 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergy Between Semantic Segmentation and Image Denoising via Alternate Boosting
Feb 24, 2021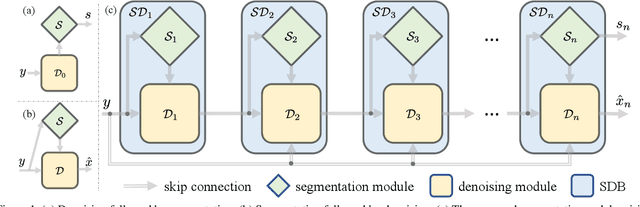
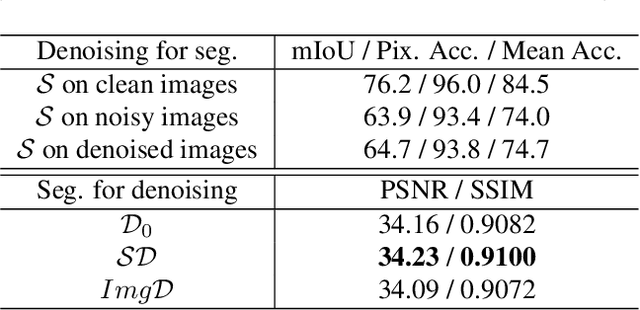
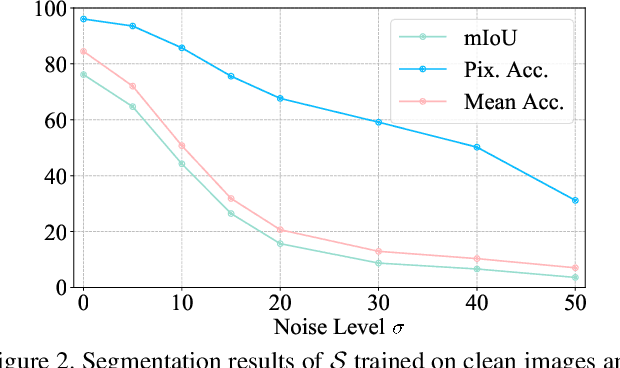
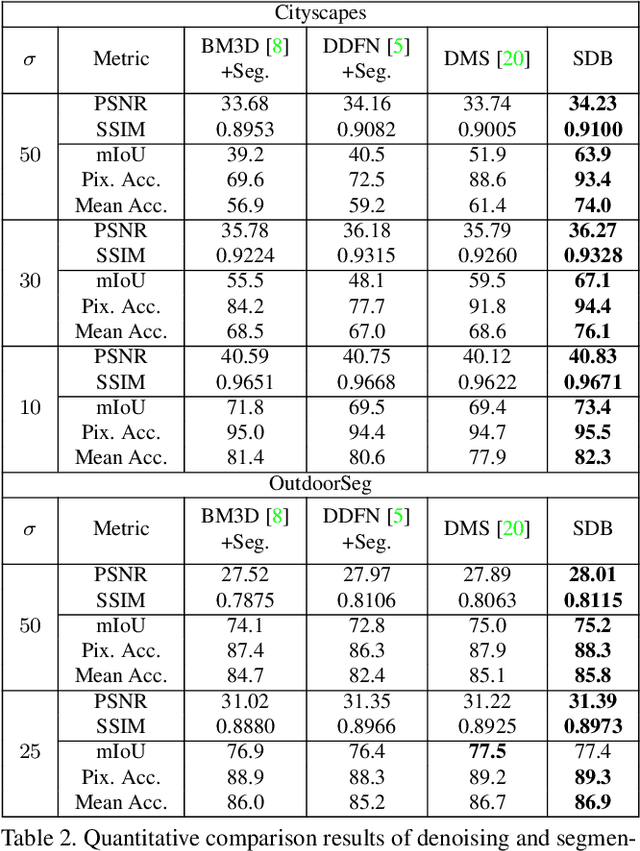
The capability of image semantic segmentation may be deteriorated due to noisy input image, where image denoising prior to segmentation helps. Both image denoising and semantic segmentation have been developed significantly with the advance of deep learning. Thus, we are interested in the synergy between them by using a holistic deep model. We observe that not only denoising helps combat the drop of segmentation accuracy due to noise, but also pixel-wise semantic information boosts the capability of denoising. We then propose a boosting network to perform denoising and segmentation alternately. The proposed network is composed of multiple segmentation and denoising blocks (SDBs), each of which estimates semantic map then uses the map to regularize denoising. Experimental results show that the denoised image quality is improved substantially and the segmentation accuracy is improved to close to that of clean images. Our code and models will be made publicly available.
