 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolGym: an Open-world Tool-using Environment for Scalable Agent Testing and Data Curation
Jan 09, 2026Tool-using LLM agents still struggle in open-world settings with large tool pools, long-horizon objectives, wild constraints, and unreliable tool states. For scalable and realistic training and testing, we introduce an open-world tool-using environment, built on 5,571 format unified tools across 204 commonly used apps. It includes a task creation engine that synthesizes long-horizon, multi-tool workflows with wild constraints, and a state controller that injects interruptions and failures to stress-test robustness. On top of this environment, we develop a tool select-then-execute agent framework with a planner-actor decomposition to separate deliberate reasoning and self-correction from step-wise execution. Comprehensive evaluation of state-of-the-art LLMs reveals the misalignment between tool planning and execution abilities, the constraint following weakness of existing LLMs, and DeepSeek-v3.2's strongest robustness. Finally, we collect 1,170 trajectories from our environment to fine-tune LLMs, achieving superior performance to baselines using 119k samples, indicating the environment's value as both a realistic benchmark and a data engine for tool-using agents. Our code and data will be publicly released.
Slot-ID: Identity-Preserving Video Generation from Reference Videos via Slot-Based Temporal Identity Encoding
Jan 04, 2026Producing prompt-faithful videos that preserve a user-specified identity remains challenging: models need to extrapolate facial dynamics from sparse reference while balancing the tension between identity preservation and motion naturalness. Conditioning on a single image completely ignores the temporal signature, which leads to pose-locked motions, unnatural warping, and "average" faces when viewpoints and expressions change. To this end, we introduce an identity-conditioned variant of a diffusion-transformer video generator which uses a short reference video rather than a single portrait. Our key idea is to incorporate the dynamics in the reference. A short clip reveals subject-specific patterns, e.g., how smiles form, across poses and lighting. From this clip, a Sinkhorn-routed encoder learns compact identity tokens that capture characteristic dynamics while remaining pretrained backbone-compatible. Despite adding only lightweight conditioning, the approach consistently improves identity retention under large pose changes and expressive facial behavior, while maintaining prompt faithfulness and visual realism across diverse subjects and prompts.
VIPER: Process-aware Evaluation for Generative Video Reasoning
Dec 31, 2025Recent breakthroughs in video generation have demonstrated an emerging capability termed Chain-of-Frames (CoF) reasoning, where models resolve complex tasks through the generation of continuous frames. While these models show promise for Generative Video Reasoning (GVR), existing evaluation frameworks often rely on single-frame assessments, which can lead to outcome-hacking, where a model reaches a correct conclusion through an erroneous process. To address this, we propose a process-aware evaluation paradigm. We introduce VIPER, a comprehensive benchmark spanning 16 tasks across temporal, structural, symbolic, spatial, physics, and planning reasoning. Furthermore, we propose Process-outcome Consistency (POC@r), a new metric that utilizes VLM-as-Judge with a hierarchical rubric to evaluate both the validity of the intermediate steps and the final result. Our experiments reveal that state-of-the-art video models achieve only about 20% POC@1.0 and exhibit a significant outcome-hacking. We further explore the impact of test-time scaling and sampling robustness, highlighting a substantial gap between current video generation and true generalized visual reasoning. Our benchmark will be publicly released.
DeliveryBench: Can Agents Earn Profit in Real World?
Dec 22, 2025



LLMs and VLMs are increasingly deployed as embodied agents, yet existing benchmarks largely revolve around simple short-term tasks and struggle to capture rich realistic constraints that shape real-world decision making. To close this gap, we propose DeliveryBench, a city-scale embodied benchmark grounded in the real-world profession of food delivery. Food couriers naturally operate under long-horizon objectives (maximizing net profit over hours) while managing diverse constraints, e.g., delivery deadline, transportation expense, vehicle battery, and necessary interactions with other couriers and customers. DeliveryBench instantiates this setting in procedurally generated 3D cities with diverse road networks, buildings, functional locations, transportation modes, and realistic resource dynamics, enabling systematic evaluation of constraint-aware, long-horizon planning. We benchmark a range of VLM-based agents across nine cities and compare them with human players. Our results reveal a substantial performance gap to humans, and find that these agents are short-sighted and frequently break basic commonsense constraints. Additionally, we observe distinct personalities across models (e.g., adventurous GPT-5 vs. conservative Claude), highlighting both the brittleness and the diversity of current VLM-based embodied agents in realistic, constraint-dense environments. Our code, data, and benchmark are available at https://deliverybench.github.io.
3DTeethSAM: Taming SAM2 for 3D Teeth Segmentation
Dec 12, 2025



