 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing Approximate Equilibria in Sequential Adversarial Games by Exploitability Descent
Mar 21, 2019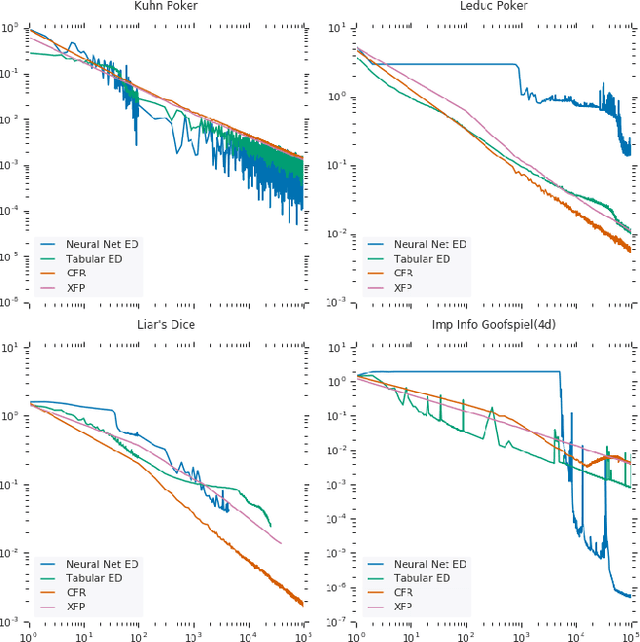
In this paper, we present exploitability descent, a new algorithm to compute approximate equilibria in two-player zero-sum extensive-form games with imperfect information, by direct policy optimization against worst-case opponents. We prove that when following this optimization, the exploitability of a player's strategy converges asymptotically to zero, and hence when both players employ this optimization, the joint policies converge to a Nash equilibrium. Unlike fictitious play (XFP) and counterfactual regret minimization (CFR), our convergence result pertains to the policies being optimized rather than the average policies. Our experiments demonstrate convergence rates comparable to XFP and CFR in four benchmark games in the tabular case. Using function approximation, we find that our algorithm outperforms the tabular version in two of the games, which, to the best of our knowledge, is the first such result in imperfect information games among this class of algorithms.
Fully Convolutional One-Shot Object Segmentation for Industrial Robotics
Mar 02, 2019
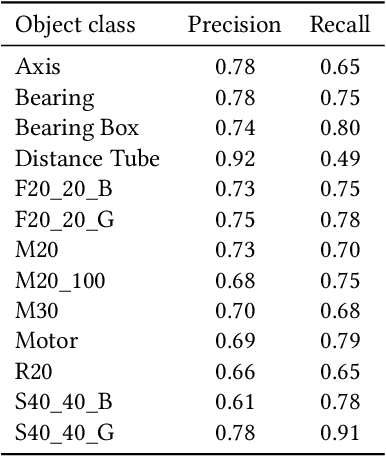
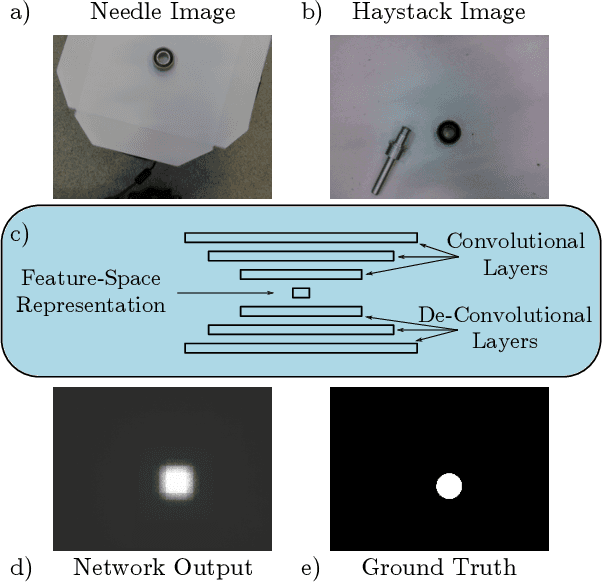
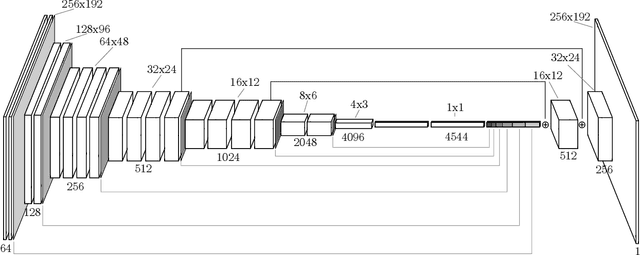
The ability to identify and localize new objects robustly and effectively is vital for robotic grasping and manipulation in warehouses or smart factories. Deep convolutional neural networks (DCNNs) have achieved the state-of-the-art performance on established image datasets for object detection and segmentation. However, applying DCNNs in dynamic industrial scenarios, e.g., warehouses and autonomous production, remains a challenging problem. DCNNs quickly become ineffective when tasked with detecting objects that they have not been trained on. Given that re-training using the latest data is time consuming, DCNNs cannot meet the requirement of the Factory of the Future (FoF) regarding