 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Flow Matching Framework for Soft-Robot Inverse Dynamics
Apr 03, 2026Learning the inverse dynamics of soft continuum robots remains challenging due to high-dimensional nonlinearities and complex actuation coupling. Conventional feedback-based controllers often suffer from control chattering due to corrective oscillations, while deterministic regression-based learners struggle to capture the complex nonlinear mappings required for accurate dynamic tracking. Motivated by these limitations, we propose an inverse-dynamics framework for open-loop feedforward control that learns the system's differential dynamics as a generative transport map. Specifically, inverse dynamics is reformulated as a conditional flow-matching problem, and Rectified Flow (RF) is adopted as a lightweight instance to generate physically consistent control inputs rather than conditional averages. Two variants are introduced to further enhance physical consistency: RF-Physical, utilizing a physics-based prior for residual modeling; and RF-FWD, integrating a forward-dynamics consistency loss during flow matching. Extensive evaluations demonstrate that our framework reduces trajectory tracking RMSE by over 50% compared to standard regression baselines (MLP, LSTM, Transformer). The system sustains stable open-loop execution at a peak end-effector velocity of 1.14 m/s with sub-millisecond inference latency (0.995 ms). This work demonstrates flow matching as a robust, high-performance paradigm for learning differential inverse dynamics in soft robotic systems.
EmoAra: Emotion-Preserving English Speech Transcription and Cross-Lingual Translation with Arabic Text-to-Speech
Feb 01, 2026This work presents EmoAra, an end-to-end emotion-preserving pipeline for cross-lingual spoken communication, motivated by banking customer service where emotional context affects service quality. EmoAra integrates Speech Emotion Recognition, Automatic Speech Recognition, Machine Translation, and Text-to-Speech to process English speech and deliver an Arabic spoken output while retaining emotional nuance. The system uses a CNN-based emotion classifier, Whisper for English transcription, a fine-tuned MarianMT model for English-to-Arabic translation, and MMS-TTS-Ara for Arabic speech synthesis. Experiments report an F1-score of 94% for emotion classification, translation performance of BLEU 56 and BERTScore F1 88.7%, and an average human evaluation score of 81% on banking-domain translations. The implementation and resources are available at the accompanying GitHub repository.
PedagoSense: A Pedology Grounded LLM System for Pedagogical Strategy Detection and Contextual Response Generation in Learning Dialogues
Feb 01, 2026This paper addresses the challenge of improving interaction quality in dialogue based learning by detecting and recommending effective pedagogical strategies in tutor student conversations. We introduce PedagoSense, a pedology grounded system that combines a two stage strategy classifier with large language model generation. The system first detects whether a pedagogical strategy is present using a binary classifier, then performs fine grained classification to identify the specific strategy. In parallel, it recommends an appropriate strategy from the dialogue context and uses an LLM to generate a response aligned with that strategy. We evaluate on human annotated tutor student dialogues, augmented with additional non pedagogical conversations for the binary task. Results show high performance for pedagogical strategy detection and consistent gains when using data augmentation, while analysis highlights where fine grained classes remain challenging. Overall, PedagoSense bridges pedagogical theory and practical LLM based response generation for more adaptive educational technologies.
