 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Video Generators to Remember: Eliciting Dynamic Memory for Out-of-Sight State Evolution
May 25, 2026Video world models should maintain evolving states when evidence is unobserved, yet current generators often freeze hidden states upon interruption. This is not simply a capacity problem: pretrained video diffusion transformers already possess KV-cache mechanisms capable of non-local retrieval, but they are rarely trained to use them as dynamic memory. We introduce ReMind, a framework eliciting dynamic memory behavior via memory-oriented data, event-aware training, and cache adaptation. Organized around a taxonomy of 100+ dynamic events, we build a camera-annotated training mixture combining VLM-filtered real videos, generated hard dynamics, synthetic camera loops, and memory-interruption augmentations. Each clip is converted into a frame graph with protected anchors, degraded intervals, and explicit temporal gaps. A node-structured curriculum, including node-drop, noisy memory, frontier continuation, and reference-cache training, forces the model to retrieve relevant past states across interruptions rather than relying solely on local continuity. PM-RoPE, an elegant camera-phase RoPE extension, unlocks spatiotemporal retrieval at a single-attention cost while preserving pretrained pathways. ReMind achieves the best overall scores on STEVO-Bench and recovery tasks. Furthermore, general image-to-video evaluations confirm this curriculum avoids catastrophic forgetting. We will open-source our code, data, and models.
LaMo: Self-Supervised Latent Motion Priors for Physical Realism in Video Generation
May 22, 2026Modern video generators produce visually compelling clips but still struggle with physical and motion consistency, limiting their use as reliable world simulators. Existing remedies often rely on external simulators, teacher models, or curated physics-focused data. We explore a complementary self-supervised direction: extracting motion cues from the unlabeled videos already used to train video diffusion models. We propose LaMo, which formulates a latent motion prior over frame-to-frame latent changes conditioned on the current latent and prompt. This prior is exposed through two lightweight readouts: a macro motion drift used during training as a Motion Drift Loss, and a learned micro motion field used during sampling as Motion Prior Guidance. Both components are plug-and-play with existing video diffusion backbones, requiring no architectural or I/O changes. On VideoPhy and VideoPhy2, LaMo improves CogVideoX backbones and outperforms recent physics-aware baselines that use external supervision. On VBench, it preserves overall generation quality while improving motion-related dimensions. These results suggest that unlabeled video contains useful motion supervision for improving physical fidelity in modern video diffusion models.
URoPE: Universal Relative Position Embedding across Geometric Spaces
Apr 20, 2026Relative position embedding has become a standard mechanism for encoding positional information in Transformers. However, existing formulations are typically limited to a fixed geometric space, namely 1D sequences or regular 2D/3D grids, which restricts their applicability to many computer vision tasks that require geometric reasoning across camera views or between 2D and 3D spaces. To address this limitation, we propose URoPE, a universal extension of Rotary Position Embedding (RoPE) to cross-view or cross-dimensional geometric spaces. For each key/value image patch, URoPE samples 3D points along the corresponding camera ray at predefined depth anchors and projects them into the query image plane. Standard 2D RoPE can then be applied using the projected pixel coordinates. URoPE is a parameter-free and intrinsics-aware relative position embedding that is invariant to the choice of global coordinate systems, while remaining fully compatible with existing RoPE-optimized attention kernels. We evaluate URoPE as a plug-in positional encoding for transformer architectures across a diverse set of tasks, including novel view synthesis, 3D object detection, object tracking, and depth estimation, covering 2D-2D, 2D-3D, and temporal scenarios. Experiments show that URoPE consistently improves the performance of transformer-based models across all tasks, demonstrating its effectiveness and generality for geometric reasoning. Our project website is: https://urope-pe.github.io/.
