 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Triaging for Fast Reading Comprehension
Sep 28, 2019
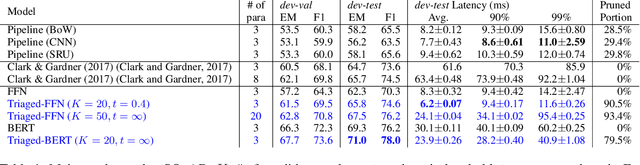
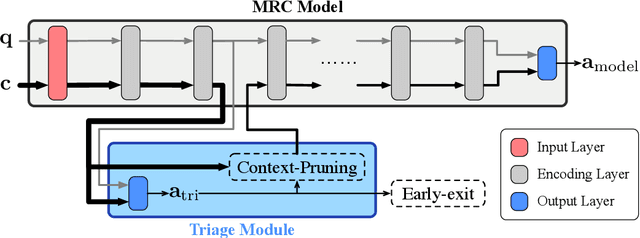
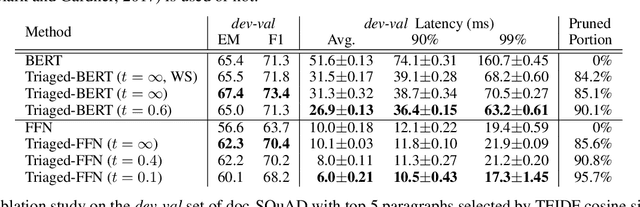
Although according to several benchmarks automatic machine reading comprehension (MRC) systems have recently reached super-human performance, less attention has been paid to their computational efficiency. However, efficiency is of crucial importance for training and deployment in real world applications. This paper introduces Integrated Triaging, a framework that prunes almost all context in early layers of a network, leaving the remaining (deep) layers to scan only a tiny fraction of the full corpus. This pruning drastically increases the efficiency of MRC models and further prevents the later layers from overfitting to prevalent short paragraphs in the training set. Our framework is extremely flexible and naturally applicable to a wide variety of models. Our experiment on doc-SQuAD and TriviaQA tasks demonstrates its effectiveness in consistently improving both speed and quality of several diverse MRC models.
Positional Normalization
Jul 09, 2019
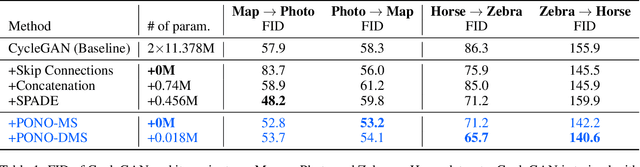


A widely deployed method for reducing the training time of deep neural networks is to normalize activations at each layer. Although various normalization schemes have been proposed, they all follow a common theme: normalize across spatial dimensions and discard the extracted statistics. In this paper, we propose a novel normalization method that noticeably departs from this convention. Our approach, which we refer to as Positional Normalization (PONO), normalizes exclusively across channels --- a naturally appealing dimension, which captures the first and second moments of features extracted at a particular image position. We argue that these moments convey structural information about the input image and the extracted features, which opens a new avenue along which a network can benefit from feature normalization: Instead of disregarding the PONO normalization constants, we propose to re-inject them into later layers to preserve or transfer structural information in generative networks.
