 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-learned representation-guided latent diffusion model for breast cancer classification in deep ultraviolet whole surface images
Jan 16, 2026Breast-Conserving Surgery (BCS) requires precise intraoperative margin assessment to preserve healthy tissue. Deep Ultraviolet Fluorescence Scanning Microscopy (DUV-FSM) offers rapid, high-resolution surface imaging for this purpose; however, the scarcity of annotated DUV data hinders the training of robust deep learning models. To address this, we propose an Self-Supervised Learning (SSL)-guided Latent Diffusion Model (LDM) to generate high-quality synthetic training patches. By guiding the LDM with embeddings from a fine-tuned DINO teacher, we inject rich semantic details of cellular structures into the synthetic data. We combine real and synthetic patches to fine-tune a Vision Transformer (ViT), utilizing patch prediction aggregation for WSI-level classification. Experiments using 5-fold cross-validation demonstrate that our method achieves 96.47 % accuracy and reduces the FID score to 45.72, significantly outperforming class-conditioned baselines.
Anatomy Aware Cascade Network: Bridging Epistemic Uncertainty and Geometric Manifold for 3D Tooth Segmentation
Jan 12, 2026Accurate three-dimensional (3D) tooth segmentation from Cone-Beam Computed Tomography (CBCT) is a prerequisite for digital dental workflows. However, achieving high-fidelity segmentation remains challenging due to adhesion artifacts in naturally occluded scans, which are caused by low contrast and indistinct inter-arch boundaries. To address these limitations, we propose the Anatomy Aware Cascade Network (AACNet), a coarse-to-fine framework designed to resolve boundary ambiguity while maintaining global structural consistency. Specifically, we introduce two mechanisms: the Ambiguity Gated Boundary Refiner (AGBR) and the Signed Distance Map guided Anatomical Attention (SDMAA). The AGBR employs an entropy based gating mechanism to perform targeted feature rectification in high uncertainty transition zones. Meanwhile, the SDMAA integrates implicit geometric constraints via signed distance map to enforce topological consistency, preventing the loss of spatial details associated with standard pooling. Experimental results on a dataset of 125 CBCT volumes demonstrate that AACNet achieves a Dice Similarity Coefficient of 90.17 \% and a 95\% Hausdorff Distance of 3.63 mm, significantly outperforming state-of-the-art methods. Furthermore, the model exhibits strong generalization on an external dataset with an HD95 of 2.19 mm, validating its reliability for downstream clinical applications such as surgical planning. Code for AACNet is available at https://github.com/shiliu0114/AACNet.
Breast Cancer Classification in Deep Ultraviolet Fluorescence Images Using a Patch-Level Vision Transformer Framework
May 12, 2025Breast-conserving surgery (BCS) aims to completely remove malignant lesions while maximizing healthy tissue preservation. Intraoperative margin assessment is essential to achieve a balance between thorough cancer resection and tissue conservation. A deep ultraviolet fluorescence scanning microscope (DUV-FSM) enables rapid acquisition of whole surface images (WSIs) for excised tissue, providing contrast between malignant and normal tissues. However, breast cancer classification with DUV WSIs is challenged by high resolutions and complex histopathological features. This study introduces a DUV WSI classification framework using a patch-level vision transformer (ViT) model, capturing local and global features. Grad-CAM++ saliency weighting highlights relevant spatial regions, enhances result interpretability, and improves diagnostic accuracy for benign and malignant tissue classification. A comprehensive 5-fold cross-validation demonstrates the proposed approach significantly outperforms conventional deep learning methods, achieving a classification accuracy of 98.33%.
SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM
Apr 22, 2025



Recent advances of reasoning models, exemplified by OpenAI's o1 and DeepSeek's R1, highlight the significant potential of Reinforcement Learning (RL) to enhance the reasoning capabilities of Large Language Models (LLMs). However, replicating these advancements across diverse domains remains challenging due to limited methodological transparency. In this work, we present two-Staged history-Resampling Policy Optimization (SRPO), which surpasses the performance of DeepSeek-R1-Zero-32B on the AIME24 and LiveCodeBench benchmarks. SRPO achieves this using the same base model as DeepSeek (i.e. Qwen2.5-32B), using only about 1/10 of the training steps required by DeepSeek-R1-Zero-32B, demonstrating superior efficiency. Building upon Group Relative Policy Optimization (GRPO), we introduce two key methodological innovations: (1) a two-stage cross-domain training paradigm designed to balance the development of mathematical reasoning and coding proficiency, and (2) History Resampling (HR), a technique to address ineffective samples. Our comprehensive experiments validate the effectiveness of our approach, offering valuable insights into scaling LLM reasoning capabilities across diverse tasks.
Physics-informed DeepCT: Sinogram Wavelet Decomposition Meets Masked Diffusion
Jan 17, 2025



Diffusion model shows remarkable potential on sparse-view computed tomography (SVCT) reconstruction. However, when a network is trained on a limited sample space, its generalization capability may be constrained, which degrades performance on unfamiliar data. For image generation tasks, this can lead to issues such as blurry details and inconsistencies between regions. To alleviate this problem, we propose a Sinogram-based Wavelet random decomposition And Random mask diffusion Model (SWARM) for SVCT reconstruction. Specifically, introducing a random mask strategy in the sinogram effectively expands the limited training sample space. This enables the model to learn a broader range of data distributions, enhancing its understanding and generalization of data uncertainty. In addition, applying a random training strategy to the high-frequency components of the sinogram wavelet enhances feature representation and improves the ability to capture details in different frequency bands, thereby improving performance and robustness. Two-stage iterative reconstruction method is adopted to ensure the global consistency of the reconstructed image while refining its details. Experimental results demonstrate that SWARM outperforms competing approaches in both quantitative and qualitative performance across various datasets.
Deep learning for automated detection of breast cancer in deep ultraviolet fluorescence images with diffusion probabilistic model
Jul 01, 2024


Data limitation is a significant challenge in applying deep learning to medical images. Recently, the diffusion probabilistic model (DPM) has shown the potential to generate high-quality images by converting Gaussian random noise into realistic images. In this paper, we apply the DPM to augment the deep ultraviolet fluorescence (DUV) image dataset with an aim to improve breast cancer classification for intraoperative margin assessment. For classification, we divide the whole surface DUV image into small patches and extract convolutional features for each patch by utilizing the pre-trained ResNet. Then, we feed them into an XGBoost classifier for patch-level decisions and then fuse them with a regional importance map computed by Grad-CAM++ for whole surface-level prediction. Our experimental results show that augmenting the training dataset with the DPM significantly improves breast cancer detection performance in DUV images, increasing accuracy from 93% to 97%, compared to using Affine transformations and ProGAN.
KS-Net: Multi-band joint speech restoration and enhancement network for 2024 ICASSP SSI Challenge
Feb 02, 2024

This paper presents the speech restoration and enhancement system created by the 1024K team for the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. Our system consists of a generative adversarial network (GAN) in complex-domain for speech restoration and a fine-grained multi-band fusion module for speech enhancement. In the blind test set of SSI, the proposed system achieves an overall mean opinion score (MOS) of 3.49 based on ITU-T P.804 and a Word Accuracy Rate (WAcc) of 0.78 for the real-time track, as well as an overall P.804 MOS of 3.43 and a WAcc of 0.78 for the non-real-time track, ranking 1st in both tracks.
BAE-Net: A Low complexity and high fidelity Bandwidth-Adaptive neural network for speech super-resolution
Dec 21, 2023



Speech bandwidth extension (BWE) has demonstrated promising performance in enhancing the perceptual speech quality in real communication systems. Most existing BWE researches primarily focus on fixed upsampling ratios, disregarding the fact that the effective bandwidth of captured audio may fluctuate frequently due to various capturing devices and transmission conditions. In this paper, we propose a novel streaming adaptive bandwidth extension solution dubbed BAE-Net, which is suitable to handle the low-resolution speech with unknown and varying effective bandwidth. To address the challenges of recovering both the high-frequency magnitude and phase speech content blindly, we devise a dual-stream architecture that incorporates the magnitude inpainting and phase refinement. For potential applications on edge devices, this paper also introduces BAE-NET-lite, which is a lightweight, streaming and efficient framework. Quantitative results demonstrate the superiority of BAE-Net in terms of both performance and computational efficiency when compared with existing state-of-the-art BWE methods.