SpectralSplat: Appearance-Disentangled Feed-Forward Gaussian Splatting for Driving Scenes
Apr 03, 2026Feed-forward 3D Gaussian Splatting methods have achieved impressive reconstruction quality for autonomous driving scenes, yet they entangle scene geometry with transient appearance properties such as lighting, weather, and time of day. This coupling prevents relighting, appearance transfer, and consistent rendering across multi-traversal data captured under varying environmental conditions. We present SpectralSplat, a method that disentangles appearance from geometry within a feed-forward Gaussian Splatting framework. Our key insight is to factor color prediction into an appearance-agnostic base stream and and appearance-conditioned adapted stream, both produced by a shared MLP conditioned on a global appearance embedding derived from DINOv2 features. To enforce disentanglement, we train with paired observations generated by a hybrid relighting pipeline that combines physics-based intrinsic decomposition with diffusion based generative refinement, and supervise with complementary consistency, reconstruction, cross-appearance, and base color losses. We further introduce an appearance-adaptable temporal history that stores appearance-agnostic features, enabling accumulated Gaussians to be re-rendered under arbitrary target appearances. Experiments demonstrate that SpectralSplat preserves the reconstruction quality of the underlying backbone while enabling controllable appearance transfer and temporally consistent relighting across driving sequences.
Evaluating Roadside Perception for Autonomous Vehicles: Insights from Field Testing
Jan 22, 2024Roadside perception systems are increasingly crucial in enhancing traffic safety and facilitating cooperative driving for autonomous vehicles. Despite rapid technological advancements, a major challenge persists for this newly arising field: the absence of standardized evaluation methods and benchmarks for these systems. This limitation hampers the ability to effectively assess and compare the performance of different systems, thus constraining progress in this vital field. This paper introduces a comprehensive evaluation methodology specifically designed to assess the performance of roadside perception systems. Our methodology encompasses measurement techniques, metric selection, and experimental trial design, all grounded in real-world field testing to ensure the practical applicability of our approach. We applied our methodology in Mcity\footnote{\url{https://mcity.umich.edu/}}, a controlled testing environment, to evaluate various off-the-shelf perception systems. This approach allowed for an in-depth comparative analysis of their performance in realistic scenarios, offering key insights into their respective strengths and limitations. The findings of this study are poised to inform the development of industry-standard benchmarks and evaluation methods, thereby enhancing the effectiveness of roadside perception system development and deployment for autonomous vehicles. We anticipate that this paper will stimulate essential discourse on standardizing evaluation methods for roadside perception systems, thus pushing the frontiers of this technology. Furthermore, our results offer both academia and industry a comprehensive understanding of the capabilities of contemporary infrastructure-based perception systems.
MSight: An Edge-Cloud Infrastructure-based Perception System for Connected Automated Vehicles
Oct 08, 2023



As vehicular communication and networking technologies continue to advance, infrastructure-based roadside perception emerges as a pivotal tool for connected automated vehicle (CAV) applications. Due to their elevated positioning, roadside sensors, including cameras and lidars, often enjoy unobstructed views with diminished object occlusion. This provides them a distinct advantage over onboard perception, enabling more robust and accurate detection of road objects. This paper presents MSight, a cutting-edge roadside perception system specifically designed for CAVs. MSight offers real-time vehicle detection, localization, tracking, and short-term trajectory prediction. Evaluations underscore the system's capability to uphold lane-level accuracy with minimal latency, revealing a range of potential applications to enhance CAV safety and efficiency. Presently, MSight operates 24/7 at a two-lane roundabout in the City of Ann Arbor, Michigan.
Robust Roadside Perception for Autonomous Driving: an Annotation-free Strategy with Synthesized Data
Jun 29, 2023Recently, with the rapid development in vehicle-to-infrastructure communication technologies, the infrastructure-based, roadside perception system for cooperative driving has become a rising field. This paper focuses on one of the most critical challenges - the data-insufficiency problem. The lacking of high-quality labeled roadside sensor data with high diversity leads to low robustness, and low transfer-ability of current roadside perception systems. In this paper, a novel approach is proposed to address this problem by creating synthesized training data using Augmented Reality and Generative Adversarial Network. This method creates synthesized dataset that is capable of training or fine-tuning a roadside perception detector which is robust to different weather and lighting conditions, or to adapt a new deployment location. We validate our approach at two intersections: Mcity intersection and State St/Ellsworth Rd roundabout. Our experiments show that (1) the detector can achieve good performance in all conditions when trained on synthesized data only, and (2) the performance of an existing detector trained with labeled data can be enhanced by synthesized data in harsh conditions.