Pseudo-LiDAR++: Accurate Depth for 3D Object Detection in Autonomous Driving
Jun 14, 2019
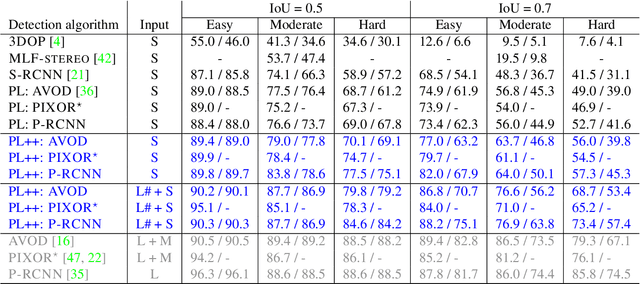
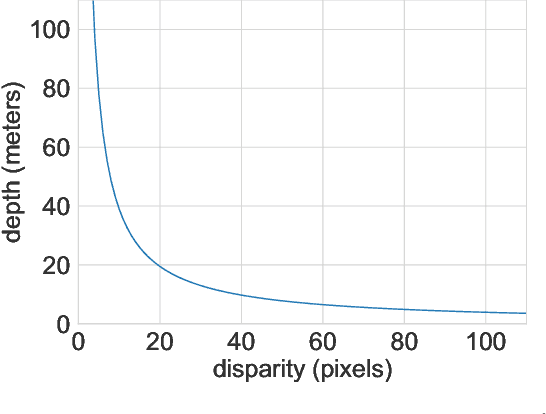
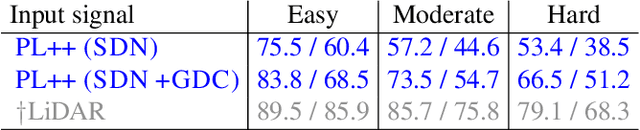
Detecting objects such as cars and pedestrians in 3D plays an indispensable role in autonomous driving. Existing approaches largely rely on expensive LiDAR sensors for accurate depth information. While recently pseudo-LiDAR has been introduced as a promising alternative, at a much lower cost based solely on stereo images, there is still a notable performance gap. In this paper we provide substantial advances to the pseudo-LiDAR framework through improvements in stereo depth estimation. Concretely, we adapt the stereo network architecture and loss function to be more aligned with accurate depth estimation of far away objects (currently the primary weakness of pseudo-LiDAR). Further, we explore the idea to leverage cheaper but extremely sparse LiDAR sensors, which alone provide insufficient information for 3D detection, to de-bias our depth estimation. We propose a depth-propagation algorithm, guided by the initial depth estimates, to diffuse these few exact measurements across the entire depth map. We show on the KITTI object detection benchmark that our combined approach yields substantial improvements in depth estimation and stereo-based 3D object detection --- outperforming the previous state-of-the-art detection accuracy for far-away objects by 40%. Our code will be publicly available at https://github.com/mileyan/Pseudo_Lidar_V2.
Simple Black-box Adversarial Attacks
May 17, 2019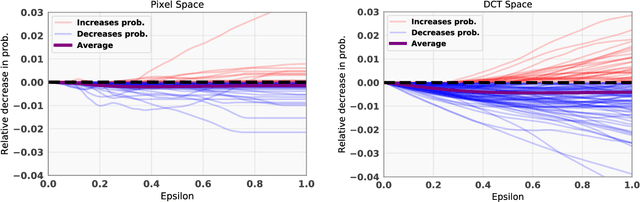

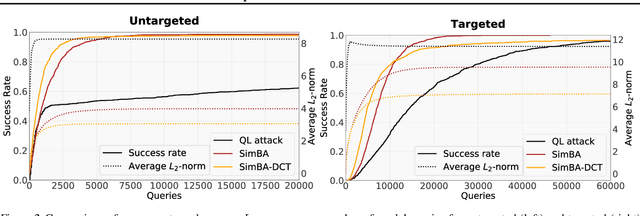
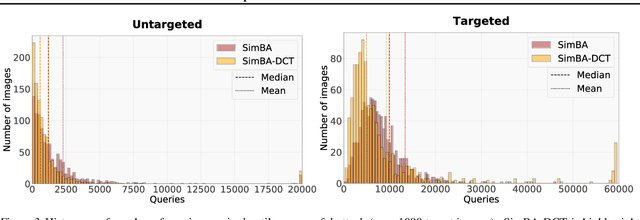
We propose an intriguingly simple method for the construction of adversarial images in the black-box setting. In constrast to the white-box scenario, constructing black-box adversarial images has the additional constraint on query budget, and efficient attacks remain an open problem to date. With only the mild assumption of continuous-valued confidence scores, our highly query-efficient algorithm utilizes the following simple iterative principle: we randomly sample a vector from a predefined orthonormal basis and either add or subtract it to the target image. Despite its simplicity, the proposed method can be used for both untargeted and targeted attacks -- resulting in previously unprecedented query efficiency in both settings. We demonstrate the efficacy and efficiency of our algorithm on several real world settings including the Google Cloud Vision API. We argue that our proposed algorithm should serve as a strong baseline for future black-box attacks, in particular because it is extremely fast and its implementation requires less than 20 lines of PyTorch code.