rapid development and production cycles. To address this problem, we propose a novel one-shot object segmentation framework, using a fully convolutional Siamese network architecture, to detect previously unknown objects based on a single prototype image. We turn to multi-task learning to reduce training time and improve classification accuracy. Furthermore, we introduce a novel approach to automatically cluster the learnt feature space representation in a weakly supervised manner. We test the proposed framework on the RoboCup@Work dataset, simulating requirements for the FoF. Results show that the trained network on average identifies 73% of previously unseen objects correctly from a single example image. Correctly identified objects are estimated to have a 87.53% successful pick-up rate. Finally, multi-task learning lowers the convergence time by up to 33%, and increases accuracy by 2.99%.
Robust temporal difference learning for critical domains
Jan 23, 2019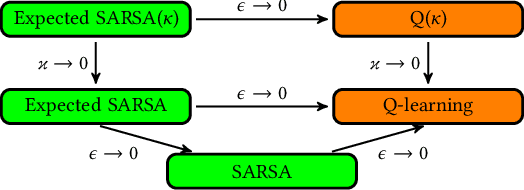

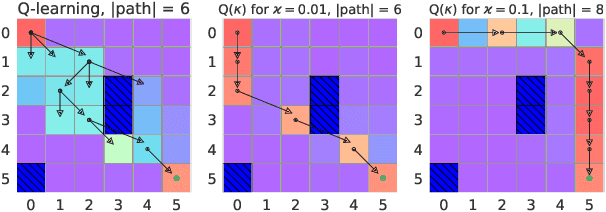
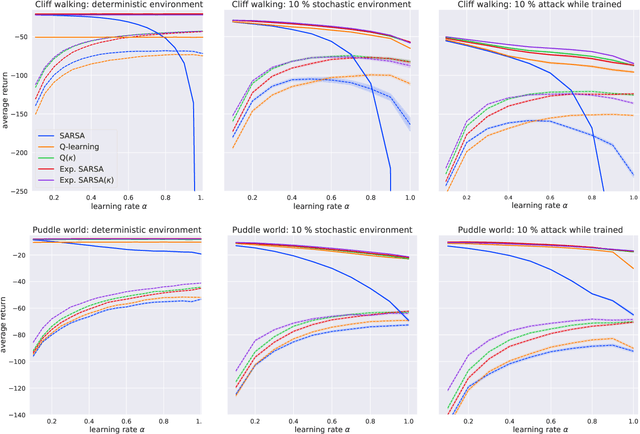
We present a new Q-function operator for temporal difference (TD) learning methods that explicitly encodes robustness against significant rare events (SRE) in critical domains. The operator, which we call the $\kappa$-operator, allows to learn a safe policy in a model-based fashion without actually observing the SRE. We introduce single- and multi-agent robust TD methods using the operator $\kappa$. We prove convergence of the operator to the optimal safe Q-function with respect to the model using the theory of Generalized Markov Decision Processes. In addition we prove convergence to the optimal Q-function of the original MDP given that the probability of SREs vanishes. Empirical evaluations demonstrate the superior performance of $\kappa$-based TD methods both in the early learning phase as well as in the final converged stage. In addition we show robustness of the proposed method to small model errors, as well as its applicability in a multi-agent context.