Multi-scale temporal-frequency attention for music source separation
Sep 02, 2022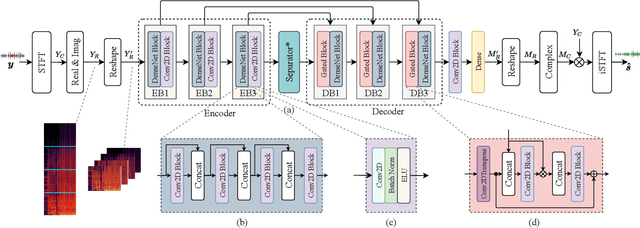
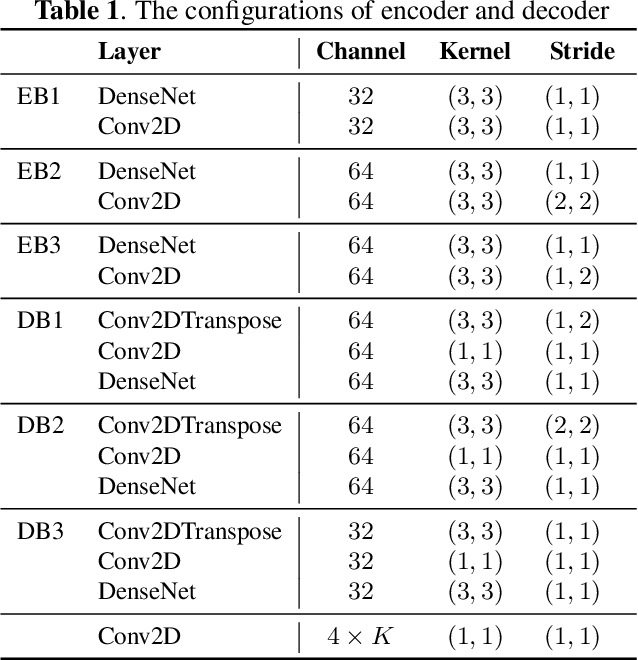
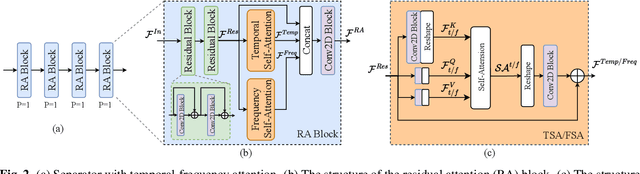
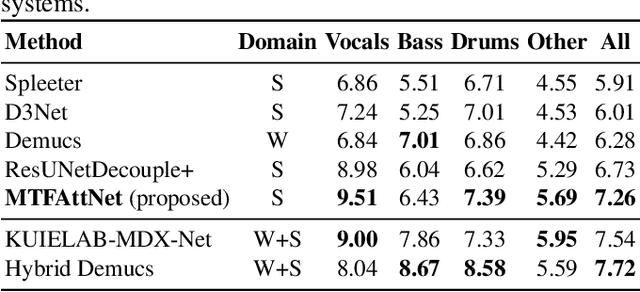
In recent years, deep neural networks (DNNs) based approaches have achieved the start-of-the-art performance for music source separation (MSS). Although previous methods have addressed the large receptive field modeling using various methods, the temporal and frequency correlations of the music spectrogram with repeated patterns have not been explicitly explored for the MSS task. In this paper, a temporal-frequency attention module is proposed to model the spectrogram correlations along both temporal and frequency dimensions. Moreover, a multi-scale attention is proposed to effectively capture the correlations for music signal. The experimental results on MUSDB18 dataset show that the proposed method outperforms the existing state-of-the-art systems with 9.51 dB signal-to-distortion ratio (SDR) on separating the vocal stems, which is the primary practical application of MSS.