Belief Space Planning for Mobile Robots with Range Sensors using iLQG
Feb 10, 2021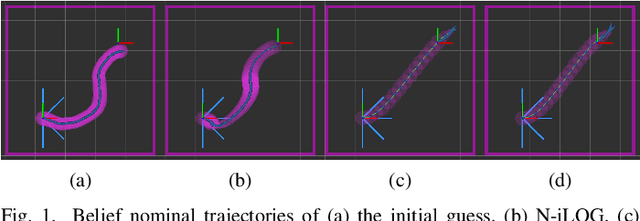
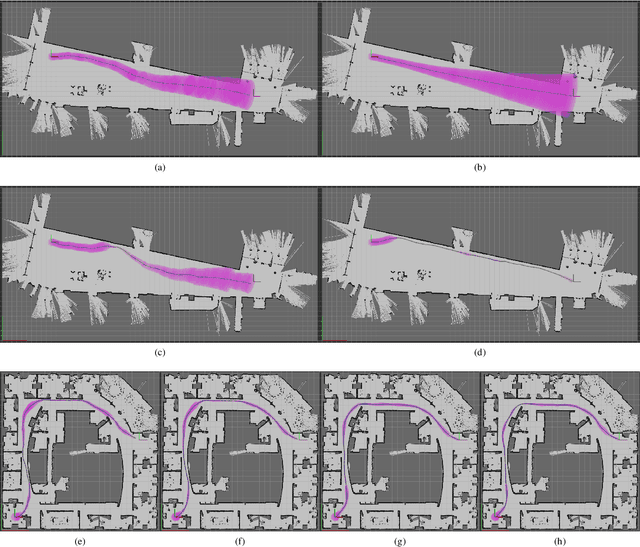
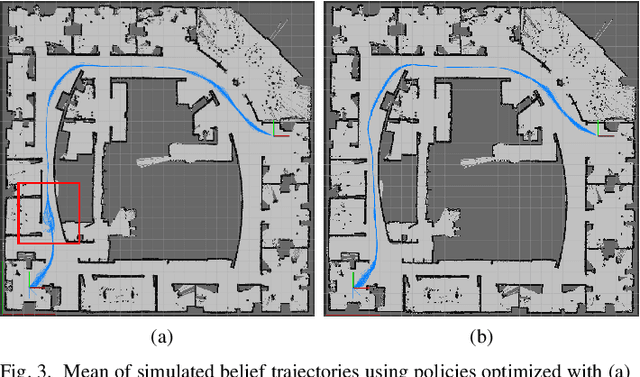
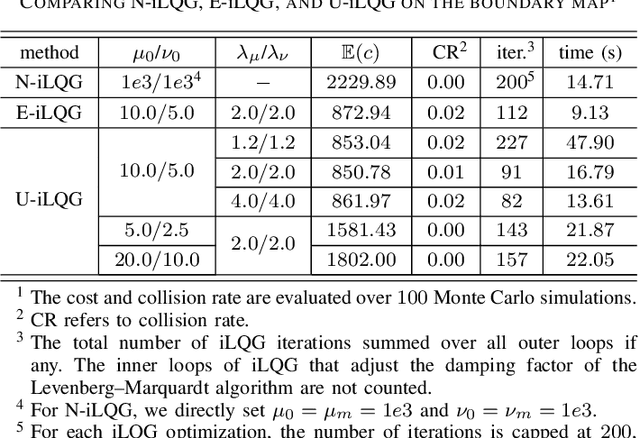
In this work, we use iterative Linear Quadratic Gaussian (iLQG) to plan motions for a mobile robot with range sensors in belief space. We address two limitations that prevent applications of iLQG to the considered robotic system. First, iLQG assumes a differentiable measurement model, which is not true for range sensors. We show that iLQG only requires the differentiability of the belief dynamics. We propose to use a derivative-free filter to approximate the belief dynamics, which does not require explicit differentiability of the measurement model. Second, informative measurements from a range sensor are sparse. Uninformative measurements produce trivial gradient information, which prevent iLQG optimization from converging to a local minimum. We densify the informative measurements by introducing additional parameters in the measurement model. The parameters are iteratively updated in the optimization to ensure convergence to the true measurement model of a range sensor. We show the effectiveness of the proposed modifications through an ablation study. We also apply the proposed method in simulations of large scale real world environments, which show superior performance comparing to the state-of-the-art methods that either assume the separation principle or maximum likelihood measurements.
