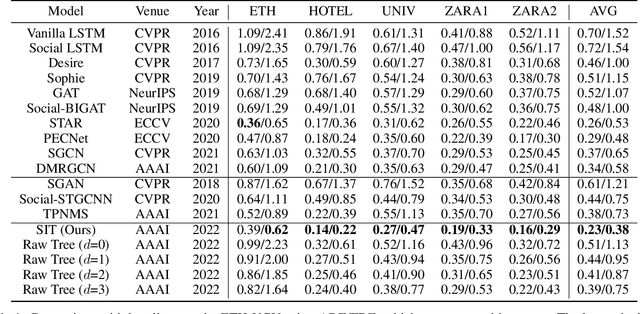
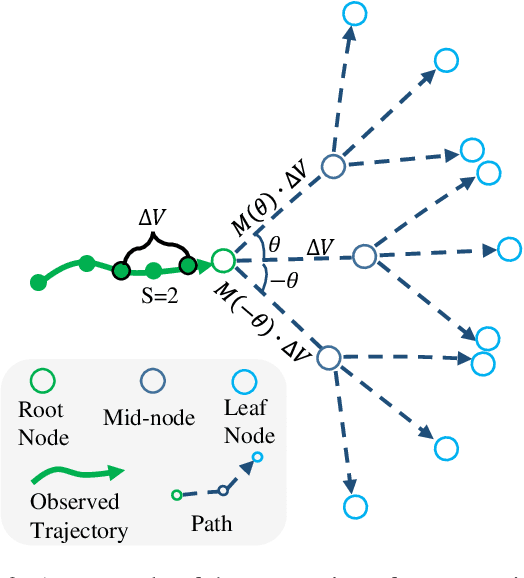
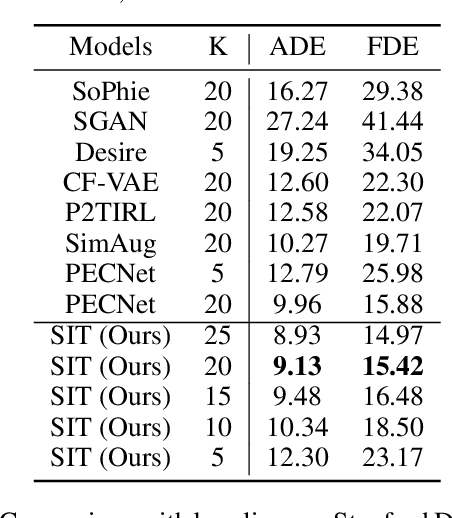
Understanding the multiple socially-acceptable future behaviors is an essential task for many vision applications. In this paper, we propose a tree-based method, termed as Social Interpretable Tree (SIT), to address this multi-modal prediction task, where a hand-crafted tree is built depending on the prior information of observed trajectory to model multiple future trajectories. Specifically, a path in the tree from the root to leaf represents an individual possible future trajectory. SIT employs a coarse-to-fine optimization strategy, in which the tree is first built by high-order velocity to balance the complexity and coverage of the tree and then optimized greedily to encourage multimodality. Finally, a teacher-forcing refining operation is used to predict the final fine trajectory. Compared with prior methods which leverage implicit latent variables to represent possible future trajectories, the path in the tree can explicitly explain the rough moving behaviors (e.g., go straight and then turn right), and thus provides better interpretability. Despite the hand-crafted tree, the experimental results on ETH-UCY and Stanford Drone datasets demonstrate that our method is capable of matching or exceeding the performance of state-of-the-art methods. Interestingly, the experiments show that the raw built tree without training outperforms many prior deep neural network based approaches. Meanwhile, our method presents sufficient flexibility in long-term prediction and different best-of-$K$ predictions.