A two-step backward compatible fullband speech enhancement system
Jan 28, 2022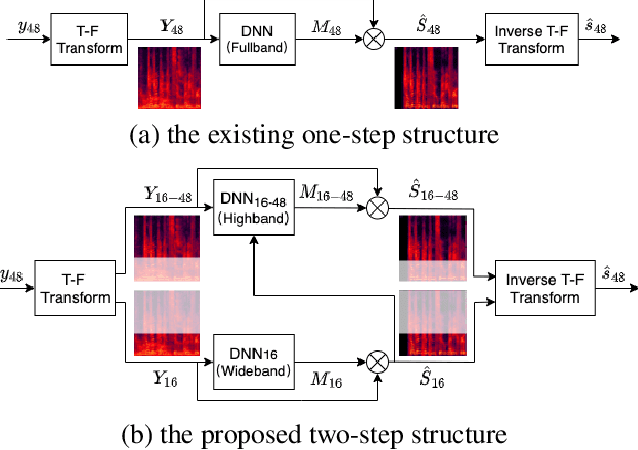
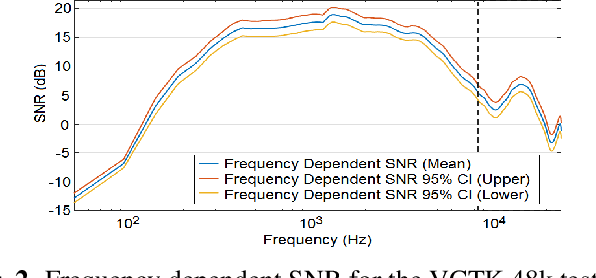
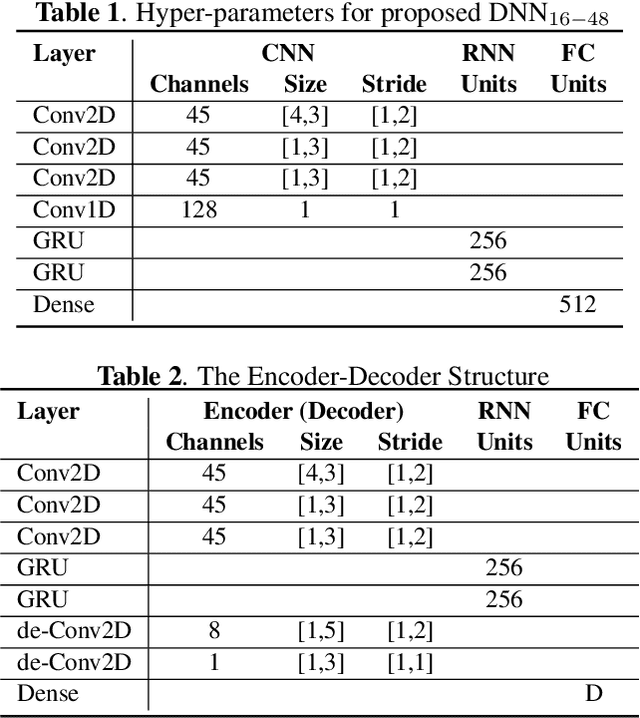
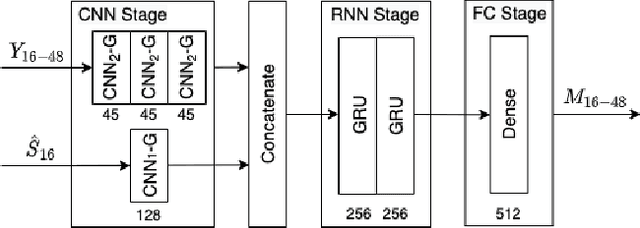
Speech enhancement methods based on deep learning have surpassed traditional methods. While many of these new approaches are operating on the wideband (16kHz) sample rate, a new fullband (48kHz) speech enhancement system is proposed in this paper. Compared to the existing fullband systems that utilizes perceptually motivated features to train the fullband speech enhancement using a single network structure, the proposed system is a two-step system ensuring good fullband speech enhancement quality while backward compatible to the existing wideband systems.