 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Regularized Budgeted Boosting
Jan 27, 2019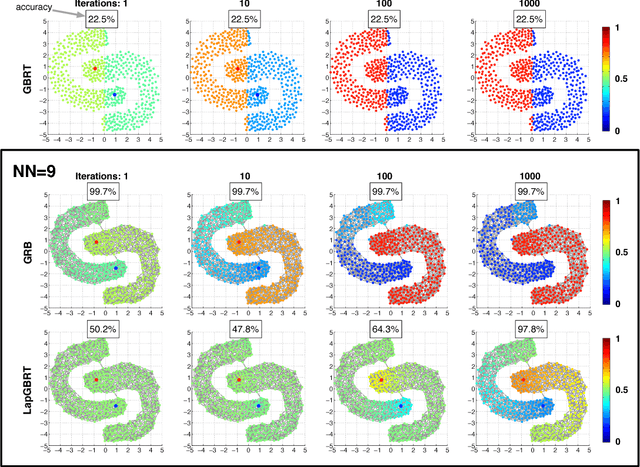
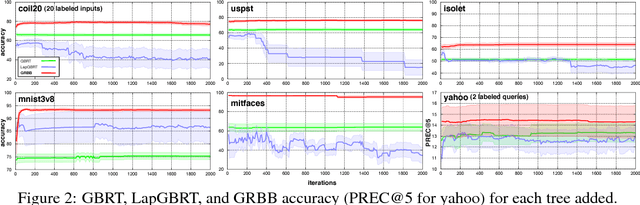
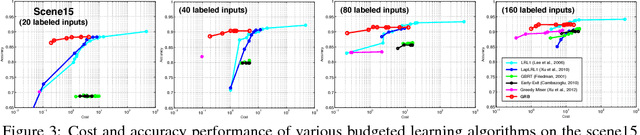
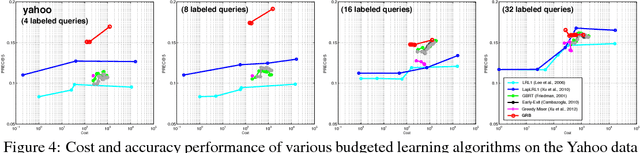
As machine learning transitions increasingly towards real world applications controlling the test-time cost of algorithms becomes more and more crucial. Recent work, such as the Greedy Miser and Speedboost, incorporate test-time budget constraints into the training procedure and learn classifiers that provably stay within budget (in expectation). However, so far, these algorithms are limited to the supervised learning scenario where sufficient amounts of labeled data are available. In this paper we investigate the common scenario where labeled data is scarce but unlabeled data is available in abundance. We propose an algorithm that leverages the unlabeled data (through Laplace smoothing) and learns classifiers with budget constraints. Our model, based on gradient boosted regression trees (GBRT), is, to our knowledge, the first algorithm for semi-supervised budgeted learning.
Gradient Boosted Feature Selection
Jan 13, 2019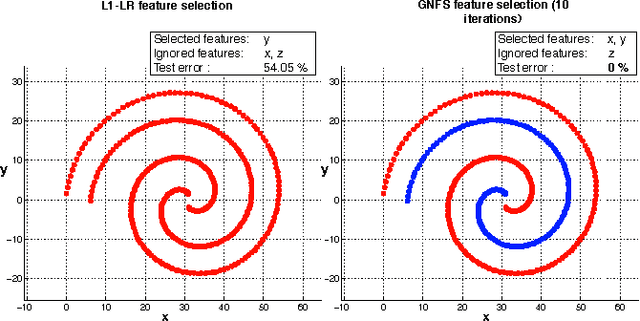

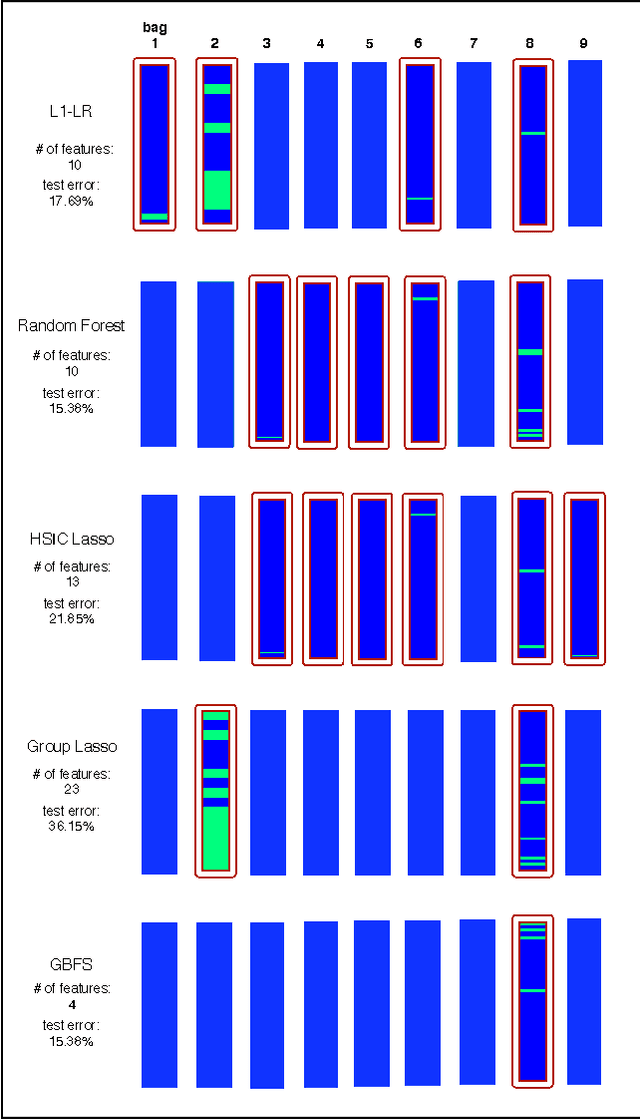
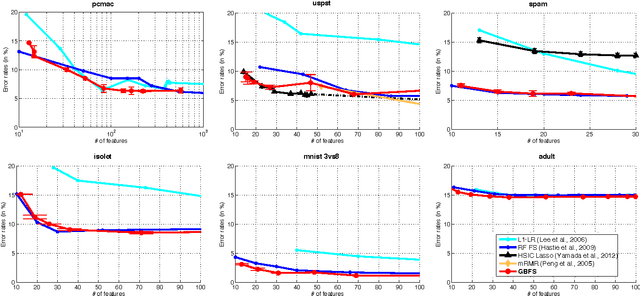
A feature selection algorithm should ideally satisfy four conditions: reliably extract relevant features; be able to identify non-linear feature interactions; scale linearly with the number of features and dimensions; allow the incorporation of known sparsity structure. In this work we propose a novel