 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAscendKernelGen: A Systematic Study of LLM-Based Kernel Generation for Neural Processing Units
Jan 12, 2026To meet the ever-increasing demand for computational efficiency, Neural Processing Units (NPUs) have become critical in modern AI infrastructure. However, unlocking their full potential requires developing high-performance compute kernels using vendor-specific Domain-Specific Languages (DSLs), a task that demands deep hardware expertise and is labor-intensive. While Large Language Models (LLMs) have shown promise in general code generation, they struggle with the strict constraints and scarcity of training data in the NPU domain. Our preliminary study reveals that state-of-the-art general-purpose LLMs fail to generate functional complex kernels for Ascend NPUs, yielding a near-zero success rate. To address these challenges, we propose AscendKernelGen, a generation-evaluation integrated framework for NPU kernel development. We introduce Ascend-CoT, a high-quality dataset incorporating chain-of-thought reasoning derived from real-world kernel implementations, and KernelGen-LM, a domain-adaptive model trained via supervised fine-tuning and reinforcement learning with execution feedback. Furthermore, we design NPUKernelBench, a comprehensive benchmark for assessing compilation, correctness, and performance across varying complexity levels. Experimental results demonstrate that our approach significantly bridges the gap between general LLMs and hardware-specific coding. Specifically, the compilation success rate on complex Level-2 kernels improves from 0% to 95.5% (Pass@10), while functional correctness achieves 64.3% compared to the baseline's complete failure. These results highlight the critical role of domain-specific reasoning and rigorous evaluation in automating accelerator-aware code generation.
Adversarial Fine-tuning for Backdoor Defense: Connect Adversarial Examples to Triggered Samples
Feb 13, 2022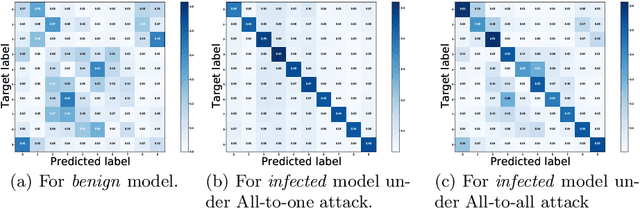

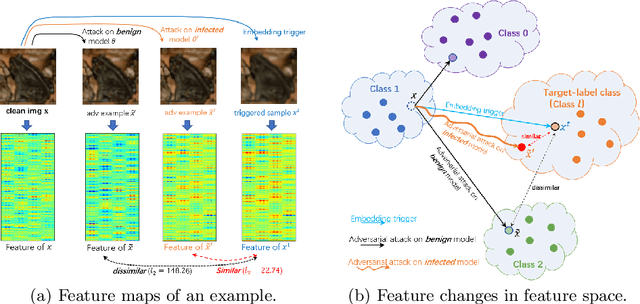

Deep neural networks (DNNs) are known to be vulnerable to backdoor attacks, i.e., a backdoor trigger planted at training time, the infected DNN model would misclassify any testing sample embedded with the trigger as target label. Due to the stealthiness of backdoor attacks, it is hard either to detect or erase the backdoor from infected models. In this paper, we propose a new Adversarial Fine-Tuning (AFT) approach to erase backdoor triggers by leveraging adversarial examples of the infected model. For an infected model, we observe that its adversarial examples have similar behaviors as its triggered samples. Based on such observation, we design the AFT to break the foundation of the backdoor attack (i.e., the strong correlation between a trigger and a target label). We empirically show that, against 5 state-of-the-art backdoor attacks, AFT can effectively erase the backdoor triggers without obvious performance degradation on clean samples, which significantly outperforms existing defense methods.