Re-evaluating Evaluation
Oct 30, 2018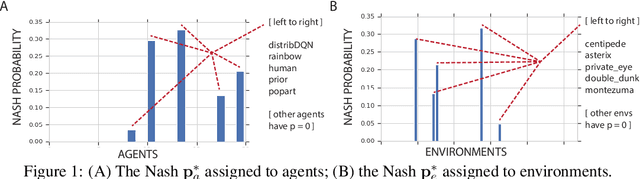
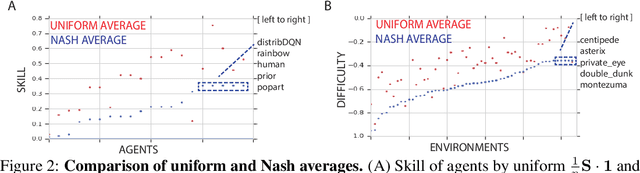
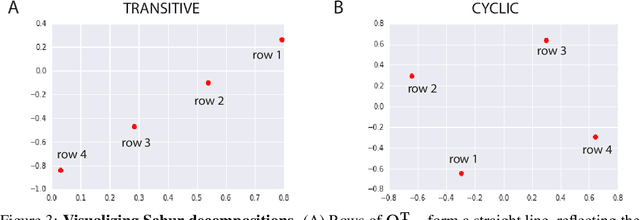
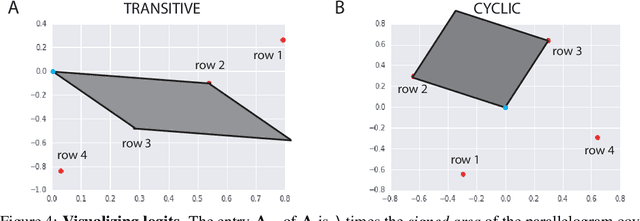
Progress in machine learning is measured by careful evaluation on problems of outstanding common interest. However, the proliferation of benchmark suites and environments, adversarial attacks, and other complications has diluted the basic evaluation model by overwhelming researchers with choices. Deliberate or accidental cherry picking is increasingly likely, and designing well-balanced evaluation suites requires increasing effort. In this paper we take a step back and propose Nash averaging. The approach builds on a detailed analysis of the algebraic structure of evaluation in two basic scenarios: agent-vs-agent and agent-vs-task. The key strength of Nash averaging is that it automatically adapts to redundancies in evaluation data, so that results are not biased by the incorporation of easy tasks or weak agents. Nash averaging thus encourages maximally inclusive evaluation -- since there is no harm (computational cost aside) from including all available tasks and agents.