BERTScore: Evaluating Text Generation with BERT
Apr 21, 2019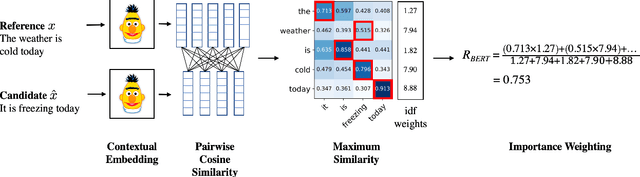
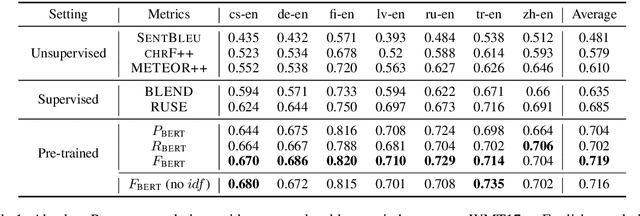
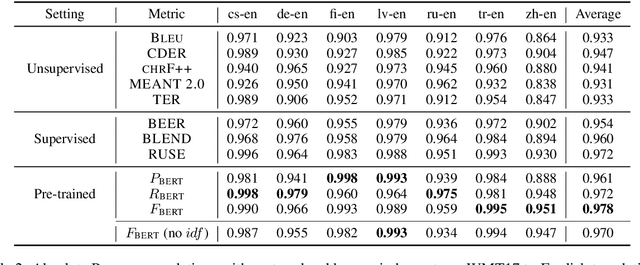
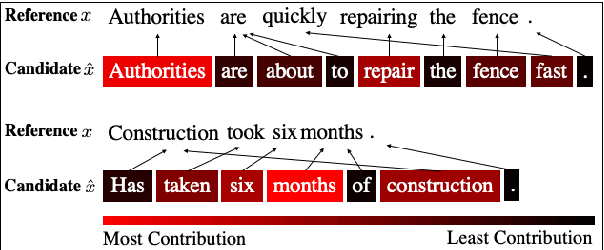
We propose BERTScore, an automatic evaluation metric for text generation. Analogous to common metrics, \method computes a similarity score for each token in the candidate sentence with each token in the reference. However, instead of looking for exact matches, we compute similarity using contextualized BERT embeddings. We evaluate on several machine translation and image captioning benchmarks, and show that BERTScore correlates better with human judgments than existing metrics, often significantly outperforming even task-specific supervised metrics.
Exact Gaussian Processes on a Million Data Points
Mar 19, 2019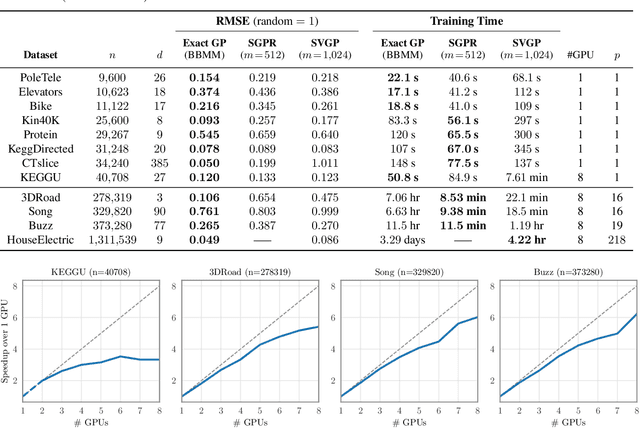
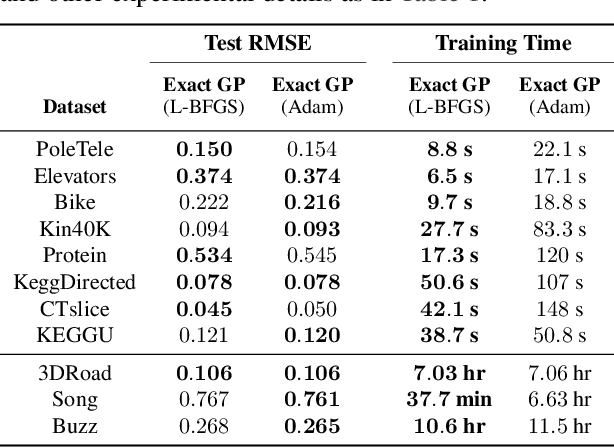
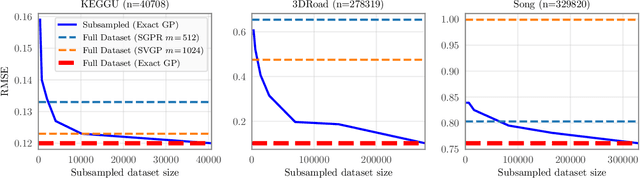
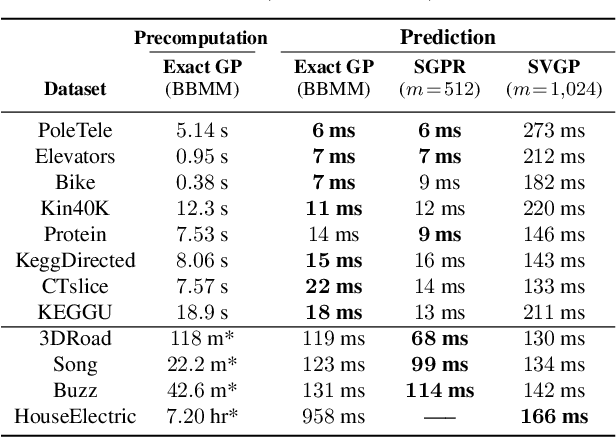
Gaussian processes (GPs) are flexible models with state-of-the-art performance on many impactful applications. However, computational constraints with standard inference procedures have limited exact GPs to problems with fewer than about ten thousand training points, necessitating approximations for larger datasets. In this paper, we develop a scalable approach for exact GPs that leverages multi-GPU parallelization