ROCO: A Roundabout Traffic Conflict Dataset
Mar 02, 2023Traffic conflicts have been studied by the transportation research community as a surrogate safety measure for decades. However, due to the rarity of traffic conflicts, collecting large-scale real-world traffic conflict data becomes extremely challenging. In this paper, we introduce and analyze ROCO - a real-world roundabout traffic conflict dataset. The data is collected at a two-lane roundabout at the intersection of State St. and W. Ellsworth Rd. in Ann Arbor, Michigan. We use raw video dataflow captured from four fisheye cameras installed at the roundabout as our input data source. We adopt a learning-based conflict identification algorithm from video to find potential traffic conflicts, and then manually label them for dataset collection and annotation. In total 557 traffic conflicts and 17 traffic crashes are collected from August 2021 to October 2021. We provide trajectory data of the traffic conflict scenes extracted using our roadside perception system. Taxonomy based on traffic conflict severity, reason for the traffic conflict, and its effect on the traffic flow is provided. With the traffic conflict data collected, we discover that failure to yield to circulating vehicles when entering the roundabout is the largest contributing reason for traffic conflicts. ROCO dataset will be made public in the short future.
CORE: Consistent Representation Learning for Face Forgery Detection
Jun 06, 2022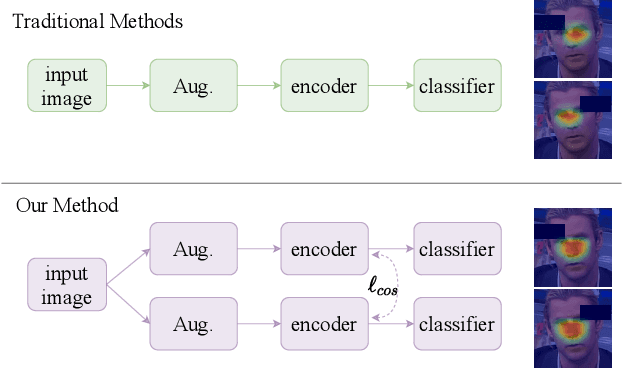
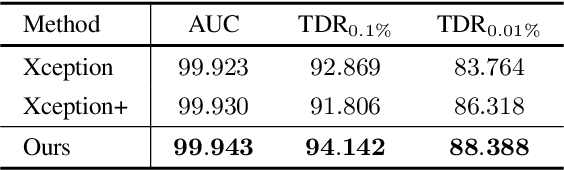
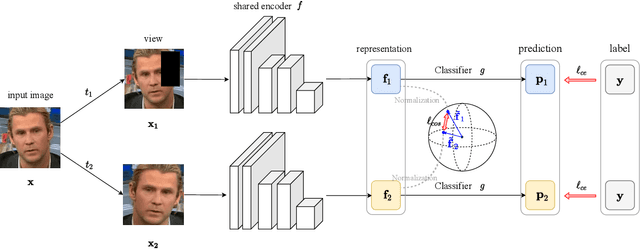
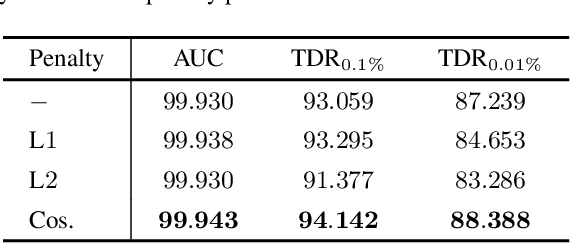
Face manipulation techniques develop rapidly and arouse widespread public concerns. Despite that vanilla convolutional neural networks achieve acceptable performance, they suffer from the overfitting issue. To relieve this issue, there is a trend to introduce some erasing-based augmentations. We find that these methods indeed attempt to implicitly induce more consistent representations for different augmentations via assigning the same label for different augmented images. However, due to the lack of explicit regularization, the consistency between different representations is less satisfactory. Therefore, we constrain the consistency of different representations explicitly and propose a simple yet effective framework, COnsistent REpresentation Learning (CORE). Specifically, we first capture the different representations with different augmentations, then regularize the cosine distance of the representations to enhance the consistency. Extensive experiments (in-dataset and cross-dataset) demonstrate that CORE performs favorably against state-of-the-art face forgery detection methods.