Actor-Critic Policy Optimization in Partially Observable Multiagent Environments
Oct 21, 2018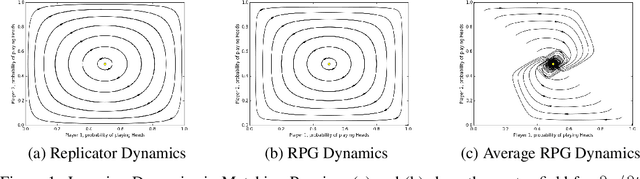
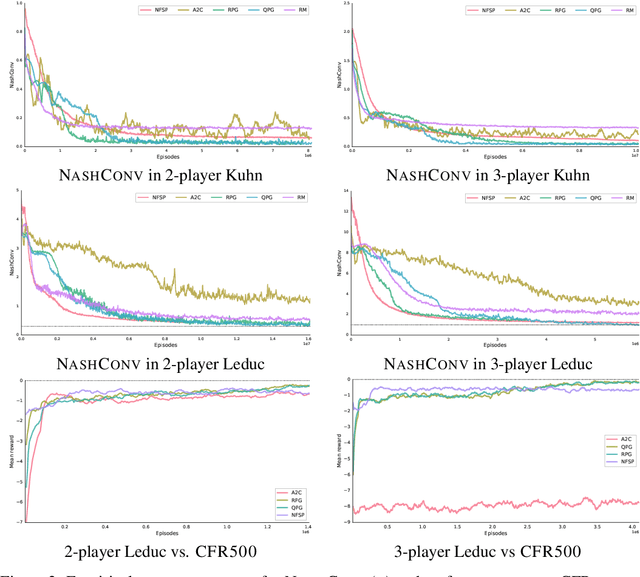
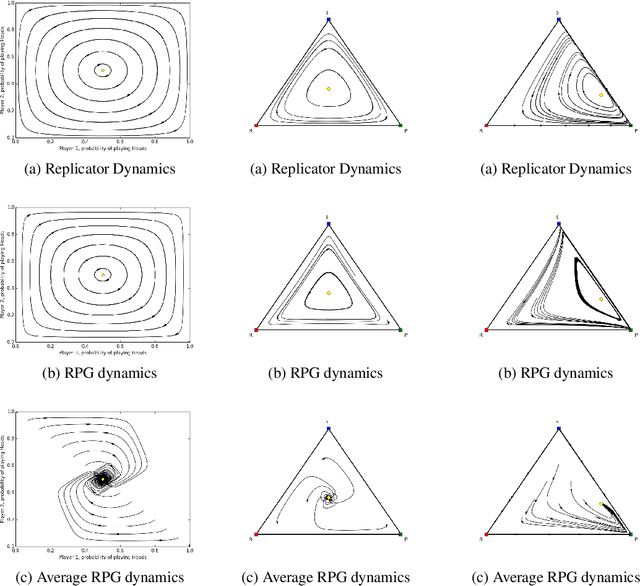
Optimization of parameterized policies for reinforcement learning (RL) is an important and challenging problem in artificial intelligence. Among the most common approaches are algorithms based on gradient ascent of a score function representing discounted return. In this paper, we examine the role of these policy gradient and actor-critic algorithms in partially-observable multiagent environments. We show several candidate policy update rules and relate them to a foundation of regret minimization and multiagent learning techniques for the one-shot and tabular cases, leading to previously unknown convergence guarantees. We apply our method to model-free multiagent reinforcement learning in adversarial sequential decision problems (zero-sum imperfect information games), using RL-style function approximation. We evaluate on commonly used benchmark Poker domains, showing performance against fixed policies and empirical convergence to approximate Nash equilibria in self-play with rates similar to or better than a baseline model-free algorithm for zero sum games, without any domain-specific state space reductions.