and methods like linear conjugate gradients, accessing the kernel matrix only through matrix multiplication. By partitioning and distributing kernel matrix multiplies, we demonstrate that an exact GP can be trained on over a million points in 3 days using 8 GPUs and can compute predictive means and variances in under a second using 1 GPU at test time. Moreover, we perform the first-ever comparison of exact GPs against state-of-the-art scalable approximations on large-scale regression datasets with $10^4-10^6$ data points, showing dramatic performance improvements.
FastFusionNet: New State-of-the-Art for DAWNBench SQuAD
Mar 02, 2019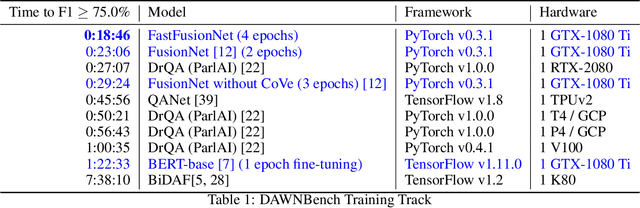
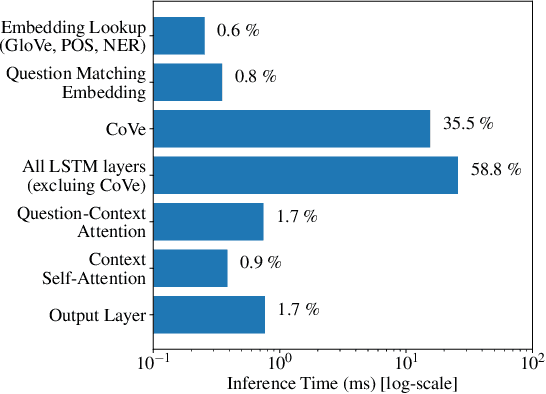
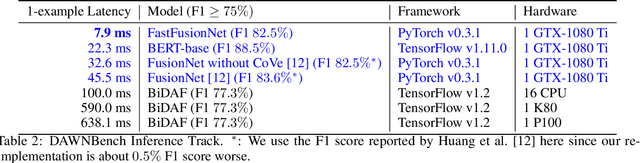
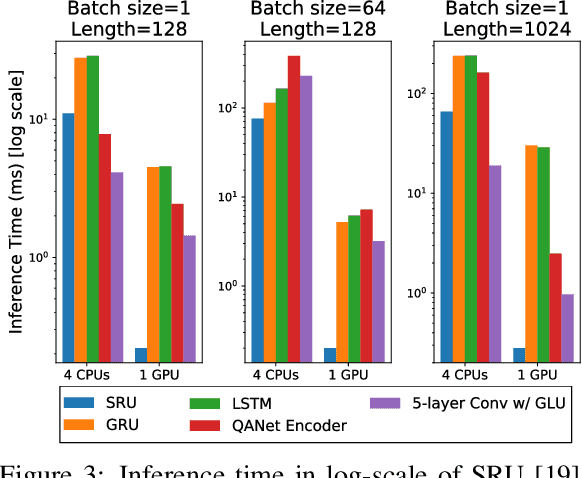
In this technical report, we introduce FastFusionNet, an efficient variant of FusionNet [12]. FusionNet is a high performing reading comprehension architecture, which was designed primarily for maximum retrieval accuracy with less regard towards computational requirements. For FastFusionNets we remove the expensive CoVe layers [21] and substitute the BiLSTMs with far more efficient SRU layers [19]. The resulting architecture obtains state-of-the-art results on DAWNBench [5] while achieving the lowest training and inference time on SQuAD [25] to-date. The code is available at https://github.com/felixgwu/FastFusionNet.