feature selection algorithm, Gradient Boosted Feature Selection (GBFS), which satisfies all four of these requirements. The algorithm is flexible, scalable, and surprisingly straight-forward to implement as it is based on a modification of Gradient Boosted Trees. We evaluate GBFS on several real world data sets and show that it matches or out-performs other state of the art feature selection algorithms. Yet it scales to larger data set sizes and naturally allows for domain-specific side information.
Rapid Feature Learning with Stacked Linear Denoisers
May 05, 2011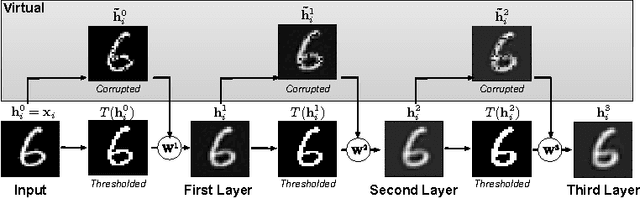

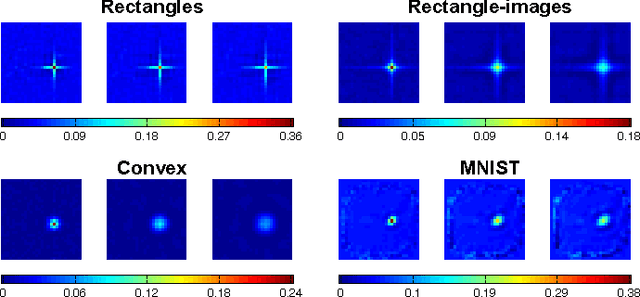
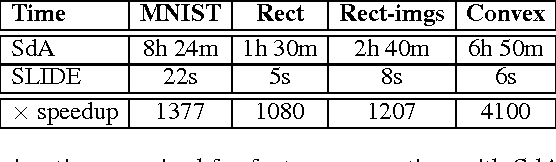
We investigate unsupervised pre-training of deep architectures as feature generators for "shallow" classifiers. Stacked Denoising Autoencoders (SdA), when used as feature pre-processing tools for SVM classification, can lead to significant improvements in accuracy - however, at the price of a substantial increase in computational cost. In this paper we create a simple algorithm which mimics the layer by layer training of SdAs. However, in contrast to SdAs, our algorithm requires no training through gradient descent as the parameters can be computed in closed-form. It can be implemented in less than 20 lines of MATLABTMand reduces the computation time from several hours to mere seconds. We show that our feature transformation reliably improves the results of SVM classification significantly on all our data sets - often outperforming SdAs and even deep neural networks in three out of four deep learning benchmarks.