 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSA3D: Text-Conditioned Assisted Self-Supervised Framework for Automatic Dental Abutment Design
Dec 12, 2025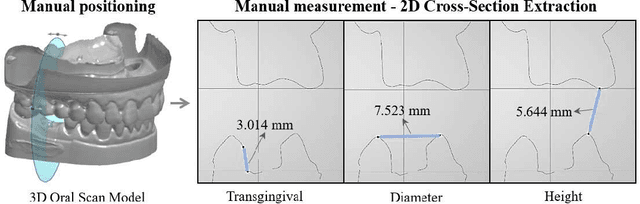
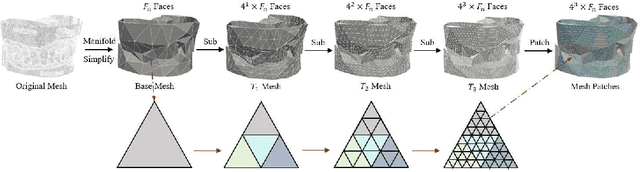
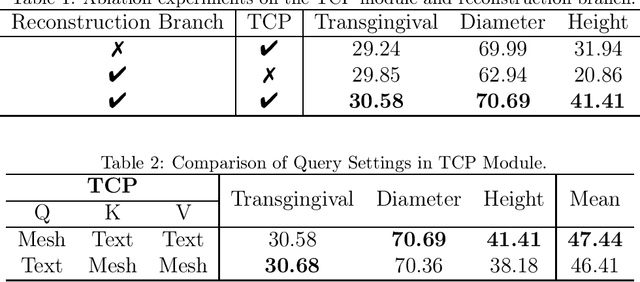
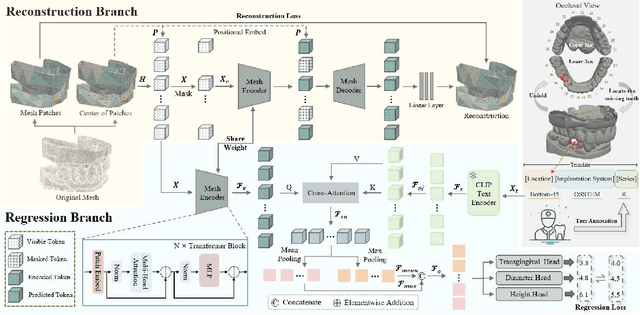
Abutment design is a critical step in dental implant restoration. However, manual design involves tedious measurement and fitting, and research on automating this process with AI is limited, due to the unavailability of large annotated datasets. Although self-supervised learning (SSL) can alleviate data scarcity, its need for pre-training and fine-tuning results in high computational costs and long training times. In this paper, we propose a Self-supervised assisted automatic abutment design framework (SS$A^3$D), which employs a dual-branch architecture with a reconstruction branch and a regression branch. The reconstruction branch learns to restore masked intraoral scan data and transfers the learned structural information to the regression branch. The regression branch then predicts the abutment parameters under supervised learning, which eliminates the separate pre-training and fine-tuning process. We also design a Text-Conditioned Prompt (TCP) module to incorporate clinical information (such as implant location, system, and series) into SS$A^3$D. This guides the network to focus on relevant regions and constrains the parameter predictions. Extensive experiments on a collected dataset show that SS$A^3$D saves half of the training time and achieves higher accuracy than traditional SSL methods. It also achieves state-of-the-art performance compared to other methods, significantly improving the accuracy and efficiency of automated abutment design.
Cross-Frequency Collaborative Training Network and Dataset for Semi-supervised First Molar Root Canal Segmentation
Apr 16, 2025Root canal (RC) treatment is a highly delicate and technically complex procedure in clinical practice, heavily influenced by the clinicians' experience and subjective judgment. Deep learning has made significant advancements in the field of computer-aided diagnosis (CAD) because it can provide more objective and accurate diagnostic results. However, its application in RC treatment is still relatively rare, mainly due to the lack of public datasets in this field. To address this issue, in this paper, we established a First Molar Root Canal segmentation dataset called FMRC-2025. Additionally, to alleviate the workload of manual annotation for dentists and fully leverage the unlabeled data, we designed a Cross-Frequency Collaborative training semi-supervised learning (SSL) Network called CFC-Net. It consists of two components: (1) Cross-Frequency Collaborative Mean Teacher (CFC-MT), which introduces two specialized students (SS) and one comprehensive teacher (CT) for collaborative multi-frequency training. The CT and SS are trained on different frequency components while fully integrating multi-frequency knowledge through cross and full frequency consistency supervisions. (2) Uncertainty-guided Cross-Frequency Mix (UCF-Mix) mechanism enables the network to generate high-confidence pseudo-labels while learning to integrate multi-frequency information and maintaining the structural integrity of the targets. Extensive experiments on FMRC-2025 and three public dental datasets demonstrate that CFC-MT is effective for RC segmentation and can also exhibit strong generalizability on other dental segmentation tasks, outperforming state-of-the-art SSL medical image segmentation methods. Codes and dataset will be released.