Stochastic Motion Planning under Partial Observability for Mobile Robots with Continuous Range Measurements
Dec 02, 2020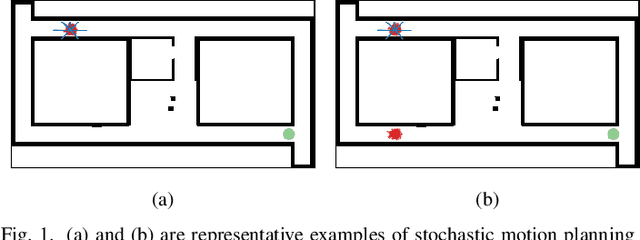
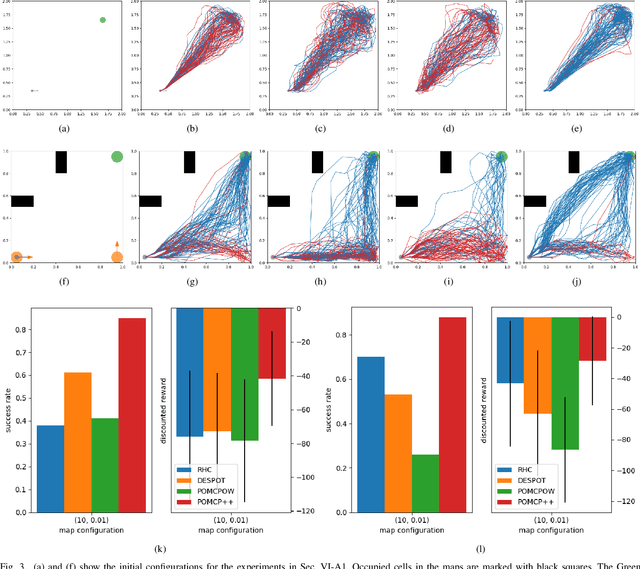
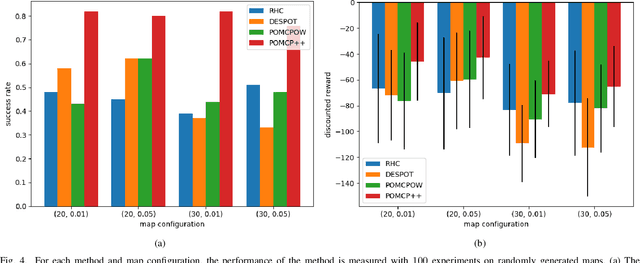
In this paper, we address the problem of stochastic motion planning under partial observability, more specifically, how to navigate a mobile robot equipped with continuous range sensors such as LIDAR. In contrast to many existing robotic motion planning methods, we explicitly consider the uncertainty of the robot state by modeling the system as a POMDP. Recent work on general purpose POMDP solvers is typically limited to discrete observation spaces, and does not readily apply to the proposed problem due to the continuous measurements from LIDAR. In this work, we build upon an existing Monte Carlo Tree Search method, POMCP, and propose a new algorithm POMCP++. Our algorithm can handle continuous observation spaces with a novel measurement selection strategy. The POMCP++ algorithm overcomes over-optimism in the value estimation of a rollout policy by removing the implicit perfect state assumption at the rollout phase. We validate POMCP++ in theory by proving it is a Monte Carlo Tree Search algorithm. Through comparisons with other methods that can also be applied to the proposed problem, we show that POMCP++ yields significantly higher success rate and total reward.