Inequity aversion improves cooperation in intertemporal social dilemmas
Sep 27, 2018
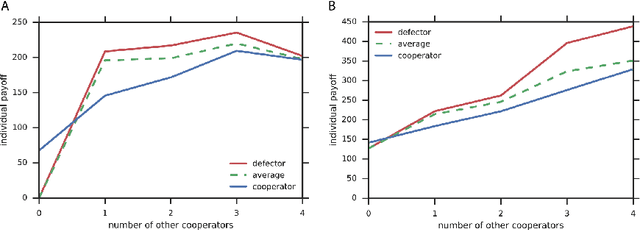
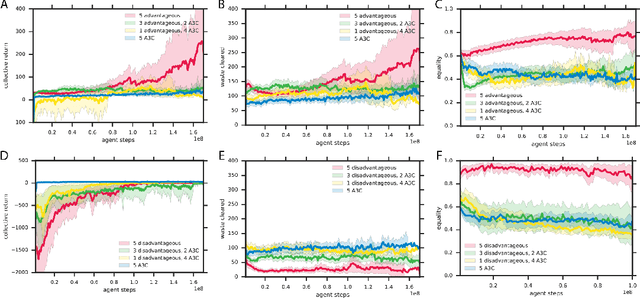
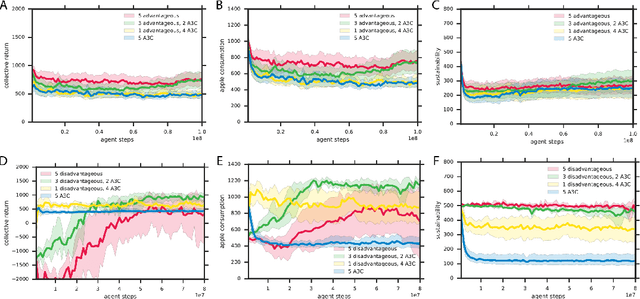
Groups of humans are often able to find ways to cooperate with one another in complex, temporally extended social dilemmas. Models based on behavioral economics are only able to explain this phenomenon for unrealistic stateless matrix games. Recently, multi-agent reinforcement learning has been applied to generalize social dilemma problems to temporally and spatially extended Markov games. However, this has not yet generated an agent that learns to cooperate in social dilemmas as humans do. A key insight is that many, but not all, human individuals have inequity averse social preferences. This promotes a particular resolution of the matrix game social dilemma wherein inequity-averse individuals are personally pro-social and punish defectors. Here we extend this idea to Markov games and show that it promotes cooperation in several types of sequential social dilemma, via a profitable interaction with policy learnability. In particular, we find that inequity aversion improves temporal credit assignment for the important class of intertemporal social dilemmas. These results help explain how large-scale cooperation may emerge and persist.
SCC-rFMQ Learning in Cooperative Markov Games with Continuous Actions
Sep 18, 2018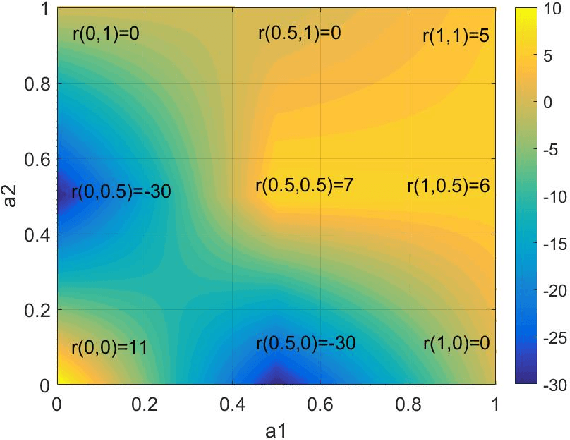
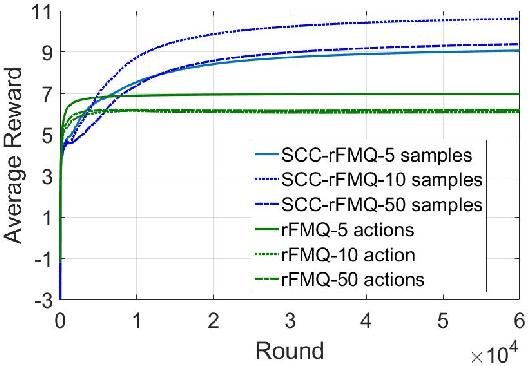
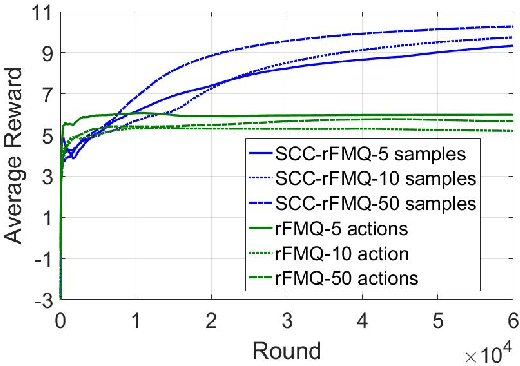
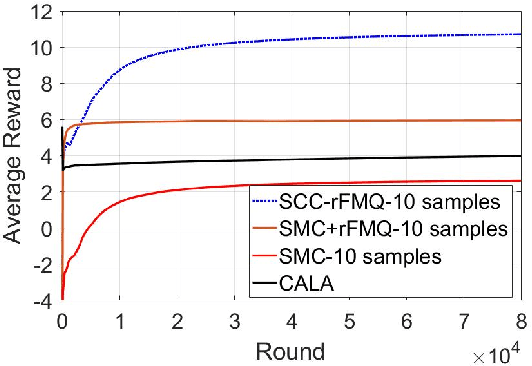
Although many reinforcement learning methods have been proposed for learning the optimal solutions in single-agent continuous-action domains, multiagent coordination domains with continuous actions have received relatively few investigations. In this paper, we propose an independent learner hierarchical method, named Sample Continuous Coordination with recursive Frequency Maximum Q-Value (SCC-rFMQ), which divides the cooperative problem with continuous actions into two layers. The first layer samples a finite set of actions from the continuous action spaces by a