Simplifying Graph Convolutional Networks
Feb 19, 2019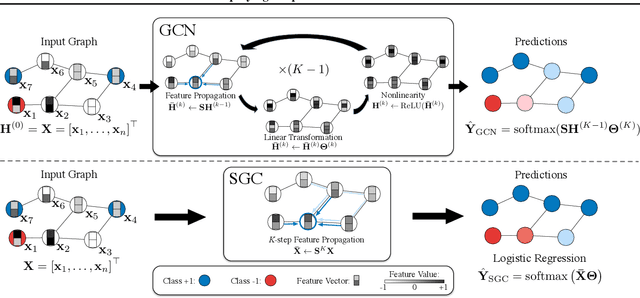
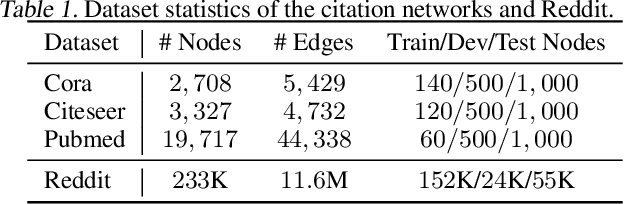
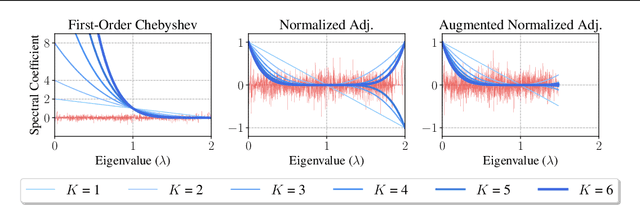
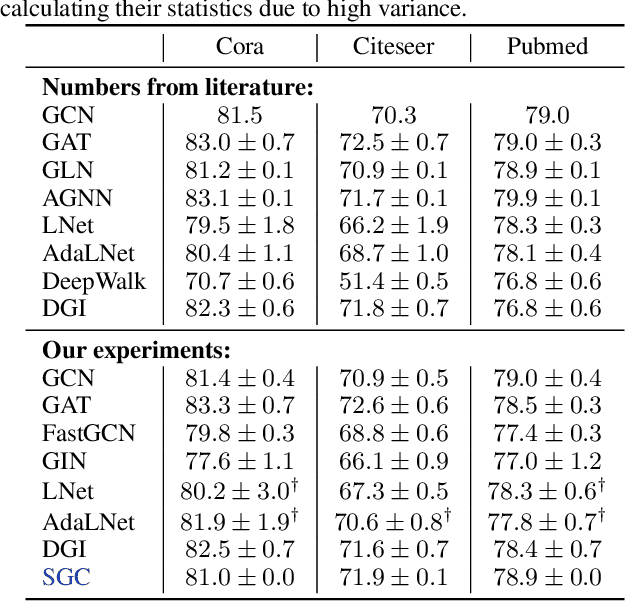
Graph Convolutional Networks (GCNs) and their variants have experienced significant attention and have become the de facto methods for learning graph representations. GCNs derive inspiration primarily from recent deep learning approaches, and as a result, may inherit unnecessary complexity and redundant computation. In this paper, we reduce this excess complexity through successively removing nonlinearities and collapsing weight matrices between consecutive layers. We theoretically analyze the resulting linear model and show that it corresponds to a fixed low-pass filter followed by a linear classifier. Notably, our experimental evaluation demonstrates that these simplifications do not negatively impact accuracy in many downstream applications. Moreover, the resulting model scales to larger datasets, is naturally interpretable, and yields up to two orders of magnitude speedup over FastGCN.