Effectiveness of MPC-friendly Softmax Replacement
Nov 23, 2020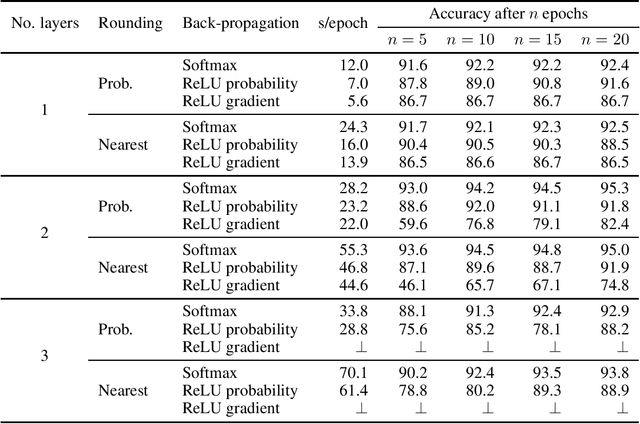

Softmax is widely used in deep learning to map some representation to a probability distribution. As it is based on exp/log functions that is relatively expensive in multi-party computation, Mohassel and Zhang (2017) proposed a simpler replacement based on ReLU to be used in secure computation. However, we could not reproduce the accuracy they reported for training on MNIST with three fully connected layers. Later works (e.g., Wagh et al., 2019 and 2021) used the softmax replacement not for computing the output probability distribution but for approximating the gradient in back-propagation. In this work, we analyze the two uses of the replacement and compare them to softmax, both in terms of accuracy and cost in multi-party computation. We found that the replacement only provides a significant speed-up for a one-layer network while it always reduces accuracy, sometimes significantly. Thus we conclude that its usefulness is limited and one should use the original softmax function instead.
A Practical Chinese Dependency Parser Based on A Large-scale Dataset
Sep 03, 2020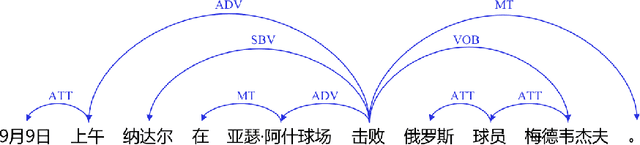
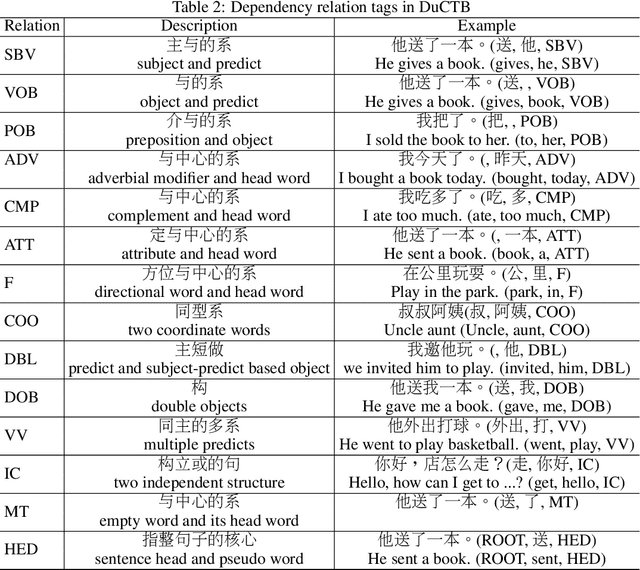
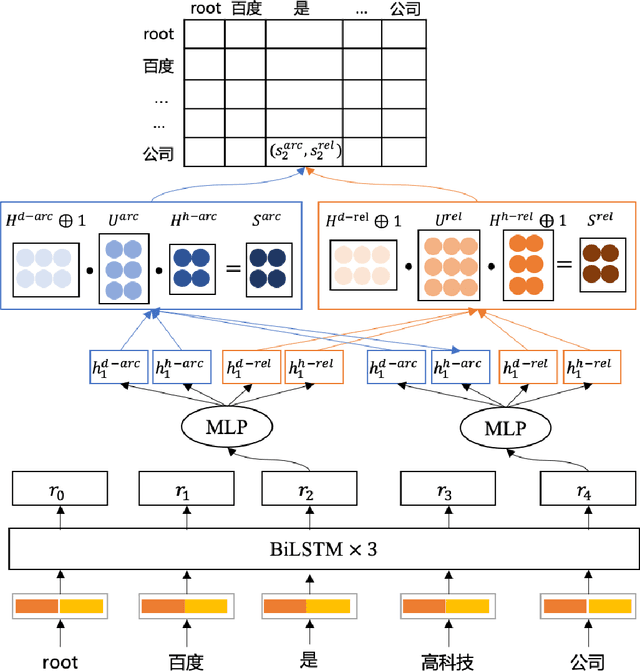
Dependency parsing is a longstanding natural language processing task, with its outputs crucial to various downstream tasks. Recently, neural network based (NN-based) dependency parsing has achieved significant progress and obtained the state-of-the-art results. As we all know, NN-based approaches require massive amounts of labeled training data, which is very expensive because it requires human annotation by experts. Thus few industrial-oriented dependency parser tools are publicly available. In this report, we present Baidu Dependency Parser (DDParser), a new Chinese dependency parser trained on a large-scale manually labeled dataset called Baidu Chinese Treebank (DuCTB). DuCTB consists of about one million annotated sentences from