re-sampling mechanism with variable exploratory rates, and the second layer evaluates the actions in the sampled action set and updates the policy using a reinforcement learning cooperative method. By constructing cooperative mechanisms at both levels, SCC-rFMQ can handle cooperative problems in continuous action cooperative Markov games effectively. The effectiveness of SCC-rFMQ is experimentally demonstrated on two well-designed games, i.e., a continuous version of the climbing game and a cooperative version of the boat problem. Experimental results show that SCC-rFMQ outperforms other reinforcement learning algorithms.
Negative Update Intervals in Deep Multi-Agent Reinforcement Learning
Sep 17, 2018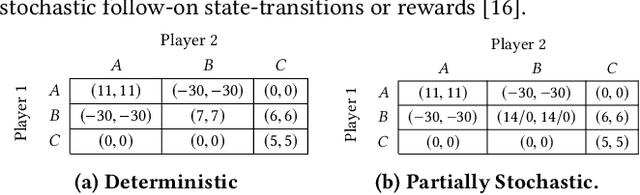

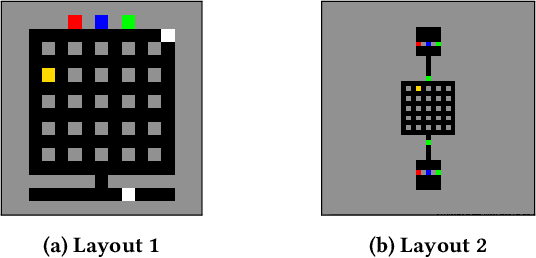
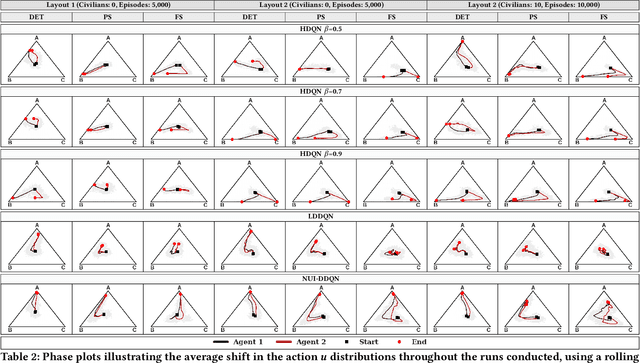
In Multi-Agent Reinforcement Learning, independent cooperative learners must overcome a number of pathologies in order to learn optimal joint policies. These pathologies include action-shadowing, stochasticity, the moving target and alter-exploration problems (Matignon, Laurent, and Le Fort-Piat 2012; Wei and Luke 2016). Numerous methods have been proposed to address these pathologies, but evaluations are predominately conducted in repeated strategic-form games and stochastic games consisting of only a small number of state transitions. This raises the question of the scalability of the methods to complex, temporally extended, partially observable domains with stochastic transitions and rewards. In this paper we study such complex settings, which require reasoning over long time horizons and confront agents with the curse of dimensionality. To deal with the dimensionality, we adopt a Multi-Agent Deep Reinforcement Learning (MA-DRL) approach. We find that when the agents have to make critical decisions in seclusion, existing methods succumb to a combination of relative overgeneralisation (a type of action shadowing), the alter-exploration problem, and the stochasticity. To address these pathologies we introduce expanding negative update intervals that enable independent learners to establish the near-optimal average