 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing and Repairing Unsafe Channels in Vision-Language Models via Causal Discovery and Dual-Modal Safety Subspace Projection
Mar 28, 2026Large Vision-Language Models (LVLMs) have achieved impressive performance across multimodal understanding and reasoning tasks, yet their internal safety mechanisms remain opaque and poorly controlled. In this work, we present a comprehensive framework for diagnosing and repairing unsafe channels within LVLMs (CARE). We first perform causal mediation analysis to identify neurons and layers that are causally responsible for unsafe behaviors. Based on these findings, we introduce a dual-modal safety subspace projection method that learns generalized safety subspaces for both visual and textual modalities through generalized eigen-decomposition between benign and malicious activations. During inference, activations are dynamically projected toward these safety subspaces via a hybrid fusion mechanism that adaptively balances visual and textual corrections, effectively suppressing unsafe features while preserving semantic fidelity. Extensive experiments on multiple safety benchmarks demonstrate that our causal-subspace repair framework significantly enhances safety robustness without degrading general multimodal capabilities, outperforming prior activation steering and alignment-based baselines. Additionally, our method exhibits good transferability, defending against unseen attacks.
Disrupting Vision-Language Model-Driven Navigation Services via Adversarial Object Fusion
May 29, 2025We present Adversarial Object Fusion (AdvOF), a novel attack framework targeting vision-and-language navigation (VLN) agents in service-oriented environments by generating adversarial 3D objects. While foundational models like Large Language Models (LLMs) and Vision Language Models (VLMs) have enhanced service-oriented navigation systems through improved perception and decision-making, their integration introduces vulnerabilities in mission-critical service workflows. Existing adversarial attacks fail to address service computing contexts, where reliability and quality-of-service (QoS) are paramount. We utilize AdvOF to investigate and explore the impact of adversarial environments on the VLM-based perception module of VLN agents. In particular, AdvOF first precisely aggregates and aligns the victim object positions in both 2D and 3D space, defining and rendering adversarial objects. Then, we collaboratively optimize the adversarial object with regularization between the adversarial and victim object across physical properties and VLM perceptions. Through assigning importance weights to varying views, the optimization is processed stably and multi-viewedly by iterative fusions from local updates and justifications. Our extensive evaluations demonstrate AdvOF can effectively degrade agent performance under adversarial conditions while maintaining minimal interference with normal navigation tasks. This work advances the understanding of service security in VLM-powered navigation systems, providing computational foundations for robust service composition in physical-world deployments.
Attention! You Vision Language Model Could Be Maliciously Manipulated
May 26, 2025



Large Vision-Language Models (VLMs) have achieved remarkable success in understanding complex real-world scenarios and supporting data-driven decision-making processes. However, VLMs exhibit significant vulnerability against adversarial examples, either text or image, which can lead to various adversarial outcomes, e.g., jailbreaking, hijacking, and hallucination, etc. In this work, we empirically and theoretically demonstrate that VLMs are particularly susceptible to image-based adversarial examples, where imperceptible perturbations can precisely manipulate each output token. To this end, we propose a novel attack called Vision-language model Manipulation Attack (VMA), which integrates first-order and second-order momentum optimization techniques with a differentiable transformation mechanism to effectively optimize the adversarial perturbation. Notably, VMA can be a double-edged sword: it can be leveraged to implement various attacks, such as jailbreaking, hijacking, privacy breaches, Denial-of-Service, and the generation of sponge examples, etc, while simultaneously enabling the injection of watermarks for copyright protection. Extensive empirical evaluations substantiate the efficacy and generalizability of VMA across diverse scenarios and datasets.
