 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Aware Guidance for Blind Image Restoration via Diffusion Models
Nov 19, 2024



Blind image restoration remains a significant challenge in low-level vision tasks. Recently, denoising diffusion models have shown remarkable performance in image synthesis. Guided diffusion models, leveraging the potent generative priors of pre-trained models along with a differential guidance loss, have achieved promising results in blind image restoration. However, these models typically consider data consistency solely in the spatial domain, often resulting in distorted image content. In this paper, we propose a novel frequency-aware guidance loss that can be integrated into various diffusion models in a plug-and-play manner. Our proposed guidance loss, based on 2D discrete wavelet transform, simultaneously enforces content consistency in both the spatial and frequency domains. Experimental results demonstrate the effectiveness of our method in three blind restoration tasks: blind image deblurring, imaging through turbulence, and blind restoration for multiple degradations. Notably, our method achieves a significant improvement in PSNR score, with a remarkable enhancement of 3.72\,dB in image deblurring. Moreover, our method exhibits superior capability in generating images with rich details and reduced distortion, leading to the best visual quality.
Towards Multi-View Consistent Style Transfer with One-Step Diffusion via Vision Conditioning
Nov 15, 2024



The stylization of 3D scenes is an increasingly attractive topic in 3D vision. Although image style transfer has been extensively researched with promising results, directly applying 2D style transfer methods to 3D scenes often fails to preserve the structural and multi-view properties of 3D environments, resulting in unpleasant distortions in images from different viewpoints. To address these issues, we leverage the remarkable generative prior of diffusion-based models and propose a novel style transfer method, OSDiffST, based on a pre-trained one-step diffusion model (i.e., SD-Turbo) for rendering diverse styles in multi-view images of 3D scenes. To efficiently adapt the pre-trained model for multi-view style transfer on small datasets, we introduce a vision condition module to extract style information from the reference style image to serve as conditional input for the diffusion model and employ LoRA in diffusion model for adaptation. Additionally, we consider color distribution alignment and structural similarity between the stylized and content images using two specific loss functions. As a result, our method effectively preserves the structural information and multi-view consistency in stylized images without any 3D information. Experiments show that our method surpasses other promising style transfer methods in synthesizing various styles for multi-view images of 3D scenes. Stylized images from different viewpoints generated by our method achieve superior visual quality, with better structural integrity and less distortion. The source code is available at https://github.com/YushenZuo/OSDiffST.
Geometric Distortion Guided Transformer for Omnidirectional Image Super-Resolution
Jun 16, 2024



As virtual and augmented reality applications gain popularity, omnidirectional image (ODI) super-resolution has become increasingly important. Unlike 2D plain images that are formed on a plane, ODIs are projected onto spherical surfaces. Applying established image super-resolution methods to ODIs, therefore, requires performing equirectangular projection (ERP) to map the ODIs onto a plane. ODI super-resolution needs to take into account geometric distortion resulting from ERP. However, without considering such geometric distortion of ERP images, previous deep-learning-based methods only utilize a limited range of pixels and may easily miss self-similar textures for reconstruction. In this paper, we introduce a novel Geometric Distortion Guided Transformer for Omnidirectional image Super-Resolution (GDGT-OSR). Specifically, a distortion modulated rectangle-window self-attention mechanism, integrated with deformable self-attention, is proposed to better perceive the distortion and thus involve more self-similar textures. Distortion modulation is achieved through a newly devised distortion guidance generator that produces guidance by exploiting the variability of distortion across latitudes. Furthermore, we propose a dynamic feature aggregation scheme to adaptively fuse the features from different self-attention modules. We present extensive experimental results on public datasets and show that the new GDGT-OSR outperforms methods in existing literature.
FactLLaMA: Optimizing Instruction-Following Language Models with External Knowledge for Automated Fact-Checking
Sep 01, 2023