multiple sources including search logs, Chinese newswire, various forum discourses, and conversation programs. DDParser is extended on the graph-based biaffine parser to accommodate to the characteristics of Chinese dataset. We conduct experiments on two test sets: the standard test set with the same distribution as the training set and the random test set sampled from other sources, and the labeled attachment scores (LAS) of them are 92.9% and 86.9% respectively. DDParser achieves the state-of-the-art results, and is released at https://github.com/baidu/DDParser.
Multivariate Relations Aggregation Learning in Social Networks
Aug 09, 2020
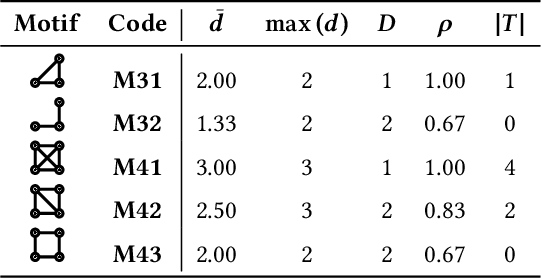
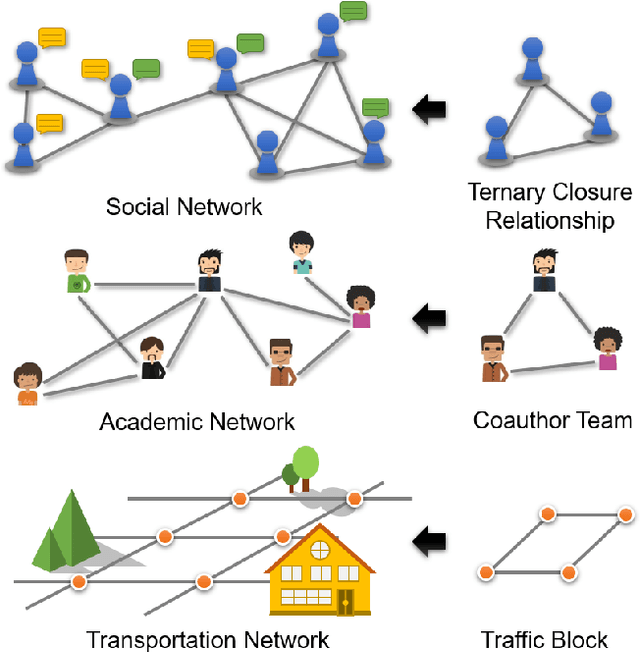
Multivariate relations are general in various types of networks, such as biological networks, social networks, transportation networks, and academic networks. Due to the principle of ternary closures and the trend of group formation, the multivariate relationships in social networks are complex and rich. Therefore, in graph learning tasks of social networks, the identification and utilization of multivariate relationship information are more important. Existing graph learning methods are based on the neighborhood information diffusion mechanism, which often leads to partial omission or even lack of multivariate relationship information, and ultimately affects the accuracy and execution efficiency of the task. To address these challenges, this paper proposes the multivariate relationship aggregation learning (MORE) method, which can effectively capture the multivariate relationship information in the network environment. By aggregating node attribute features and structural features, MORE achieves higher accuracy and faster convergence speed. We conducted experiments on one citation network and five social networks. The experimental results show that the MORE model has higher accuracy than the GCN (Graph Convolutional Network) model in node classification tasks, and can significantly reduce time cost.
