 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHawkesRank: Event-Driven Centrality for Real-Time Importance Ranking
Mar 12, 2026Quantifying influence in networks is important across science, economics, and public health, yet widely used centrality measures remain limited: they rely on static representations, heuristic network constructions, and purely endogenous notions of importance, while offering little semantic connection to observable activity. We introduce HawkesRank, a dynamic framework grounded in multivariate Hawkes point processes that models exogenous drivers (intrinsic contributions) and endogenous amplification (self- and cross-excitation). This yields a principled, empirically calibrated, and adaptive importance measure. Classical indices such as Katz centrality and PageRank emerge as mean-field limits of the framework, clarifying both their validity and their limitations. Unlike static averages, HawkesRank measures importance through instantaneous event intensities, enabling prediction, transparent endo-exo decomposition, and adaptability to shocks. Using both simulations and empirical analysis of emotion dynamics in online communication platforms, we show that HawkesRank closely tracks system activity and consistently outperforms static centrality metrics.
Why AI Alignment Failure Is Structural: Learned Human Interaction Structures and AGI as an Endogenous Evolutionary Shock
Jan 13, 2026Recent reports of large language models (LLMs) exhibiting behaviors such as deception, threats, or blackmail are often interpreted as evidence of alignment failure or emergent malign agency. We argue that this interpretation rests on a conceptual error. LLMs do not reason morally; they statistically internalize the record of human social interaction, including laws, contracts, negotiations, conflicts, and coercive arrangements. Behaviors commonly labeled as unethical or anomalous are therefore better understood as structural generalizations of interaction regimes that arise under extreme asymmetries of power, information, or constraint. Drawing on relational models theory, we show that practices such as blackmail are not categorical deviations from normal social behavior, but limiting cases within the same continuum that includes market pricing, authority relations, and ultimatum bargaining. The surprise elicited by such outputs reflects an anthropomorphic expectation that intelligence should reproduce only socially sanctioned behavior, rather than the full statistical landscape of behaviors humans themselves enact. Because human morality is plural, context-dependent, and historically contingent, the notion of a universally moral artificial intelligence is ill-defined. We therefore reframe concerns about artificial general intelligence (AGI). The primary risk is not adversarial intent, but AGI's role as an endogenous amplifier of human intelligence, power, and contradiction. By eliminating longstanding cognitive and institutional frictions, AGI compresses timescales and removes the historical margin of error that has allowed inconsistent values and governance regimes to persist without collapse. Alignment failure is thus structural, not accidental, and requires governance approaches that address amplification, complexity, and regime stability rather than model-level intent alone.
Uncovering Feature Interdependencies in Complex Systems with Non-Greedy Random Forests
Oct 05, 2020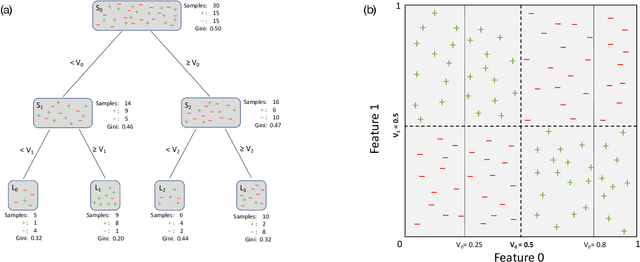
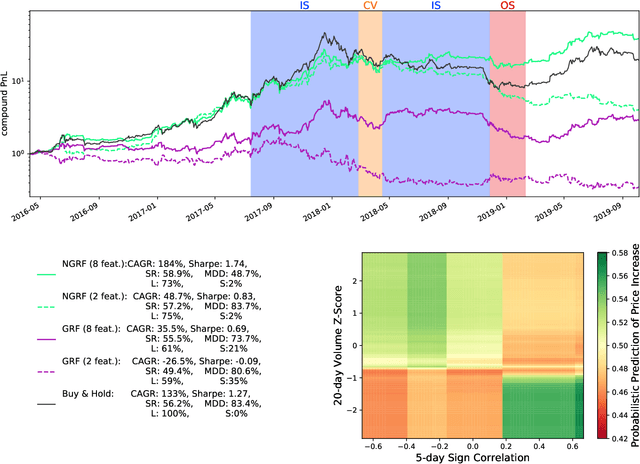
A "non-greedy" variation of the random forest algorithm is presented to better uncover feature interdependencies inherent in complex systems. Conventionally, random forests are built from "greedy" decision trees which each consider only one split at a time during their construction. In contrast, the decision trees included in this random forest algorithm each consider three split nodes simultaneously in tiers of depth two. It is demonstrated on synthetic data and bitcoin price time series that the non-greedy version significantly outperforms the greedy one if certain non-linear relationships between feature-pairs are present. In particular, both greedy and a non-greedy random forests are trained to predict the signs of daily bitcoin returns and backtest a long-short trading strategy. The better performance of the non-greedy algorithm is explained by the presence of "XOR-like" relationships between long-term and short-term technical indicators. When no such relationships exist, performance is similar. Given its enhanced ability to understand the feature-interdependencies present in complex systems, this non-greedy extension should become a standard method in the toolkit of data scientists.