Automatic fact-checking plays a crucial role in combating the spread of misinformation. Large Language Models (LLMs) and Instruction-Following variants, such as InstructGPT and Alpaca, have shown remarkable performance in various natural language processing tasks. However, their knowledge may not always be up-to-date or sufficient, potentially leading to inaccuracies in fact-checking. To address this limitation, we propose combining the power of instruction-following language models with external evidence retrieval to enhance fact-checking performance. Our approach involves leveraging search engines to retrieve relevant evidence for a given input claim. This external evidence serves as valuable supplementary information to augment the knowledge of the pretrained language model. Then, we instruct-tune an open-sourced language model, called LLaMA, using this evidence, enabling it to predict the veracity of the input claim more accurately. To evaluate our method, we conducted experiments on two widely used fact-checking datasets: RAWFC and LIAR. The results demonstrate that our approach achieves state-of-the-art performance in fact-checking tasks. By integrating external evidence, we bridge the gap between the model's knowledge and the most up-to-date and sufficient context available, leading to improved fact-checking outcomes. Our findings have implications for combating misinformation and promoting the dissemination of accurate information on online platforms. Our released materials are accessible at: https://thcheung.github.io/factllama.
AMSP-UOD: When Vortex Convolution and Stochastic Perturbation Meet Underwater Object Detection
Aug 23, 2023



In this paper, we present a novel Amplitude-Modulated Stochastic Perturbation and Vortex Convolutional Network, AMSP-UOD, designed for underwater object detection. AMSP-UOD specifically addresses the impact of non-ideal imaging factors on detection accuracy in complex underwater environments. To mitigate the influence of noise on object detection performance, we propose AMSP Vortex Convolution (AMSP-VConv) to disrupt the noise distribution, enhance feature extraction capabilities, effectively reduce parameters, and improve network robustness. We design the Feature Association Decoupling Cross Stage Partial (FAD-CSP) module, which strengthens the association of long and short-range features, improving the network performance in complex underwater environments. Additionally, our sophisticated post-processing method, based on non-maximum suppression with aspect-ratio similarity thresholds, optimizes detection in dense scenes, such as waterweed and schools of fish, improving object detection accuracy. Extensive experiments on the URPC and RUOD datasets demonstrate that our method outperforms existing state-of-the-art methods in terms of accuracy and noise immunity. AMSP-UOD proposes an innovative solution with the potential for real-world applications. Code will be made publicly available.
AGTGAN: Unpaired Image Translation for Photographic Ancient Character Generation
Mar 13, 2023



The study of ancient writings has great value for archaeology and philology. Essential forms of material are photographic characters, but manual photographic character recognition is extremely time-consuming and expertise-dependent. Automatic classification is therefore greatly desired. However, the current performance is limited due to the lack of annotated data. Data generation is an inexpensive but useful solution for data scarcity. Nevertheless, the diverse glyph shapes and complex background textures of photographic ancient characters make the generation task difficult, leading to the unsatisfactory results of existing methods. In this paper, we propose an unsupervised generative adversarial network called AGTGAN. By the explicit global and local glyph shape style modeling followed by the stroke-aware texture transfer, as well as an associate adversarial learning mechanism, our method can generate characters with diverse glyphs and realistic textures. We evaluate our approach on the photographic ancient character datasets, e.g., OBC306 and CSDD. Our method outperforms the state-of-the-art approaches in various metrics and performs much better in terms of the diversity and authenticity of generated samples. With our generated images, experiments on the largest photographic oracle bone character dataset show that our method can achieve a significant increase in classification accuracy, up to 16.34%.
Deep Learning Methods for Calibrated Photometric Stereo and Beyond: A Survey
Dec 16, 2022



Photometric stereo recovers the surface normals of an object from multiple images with varying shading cues, i.e., modeling the relationship between surface orientation and intensity at each pixel. Photometric stereo prevails in superior per-pixel resolution and fine reconstruction details. However, it is a complicated problem because of the non-linear relationship caused by non-Lambertian surface reflectance. Recently, various deep learning methods have shown a powerful ability in the context of photometric stereo against non-Lambertian surfaces. This paper provides a comprehensive review of existing deep learning-based calibrated photometric stereo methods. We first analyze these methods from different perspectives, including input processing, supervision, and network architecture. We summarize the performance of deep learning photometric stereo models on the most widely-used benchmark data set. This demonstrates the advanced performance of deep learning-based photometric stereo methods. Finally, we give suggestions and propose future research trends based on the limitations of existing models.
Online Video Super-Resolution with Convolutional Kernel Bypass Graft
Aug 04, 2022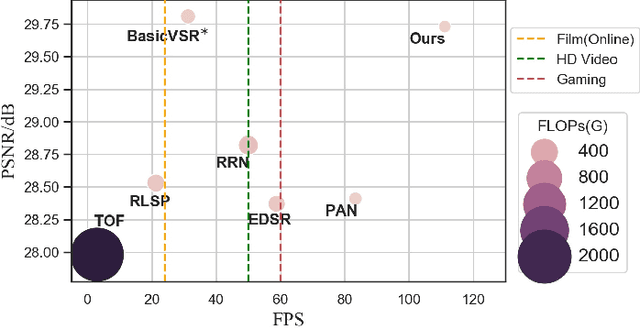