Lightweight Dynamic Modeling of Cable-Driven Continuum Robots Based on Actuation-Space Energy Formulation
Dec 15, 2025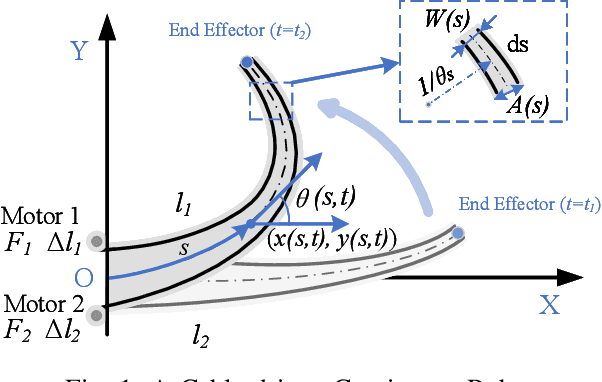
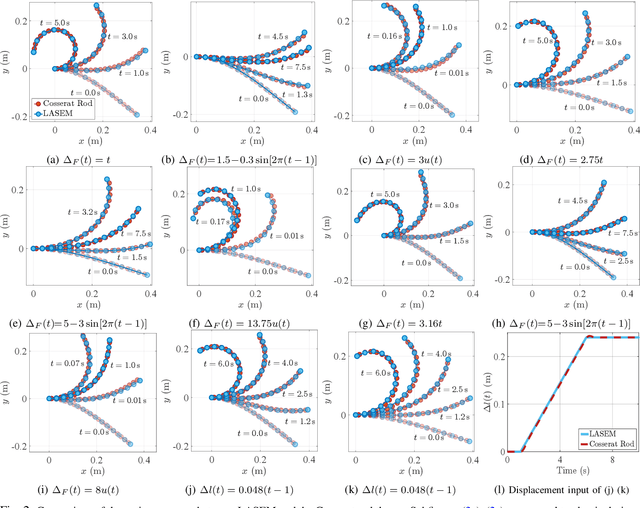
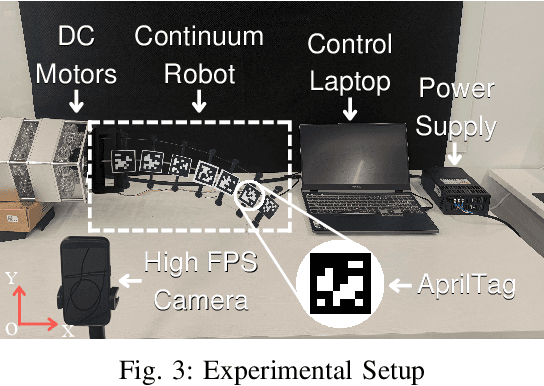
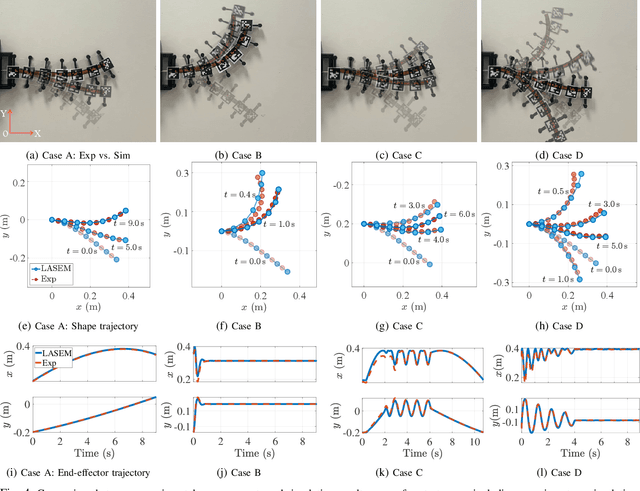
Cable-driven continuum robots (CDCRs) require accurate, real-time dynamic models for high-speed dynamics prediction or model-based control, making such capability an urgent need. In this paper, we propose the Lightweight Actuation-Space Energy Modeling (LASEM) framework for CDCRs, which formulates actuation potential energy directly in actuation space to enable lightweight yet accurate dynamic modeling. Through a unified variational derivation, the governing dynamics reduce to a single partial differential equation (PDE), requiring only the Euler moment balance while implicitly incorporating the Newton force balance. By also avoiding explicit computation of cable-backbone contact forces, the formulation simplifies the model structure and improves computational efficiency while preserving geometric accuracy and physical consistency. Importantly, the proposed framework for dynamic modeling natively supports both force-input and displacement-input actuation modes, a capability seldom achieved in existing dynamic formulations. Leveraging this lightweight structure, a Galerkin space-time modal discretization with analytical time-domain derivatives of the reduced state further enables an average 62.3% computational speedup over state-of-the-art real-time dynamic modeling approaches.