utility values for higher-level strategies while largely discarding transitions from episodes that result in mis-coordination. We evaluate Negative Update Intervals Double-DQN (NUI-DDQN) within a temporally extended Climb Game, a normal form game which has frequently been used to study relative over-generalisation and other pathologies. We show that NUI-DDQN can converge towards optimal joint-policies in deterministic and stochastic reward settings, overcoming relative-overgeneralisation and the alter-exploration problem while mitigating the moving target problem.
A Comparative Study of Bug Algorithms for Robot Navigation
Aug 17, 2018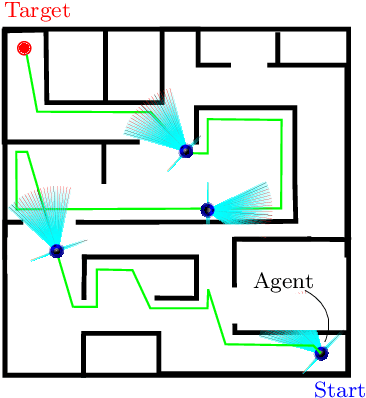
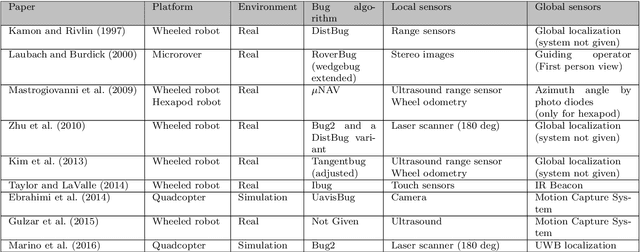
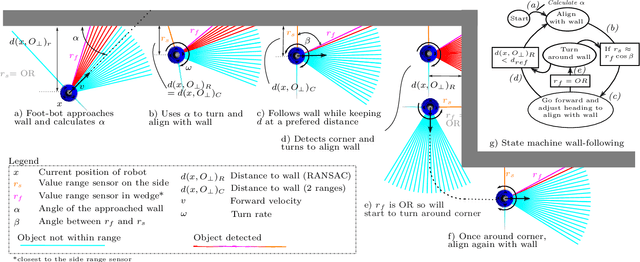
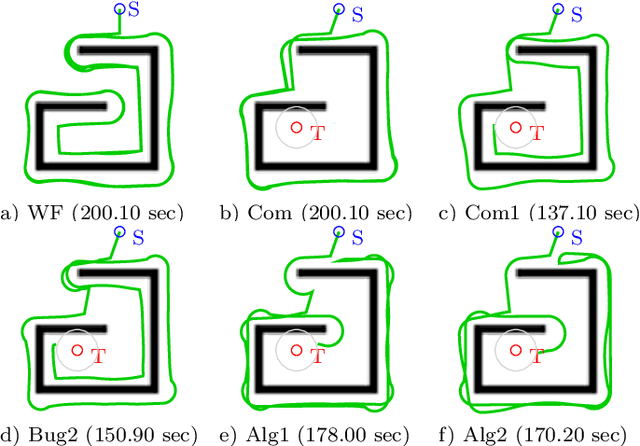
This paper presents a literature survey and a comparative study of Bug Algorithms, with the goal of investigating their potential for robotic navigation. At first sight, these methods seem to provide an efficient navigation paradigm, ideal for implementations on tiny robots with limited resources. Closer inspection, however, shows that many of these Bug Algorithms assume perfect global position estimate of the robot which in GPS-denied environments implies considerable expenses of computation and memory -- relying on accurate Simultaneous Localization And Mapping (SLAM) or Visual Odometry (VO) methods. We compare a selection of Bug Algorithms in a simulated robot and environment where they endure different types noise and failure-cases of their on-board sensors. From the simulation results, we conclude that the implemented Bug Algorithms' performances are sensitive to many types of sensor-noise, which was most noticeable for odometry-drift. This raises the question if Bug Algorithms are suitable for real-world, on-board, robotic navigation as is. Variations that use multiple sensors to keep track of their progress towards the goal, were more adept in completing their task in the presence of sensor-failures. This shows that Bug Algorithms must spread their risk, by relying on the readings of multiple sensors, to be suitable for real-world deployment.