Mining Glitch Tokens in Large Language Models via Gradient-based Discrete Optimization
Oct 19, 2024



Glitch tokens in Large Language Models (LLMs) can trigger unpredictable behaviors, compromising model reliability and safety. Existing detection methods often rely on manual observation to infer the prior distribution of glitch tokens, which is inefficient and lacks adaptability across diverse model architectures. To address these limitations, we introduce GlitchMiner, a gradient-based discrete optimization framework designed for efficient glitch token detection in LLMs. GlitchMiner leverages an entropy-based loss function to quantify the uncertainty in model predictions and integrates first-order Taylor approximation with a local search strategy to effectively explore the token space. Our evaluation across various mainstream LLM architectures demonstrates that GlitchMiner surpasses existing methods in both detection precision and adaptability. In comparison to the previous state-of-the-art, GlitchMiner achieves an average improvement of 19.07% in precision@1000 for glitch token detection. By enabling efficient detection of glitch tokens, GlitchMiner provides a valuable tool for assessing and mitigating potential vulnerabilities in LLMs, contributing to their overall security.
ART: Automatic Red-teaming for Text-to-Image Models to Protect Benign Users
May 24, 2024



Large-scale pre-trained generative models are taking the world by storm, due to their abilities in generating creative content. Meanwhile, safeguards for these generative models are developed, to protect users' rights and safety, most of which are designed for large language models. Existing methods primarily focus on jailbreak and adversarial attacks, which mainly evaluate the model's safety under malicious prompts. Recent work found that manually crafted safe prompts can unintentionally trigger unsafe generations. To further systematically evaluate the safety risks of text-to-image models, we propose a novel Automatic Red-Teaming framework, ART. Our method leverages both vision language model and large language model to establish a connection between unsafe generations and their prompts, thereby more efficiently identifying the model's vulnerabilities. With our comprehensive experiments, we reveal the toxicity of the popular open-source text-to-image models. The experiments also validate the effectiveness, adaptability, and great diversity of ART. Additionally, we introduce three large-scale red-teaming datasets for studying the safety risks associated with text-to-image models. Datasets and models can be found in https://github.com/GuanlinLee/ART.
Lower Difficulty and Better Robustness: A Bregman Divergence Perspective for Adversarial Training
Aug 26, 2022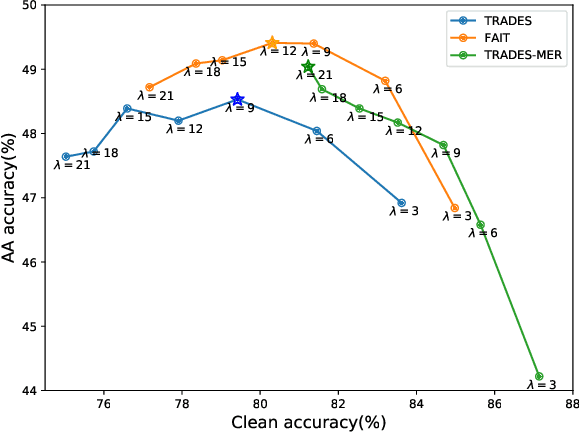