* 11 pages, 6 figures
Feedback Enhanced Motion Planning for Autonomous Vehicles
Jul 11, 2020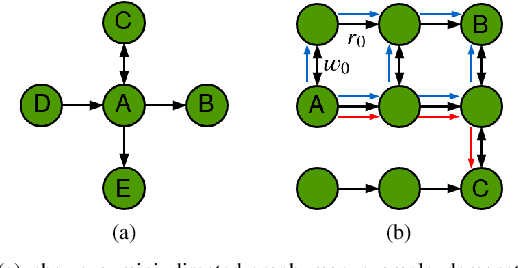

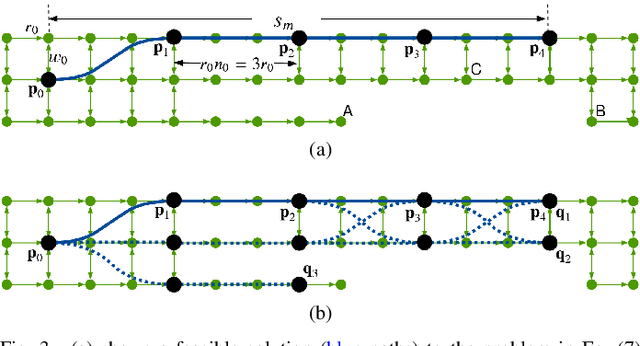
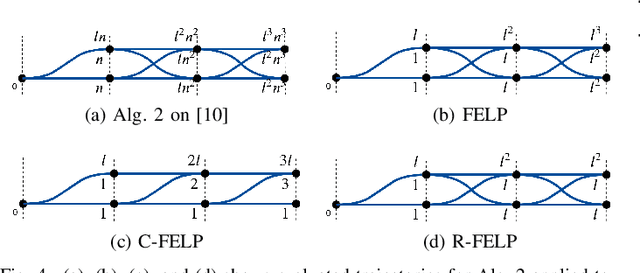
In this work, we address the motion planning problem for autonomous vehicles through a new lattice planning approach, called Feedback Enhanced Lattice Planner (FELP). Existing lattice planners have two major limitations, namely the high dimensionality of the lattice and the lack of modeling of agent vehicle behaviors. We propose to apply the Intelligent Driver Model (IDM) as a speed feedback policy to address both of these limitations. IDM both enables the responsive behavior of the agents, and uniquely determines the acceleration and speed profile of the ego vehicle on a given path. Therefore, only a spatial lattice is needed, while discretization of higher order dimensions is no longer required. Additionally, we propose a directed-graph map representation to support the implementation and execution of lattice planners. The map can reflect local geometric structure, embed the traffic rules adhering to the road, and is efficient to construct and update. We show that FELP is more efficient compared to other existing lattice planners through runtime complexity analysis, and we propose two variants of FELP to further reduce the complexity to polynomial time. We demonstrate the improvement by comparing FELP with an existing spatiotemporal lattice planner using simulations of a merging scenario and continuous highway traffic. We also study the performance of FELP under different traffic densities.