Fast Convergence for Object Detection by Learning how to Combine Error Functions
Aug 13, 2018
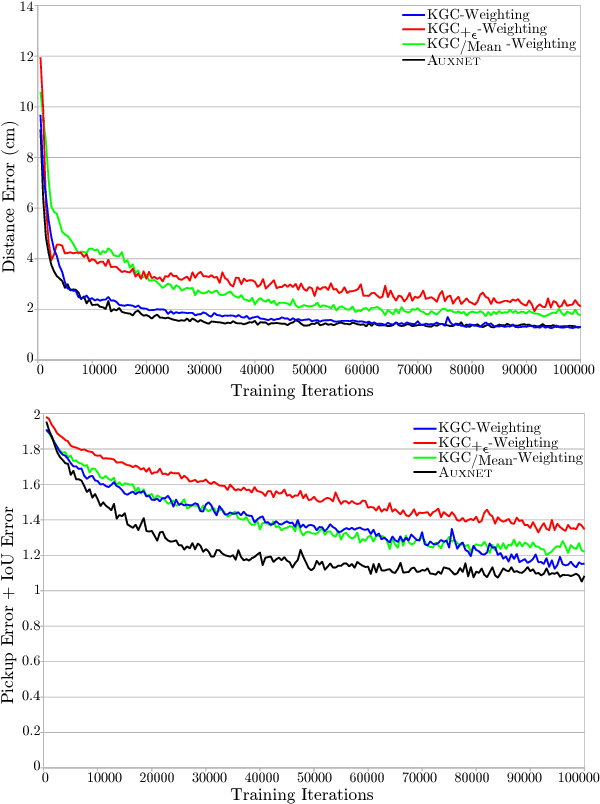
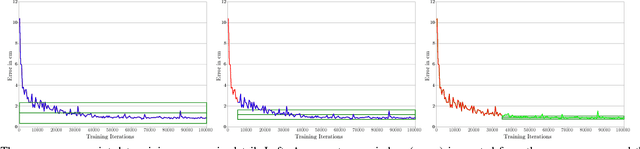
In this paper, we introduce an innovative method to improve the convergence speed and accuracy of object detection neural networks. Our approach, CONVERGE-FAST-AUXNET, is based on employing multiple, dependent loss metrics and weighting them optimally using an on-line trained auxiliary network. Experiments are performed in the well-known RoboCup@Work challenge environment. A fully convolutional segmentation network is trained on detecting objects' pickup points. We empirically obtain an approximate measure for the rate of success of a robotic pickup operation based on the accuracy of the object detection network. Our experiments show that adding an optimally weighted Euclidean distance loss to a network trained on the commonly used Intersection over Union (IoU) metric reduces the convergence time by 42.48%. The estimated pickup rate is improved by 39.90%. Compared to state-of-the-art task weighting methods, the improvement is 24.5% in convergence, and 15.8% on the estimated pickup rate.