Spatial-Frequency Dual Progressive Attention Network For Medical Image Segmentation
Jun 12, 2024In medical images, various types of lesions often manifest significant differences in their shape and texture. Accurate medical image segmentation demands deep learning models with robust capabilities in multi-scale and boundary feature learning. However, previous networks still have limitations in addressing the above issues. Firstly, previous networks simultaneously fuse multi-level features or employ deep supervision to enhance multi-scale learning. However, this may lead to feature redundancy and excessive computational overhead, which is not conducive to network training and clinical deployment. Secondly, the majority of medical image segmentation networks exclusively learn features in the spatial domain, disregarding the abundant global information in the frequency domain. This results in a bias towards low-frequency components, neglecting crucial high-frequency information. To address these problems, we introduce SF-UNet, a spatial-frequency dual-domain attention network. It comprises two main components: the Multi-scale Progressive Channel Attention (MPCA) block, which progressively extract multi-scale features across adjacent encoder layers, and the lightweight Frequency-Spatial Attention (FSA) block, with only 0.05M parameters, enabling concurrent learning of texture and boundary features from both spatial and frequency domains. We validate the effectiveness of the proposed SF-UNet on three public datasets. Experimental results show that compared to previous state-of-the-art (SOTA) medical image segmentation networks, SF-UNet achieves the best performance, and achieves up to 9.4\% and 10.78\% improvement in DSC and IOU. Codes will be released at https://github.com/nkicsl/SF-UNet.
FRCNet Frequency and Region Consistency for Semi-supervised Medical Image Segmentation
May 26, 2024Limited labeled data hinder the application of deep learning in medical domain. In clinical practice, there are sufficient unlabeled data that are not effectively used, and semi-supervised learning (SSL) is a promising way for leveraging these unlabeled data. However, existing SSL methods ignore frequency domain and region-level information and it is important for lesion regions located at low frequencies and with significant scale changes. In this paper, we introduce two consistency regularization strategies for semi-supervised medical image segmentation, including frequency domain consistency (FDC) to assist the feature learning in frequency domain and multi-granularity region similarity consistency (MRSC) to perform multi-scale region-level local context information feature learning. With the help of the proposed FDC and MRSC, we can leverage the powerful feature representation capability of them in an effective and efficient way. We perform comprehensive experiments on two datasets, and the results show that our method achieves large performance gains and exceeds other state-of-the-art methods.
DVPT: Dynamic Visual Prompt Tuning of Large Pre-trained Models for Medical Image Analysis
Jul 19, 2023



Limited labeled data makes it hard to train models from scratch in medical domain, and an important paradigm is pre-training and then fine-tuning. Large pre-trained models contain rich representations, which can be adapted to downstream medical tasks. However, existing methods either tune all the parameters or the task-specific layers of the pre-trained models, ignoring the input variations of medical images, and thus they are not efficient or effective. In this work, we aim to study parameter-efficient fine-tuning (PEFT) for medical image analysis, and propose a dynamic visual prompt tuning method, named DVPT. It can extract knowledge beneficial to downstream tasks from large models with a few trainable parameters. Firstly, the frozen features are transformed by an lightweight bottleneck layer to learn the domain-specific distribution of downstream medical tasks, and then a few learnable visual prompts are used as dynamic queries and then conduct cross-attention with the transformed features, attempting to acquire sample-specific knowledge that are suitable for each sample. Finally, the features are projected to original feature dimension and aggregated with the frozen features. This DVPT module can be shared between different Transformer layers, further reducing the trainable parameters. To validate DVPT, we conduct extensive experiments with different pre-trained models on medical classification and segmentation tasks. We find such PEFT method can not only efficiently adapt the pre-trained models to the medical domain, but also brings data efficiency with partial labeled data. For example, with 0.5\% extra trainable parameters, our method not only outperforms state-of-the-art PEFT methods, even surpasses the full fine-tuning by more than 2.20\% Kappa score on medical classification task. It can saves up to 60\% labeled data and 99\% storage cost of ViT-B/16.