Gradient Regularized Budgeted Boosting
Jan 27, 2019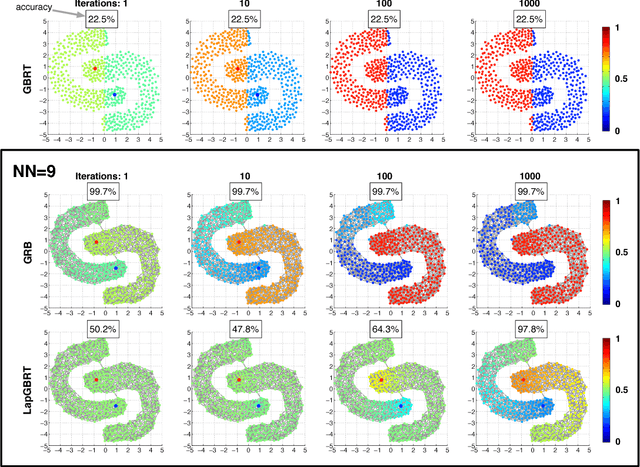
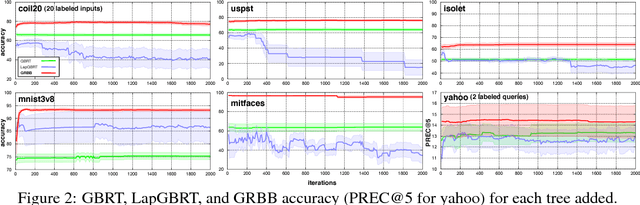
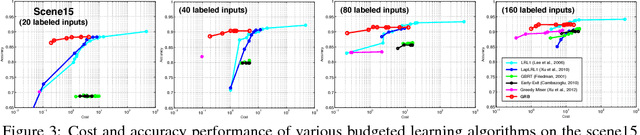
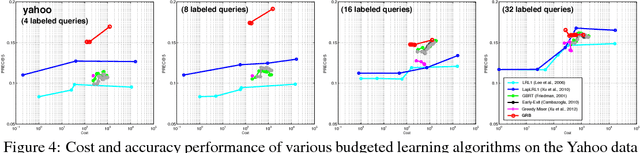
As machine learning transitions increasingly towards real world applications controlling the test-time cost of algorithms becomes more and more crucial. Recent work, such as the Greedy Miser and Speedboost, incorporate test-time budget constraints into the training procedure and learn classifiers that provably stay within budget (in expectation). However, so far, these algorithms are limited to the supervised learning scenario where sufficient amounts of labeled data are available. In this paper we investigate the common scenario where labeled data is scarce but unlabeled data is available in abundance. We propose an algorithm that leverages the unlabeled data (through Laplace smoothing) and learns classifiers with budget constraints. Our model, based on gradient boosted regression trees (GBRT), is, to our knowledge, the first algorithm for semi-supervised budgeted learning.
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving
Jan 18, 2019
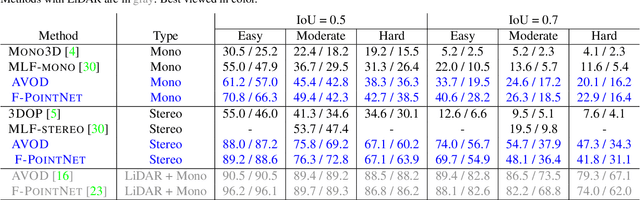


3D object detection is an essential task in autonomous driving. Recent techniques excel with highly accurate detection rates, provided the 3D input data is obtained from precise but expensive LiDAR technology. Approaches based on cheaper monocular or stereo imagery data have, until now, resulted in drastically lower accuracies --- a gap that is commonly attributed to poor image-based depth estimation. However, in this paper we argue that data representation (rather than its quality) accounts for the majority of the difference. Taking the inner workings of convolutional neural networks into consideration, we propose to convert image-based depth maps to pseudo-LiDAR representations --- essentially mimicking LiDAR signal. With this representation we can apply different existing LiDAR-based detection algorithms. On the popular KITTI benchmark, our approach achieves impressive improvements over the existing state-of-the-art in image-based performance --- raising the detection accuracy of objects within 30m range from the previous state-of-the-art of 22% to an unprecedented 74%. At the time of submission our algorithm holds the highest entry on the KITTI 3D object detection leaderboard for stereo image based approaches.