 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems
Mar 11, 2026We present the design and implementation of a RAG-based AI system benchmarking (RAGPerf) framework for characterizing the system behaviors of RAG pipelines. To facilitate detailed profiling and fine-grained performance analysis, RAGPerf decouples the RAG workflow into several modular components - embedding, indexing, retrieval, reranking, and generation. RAGPerf offers the flexibility for users to configure the core parameters of each component and examine their impact on the end-to-end query performance and quality. RAGPerf has a workload generator to model real-world scenarios by supporting diverse datasets (e.g., text, pdf, code, and audio), different retrieval and update ratios, and query distributions. RAGPerf also supports different embedding models, major vector databases such as LanceDB, Milvus, Qdrant, Chroma, and Elasticsearch, as well as different LLMs for content generation. It automates the collection of performance metrics (i.e., end-to-end query throughput, host/GPU memory footprint, and CPU/GPU utilization) and accuracy metrics (i.e., context recall, query accuracy, and factual consistency). We demonstrate the capabilities of RAGPerf through a comprehensive set of experiments and open source its codebase at GitHub. Our evaluation shows that RAGPerf incurs negligible performance overhead.
Lossless Compression for LLM Tensor Incremental Snapshots
May 14, 2025



During the training of Large Language Models (LLMs), tensor data is periodically "checkpointed" to persistent storage to allow recovery of work done in the event of failure. The volume of data that must be copied during each checkpoint, even when using reduced-precision representations such as bfloat16, often reaches hundreds of gigabytes. Furthermore, the data must be moved across a network and written to a storage system before the next epoch occurs. With a view to ultimately building an optimized checkpointing solution, this paper presents experimental analysis of checkpoint data used to derive a design that maximizes the use of lossless compression to reduce the volume of data. We examine how tensor data and its compressibility evolve during model training and evaluate the efficacy of existing common off-the-shelf general purpose compression engines combined with known data optimization techniques such as byte-grouping and incremental delta compression. Leveraging our analysis we have built an effective compression solution, known as Language Model Compressor (LMC), which is based on byte-grouping and Huffman encoding. LMC offers more compression performance than the best alternative (BZ2) but with an order-of-magnitude reduction in the time needed to perform the compression. We show that a 16-core parallel implementation of LMC can attain compression and decompression throughput of 2.78 GiB/s and 3.76 GiB/s respectively. This increase in performance ultimately reduces the CPU resources needed and provides more time to copy the data to the storage system before the next epoch thus allowing for higher-frequency checkpoints.
Non-Volatile Memory Accelerated Posterior Estimation
Feb 21, 2022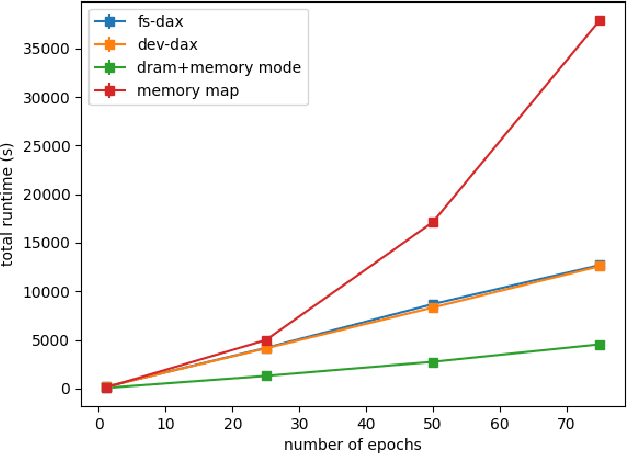
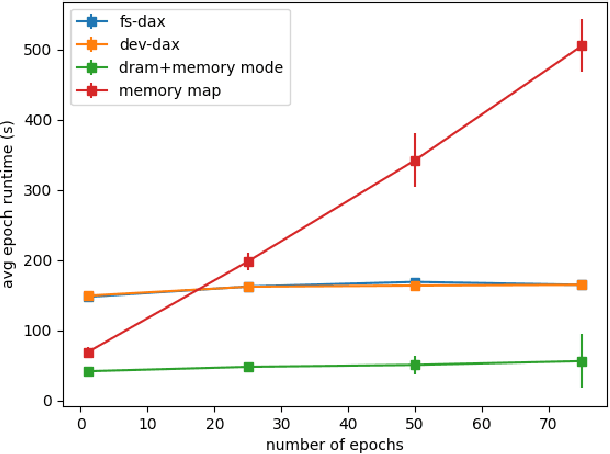
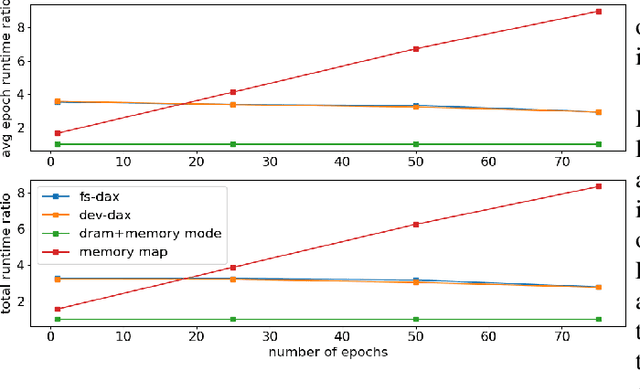
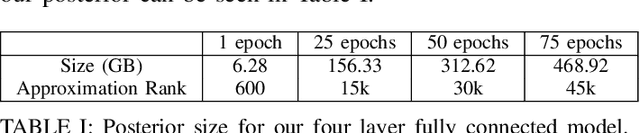
Bayesian inference allows machine learning models to express uncertainty. Current machine learning models use only a single learnable parameter combination when making predictions, and as a result are highly overconfident when their predictions are wrong. To use more learnable parameter combinations efficiently, these samples must be drawn from the posterior distribution. Unfortunately computing the posterior directly is infeasible, so often researchers approximate it with a well known distribution such as a Gaussian. In this paper, we show that through the use of high-capacity persistent storage, models whose posterior distribution was too big to approximate are now feasible, leading to improved predictions in downstream tasks.