Conditional DETR for Fast Training Convergence
Aug 19, 2021
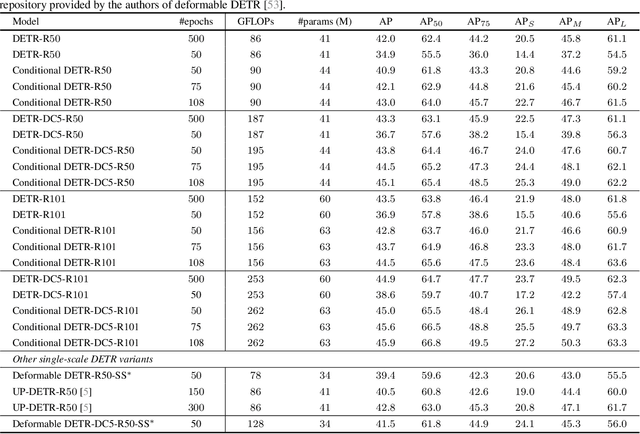
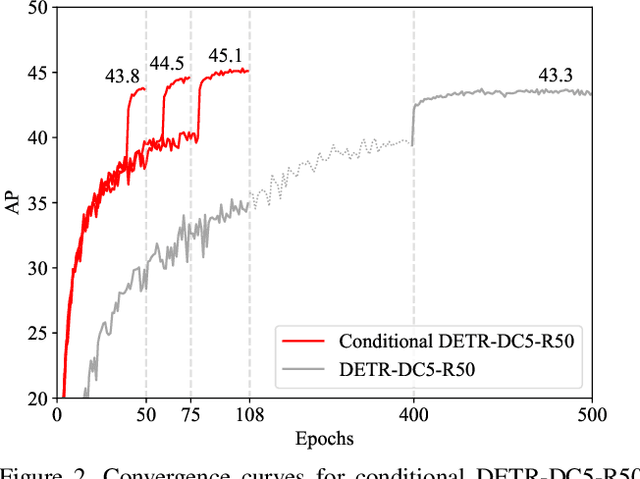
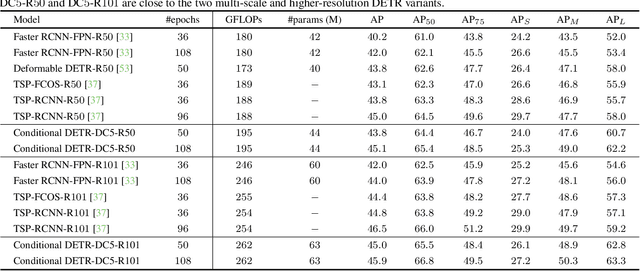
The recently-developed DETR approach applies the transformer encoder and decoder architecture to object detection and achieves promising performance. In this paper, we handle the critical issue, slow training convergence, and present a conditional cross-attention mechanism for fast DETR training. Our approach is motivated by that the cross-attention in DETR relies highly on the content embeddings for localizing the four extremities and predicting the box, which increases the need for high-quality content embeddings and thus the training difficulty. Our approach, named conditional DETR, learns a conditional spatial query from the decoder embedding for decoder multi-head cross-attention. The benefit is that through the conditional spatial query, each cross-attention head is able to attend to a band containing a distinct region, e.g., one object extremity or a region inside the object box. This narrows down the spatial range for localizing the distinct regions for object classification and box regression, thus relaxing the dependence on the content embeddings and easing the training. Empirical results show that conditional DETR converges 6.7x faster for the backbones R50 and R101 and 10x faster for stronger backbones DC5-R50 and DC5-R101. Code is available at https://github.com/Atten4Vis/ConditionalDETR.