3D teeth segmentation, involving the localization of tooth instances and their semantic categorization in 3D dental models, is a critical yet challenging task in digital dentistry due to the complexity of real-world dentition. In this paper, we propose 3DTeethSAM, an adaptation of the Segment Anything Model 2 (SAM2) for 3D teeth segmentation. SAM2 is a pretrained foundation model for image and video segmentation, demonstrating a strong backbone in various downstream scenarios. To adapt SAM2 for 3D teeth data, we render images of 3D teeth models from predefined views, apply SAM2 for 2D segmentation, and reconstruct 3D results using 2D-3D projections. Since SAM2's performance depends on input prompts and its initial outputs often have deficiencies, and given its class-agnostic nature, we introduce three light-weight learnable modules: (1) a prompt embedding generator to derive prompt embeddings from image embeddings for accurate mask decoding, (2) a mask refiner to enhance SAM2's initial segmentation results, and (3) a mask classifier to categorize the generated masks. Additionally, we incorporate Deformable Global Attention Plugins (DGAP) into SAM2's image encoder. The DGAP enhances both the segmentation accuracy and the speed of the training process. Our method has been validated on the 3DTeethSeg benchmark, achieving an IoU of 91.90% on high-resolution 3D teeth meshes, establishing a new state-of-the-art in the field.
TR-Gaussians: High-fidelity Real-time Rendering of Planar Transmission and Reflection with 3D Gaussian Splatting
Nov 17, 2025We propose Transmission-Reflection Gaussians (TR-Gaussians), a novel 3D-Gaussian-based representation for high-fidelity rendering of planar transmission and reflection, which are ubiquitous in indoor scenes. Our method combines 3D Gaussians with learnable reflection planes that explicitly model the glass planes with view-dependent reflectance strengths. Real scenes and transmission components are modeled by 3D Gaussians and the reflection components are modeled by the mirrored Gaussians with respect to the reflection plane. The transmission and reflection components are blended according to a Fresnel-based, view-dependent weighting scheme, allowing for faithful synthesis of complex appearance effects under varying viewpoints. To effectively optimize TR-Gaussians, we develop a multi-stage optimization framework incorporating color and geometry constraints and an opacity perturbation mechanism. Experiments on different datasets demonstrate that TR-Gaussians achieve real-time, high-fidelity novel view synthesis in scenes with planar transmission and reflection, and outperform state-of-the-art approaches both quantitatively and qualitatively.
PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025



A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
Vision-G1: Towards General Vision Language Reasoning with Multi-Domain Data Curation
Aug 18, 2025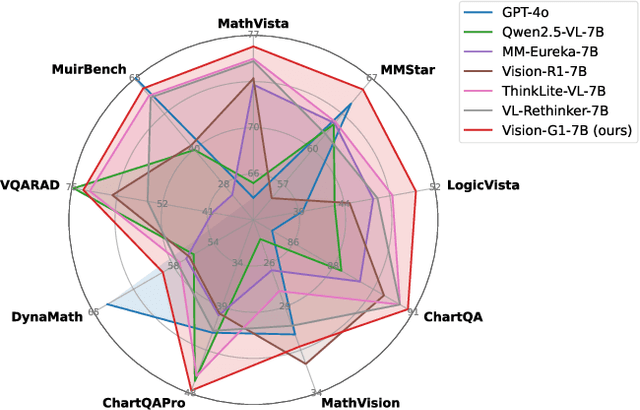

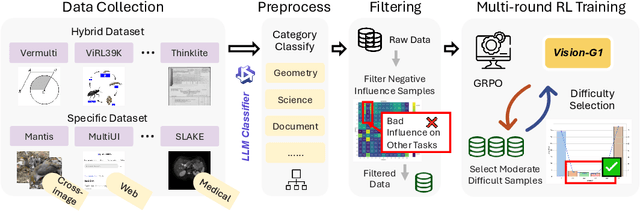

Despite their success, current training pipelines for reasoning VLMs focus on a limited range of tasks, such as mathematical and logical reasoning. As a result, these models face difficulties in generalizing their reasoning capabilities to a wide range of domains, primarily due to the scarcity of readily available and verifiable reward data beyond these narrowly defined areas. Moreover, integrating data from multiple domains is challenging, as the compatibility between domain-specific datasets remains uncertain. To address these limitations, we build a comprehensive RL-ready visual reasoning dataset from 46 data sources across 8 dimensions, covering a wide range of tasks such as infographic, mathematical, spatial, cross-image, graphic user interface, medical, common sense and general science. We propose an influence function based data selection and difficulty based filtering strategy to identify high-quality training samples from this dataset. Subsequently, we train the VLM, referred to as Vision-G1, using multi-round RL with a data curriculum to iteratively improve its visual reasoning capabilities. Our model achieves state-of-the-art performance across various visual reasoning benchmarks, outperforming similar-sized VLMs and even proprietary models like GPT-4o and Gemini-1.5 Flash. The model, code and dataset are publicly available at https://github.com/yuh-zha/Vision-G1.
Can Large Pretrained Depth Estimation Models Help With Image Dehazing?
Aug 01, 2025Image dehazing remains a challenging problem due to the spatially varying nature of haze in real-world scenes. While existing methods have demonstrated the promise of large-scale pretrained models for image dehazing, their architecture-specific designs hinder adaptability across diverse scenarios with different accuracy and efficiency requirements. In this work, we systematically investigate the generalization capability of pretrained depth representations-learned from millions of diverse images-for image dehazing. Our empirical analysis reveals that the learned deep depth features maintain remarkable consistency across varying haze levels. Building on this insight, we propose a plug-and-play RGB-D fusion module that seamlessly integrates with diverse dehazing architectures. Extensive experiments across multiple benchmarks validate both the effectiveness and broad applicability of our approach.
Motion-example-controlled Co-speech Gesture Generation Leveraging Large Language Models
Jul 27, 2025The automatic generation of controllable co-speech gestures has recently gained growing attention. While existing systems typically achieve gesture control through predefined categorical labels or implicit pseudo-labels derived from motion examples, these approaches often compromise the rich details present in the original motion examples. We present MECo, a framework for motion-example-controlled co-speech gesture generation by leveraging large language models (LLMs). Our method capitalizes on LLMs' comprehension capabilities through fine-tuning to simultaneously interpret speech audio and motion examples, enabling the synthesis of gestures that preserve example-specific characteristics while maintaining speech congruence. Departing from conventional pseudo-labeling paradigms, we position motion examples as explicit query contexts within the prompt structure to guide gesture generation. Experimental results demonstrate state-of-the-art performance across three metrics: Fr\'echet Gesture Distance (FGD), motion diversity, and example-gesture similarity. Furthermore, our framework enables granular control of individual body parts and accommodates diverse input modalities including motion clips, static poses, human video sequences, and textual descriptions. Our code, pre-trained models, and videos are available at https://robinwitch.github.io/MECo-Page.