Non-Volatile Memory Accelerated Geometric Multi-Scale Resolution Analysis
Feb 21, 2022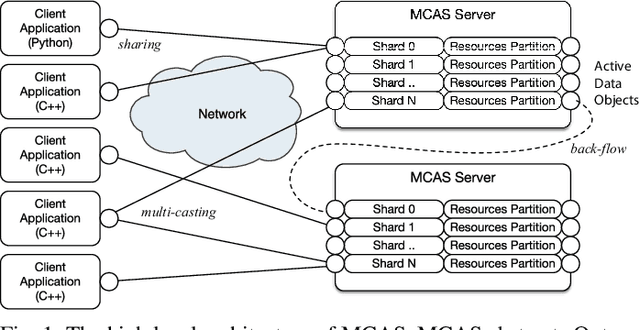
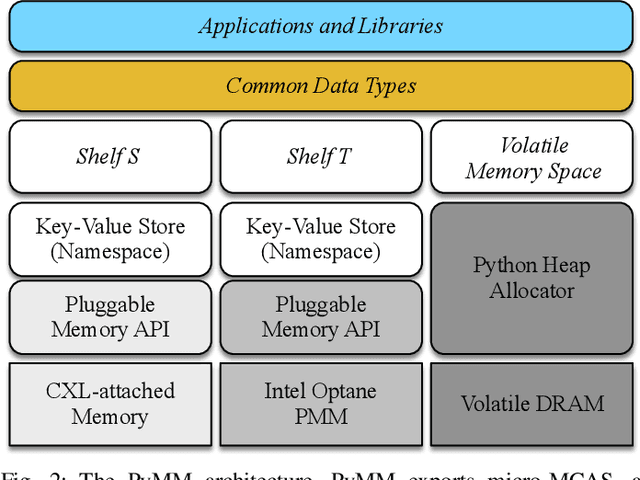
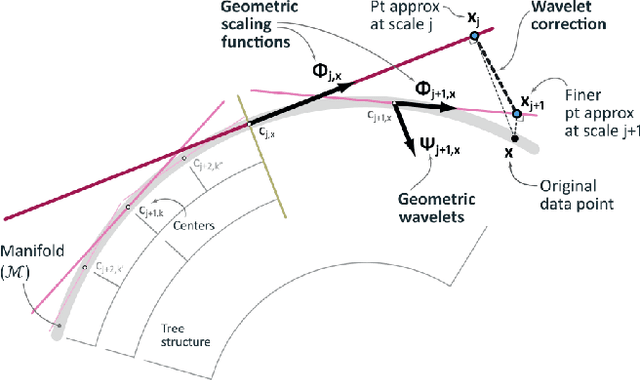
Dimensionality reduction algorithms are standard tools in a researcher's toolbox. Dimensionality reduction algorithms are frequently used to augment downstream tasks such as machine learning, data science, and also are exploratory methods for understanding complex phenomena. For instance, dimensionality reduction is commonly used in Biology as well as Neuroscience to understand data collected from biological subjects. However, dimensionality reduction techniques are limited by the von-Neumann architectures that they execute on. Specifically, data intensive algorithms such as dimensionality reduction techniques often require fast, high capacity, persistent memory which historically hardware has been unable to provide at the same time. In this paper, we present a re-implementation of an existing dimensionality reduction technique called Geometric Multi-Scale Resolution Analysis (GMRA) which has been accelerated via novel persistent memory technology called Memory Centric Active Storage (MCAS). Our implementation uses a specialized version of MCAS called PyMM that provides native support for Python datatypes including NumPy arrays and PyTorch tensors. We compare our PyMM implementation against a DRAM implementation, and show that when data fits in DRAM, PyMM offers competitive runtimes. When data does not fit in DRAM, our PyMM implementation is still able to process the data.