Bottom-Up Human Pose Estimation by Ranking Heatmap-Guided Adaptive Keypoint Estimates
Jun 28, 2020

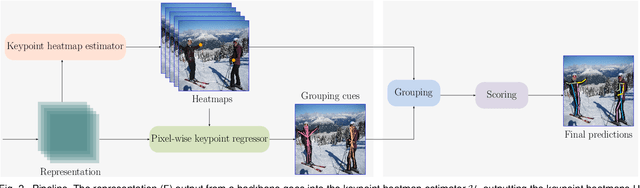
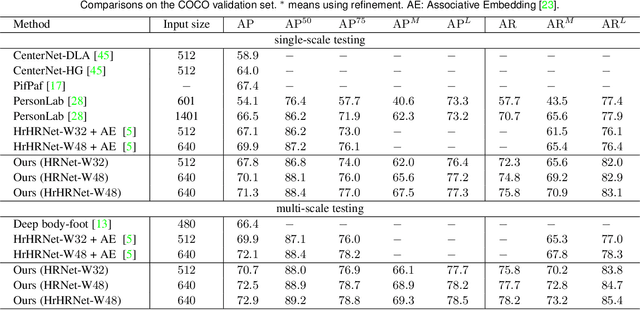
The typical bottom-up human pose estimation framework includes two stages, keypoint detection and grouping. Most existing works focus on developing grouping algorithms, e.g., associative embedding, and pixel-wise keypoint regression that we adopt in our approach. We present several schemes that are rarely or unthoroughly studied before for improving keypoint detection and grouping (keypoint regression) performance. First, we exploit the keypoint heatmaps for pixel-wise keypoint regression instead of separating them for improving keypoint regression. Second, we adopt a pixel-wise spatial transformer network to learn adaptive representations for handling the scale and orientation variance to further improve keypoint regression quality. Last, we present a joint shape and heatvalue scoring scheme to promote the estimated poses that are more likely to be true poses. Together with the tradeoff heatmap estimation loss for balancing the background and keypoint pixels and thus improving heatmap estimation quality, we get the state-of-the-art bottom-up human pose estimation result. Code is available at https://github.com/HRNet/HRNet-Bottom-up-Pose-Estimation.
Classify and Generate Reciprocally: Simultaneous Positive-Unlabelled Learning and Conditional Generation with Extra Data
Jun 14, 2020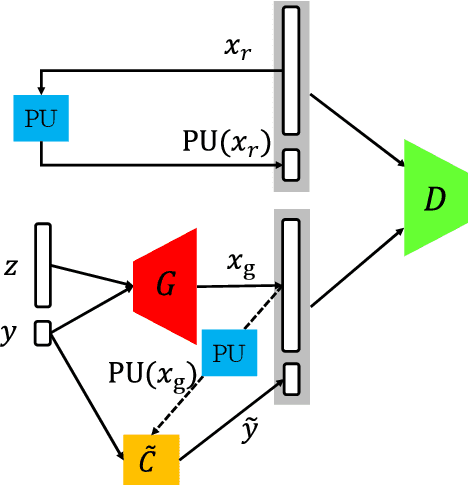
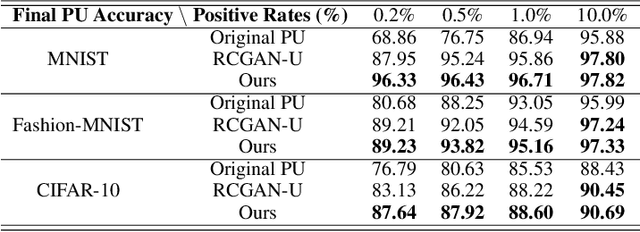
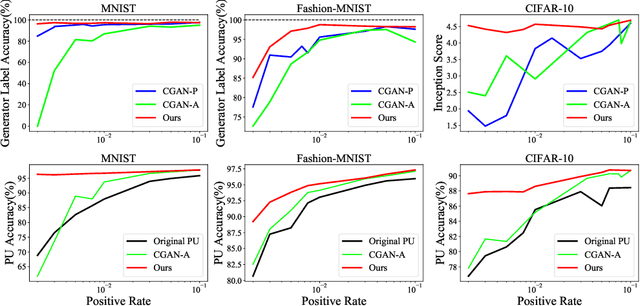

The scarcity of class-labeled data is a ubiquitous bottleneck in a wide range of machine learning problems. While abundant unlabeled data normally exist and provide a potential solution, it is extremely challenging to exploit them. In this paper, we address this problem by leveraging Positive-Unlabeled~(PU) classification and conditional generation with extra unlabeled data \emph{simultaneously}, both of which aim to make full use of agnostic unlabeled data to improve classification and generation performances. In particular, we present a novel training framework to jointly target both PU classification and conditional generation when exposing to extra data, especially out-of-distribution unlabeled data, by exploring the interplay between them: 1) enhancing the performance of PU classifiers with the assistance of a novel Conditional Generative Adversarial Network~(CGAN) that is robust to noisy labels, 2) leveraging extra data with predicted labels from a PU classifier to help the generation. Our key contribution is a Classifier-Noise-Invariant Conditional GAN~(CNI-CGAN) that can learn the clean data distribution from noisy labels predicted by a PU classifier. Theoretically, we proved the optimal condition of CNI-CGAN and experimentally, we conducted extensive evaluations on diverse datasets, verifying the simultaneous improvements on both classification and generation.