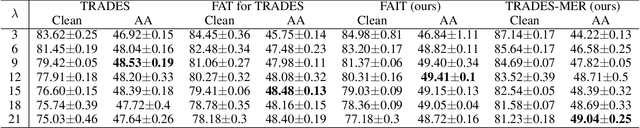
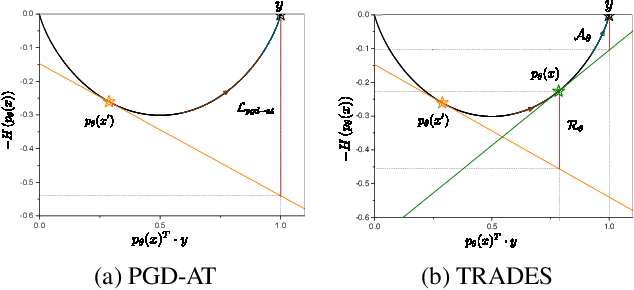
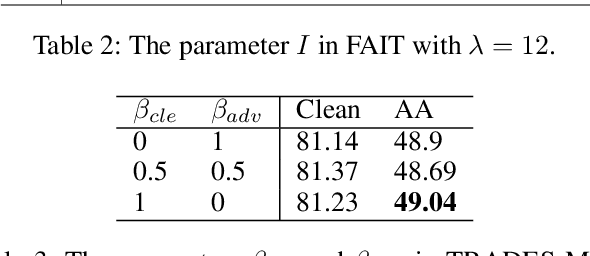
In this paper, we investigate on improving the adversarial robustness obtained in adversarial training (AT) via reducing the difficulty of optimization. To better study this problem, we build a novel Bregman divergence perspective for AT, in which AT can be viewed as the sliding process of the training data points on the negative entropy curve. Based on this perspective, we analyze the learning objectives of two typical AT methods, i.e., PGD-AT and TRADES, and we find that the optimization process of TRADES is easier than PGD-AT for that TRADES separates PGD-AT. In addition, we discuss the function of entropy in TRADES, and we find that models with high entropy can be better robustness learners. Inspired by the above findings, we propose two methods, i.e., FAIT and MER, which can both not only reduce the difficulty of optimization under the 10-step PGD adversaries, but also provide better robustness. Our work suggests that reducing the difficulty of optimization under the 10-step PGD adversaries is a promising approach for enhancing the adversarial robustness in AT.
Alleviating Robust Overfitting of Adversarial Training With Consistency Regularization
May 24, 2022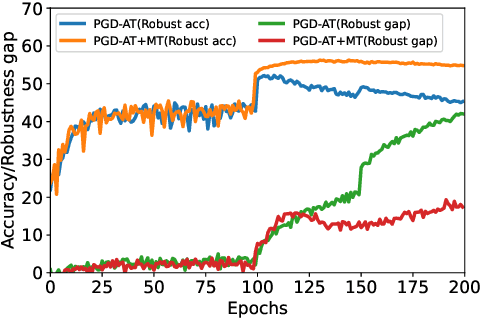
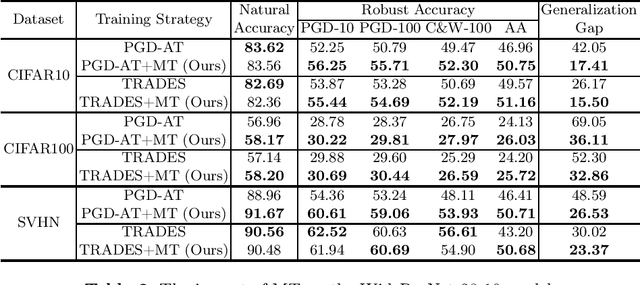
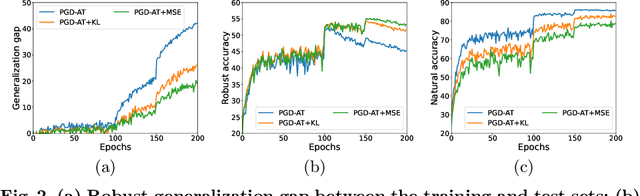

Adversarial training (AT) has proven to be one of the most effective ways to defend Deep Neural Networks (DNNs) against adversarial attacks. However, the phenomenon of robust overfitting, i.e., the robustness will drop sharply at a certain stage, always exists during AT. It is of great importance to decrease this robust generalization gap in order to obtain a robust model. In this paper, we present an in-depth study towards the robust overfitting from a new angle. We observe that consistency regularization, a popular technique in semi-supervised learning, has a similar goal as AT and can be used to alleviate robust overfitting. We empirically validate this observation, and find a majority of prior solutions have implicit connections to consistency regularization. Motivated by this, we introduce a new AT solution, which integrates the consistency regularization and Mean Teacher (MT) strategy into AT. Specifically, we introduce a teacher model, coming from the average weights of the student models over the training steps. Then we design a consistency loss function to make the prediction distribution of the student models over adversarial examples consistent with that of the teacher model over clean samples. Experiments show that our proposed method can effectively alleviate robust overfitting and improve the robustness of DNN models against common adversarial attacks.