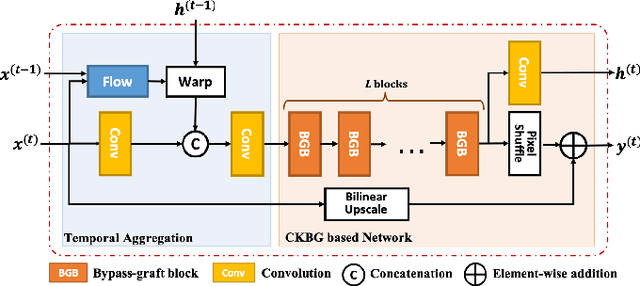
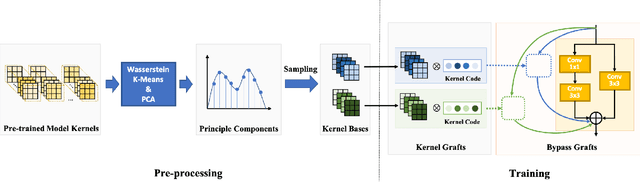
Deep learning-based models have achieved remarkable performance in video super-resolution (VSR) in recent years, but most of these models are less applicable to online video applications. These methods solely consider the distortion quality and ignore crucial requirements for online applications, e.g., low latency and low model complexity. In this paper, we focus on online video transmission, in which VSR algorithms are required to generate high-resolution video sequences frame by frame in real time. To address such challenges, we propose an extremely low-latency VSR algorithm based on a novel kernel knowledge transfer method, named convolutional kernel bypass graft (CKBG). First, we design a lightweight network structure that does not require future frames as inputs and saves extra time costs for caching these frames. Then, our proposed CKBG method enhances this lightweight base model by bypassing the original network with ``kernel grafts'', which are extra convolutional kernels containing the prior knowledge of external pretrained image SR models. In the testing phase, we further accelerate the grafted multi-branch network by converting it into a simple single-path structure. Experiment results show that our proposed method can process online video sequences up to 110 FPS, with very low model complexity and competitive SR performance.
Multi-scale Sampling and Aggregation Network For High Dynamic Range Imaging
Aug 04, 2022