milliEgo: mmWave Aided Egomotion Estimation with Deep Sensor Fusion
Jun 03, 2020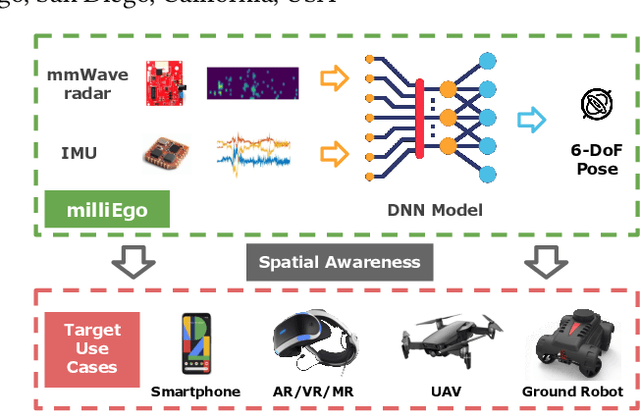
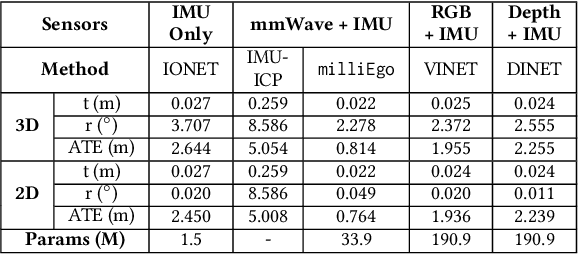
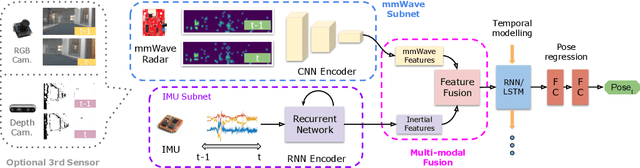
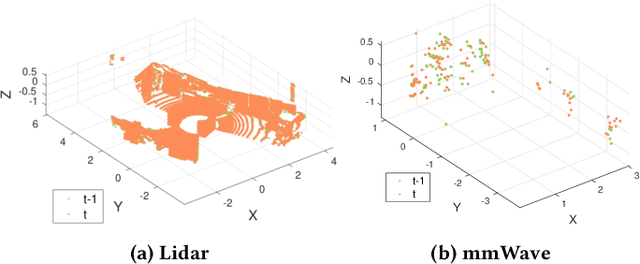
Robust and accurate trajectory estimation of mobile agents such as people and robots is a key requirement for providing spatial awareness to emerging capabilities such as augmented reality or autonomous interaction. Although currently dominated by vision based techniques e.g., visual-inertial odometry, these suffer from challenges with scene illumination or featureless surfaces. As an alternative, we propose \sysname, a novel deep-learning approach to robust egomotion estimation which exploits the capabilities of low-cost mmWave radar. Although mmWave radar has a fundamental advantage over monocular cameras of being metric i.e., providing absolute scale or depth, current single chip solutions have limited and sparse imaging resolution, making existing point-cloud registration techniques brittle. We propose a new architecture that is optimized for solving this underdetermined pose transformation problem. Secondly, to robustly fuse mmWave pose estimates with additional sensors, e.g. inertial or visual sensor we introduce a mixed attention approach to deep fusion. Through extensive experiments, we demonstrate how mmWave radar outperforms existing state-of-the-art odometry techniques. We also show that the neural architecture can be made highly efficient and suitable for real-time embedded applications.