Progressive Multi-scale Consistent Network for Multi-class Fundus Lesion Segmentation
May 31, 2022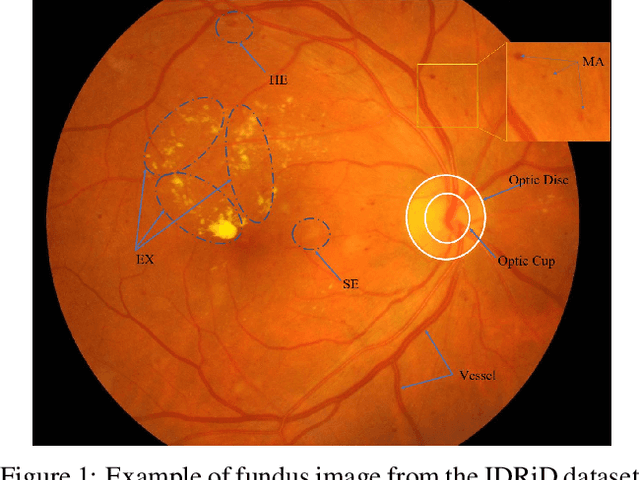
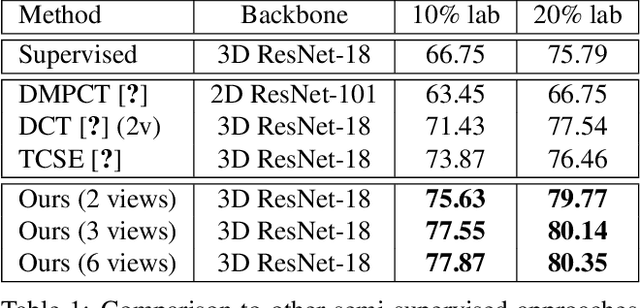
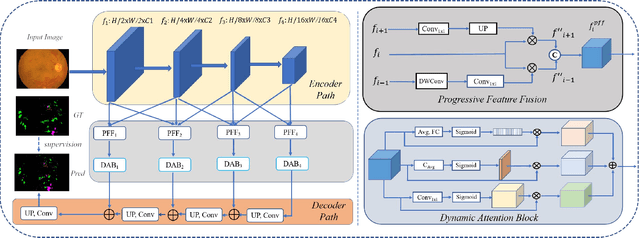
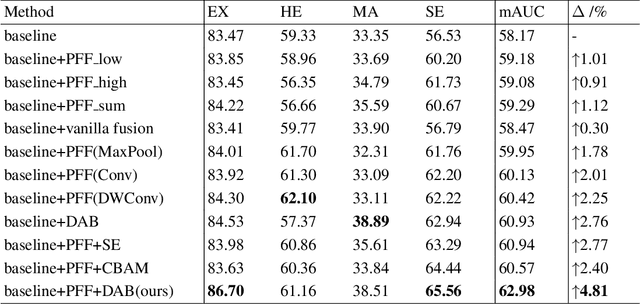
Effectively integrating multi-scale information is of considerable significance for the challenging multi-class segmentation of fundus lesions because different lesions vary significantly in scales and shapes. Several methods have been proposed to successfully handle the multi-scale object segmentation. However, two issues are not considered in previous studies. The first is the lack of interaction between adjacent feature levels, and this will lead to the deviation of high-level features from low-level features and the loss of detailed cues. The second is the conflict between the low-level and high-level features, this occurs because they learn different scales of features, thereby confusing the model and decreasing the accuracy of the final prediction. In this paper, we propose a progressive multi-scale consistent network (PMCNet) that integrates the proposed progressive feature fusion (PFF) block and dynamic attention block (DAB) to address the aforementioned issues. Specifically, PFF block progressively integrates multi-scale features from adjacent encoding layers, facilitating feature learning of each layer by aggregating fine-grained details and high-level semantics. As features at different scales should be consistent, DAB is designed to dynamically learn the attentive cues from the fused features at different scales, thus aiming to smooth the essential conflicts existing in multi-scale features. The two proposed PFF and DAB blocks can be integrated with the off-the-shelf backbone networks to address the two issues of multi-scale and feature inconsistency in the multi-class segmentation of fundus lesions, which will produce better feature representation in the feature space. Experimental results on three public datasets indicate that the proposed method is more effective than recent state-of-the-art methods.