Improving robustness of language models from a geometry-aware perspective
Apr 28, 2022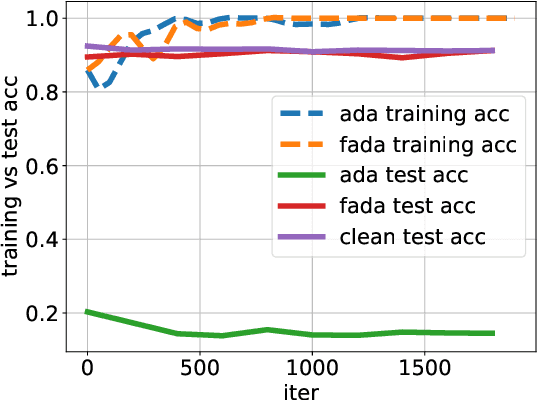

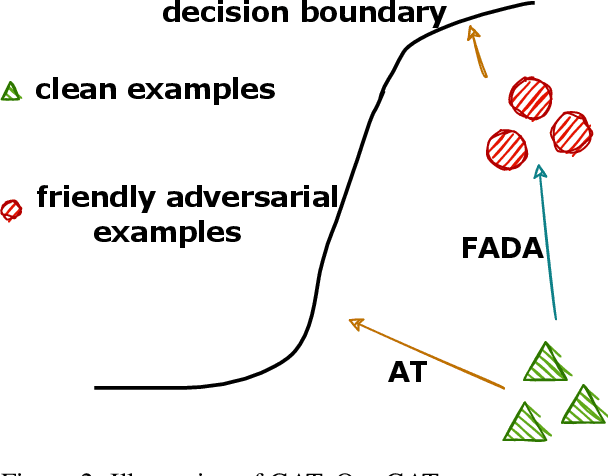
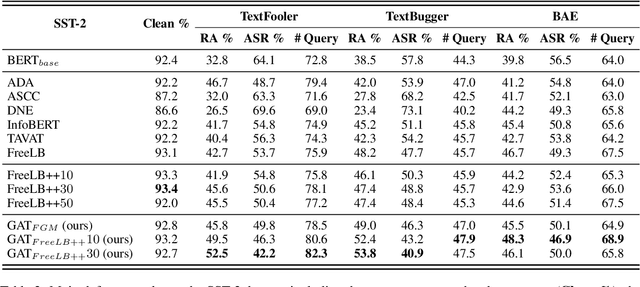
Recent studies have found that removing the norm-bounded projection and increasing search steps in adversarial training can significantly improve robustness. However, we observe that a too large number of search steps can hurt accuracy. We aim to obtain strong robustness efficiently using fewer steps. Through a toy experiment, we find that perturbing the clean data to the decision boundary but not crossing it does not degrade the test accuracy. Inspired by this, we propose friendly adversarial data augmentation (FADA) to generate friendly adversarial data. On top of FADA, we propose geometry-aware adversarial training (GAT) to perform adversarial training on friendly adversarial data so that we can save a large number of search steps. Comprehensive experiments across two widely used datasets and three pre-trained language models demonstrate that GAT can obtain stronger robustness via fewer steps. In addition, we provide extensive empirical results and in-depth analyses on robustness to facilitate future studies.
Adversarial Fine-tuning for Backdoor Defense: Connect Adversarial Examples to Triggered Samples
Feb 13, 2022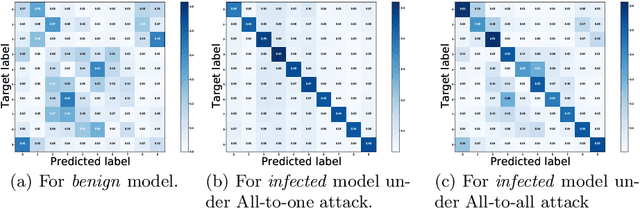

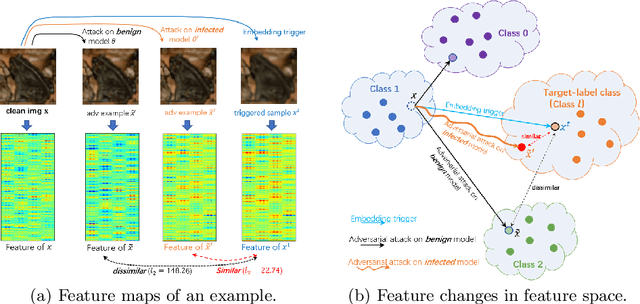

Deep neural networks (DNNs) are known to be vulnerable to backdoor attacks, i.e., a backdoor trigger planted at training time, the infected DNN model would misclassify any testing sample embedded with the trigger as target label. Due to the stealthiness of backdoor attacks, it is hard either to detect or erase the backdoor from infected models. In this paper, we propose a new Adversarial Fine-Tuning (AFT) approach to erase backdoor triggers by leveraging adversarial examples of the infected model. For an infected model, we observe that its adversarial examples have similar behaviors as its triggered samples. Based on such observation, we design the AFT to break the foundation of the backdoor attack (i.e., the strong correlation between a trigger and a target label). We empirically show that, against 5 state-of-the-art backdoor attacks, AFT can effectively erase the backdoor triggers without obvious performance degradation on clean samples, which significantly outperforms existing defense methods.