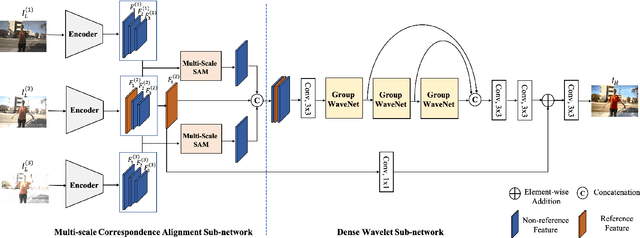
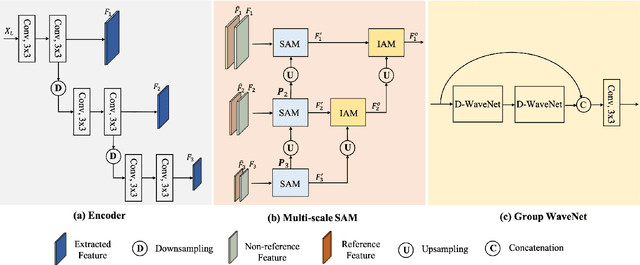
High dynamic range (HDR) imaging is a fundamental problem in image processing, which aims to generate well-exposed images, even in the presence of varying illumination in the scenes. In recent years, multi-exposure fusion methods have achieved remarkable results, which merge multiple low dynamic range (LDR) images, captured with different exposures, to generate corresponding HDR images. However, synthesizing HDR images in dynamic scenes is still challenging and in high demand. There are two challenges in producing HDR images: 1). Object motion between LDR images can easily cause undesirable ghosting artifacts in the generated results. 2). Under and overexposed regions often contain distorted image content, because of insufficient compensation for these regions in the merging stage. In this paper, we propose a multi-scale sampling and aggregation network for HDR imaging in dynamic scenes. To effectively alleviate the problems caused by small and large motions, our method implicitly aligns LDR images by sampling and aggregating high-correspondence features in a coarse-to-fine manner. Furthermore, we propose a densely connected network based on discrete wavelet transform for performance improvement, which decomposes the input into several non-overlapping frequency subbands and adaptively performs compensation in the wavelet domain. Experiments show that our proposed method can achieve state-of-the-art performances under diverse scenes, compared to other promising HDR imaging methods. In addition, the HDR images generated by our method contain cleaner and more detailed content, with fewer distortions, leading to better visual quality.
Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark
Jan 03, 2022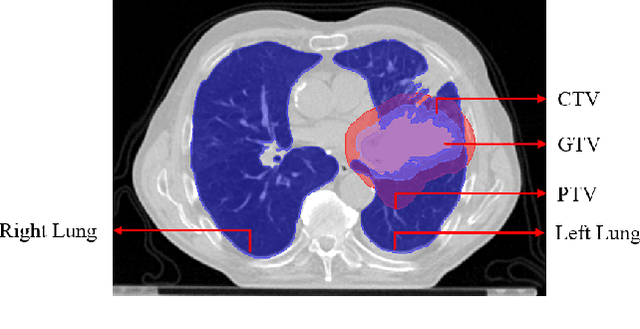
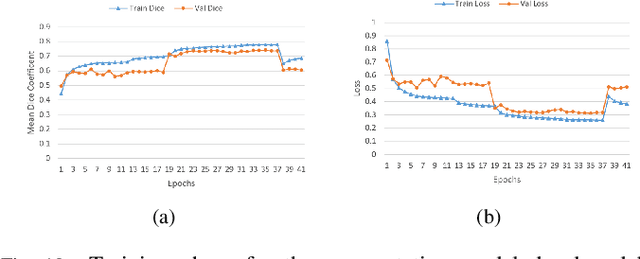
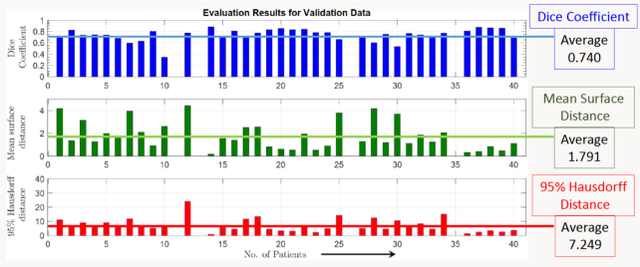
Lung cancer is one of the deadliest cancers, and in part its effective diagnosis and treatment depend on the accurate delineation of the tumor. Human-centered segmentation, which is currently the most common approach, is subject to inter-observer variability, and is also time-consuming, considering the fact that only experts are capable of providing annotations. Automatic and semi-automatic tumor segmentation methods have recently shown promising results. However, as different researchers have validated their algorithms using various datasets and performance metrics, reliably evaluating these methods is still an open challenge. The goal of the Lung-Originated Tumor Segmentation from Computed Tomography Scan (LOTUS) Benchmark created through 2018 IEEE Video and Image Processing (VIP) Cup competition, is to provide a unique dataset and pre-defined metrics, so that different researchers can develop and evaluate their methods in a unified fashion. The 2018 VIP Cup started with a global engagement from 42 countries to access the competition data. At the registration stage, there were 129 members clustered into 28 teams from 10 countries, out of which 9 teams made it to the final stage and 6 teams successfully completed all the required tasks. In a nutshell, all the algorithms proposed during the competition, are based on deep learning models combined with a false positive reduction technique. Methods developed by the three finalists show promising results in tumor segmentation, however, more effort should be put into reducing the false positive rate. This competition manuscript presents an overview of the VIP-Cup challenge, along with the proposed algorithms and results.