Diffractive deep neural network based adaptive optics scheme for vortex beam in oceanic turbulence
Feb 06, 2022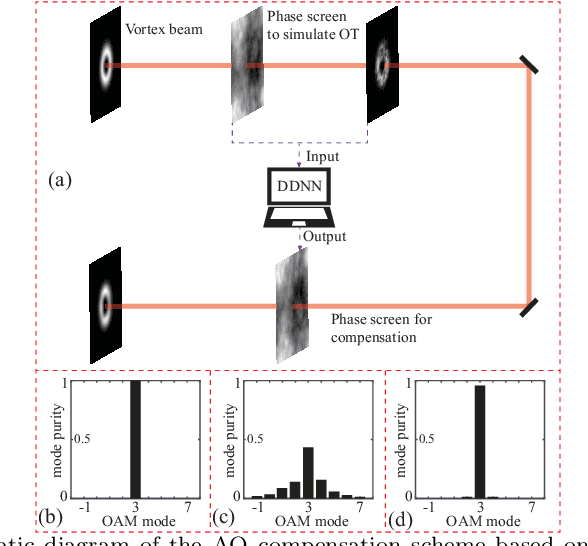

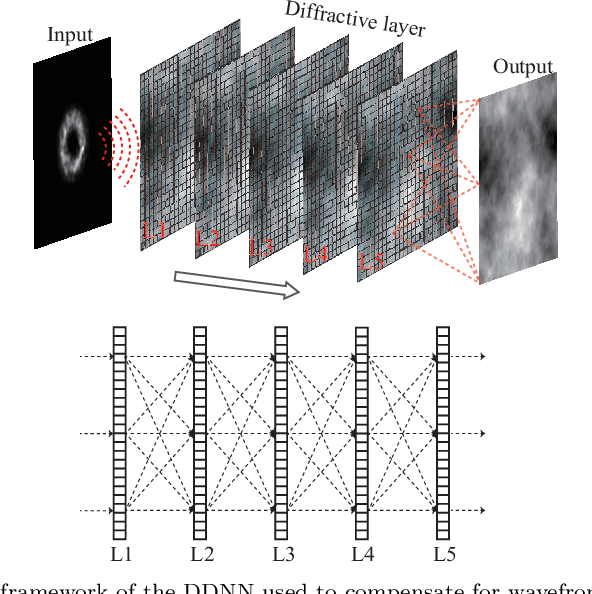
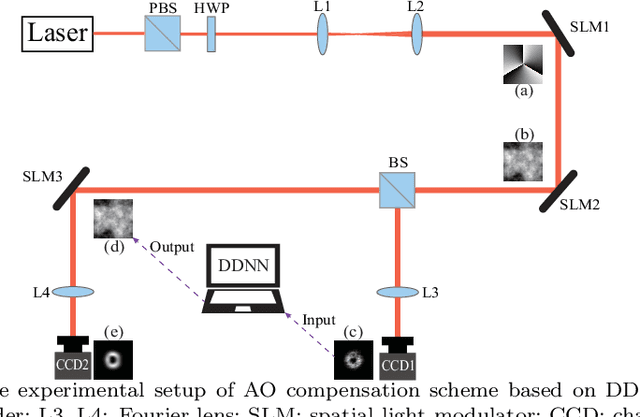
Vortex beam carrying orbital angular momentum (OAM) is disturbed by oceanic turbulence (OT) when propagating in underwater wireless optical communication (UWOC) system. Adaptive optics (AO) is used to compensate for distortion and improve the performance of the UWOC system. In this work, we propose a diffractive deep neural network (DDNN) based AO scheme to compensate for the distortion caused by OT, where the DDNN is trained to obtain the mapping between the distortion intensity distribution of the vortex beam and its corresponding phase screen representating OT. The intensity pattern of the distorted vortex beam obtained in the experiment is input to the DDNN model, and the predicted phase screen can be used to compensate the distortion in real time. The experiment results show that the proposed scheme can extract quickly the characteristics of the intensity pattern of the distorted vortex beam, and output accurately the predicted phase screen. The mode purity of the compensated vortex beam is significantly improved, even with a strong OT. Our scheme may provide a new avenue for AO techniques, and is expected to promote the communication quality of UWOC system.